整理来自yolov8官方文档常用的一些命令行参数,官方文档YOLOv8 Docs
yolov8命令行的统一运行格式为:
yolo TASK MODE ARGS
其中主要是三部分传参:
- TASK(可选) 是[detect、segment、classification]中的一个。如果没有显式传递,YOLOv8将尝试从模型类型中猜测TASK。
- MODE(必选) 是[train, val, predict, export]中的一个
- ARGS(可选) 是任意数量的自定义arg=value对,如imgsz=320,覆盖默认值。
一、训练参数
训练命令行示例:
# 从YAML中构建一个新模型,并从头开始训练
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640# 从预先训练的*.pt模型开始训练
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640# 从YAML中构建一个新的模型,将预训练的权重传递给它,并开始训练
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
对应python代码示例:
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.yaml') # 从YAML中构建一个新模型
model = YOLO('yolov8n.pt') #加载预训练的模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML构建并传递权重# Train the model
model.train(data='coco128.yaml', epochs=100, imgsz=640)
一些比较常用的传参:
model 传入的model.yaml文件或者model.pt文件,用于构建网络和初始化,不同点在于只传入yaml文件的话参数会随机初始化
data 训练数据集的配置yaml文件
epochs 训练轮次,默认100
patience 早停训练观察的轮次,默认50,如果50轮没有精度提升,模型会直接停止训练
batch 训练批次,默认16
imgsz 训练图片大小,默认640
save 保存训练过程和训练权重,默认开启
save_period 训练过程中每x个轮次保存一次训练模型,默认-1(不开启)
cache 是否采用ram进行数据载入,设置True会加快训练速度,但是这个参数非常吃内存,一般服务器才会设置
device 要运行的设备,即cuda device =0或Device =0,1,2,3或device = cpu
workers 载入数据的线程数。windows一般为4,服务器可以大点,windows上这个参数可能会导致线程报错,发现有关线程报错,可以尝试减少这个参数,这个参数默认为8,大部分都是需要减少的
project 项目文件夹的名,默认为runs
name 用于保存训练文件夹名,默认exp,依次累加
exist_ok 是否覆盖现有保存文件夹,默认Flase
pretrained 是否加载预训练权重,默认Flase
optimizer 优化器选择,默认SGD,可选[SGD、Adam、AdamW、RMSProP]
verbose 是否打印详细输出
seed 随机种子,用于复现模型,默认0
deterministic 设置为True,保证实验的可复现性
single_cls 将多类数据训练为单类,把所有数据当作单类训练,默认Flase
image_weights 使用加权图像选择进行训练,默认Flase
rect 使用矩形训练,和矩形推理同理,默认False
cos_lr 使用余弦学习率调度,默认Flase
close_mosaic 最后x个轮次禁用马赛克增强,默认10
resume 断点训练,默认Flase
lr0 初始化学习率,默认0.01
lrf 最终学习率,默认0.01
label_smoothing 标签平滑参数,默认0.0
dropout 使用dropout正则化(仅对训练进行分类),默认0.0
