文章目录
- 一、位图的引入
- 二、位图的实现
- 三、bitset
- 四、位图的应用
- 五、哈希切割
一、位图的引入
我们通过一道面试题来引入位图:
给定40亿个不重复的无符号整数,且没排过序,现在给一个无符号整数,如何快速判断一个数是否在这40亿个数中?
常规的解题思路是排序 + 二分,或者将数据插入到 unordered_map/unordered_set,然后进行查找;但是这两个方法在这里都不行,因为数据量太大了,内存中存放不下;
1G空间大约有10亿字节,这里有40亿个整数,每个整数4个字节,那么一共就是160亿个字节,换算过来大约为16G,而我们的内存空间一般都是4G;如果我们要使用排序+二分,那么就必须开辟一个16G大小的整形数组,这显然是做不到的;而如果排序+二分不行,哈希表就更不行了,因为哈希表中每个桶中还要存放一个指针来指向下一个节点,空间消耗更大。
常规思路不行,我们就换一种思路 – 题目只要求我们判断一个数在不在,并没有其他要求,所以我们完全不用将这些数存储下来,只需要对它们进行标记即可;而要标记一个数只需要一个比特位,如果二进制比特位为1,代表存在,为0代表不存在。
所谓位图,就是用比特位来存放某种状态,适用于在海量数据中判断某一数据是否存在的场景;实际上位图是哈希表直接映射法的一种变形。
二、位图的实现
在有了具体思路之后,位图的实现就变得很简单了;一般来说,对于位图我们只需要提供如下三个接口即可:
- set:用于将某一数值对应的比特位置1,即标记 (插入) 数据;
- reset:用于将某一数值对应的比特位置0,即取消标记 (删除);
- test:用于测试某一数值对应的比特位是否为1,即查找数据。
代码实现如下:
#pragma once
#include <vector>
using std::vector;
namespace thj {
template<size_t N>
class bitset {
public:
bitset() {
_bs.resize(N / 8 + 1, 0);
}
void set(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
_bs[i] |= (1 << j);
}
void reset(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
_bs[i] &= ~(1 << j);
}
bool test(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
return _bs[i] & (1 << j);
}
private:
vector<char> _bs;
};
}
其中,模板参数 N 是给定的 数据的范围 (特别注意这里N不是数据的个数),因为C++中最小的数据类型是 char,占一个字节的空间,而一个字节中有8个比特位,可以标识8个元素,所以在构造函数中我们将 vector resize 到 N/8+1 即可,这里加1是因为 C++ 中的除法是整数除法,即直接舍弃余数,所以我们需要多开辟一个字节的空间。
注:我们也可以将 vector 的数据类型定义为 int,这样我们开辟空间时 reseize 到 N/32+1 即可。
对于 set、reset 和 reset 函数,目标值 x/8 可以得到 x 应该被映射到哪个下标,即第几个 char,x%8 可以得到 x 应该被映射到该下标的第几个比特位,然后再将对应下标的对应比特位置1或置0即可。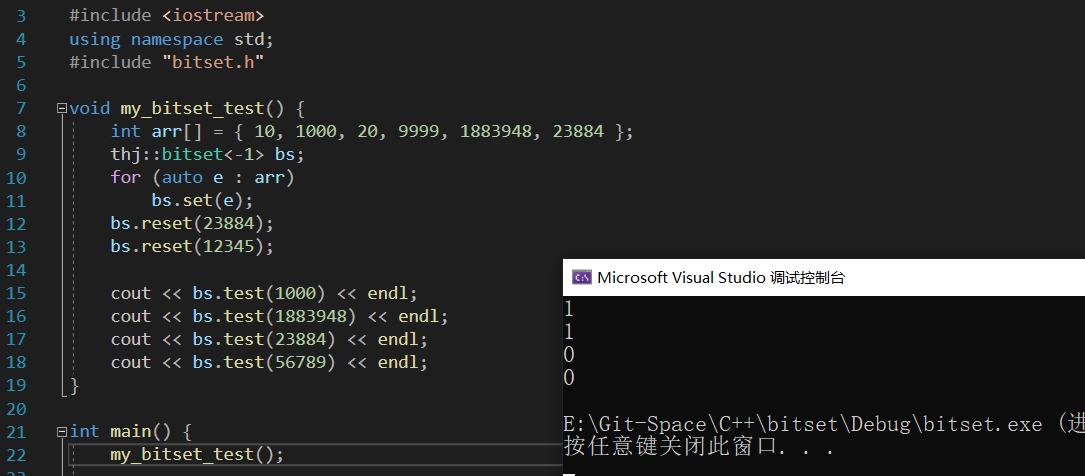
