基于Scrapy框架实现多级页面数据抓取
前言
本文中介绍 如何基于 Scrapy 框架实现多级页面数据的抓取,并以抓取汽车之家二手车数据为例进行讲解。
正文
在介绍如何基于 Scrapy 框架实现多级页面数据的抓取之前,先介绍下 Scrapy 框架的请求对象 request 和响应对象 response。
1、请求对象request属性及方法
- request.url:请求的 url 地址
- request.headers:请求头-字典格式
- request.meta:解析函数间 item 数据传递,定义代理
- request.cookies:Cookie 参数
2、响应对象response属性及方法
- response.url:返回实际数据的 url 地址
- response.text:响应内容-字符串格式
- response.body:响应内容-字符串格式
- response.encoding:响应字符编码
- response.status:HTTP响应码
3、请求对象request的meta参数
meta 参数:在不同的解析函数之间传递数据。
在执行 scrapy.Request() 方法时把一些回调函数中需要的数据传进去,meta 必须是一个字典,在下一个函数中可以使用 response.meta 进行访问,meta 会随着 response 响应对象一起回来,作为response 的一个属性。
注意:meta 传递的数据是浅拷贝传递的,如果传递的数据是可变的数据类型,那么很容易造成数据不对应的错误。
利用 mata 参数在不同的解析函数间传递数据:如有需要继续交给调度器的请求,则创建新的 item 对象。
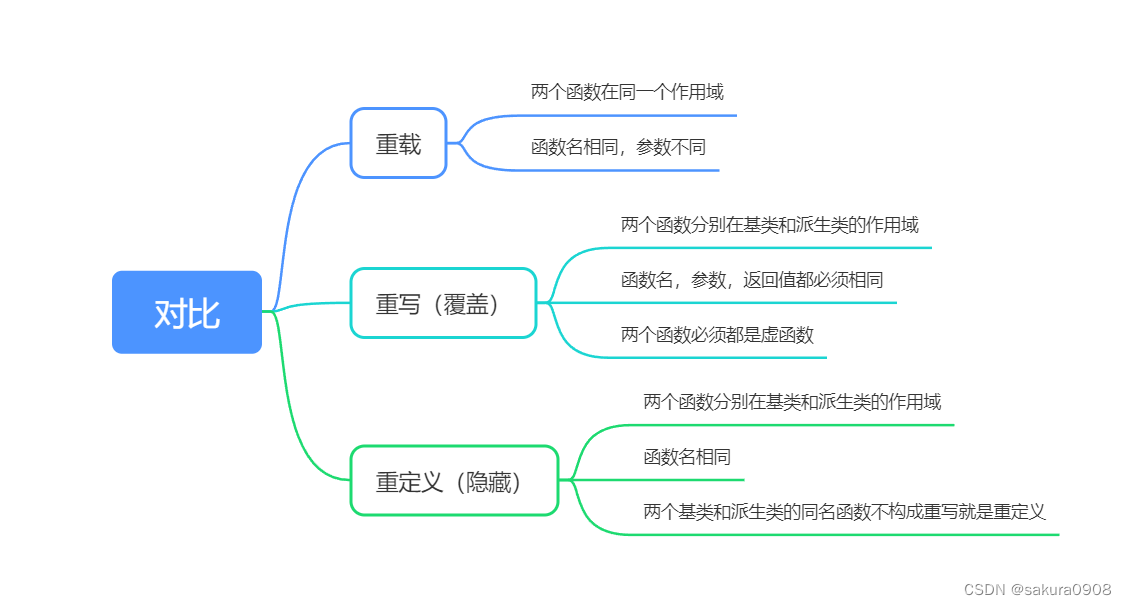
4、基于Scrapy框架实现多级页面数据抓取
多级页面抓取的注意事项:
- 多级页面,数据不能直接提交给管道;
- 通过 meta 参数传递的数据是浅拷贝传递的,如果传递的数据是可变的数据类型,那么很容易造成数据不对应的错误;
- 针对 meta 参数传递数据不对应的的解决方法:传递多个参数。
案例详情:
这里参考 【Python_Scrapy学习笔记(六)】Scrapy框架基本使用流程 里的案例,并在此案例基础之上升级。
-
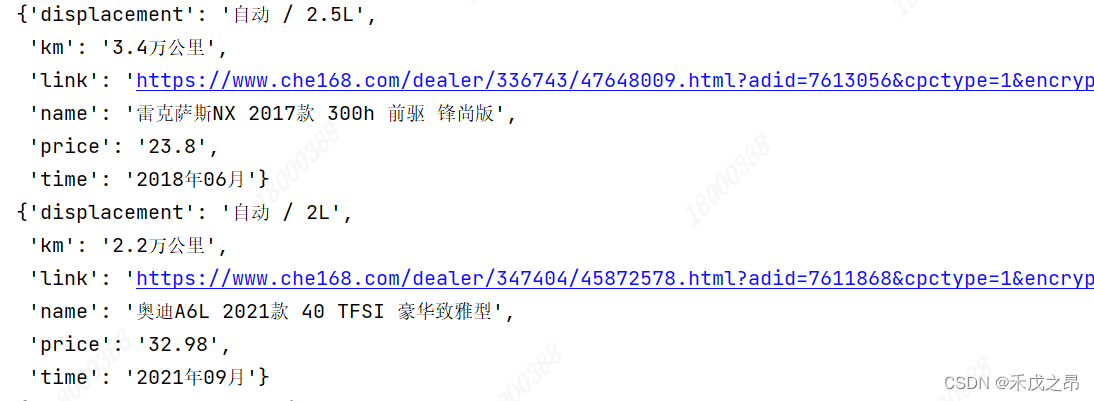
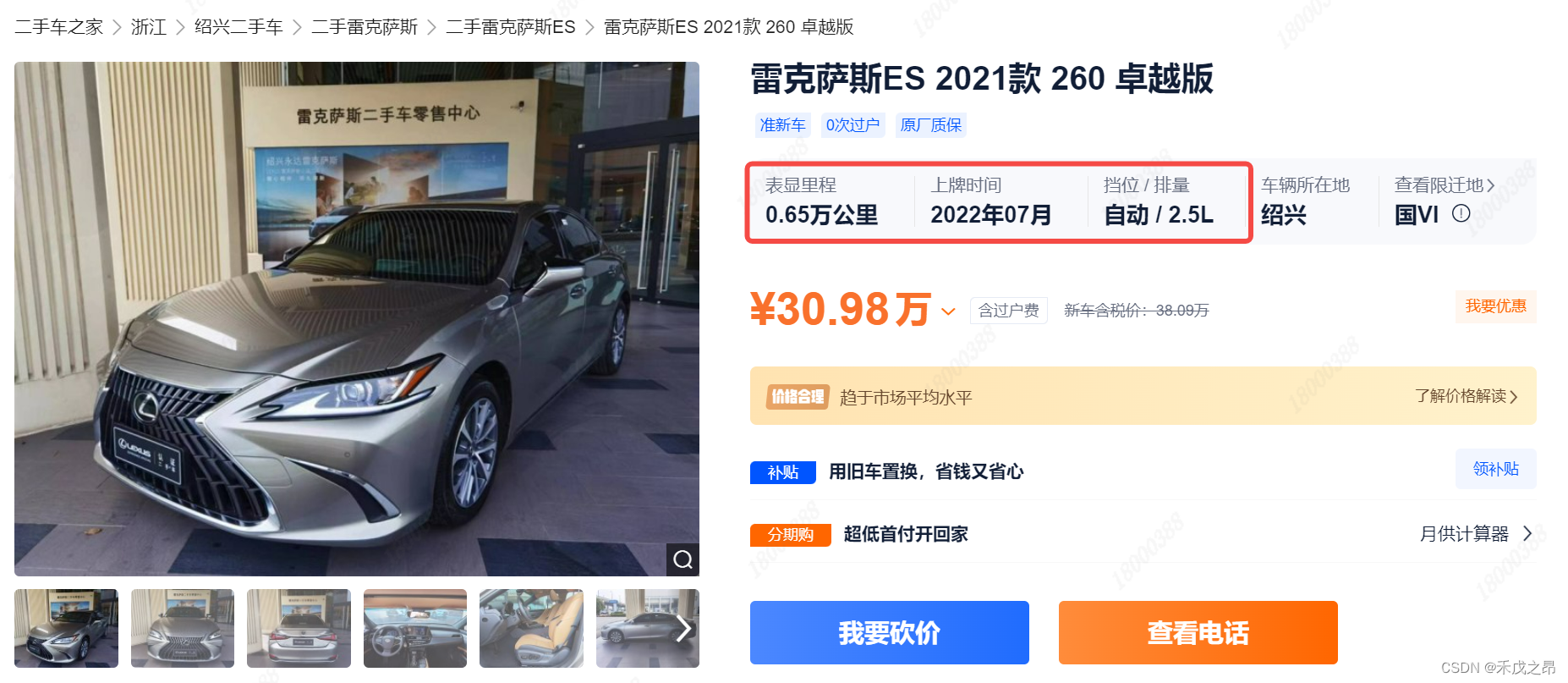
需求梳理:二级页面要爬取表显里程、上牌时间、排量
-
整体思路:梳理要改写的 py 文件
- items.py:定义所有要抓取的数据结构
- car.py:将详情页链接继续交给调度器队列
- pipelines.py:处理全部汽车信息的item对象
-