数据增强参数:
更多参数参考:modes/train
二、评估参数
评估命令行代码示例:
yolo detect val model=yolov8n.pt # val 官方模型
yolo detect val model=path/to/best.pt # val 自己训练的模型
对应的python代码:
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') #加载官方模型
model = YOLO('path/to/best.pt') # 加载自己训练的模型# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
一些比较常用的传参:
model 需要评估的pt模型文件路径
data 需要评估的数据集yaml文件
imgsz 评估图片推理大小,默认640
batch 评估推理批次,默认16
save_json 是否保存评估结果为json输出,默认False
save_hybrid 是否保存混合版本的标签(标签+额外的预测)
conf 模型评估置信度阈值,默认0.001
iou 模型评估iou阈值,默认0.6
max_det 单张图最大检测目标数量,默认300
half 是否使用fp16推理,默认True
device 要运行的设备,即cuda device =0或Device =0,1,2,3或device = cpu
dnn 是否使用use OpenCV DNN for ONNX inference,默认Flase
rect 是否使用矩形推理,默认False
split 数据集分割用于验证,即val、 test、train,默认val
三、推理参数
推理命令行示例:
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
对应python代码示例:
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model# Predict with the model
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image# 目标检测后处理
boxes = results[0].boxes
boxes.xyxy # box with xyxy format, (N, 4)
boxes.xywh # box with xywh format, (N, 4)
boxes.xyxyn # box with xyxy format but normalized, (N, 4)
boxes.xywhn # box with xywh format but normalized, (N, 4)
boxes.conf # confidence score, (N, 1)
boxes.cls # cls, (N, 1)
boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .# 实例分割后处理
masks = results[0].masks # Masks object
masks.segments # bounding coordinates of masks, List[segment] * N
masks.data # raw masks tensor, (N, H, W) or masks.masks # 目标分类后处理
results = model(inputs)
results[0].probs # cls prob, (num_class, )
一些常用传参解释:
source 跟之前的yolov5一致,可以输入图片路径,图片文件夹路径,视频路径
save 保存检测后输出的图像,默认False
conf 用于检测的对象置信阈值,默认0.25
iou 用于nms的IOU阈值,默认0.7
half FP16推理,默认False
device 要运行的设备,即cuda设备=0/1/2/3或设备=cpu
show 用于推理视频过程中展示推理结果,默认False
