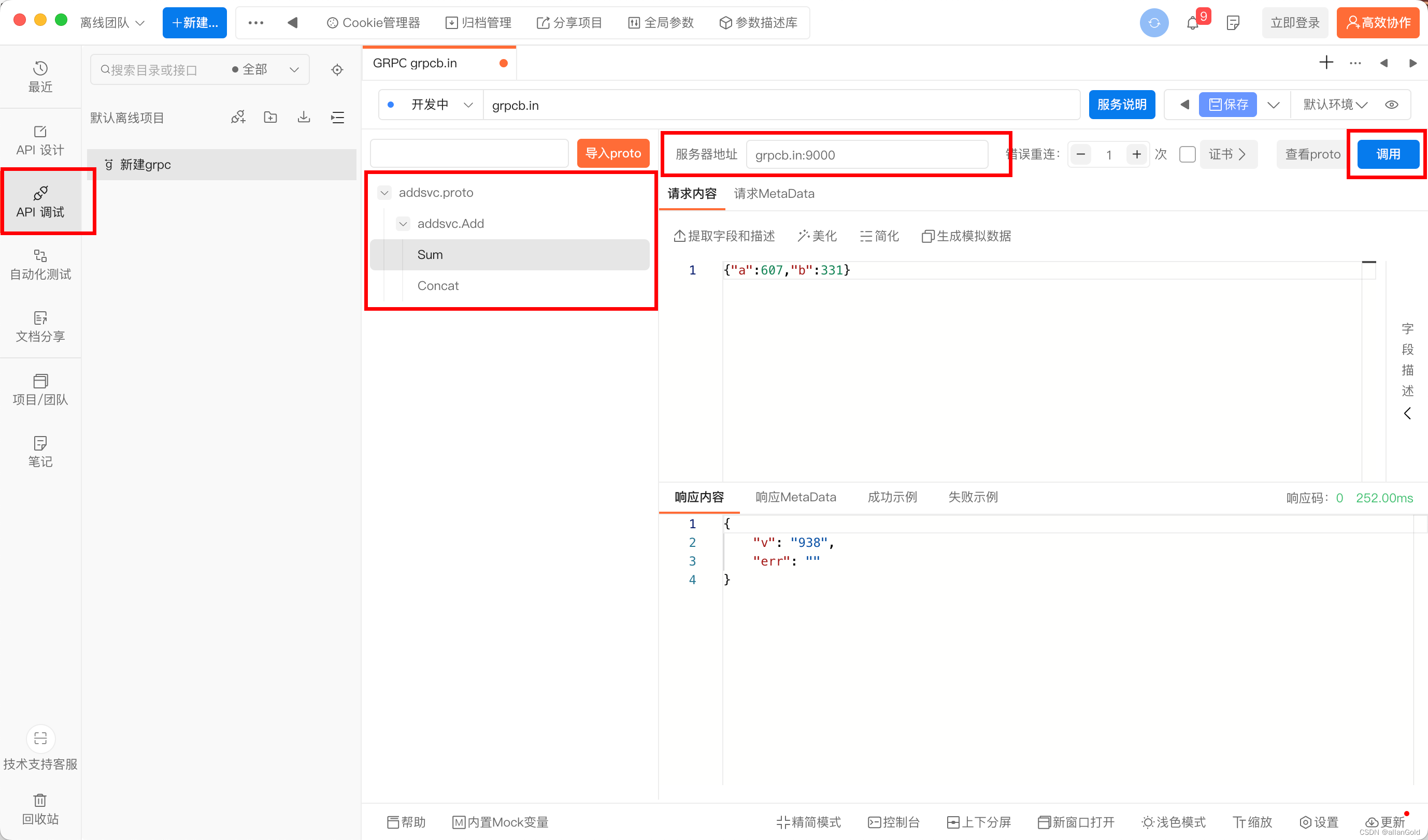
cuda-gdb 基础使用指南
本文的cuda-gdb的简单入门指导,主要的参考是官方文档.但是原文是英文,又找了腾讯家的文档翻译机器,可惜水平着实一般.如果在使用过程中有更细的要求,可以看文档,本文最后贴出原文的目录,可以自己按图索骥,看看有没有其他的需求.
入门要求
既然是cuda-gdb,那么首先是要求gdb的使用指南,本文并不会涉及到这一块,也就是说默认读者已经基本学习了gdb的使用,如果还不会的这里建议先看b站的视频入门,在看这一篇博客,然后还有问题自行参考官方文档和搜索引擎和new bing.
然后是cuda,这里默认读者已经是cuda入门,所以下文中很多名词不会解释.