item.py:定义所有要抓取的数据结构,增加要爬取的三个字段
import scrapy class CarspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 汽车的名称、价格、和详情页链接,相当于定义了一个字典,只赋值了key,未赋值value name = scrapy.Field() price = scrapy.Field() link = scrapy.Field() # 表显里程、上牌时间、排量 time = scrapy.Field() km = scrapy.Field() displacement = scrapy.Field() -
car.py:将详情页链接继续交给调度器队列,通过 meta 参数传递数据
import scrapy from ..items import CarspiderItem class CarSpider(scrapy.Spider): name = "car" allowed_domains = ["www.che168.com"] # i = 1 # 1、删除掉 start_urls 变量 # start_urls = ["https://www.che168.com/china/a0_0msdgscncgpi1ltocsp1exx0/"] # 从第一页开始 def start_requests(self): """ 2、重写 start_requests() 方法:一次性生成所有要抓取的url地址,并一次性交给调度器入队列 :return: """ for i in range(1, 3): url = "https://www.che168.com/china/a0_0msdgscncgpi1ltocsp{}exx0/".format(i) # 交给调度器入队列,并指定解析函数 yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): item = {} # 先写基准xpath //body/div/div/ul/li li_list = response.xpath("//body/div/div/ul[@class='viewlist_ul']/li") for li in li_list: item["name"] = li.xpath("./@carname").get() item["price"] = li.xpath("./@price").get() if li.xpath("./a/@href").get().find('/dealer') == 0: item["link"] = "https://www.che168.com" + li.xpath("./a/@href").get() else: item["link"] = "https://" + li.xpath("./a/@href").get()[2:] # 此时把每个详情页的链接交给调度器入队列 yield scrapy.Request(url=item["link"], meta={'k1': item['name'], 'k2': item['price'], 'k3': item['link']}, callback=self.get_car_info) # meta传递的数据是浅拷贝传递的,如果传递的数据是可变的数据类型,那么很容易造成数据不对应的错误。 # 当scrapy用请求对象发送请求并将返回结果给下一个解析方法后,接收到的meta里的数据是可以被操作修改的,所以item是会被for循环不断的修改,从而接收到的数据是被修改过后的数据。 # 利用mata参数在不同的解析函数间传递数据:如有需要继续交给调度器的请求,则创建新的item对象 # 解决方法:传递多个参数 # 多级页面,不能直接提交给管道 def get_car_info(self, response): """ function: 提取二级页面的数据 in: out: return: int >0 ok, <0 some wrong others: """ item = CarspiderItem() # 给item.py的CarspiderItem类做实例化 # meta会随着response响应对象一起回来,作为response的一个属性 # item = response.meta["item"] item['name'] = response.meta['k1'] item['price'] = response.meta['k2'] item['link'] = response.meta['k3'] item["time"] = response.xpath(".//div[@class='car-box']/ul/li[2]/h4/text()").get() item["km"] = response.xpath(".//div[@class='car-box']/ul/li[1]/h4/text()").get() item["displacement"] = response.xpath(".//div[@class='car-box']/ul/li[3]/h4/text()").get() yield item -
pipelines.py:处理全部汽车信息的item对象
class CarspiderPipeline: def process_item(self, item, spider): print(item) # 这里只做打印处理 return item -
运行效果