save_txt 是否把识别结果保存为txt,默认False
save_conf 保存带有置信度分数的结果 ,默认False
save_crop 保存带有结果的裁剪图像,默认False
hide_label 保存识别的图像时候是否隐藏label ,默认False
hide_conf 保存识别的图像时候是否隐藏置信度,默认False
vid_stride 视频检测中的跳帧帧数,默认1
classes 展示特定类别的,根据类过滤结果,即class=0,或class=[0,2,3]
line_thickness 目标框中的线条粗细大小 ,默认3
visualize 可视化模型特征 ,默认False
augment 是否使用数据增强,默认False
agnostic_nms 是否采用class-agnostic NMS,默认False
retina_masks 使用高分辨率分割掩码,默认False
max_det 单张图最大检测目标,默认300
box 在分割人物中展示box信息,默认True
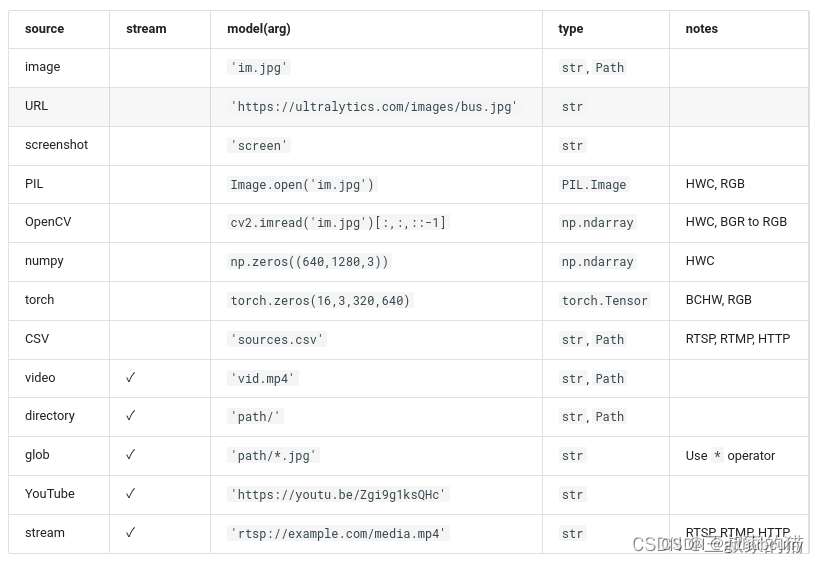
yolov8支持各种输入源推理:
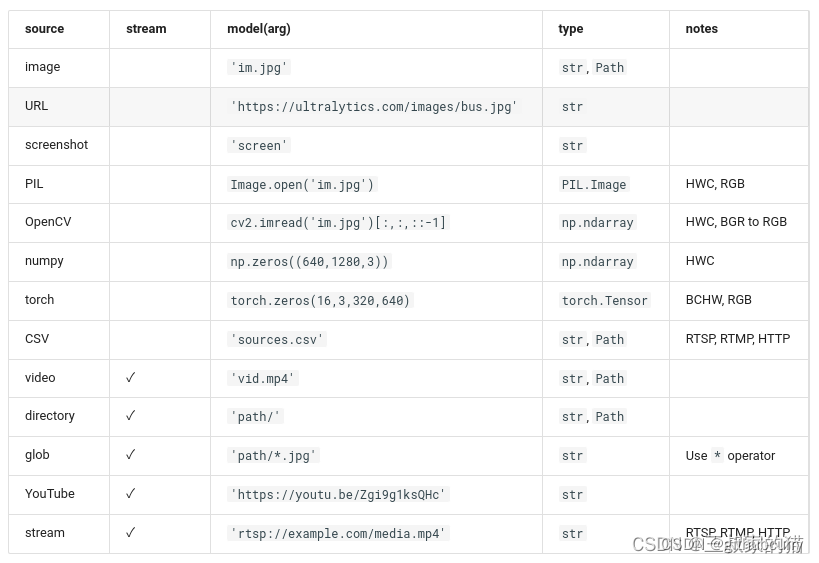
对于图片还支持以下保存格式的输入图片:
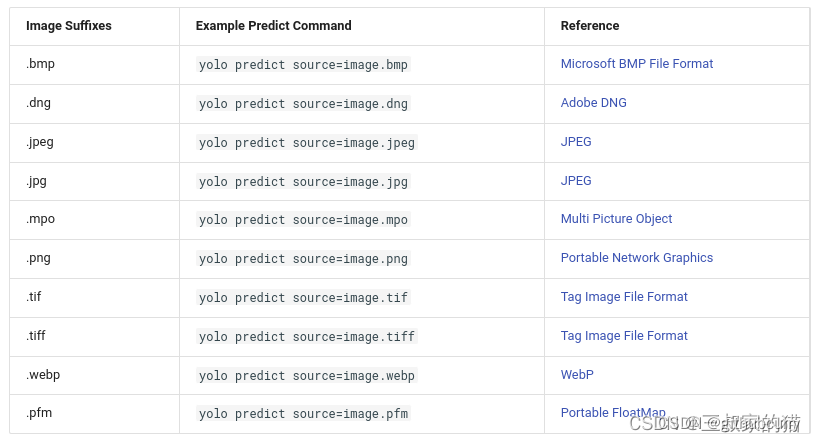
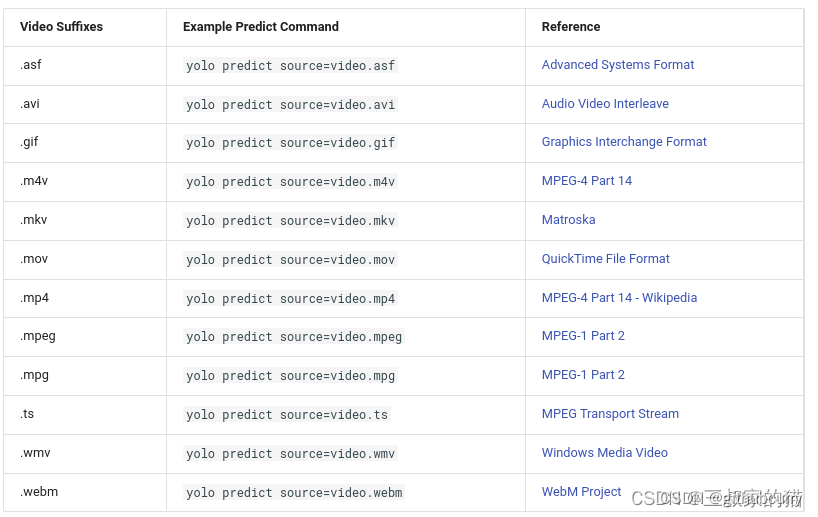
对于视频支持以下视频格式输入:
返回的result结果解析:
Results.boxes: 目标检测返回的boxes信息
Results.masks: 返回的分割mask坐标信息
Results.probs: 分类输出的类概率
Results.orig_img: 原始图像
Results.path: 输入图像的路径
result可以使用如下方法在加载到cpu或者gpu设备中:
results = results.cuda()
results = results.cpu()
results = results.to(“cpu”)
results = results.numpy()
更多细节:modes/predict
四、模型导出
yolov8支持一键导出多种部署模型,支持如下格式的模型导出:

命令行运行示例:
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
python代码示例:
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained# Export the model
model.export(format='onnx')
一些常用参数解释:
format 导出的格式,默认’torchscript’,可选如上支持的格式 onnx、engine、openvino等
imgsz 导出时固定的图片推理大小,为标量或(h, w)列表,即(640,480) ,默认640
keras 使用Keras导出TF SavedModel ,用于部署tensorflow模型,默认False
optimize 是否针对移动端对TorchScript进行优化
half fp16量化导出,默认False
int8 int8量化导出,默认False
dynamic 针对ONNX/TF/TensorRT:动态推理,默认False
simplify onnx simplify简化,默认False
opset onnx的Opset版本(可选,默认为最新)
workspace TensorRT:工作空间大小(GB),默认4
nms 导出CoreML,添加NMS
更多参考:modes/export
五、跟踪参数
yolov8目前支持:BoT-SORT、ByteTrack两种目标跟踪,默认使用BoT-SORT
命令行使用示例:
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