文档中特别强调的点
编译
和gdb编译类似,cuda-gdb的程序,需要添加额外的编译选项-g -G
cuda-gdb中在cuda代码中不支持watchpoint
只支持主机端的代码,不支持设备端的代码.
cuda-gdb独有的命令的命名规则
每个新的CUDA命令或选项的前缀是CUDA关键字。
这里要举一个我弄错的例子,那就threads,我在实验的时候查看threads,却发现没办法切换到4以后得线程,实际上切换的却是主机端的线程.
(cuda-gdb) info threads
(cuda-gdb) thread 1
实际上CUDA threads 切换 cuda thread 1使用一下命令
(cuda-gdb) info cuda threads
(cuda-gdb) cuda thread 1
cuda 焦点(cuda focus)
我们都知道cuda的体系下有两套并行体系,逻辑上(kernel block thread)和硬件上(device sm warp lane)的.具体的分析,可以参考原文7.1界.
查看当前的焦点(也就是当前的界面显示是哪一个并行下的所属的地方)可以看
(cuda-gdb) cuda device sm warp lane block thread
block (0,0,0), thread (0,0,0), device 0, sm 0, warp 0, lane 0
(cuda-gdb) cuda kernel block thread
kernel 1, block (0,0,0), thread (0,0,0)
至于切换焦点,可以参考一下
(cuda-gdb) cuda device 0 sm 1 warp 2 lane 3
[Switching focus to CUDA kernel 1, grid 2, block (8,0,0), thread
(67,0,0), device 0, sm 1, warp 2, lane 3]
374 int totalThreads = gridDim.x * blockDim.x;
至于thread和block,切换的时候加括号(),用来区分x,y,z轴
(cuda-gdb) cuda thread (15,0,0)
[Switching focus to CUDA kernel 1, grid 2, block (8,0,0), thread
(15,0,0), device 0, sm 1, warp 0, lane 15]
374 int totalThreads = gridDim.x * blockDim.x;
也支持一起切换block和thread
(cuda-gdb) cuda block 1 thread 3
[Switching focus to CUDA kernel 1, grid 2, block (1,0,0), thread (3,0,0),
device 0, sm 3, warp 0, lane 3]
374 int totalThreads = gridDim.x * blockDim.
具体的列表参考一下原文(10.3):
`devices` information about all the devices
`sms` information about all the active SMs in the current device
`warps` information about all the active warps in the current SM
`lanes` information about all the active lanes in the current warp
`kernels` information about all the active kernels
`blocks` information about all the active blocks in the current kernel
`threads` information about all the active threads in the current kernel
`launch trace` information about the parent kernels of the kernel in focus
`launch children` information about the kernels launched by the kernels in focus
`contexts` information about all the contexts(上下文环境 这一点具体可以看文档)
cuda-gdb的独特打印
cuda里面某些变量是独有的,因此cuda-gdb文档里面特别强调了地方.比如寄存器,本地内存,共享内存.threadIdx,blockDim
一下案例用来打印共享内存与共享内存中的偏移
(cuda-gdb) print &array
$1 = (@shared int (*)[0]) 0x20
(cuda-gdb) print array[0]@4
$2 = {0, 128, 64, 192}
(cuda-gdb) print *(@shared int*)0x20
$3 = 0
(cuda-gdb) print *(@shared int*)0x24
$4 = 128
(cuda-gdb) print *(@shared int*)0x28
$5 = 64
下面的示例显示了如何访问 内核的输入参数的起始地址
(cuda-gdb) print &data
$6 = (const @global void * const @parameter *) 0x10
(cuda-gdb) print *(@global void * const @parameter *) 0x10
$7 = (@global void * const @parameter) 0x110000<∕>
关于反汇编和寄存器,可以参考源文档.
cuda异常代码
其实这一段我觉得不应该放在本文里面,不过既然原文有就放下来好了,参考一下.

使用案例
源文档中给了三个案例,第三个是结合openmp的,这里就不给出来,需要的自己参考
案例1 bit reversal
#include <stdio.h>
#include <stdlib.h>
// Simple 8-bit bit reversal Compute test
#define N 256
__global__ void bitreverse(void *data) {
unsigned int *idata = (unsigned int*)data;
extern __shared__ int array[];
array[threadIdx.x] = idata[threadIdx.x];
array[threadIdx.x] = ((0xf0f0f0f0 & array[threadIdx.x]) >> 4) |
((0x0f0f0f0f & array[threadIdx.x]) << 4);
array[threadIdx.x] = ((0xcccccccc & array[threadIdx.x]) >> 2) |
((0x33333333 & array[threadIdx.x]) << 2);
array[threadIdx.x] = ((0xaaaaaaaa & array[threadIdx.x]) >> 1) |
((0x55555555 & array[threadIdx.x]) << 1);
idata[threadIdx.x] = array[threadIdx.x];
}
int main(void) {
void *d = NULL; int i;
unsigned int idata[N], odata[N];
for (i = 0; i < N; i++)
idata[i] = (unsigned int)i;
cudaMalloc((void**)&d, sizeof(int)*N);
cudaMemcpy(d, idata, sizeof(int)*N,
cudaMemcpyHostToDevice);
bitreverse<<<1, N, N*sizeof(int)>>>(d);
cudaMemcpy(odata, d, sizeof(int)*N,
cudaMemcpyDeviceToHost);
for (i = 0; i < N; i++)
printf("%u -> %u\n", idata[i], odata[i]);
cudaFree((void*)d);
return 0;
}
首先编译与运行
$ nvcc -g -G bitreverse.cu -o bitreverse
$ cuda-gdb bitreverse
添加breakpoint并运行
(cuda-gdb) break main
Breakpoint 1 at 0x18e1: file bitreverse.cu, line 25.
