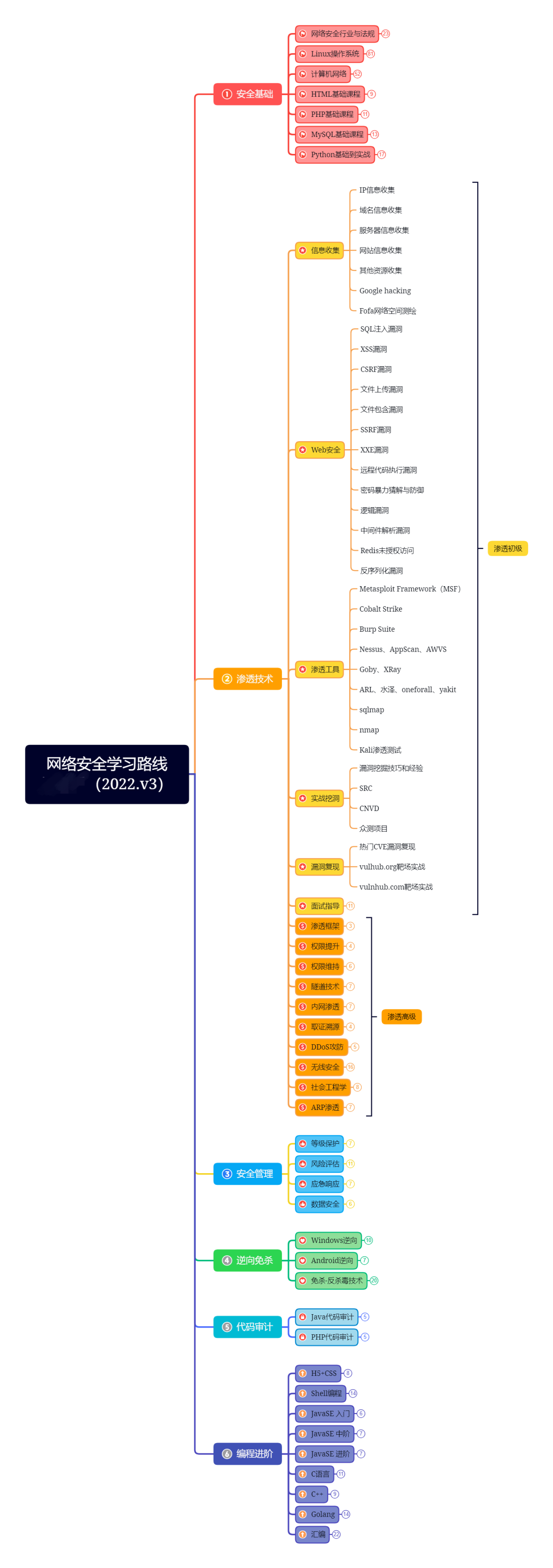
机器学习:基于KNN对葡萄酒质量进行分类
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 订阅专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价 |
| 机器学习:基于神经网络对用户评论情感分析预测 |
| 机器学习:朴素贝叶斯模型算法原理(含实战案例) |
| 机器学习:逻辑回归模型算法原理(附案例实战) |
| 机器学习:基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习:基于逻辑回归对超市销售活动预测分析 |
文章目录
- 机器学习:基于KNN对葡萄酒质量进行分类
- 一、实验简介
- 二、数据说明
- 三、实验环境
- 四、加载数据
- 五、定义高质量红酒
- 六、转换数据
- 七、划分数据集
- 八、数据归一化
- 九、建立KNN分类模型
- 十、选择最优K
- 十一、将最好的KNN分类器应用于test set上
- 总结
一、实验简介
该数据集采集于葡萄牙北部“Vinho Verde”葡萄酒,由于隐私和物流问题,只有理化变量特征是可以进行使用的(例如,数据集中没有关于葡萄品种、葡萄酒品牌、葡萄酒销售价格等的数据)。本篇notebook使用了红葡萄酒质量的数据集,并用KNN进行分类模型的训练。
二、数据说明
文件列表
该数据集包含四个文件
- winequality-red.csv:红葡萄酒质量数据
- winequality-white.csv:白葡萄酒质量数据
- white_train.csv:白葡萄酒质量训练集数据(target label: good_or_not, 即quality>5的样本都为品质好的葡萄酒)
- white_test.csv:白葡萄酒质量测试集数据(without target label)
三、实验环境
Python 3.9
Anaconda
Jupyter Notebook
四、加载数据
加载模块
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
加载数据
df = pd.read_csv("./input/winequality/winequality-red.csv")
df.head()