有了位图之后,我们就可以解决上面的面试题了 – 由于题目中只说明了数据是无符号整数,而并没有给出具体的数据范围,所以我们可以将 N 定义为 -1 (有符号的 -1 等于无符号的最大值,参考 string 的 npos),然后我们只需要将这 40 亿个元素依次进行 set,最后对目标元素进行 test 即可。
注:无符号数的最大值大约等于42亿9千万,也就是说一共需要这么多个比特位来进行标记,换算过来大约5亿字节,而1G内存大约有10亿字节,所以位图最多占用512M左右的内存,这是现在的一般计算机能够做到的。
三、bitset
C++ 中其实也提供了类似于位图这样的东西,只是 C++ 把它叫做位的集合 – bitset,它的功能比我们自己模拟实现的要更加丰富,不过主要功能比如 set、reset 和 test 都是一样的。
四、位图的应用
位图主要应用于如下几个方面:
- 快速查找某个数据是否在一个集合中;
- 排序和去重;
- 求两个集合的交集、并集;
- 操作系统中磁盘块标记;
对于快速查找某个数据是否在一个集合中,我们上面已经给出了例子,这里我们再给出它的一个变形题:
给定100亿个整数,设计算法找到只出现一次的整数?
我们发现,使用传统的位图并不能解决这个问题,因为位图只能表示在或不在,并不能表示某个数出现了几次;而位图只能表示在或不在是因为位图中一个数据只用一个比特位表示,而一个比特位只能标识两种状态,那么我们可以将两个位图合在一起,使用两个比特位来标识一个数据,而两个比特位一共可以标识四种状态,我们取其中三种即可:
- 00:不在;
- 01:出现一次;
- 10:出现两次及以上。
代码实现如下:
namespace thj {
template<size_t N>
class two_bitset {
public:
void set(size_t x) {
int flag1 = _bs1.test(x);
int flag2 = _bs2.test(x);
00:第一次插入,置为01
if (!flag1 && !flag2)
{
_bs2.set(x);
}
//01:第二次插入,置为10
else if (!flag1 && flag2)
{
_bs1.set(x);
_bs2.reset(x);
}
//10:第三次及以后插入,不动
else {}
}
bool test(size_t x) {
//只有01表示只出现一次,返回true
if (!_bs1.test(x) && _bs2.test(x)) return true;
return false;
}
private:
std::bitset<N> _bs1;
std::bitset<N> _bs2;
};
}
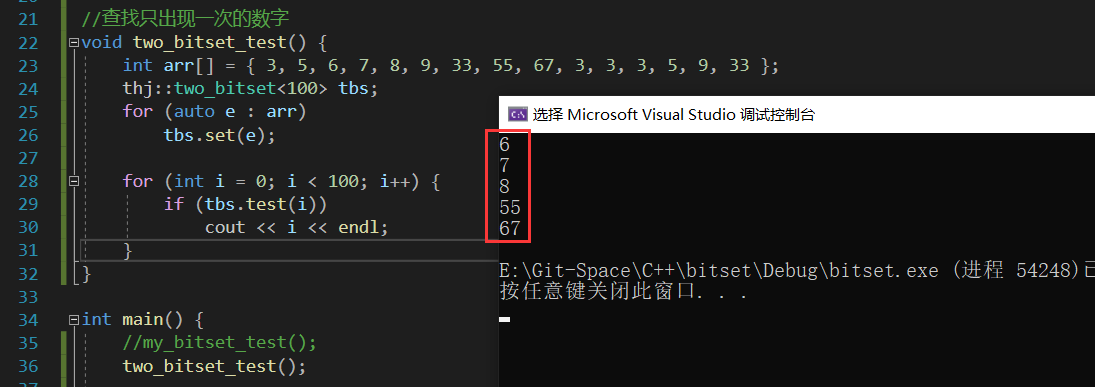
注意:这里题目只说了给100亿个整数,而并没有给出数据的范围,所以我们还是需要将位图的范围定义为无符号数的最大值的,上面将N给为100只是为了方便测试。
位图应用再变形:
1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
这道题和上面求出现一次的数字的思路其实是一样的,只是这里我们要将出现次数为 0次、1次、2次、3次及以上都标识出来而已,所以需要将状态 11 利用起来;这里我就不再给出代码实现,大家可以自己尝试着实现一下。