yolo track model=yolov8n-seg.pt source=... # official segmentation model
yolo track model=path/to/best.pt source=... # custom model
yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
python代码使用示例:
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load an official detection model
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
model = YOLO('path/to/best.pt') # load a custom model# Track with the model
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
同时支持检测和分割模型,只需要加载相应权重即可。
跟踪的传参和推理时一样,主要有三个:conf、 iou、 show
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show# orfrom ultralytics import YOLOmodel = YOLO('yolov8n.pt')
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
也可以自定义修改跟踪配置文件,需要修改ultralytics/tracker/cfg中的yaml文件,修改你需要的配置(除了跟踪器类型),同样的运行方式:
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'# orfrom ultralytics import YOLOmodel = YOLO('yolov8n.pt')
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
六、基准测试参数
基准测试模式用于分析YOLOv8各种导出格式的速度和准确性。基准测试提供了关于导出格式的大小、其mAP50-95指标(用于对象检测和分割)或精度top5指标(用于分类)的信息,以及在各种导出格式(如ONNX、OpenVINO、TensorRT等)中,每张图像的推断时间(以毫秒为单位)。这些信息可以帮助用户根据他们对速度和准确性的需求,为他们的特定用例选择最佳的导出格式。
命令行代码示例:
yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
python代码示例:
from ultralytics.yolo.utils.benchmarks import benchmark# Benchmark
benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
一些基准测试常用参数:
model 模型文件路径,yoloV8v.pt等
imgsz 基准测试图片大小,默认640
half 基准测试是否开启fp16,默认False
device 在哪些设备上测试cuda device=0 or device=0,1,2,3 or device=cpu
hard_fail 在错误(bool)或val下限阈值(float)时停止继续,默认False
基准测试可以支持以下导出的格式上运行测试:

更多参考:modes/benchmark








![逆向-还原代码之(*point)[4]和char *point[4] (Arm 64)](https://img-blog.csdnimg.cn/6f18117212bb497e9da652d1e8f172d2.png)


![洛谷P8772 [蓝桥杯 2022 省 A] 求和 C语言/C++](https://img-blog.csdnimg.cn/aa90339fa213408d915c6e1208818890.png)