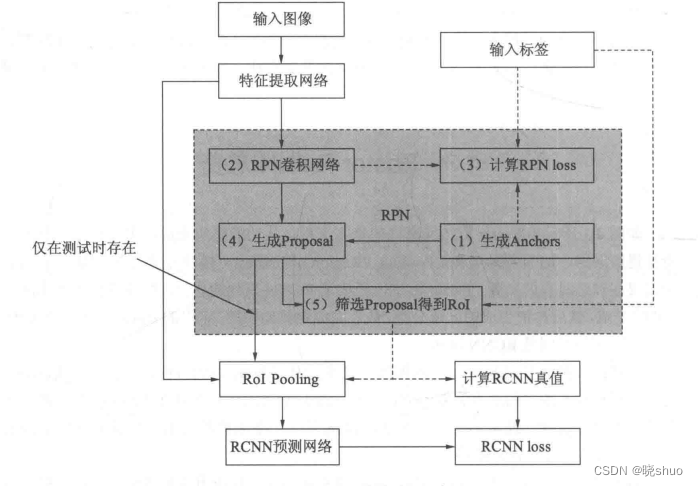
BCEWithLogitsLoss是一种用于二分类问题的损失函数,它将Sigmoid函数和二元交叉熵损失结合在一起。
假设我们有一个大小为
N
N
N的二分类问题,其中每个样本
x
i
x_i
xi有一个二元标签
y
i
∈
0
,
1
y_i\in {0,1}
yi∈0,1,并且我们希望预测每个样本的概率为
p
i
∈
[
0
,
1
]
p_i\in [0,1]
pi∈[0,1]。则BCEWithLogitsLoss可以表示为:

其中,
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x) = \frac{1}{1+e^{-x}}
σ(x)=1+e−x1是Sigmoid函数,
log
\log
log是自然对数。在实践中,由于数值计算的稳定性问题,通常使用函数库中提供的BCEWithLogitsLoss函数来计算损失。
p
i
p_i
pi表示样本
x
i
x_i
xi被预测为正例(1)的概率。在二分类问题中,BCEWithLogitsLoss通常用于处理模型输出的logits(即未经过Sigmoid函数激活的输出),通过将logits作为输入,结合Sigmoid函数进行概率估计和损失计算。在计算过程中,BCEWithLogitsLoss会首先对logits进行Sigmoid激活,然后计算预测概率和二元交叉熵损失。
y
i
y_i
yi表示样本
x
i
x_i
xi的真实标签。在二分类问题中,
y
i
y_i
yi通常为0或1,表示样本
x
i
x_i
xi是否属于正例(1)类别。在BCEWithLogitsLoss中,
y
i
y_i
yi用于计算二元交叉熵损失,帮助模型学习将预测结果和真实标签匹配的能力。具体来说,当
y
i
=
1
y_i=1
yi=1时,BCEWithLogitsLoss会惩罚模型的预测值偏离1的程度;当
y
i
=
0
y_i=0
yi=0时,BCEWithLogitsLoss会惩罚模型的预测值偏离0的程度。因此,
y
i
y_i
yi在BCEWithLogitsLoss中是非常重要的一部分。