对于排序和去重,我们可以将待排序的数据按照某种方式转换成二进制位 (比如上面的除和模),然后使用位图来表示这些数据;最后遍历位图,将所有为1的二进制位按照相同的方式转换为对应的数据输出即可;同时,由于位图只能表示存在与不存在两种状态,所以位图天生具有去重功能。
注意:位图适用于数据范围比较集中的场景,如果数据范围比较分散,则应该考虑使用其他的数据结构来实现排序和去重的功能,比如 set 和 map。
对于求两个集合的交集、并集,我们还是以面试题为例:
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
这道题的思路很简单,我们可以先将第一个文件中的数据全部映射到位图中,然后再遍历取出第二个文件中的数据来进行 test 即可,但是这样可能会得到许多重复的结果;所以我们也可以分别将两个文件中的数据映射到两个位图中,然后遍历取出某一个位图中的数据与另一个位图进行 test。
对于操作系统磁盘块标记来说,在操作系统中的文件系统中,文件系统会将磁盘上的空间划分为一个个固定大小的块,每个块都有一个对应的位图位;位图中为0的位表示该块是空闲的,为1的位表示该块已经被分配给某个文件或目录;
当文件系统需要分配一个新的块时,可以在位图中查找第一个为0的位,将其设置为1,并将该块分配给文件;当文件系统需要释放一个块时,可以将该块对应的位图位设置为0,表示该块变为了空闲块,可以被重新分配给其他文件或目录。
五、哈希切割
除了位图,在面试时还常考下面这种题:
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
和上面的题不一样,这道题不能使用位图来解决,因为我们不知道相同IP最多会出现多少次,所以无法确定使用多少个比特位来标识一个数据;
那么既然100G太大内存放不下,我们能不能将这个文件平均分成100份小文件,这样每个文件只有1G大小,此时再依次放进 map 中进行统计呢?答案是也不行,因为再统计下一个小文件之前我们需要将前一个文件的统计结果即 map 中的数据情况,否则还是有可能因为 map 中存放的数据过多导致内存不足,但这样就会导致统计的次数不准,因为我们不能保证相同的IP全部被划分到同一个子文件中去;
正确的解决办法是进行哈希切割 – 先使用字符串哈希函数将IP地址转化为整形,然后再使用除留余数法将100G文件中的IP地址划分到不同的小文件中:
size_t Ai = HashFunc(IP) % 100; //100为小文件的个数
经过哈希切割后,相同的IP一定会被划分到同一个小文件中,因为相同IP结果字符串哈希函数转换得到的整数是相同的,那么模出来的小标位置也是相同的;但是不同的IP也可能会被划分到同一文件中,因为会发生哈希冲突;并且划分的结果有两种:
- 子文件中有多种不同的IP地址,但是子文件大小在1G左右,说明这些IP地址出现的次数不多,此时我们可以直接使用 map 统计出这些IP地址的数量;(所有相同的IP地址一定会出现在同一个子文件中)
- 子文件中有多种不同的IP地址,但是子文件非常大,说明这些IP地址中的某一个/某几个IP地址出现次数非常多,此时 map 统计不下,我们可以换一种字符串哈希函数继续对这个子文件进行哈希切割,即递归子问题解决。
最终出现次数最多的那个IP地址会被全部映射到某一个子文件中,我们对该子文件使用 map 进行统计可以得到其出现的次数。