(cuda-gdb) break bitreverse
Breakpoint 2 at 0x18a1: file bitreverse.cu, line 8.
(cuda-gdb) break 21
Breakpoint 3 at 0x18ac: file bitreverse.cu, line 21.
(cuda-gdb) run
Starting program: ∕Users∕CUDA_User1∕docs∕bitreverse
Reading symbols for shared libraries
..++........................................................... done
Breakpoint 1, main () at bitreverse.cu:25
25 void *d = NULL; int i;
我们继续执行,这里回到核函数里面
(cuda-gdb) continue
Continuing.
Reading symbols for shared libraries .. done
Reading symbols for shared libraries .. done
[Context Create of context 0x80f200 on Device 0]
[Launch of CUDA Kernel 0 (bitreverse<<<(1,1,1),(256,1,1)>>>) on Device 0]
Breakpoint 3 at 0x8667b8: file bitreverse.cu, line 21.
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (0,0,0), device
,→0, sm 0, warp 0, lane 0]
Breakpoint 2, bitreverse<<<(1,1,1),(256,1,1)>>> (data=0x110000) at bitreverse.cu:9
9 unsigned int *idata = (unsigned int*)data;
现在我们切换观察

我们现在打印threadid和blockdim
(cuda-gdb) print blockIdx
$1 = {x = 0, y = 0}
(cuda-gdb) print threadIdx
$2 = {x = 0, y = 0, z = 0)
(cuda-gdb) print gridDim
$3 = {x = 1, y = 1}
(cuda-gdb) print blockDim
$4 = {x = 256, y = 1, z = 1)
继续运行并且打印一些函数

删除观测点并退出
(cuda-gdb) delete breakpoints
Delete all breakpoints? (y or n) y
(cuda-gdb) continue
Continuing.
Program exited normally.
(cuda-gdb)
案例2 单步执行
#define NUM_BLOCKS 8
#define THREADS_PER_BLOCK 64
__global__ void example(int **data) {
int value1, value2, value3, value4, value5;
int idx1, idx2, idx3;
idx1 = blockIdx.x * blockDim.x;
idx2 = threadIdx.x;
idx3 = idx1 + idx2;
value1 = *(data[idx1]);
value2 = *(data[idx2]);
value3 = value1 + value2;
value4 = value1 * value2;
value5 = value3 + value4;
*(data[idx3]) = value5;
*(data[idx1]) = value3;
*(data[idx2]) = value4;
idx1 = idx2 = idx3 = 0;
}
int main(int argc, char *argv[]) {
int *host_data[NUM_BLOCKS * THREADS_PER_BLOCK];
int **dev_data;
const int zero = 0;
/* Allocate an integer for each thread in each block */
for (int block = 0; block < NUM_BLOCKS; block++) {
for (int thread = 0; thread < THREADS_PER_BLOCK; thread++) {
int idx = thread + block * THREADS_PER_BLOCK;
cudaMalloc(&host_data[idx], sizeof(int));
cudaMemcpy(host_data[idx], &zero, sizeof(int),
cudaMemcpyHostToDevice);
}
}
/* This inserts an error into block 3, thread 39*/
host_data[3*THREADS_PER_BLOCK + 39] = NULL;
/* Copy the array of pointers to the device */
cudaMalloc((void**)&dev_data, sizeof(host_data));
cudaMemcpy(dev_data, host_data, sizeof(host_data), cudaMemcpyHostToDevice);
/* Execute example */
example <<< NUM_BLOCKS, THREADS_PER_BLOCK >>> (dev_data);
cudaThreadSynchronize();
}
摆烂了,自己看原文





![[Java]面向对象高级篇](https://img-blog.csdnimg.cn/fdacd94b6b564c7d8a7c7a8df5f933e1.png)