目录
选择题
for循环
指针数组
位段
getchar
大小端存储
进制与格式控制符
位运算
数组指针
二维数组的存储
计算二进制中1的个数
斐波那契数列求递归次数
编程题
删除公共字符
排序子序列
倒置字符串
选择题
for循环

解析:该题主要看for循环中的条件表达式," j=0 " 该值是一个假的,因此该for循环将一次也不进入循环体语句,因此k还是刚开始赋初值的0,因此选择B。
指针数组

解析:acX数组和acY数组看似存入的值是一样的,其实不然。acX中是以字符串初始化,acY是以字符进行初始化,在acX中其实还隐藏的加入了一个'\0'。所以acX与axY占用的内存大小不一样,C错误。由于szX与szY中指向的数据是一样的,所以他们指向的地址是一样的。如果szX的内容改变(内容中存放的是地址),其实就是szX指针的指向改变了,并不影响szY的内容。因此选择D选项。
位段

解析:位段中存放的单位为bit。首先为a开辟一个4字节(32位)的空间,a和b相加只有30,因此他们共同存入这个四字节大小的空间里面。再为c开辟一个4字节(32位)的空间,将c可以存入,c存入后还剩28个bit,已经不足以存放d。因此需要再次开辟4字节(32位)的空间,用来存储d。同样的
index由于空间不足需要再次开辟一段1字节(8位)的空间来存放。最后进行内存对齐后一共是16字节。

因此选择C选项。
getchar

getchar是可以从键盘中接受单个字符的,由题可知我们是需要在键盘上输入一段字符,然后以回车('\n')结束,A、B、C选项中都是接受单个字符后,n++来统计次数,因此符合条件。但是D选项,很明显getchar只能再初始化表达式区域初始化一次,然后后续我们输入的字符它是接收不到的,更别提统计我们输入字符的个数了,因此选择D选项。
大小端存储

解析:由题可知,我们首先需要了解大小端存储数据的区别。
-
大端存储(Big Endian):将高字节存储在内存的低地址中,低字节存储在内存的高地址中。在大端存储方式下,一个多字节数据类型的值的最高位字节被放在了最前面(低地址)。
-
小端存储(Little Endian):将低字节存储在内存的低地址中,高字节存储在内存的高地址中。在小端存储方式下,一个多字节数据类型的值的最低位字节被放在了最前面(低地址)。
因此题中数据过程如图所示:
因此该题选择B选项。该题输出结果没有按照预期的走是因为我们的格式控制符和类型不匹配导致的,因此我们注意在使用long long 类型的时候格式控制符应该使用%lld。
进制与格式控制符

解析:我们首先需要知道每个进制所对应的格式控制符和进制的表示。
在程序中,可以使用各种进制来表示常量或变量的值。例如,在C++中,可以使用以下表示方法:
- 二进制:使用
0b或0B前缀,如int a = 0b1010;表示将二进制的1010转换为十进制的10,并将其赋值给变量a。 - 八进制:使用
0前缀,如int b = 017;表示将八进制的17转换为十进制的15,并将其赋值给变量b。 - 十进制:直接书写数字即可,如
int c = 123;表示将十进制的123赋值给变量c。 - 十六进制:使用
0x或0X前缀,如int d = 0x1A;表示将十六进制的1A转换为十进制的26,并将其赋值给变量d。
需要注意的是,在程序中使用不同进制表示的数值,在内存中存储的方式是一样的,都是二进制形式。
格式控制符与进制的对应情况:
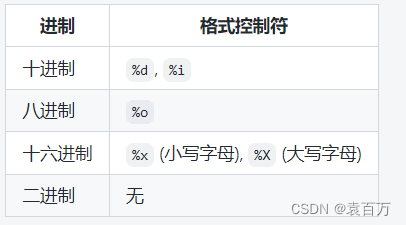
因此我们再去看题目的时候不难发现最后printf中两个数据都需要以八进制的形式打印,然而m=0123已经是八进制,输出的时候直接把0去掉输出123即可。但是n是以十进制的形式存在的,应该首先把该十进制转换为八进制。我们通过除8取余数的方法,可以算出123的八进制为173。
十进制123转换为八进制的步骤图:

因此我们选择C选项。
位运算

解析:本题主要考察的是位运算。
位运算:
- 按位与(&):将两个二进制数的每一位进行与运算,如果两个对应的位都是1,则结果为1,否则为0。例如,0b1010 & 0b1100 = 0b1000。
- 按位或(|):将两个二进制数的每一位进行或运算,如果两个对应的位都是0,则结果为0,否则为1。例如,0b1010 | 0b1100 = 0b1110。
- 按位异或(^):将两个二进制数的每一位进行异或运算,如果两个对应的位相同,则结果为0,否则为1。例如,0b1010 ^ 0b1100 = 0b0110。
- 按位取反(~):对一个二进制数的每一位进行取反操作,即0变成1,1变成0。例如,~0b1010 = 0b0101。
- 左移(<<):将一个二进制数的每一位向左移动若干位,低位用0补齐。例如,0b1010 << 2 = 0b101000。
- 右移(>>):将一个二进制数的每一位向右移动若干位,高位用0补齐(逻辑右移)或用符号位补齐(算术右移)。例如,0b1010 >> 2 = 0b0010。
由题意知,我们需要将flag的第二个bit位置0,但是其他位不改变。最简单的方法就是直接对A、B、C、D。选项进行计算。这样我们就可以得出A选项是正确的。
数组指针