查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(df.shape[0],df.shape[1]))
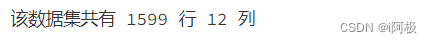
查看特征值和空值
df.isnull().any()

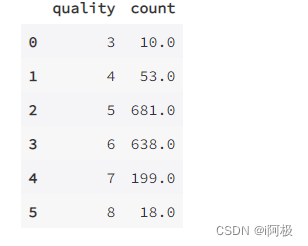
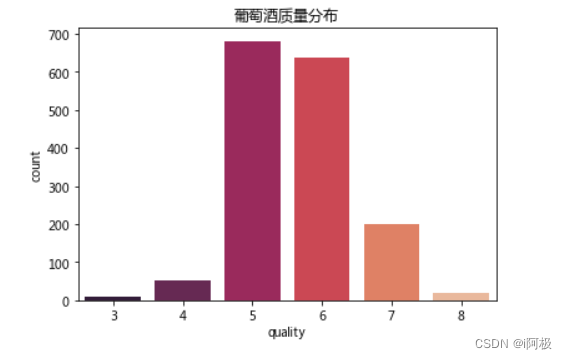
查看葡萄酒质量情况分布
score = df.groupby("quality").agg({"fixed acidity": lambda x: len(x)})
score = score.reset_index()
score.columns = ["quality","count"]
score
sns.barplot(x = 'quality', y = 'count', data = score, palette="rocket").set_title("葡萄酒质量分布")
plt.show()
五、定义高质量红酒
我们将评分为6分及以上的红酒定义为高质量红酒。
本研究的目的是建立KNN模型,区分“高质量红酒”与非“高质量红酒”,是一个二元分类问题。
df["GoodWine"] = df.quality.apply(lambda x: 1 if x >=6 else 0)
df["GoodWine"].head()

六、转换数据
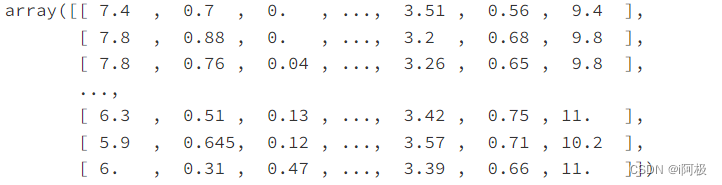
SciKit-Learn接受NumPy Arrays形式的输入,因此我们把11个特征(features)和分类标签(classification label)改成NumPy Arrays的形式。
#特征
X = np.array(df[df.columns[:11]])
X
#分类标签
y = np.array(df.GoodWine)
y
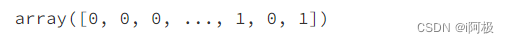
七、划分数据集
我们有1599行数据,按照70%和30%将数据集分为training set和test set。
from sklearn.model_selection import train_test_split
X_train_unproc, X_test_unproc, y_train, y_test = train_test_split(X,y,test_size = 0.3)
X_train_unproc
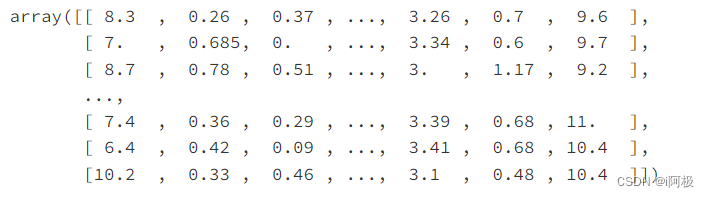
八、数据归一化
因为KNN模型对数据的缩放(scaling)很敏感,我们根据training set数据进行归一化,并把同样的转换加诸于test set上。这样能够确保每个特征对KNN模型的影响力一样大。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train_unproc)
X_train = scaler.transform(X_train_unproc)
X_test = scaler.transform(X_test_unproc)
X_train
九、建立KNN分类模型
KNN算法主要考虑三个重要要素:
- K值的选择
- 距离度量的方式
- 分类决策规则
在这里,我们先给k值选择一个较小的值,然后通过交叉验证选择一个合适k值。
假定k = 3,建立一个KNN分类器,并查看其准确率。
from sklearn.neighbors import KNeighborsClassifier
#初始化
k = 3
clf = KNeighborsClassifier(k)
#使用training set训练模型
clf.fit(X_train, y_train)

# training set正确率
print("训练集正确率:{}%".format(round(clf.score(X_train, y_train)*100,2)))

交叉验证
# cross validation正确率
from sklearn import model_selection as cv
scores = cv.cross_val_score(clf, X_train, y_train, cv = 5)
score = scores.mean()
print("交叉验证正确率:{}%".format(round(score*100, 2)))

十、选择最优K
我们使用交叉验证(cross validation)选择最好的k,使得KNN分类器在未来的数据上有最好的表现。
这里我们尝试了k = 1,2,3,…100。
# selecting the best k
ks = range(1,100)
inSampleScores = []
crossValidationScores = []
d = {} #key = k, value = cv accuracy rate
for k in ks:
clf = KNeighborsClassifier(k).fit(X_train, y_train)
inSampleScores.append(clf.score(X_train, y_train))
scores = cv.cross_val_score(clf, X_train, y_train, cv = 5)
crossValidationScores.append(scores.mean())
d[k] = scores.mean()
# 画图
import matplotlib.pyplot as plt
p1 = plt.plot(ks, inSampleScores)
p2 = plt.plot(ks, crossValidationScores)
plt.legend(["train正确率", "cv正确率"])
plt.show()
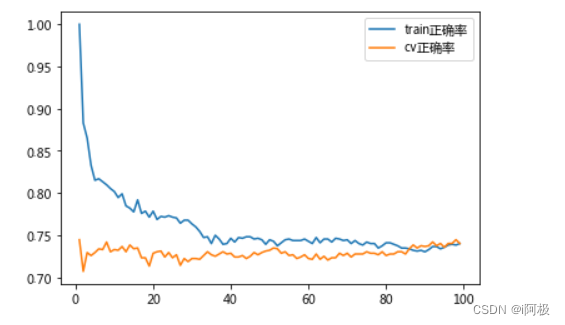
# 选择最好的k
best_k = sorted(d.items(), key = lambda x:x[1], reverse = True)[0][0]
print("最优的k值:{}".format(best_k))

十一、将最好的KNN分类器应用于test set上
#建模
clf = KNeighborsClassifier(best_k).fit(X_train, y_train)
#预测
y_test_pred = clf.predict(X_test)
#正确率
print("测试集正确率:{}%".format(round(clf.score(X_test, y_test)*100, 2)))
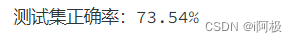
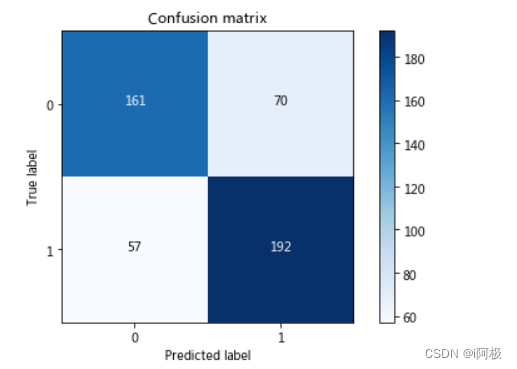
混淆矩阵
# 混淆矩阵 (confusion matrix)
from sklearn.metrics import confusion_matrix
cnf_matrix = confusion_matrix(y_test, y_test_pred)
class_names = [0,1]
plot_confusion_matrix(cnf_matrix , classes=class_names, title='Confusion matrix')
plt.show()
评估报告
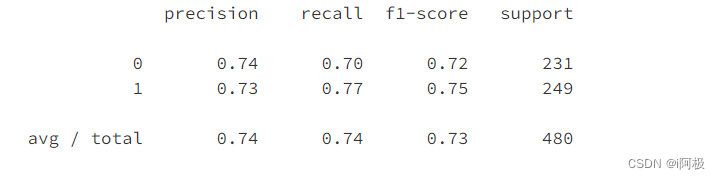
from sklearn.metrics import classification_report
print(classification_report(y_test, y_test_pred))
总结
可以从以下几个方面来探索葡萄酒质量数据:
- 葡萄酒质量的分布情况如何?
- 如何根据现有数据预测新的葡萄酒的质量?
- 是否所有理化特征都与葡萄酒的质量相关?
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗
![[网络安全] Windows Server 设置文件屏蔽防止黑客利用漏洞上传特定类型的非法文件](https://img-blog.csdnimg.cn/d4813e667de34d62bf9f376d52f80adc.png)