这道题看似很复杂,我们只要明白其中每个变量表达的含义其实也不难。
首先第一行中,我们定义了一个类型为int的数组并且赋初值。
第二行是关键。首先我们在这里阐述一个概念,数组名除了在&后边--&a和sizeof后--sizeof(a)的时候表示整个数组,其他时候都表示首元素的地址。

因此选择C选项。
二维数组的存储

解析:该题主要考察了二维数组。

因此选择A选项。
计算二进制中1的个数

将9999传入这个参数,由于9999这个数并不小,所以直接算肯定是不可取的。所以我们要去寻找规律。
我们首先先传进去几个值来找一下规律。
当x为3时---count=3;当x为5时---count=2;当x为7时---count=3;
又因为在函数体里面进行的是位运算(也就是对二进制进行操作)我们发现该函数其实是求出了x的二进制中1的个数。我们将9999转换为二进制。
 可得9999的二进制为10011100001111中1的个数为8,因此选择A选项。
可得9999的二进制为10011100001111中1的个数为8,因此选择A选项。
斐波那契数列求递归次数

由题意可知,cnt计算的是递归的次数。直接穷举。

因此选择B选项。
编程题
删除公共字符
删除公共字符_牛客题霸_牛客网

我们定义一个数组,根据字符本质在内存中以ASCII码值存在这一点,将str2中的字符首先映射到数组中。然后使用str1进行遍历,如果str1中有str2中没有,则存储起来。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string str1;
string str2;
// 由于输入的字符串中有空格所以使用getline来接收字符串
getline(cin,str1);
getline(cin,str2);
// 定义一个数组
int hashTable[256]={0};
// 先把str2的数据给映射到数组中
int i=0;
for(i=0;i<str2.size();i++)
{
hashTable[str2[i]]++;
}
string ret;
// 使用str1来对比数组中的数据如果不存在则+=到ret中
// 不存在的话就说明在str1中有 str2中没有 符合条件
int j=0;
for(j=0;j<str1.size();j++)
{
if(hashTable[str1[j]]==0)
ret+=str1[j];
}
cout<<ret<<endl;
return 0;
}排序子序列
排序子序列_牛客笔试题_牛客网
这道题的关键就是我们需要明白非递减序列与非递增序列是什么。
非递增就是不是单调的递减的序列,如下所示:
3 3 2 1 就是一个非递增的序列。
在数组中就是满足a[i]>=a[i+1]。
非递减就是不是单调的递增序列,如下所示:
1 1 2 3 就是一个非递减序列。
在数组中就是满足a[i]<=a[i+1]。
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int n = 0;
cin >> n;
vector<int> v;
v.resize(n + 1);//多开辟一个空间是以防a[i+1]越界
v[n] = 0;//题目中有说我们输入的只可能是正整数
for (int i = 0; i < n; i++)
{
cin >> v[i];
}
int i = 0, count = 0;
while (i < n)
{
if (i < n && v[i] < v[i + 1])
{
while (v[i] <= v[i + 1])
{
i++;
}
i++;
count++;
}
else if (i < n && v[i] > v[i + 1])
{
while (v[i] >= v[i + 1])
{
i++;
}
i++;
count++;
}
else
{
i++;
}
}
cout << count << endl;
return 0;
}
倒置字符串
倒置字符串_牛客题霸_牛客网
翻转法:
首先把整个字符串进行翻转,然后再把单个字符串进行翻转。
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
string str;
getline(cin, str);
// 先整体翻转
reverse(str.begin(), str.end());
//为起始位置定义一个名叫start的迭代器
//这里我们使用auto自动识别类型
auto start = str.begin();
//这里while循环()里面给个1让它一直循环
//等我们便利到str.end()的时候让函数体break就行
while (1) {
//定义一个end来遍历单个字符串
auto end = start;
//如果该字符串不为0或者不为str.end()
//那么让它继续遍历说明此字符串还没到头
while (*end != ' ' && end != str.end())
end++;
//翻转单个字符串
reverse(start, end);
//如果end遍历到了' ' 说明此字符串已经遍历完了
//需进行下一个字符串的遍历 直接让start=end+1就行因为此时end处于
//前一个字符串的尾部
if (*end == ' ' && end != str.end())
start = end + 1;
//走到这里说明end==str.end()
//注意 我们直接break 因为已经遍历完毕
else
break;
}
cout << str << endl;
}
拼接法:
先接受一个字符串,然后让接下来接受的字符串都拼接在当前字符串前面,并且用' '隔开。(这里利用了cin输入的时候空格将输入的字符串隔开)。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1, s2;
//先将第一个字符串接受一下
cin >> s1;
// 接下来接受的字符串都加在s1的前面并且以' '隔开
while (cin >> s2)
s1 = s2 + ' ' + s1;
cout << s1 << endl;
}
// 64 位输出请用 printf("%lld")