论文题目(Title):Few-shot Multimodal Sentiment Analysis based on Multimodal Probabilistic Fusion Prompts
研究问题(Question):用概率融合提示进行少样本的情感分析任务
研究动机(Motivation):目前的多模态情感分析研究依赖于大规模的监督数据。整理有监督的数据既费时又费力。因此,研究少镜头多模态情感分析问题是十分必要的。
以前的工作在少镜头模型中一般使用语言模型提示,这可以提高在低资源设置中的性能。但是,文本提示符忽略了来自其他情态的信息。
然而,由于图像编码器是语言不可知的,直接将图像表示形式输入到语言模型中必须面对不同形式之间的差异问题。且不同的提示包含不同数量的信息,单一提示所传达的信息是不够的。
主要贡献(Contribution):
1. 为FMSA任务提出了一种新的多模态概率融合提示(多点)模型;
2. 设计了统一的多模态提示来减少不同模态提示的差异,并设计了概率融合方法来聚合多个多模态提示的预测,以提高模型的鲁棒性。
研究思路(Idea):
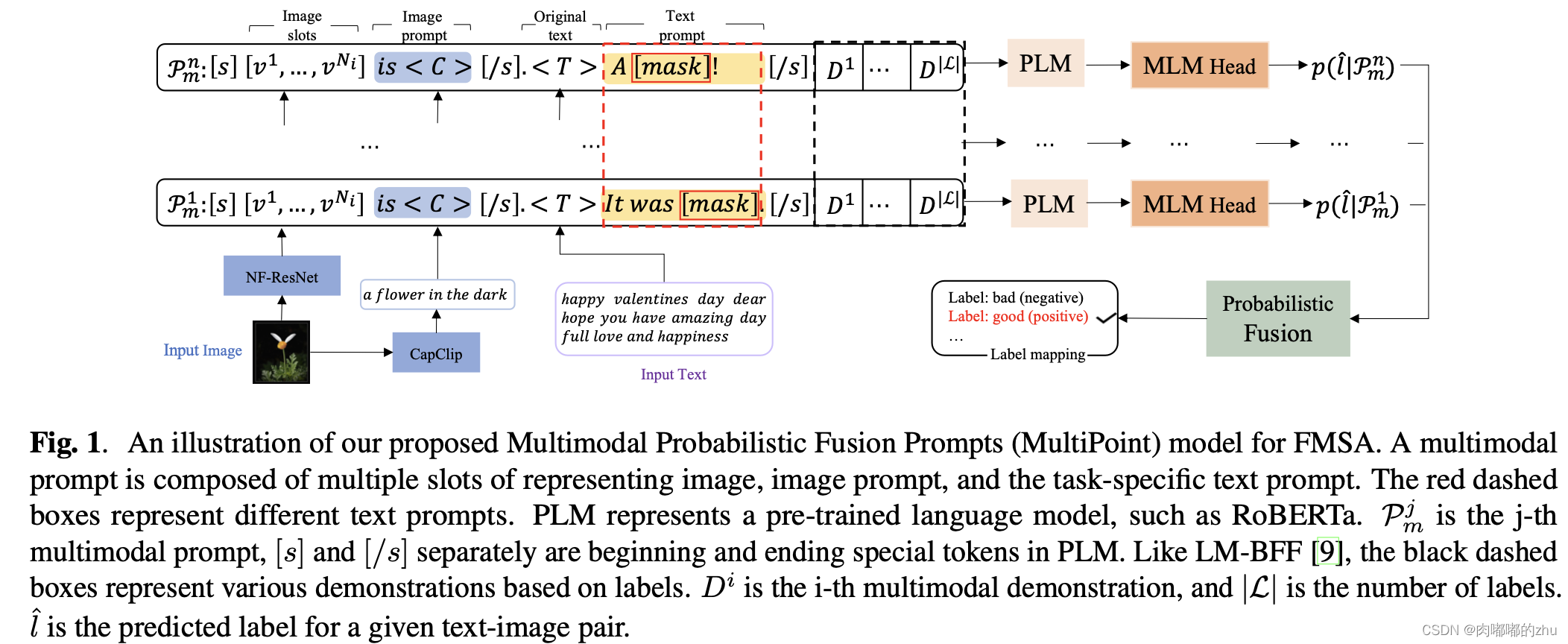
提出了多模态概率融合提示,为多模态情感检测提供多种线索。
首先设计了一个统一的多模态提示符,以减少不同模态提示符之间的差异。为了提高模型的鲁棒性,利用每个输入的多个不同提示,并提出了一种概率方法来融合输出预测。进行了大量实验,在三个数据集上证实了方法的有效性。
研究方法(Method):首先为任务设计多模式提示符。
对于文本模式,利用自动生成模板来获得多个有效的文本提示。
对于图像模态,首先生成每个图像的文本描述,并将其编码为文本提示,以提高图像和文本提示的兼容性。
提出了一种新的概率融合方法来融合来自多模态提示的多个预测。
研究过程(Process):
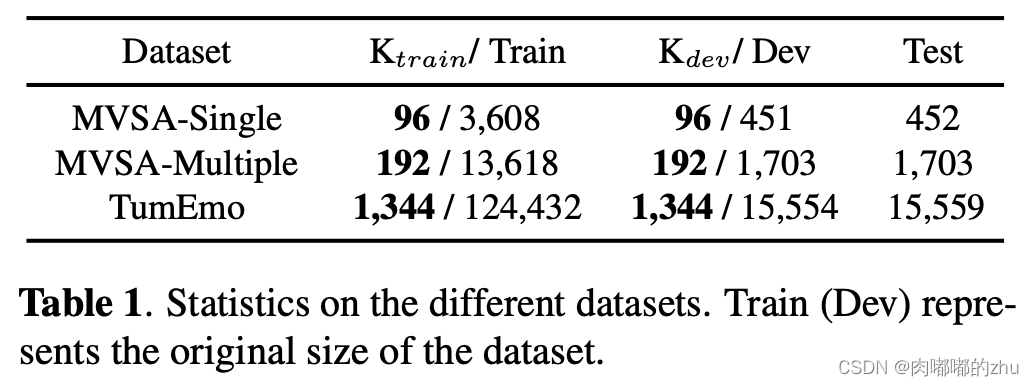
 1.数据集(Dataset)
1.数据集(Dataset)
2.评估指标(Evaluation):Acc,F1
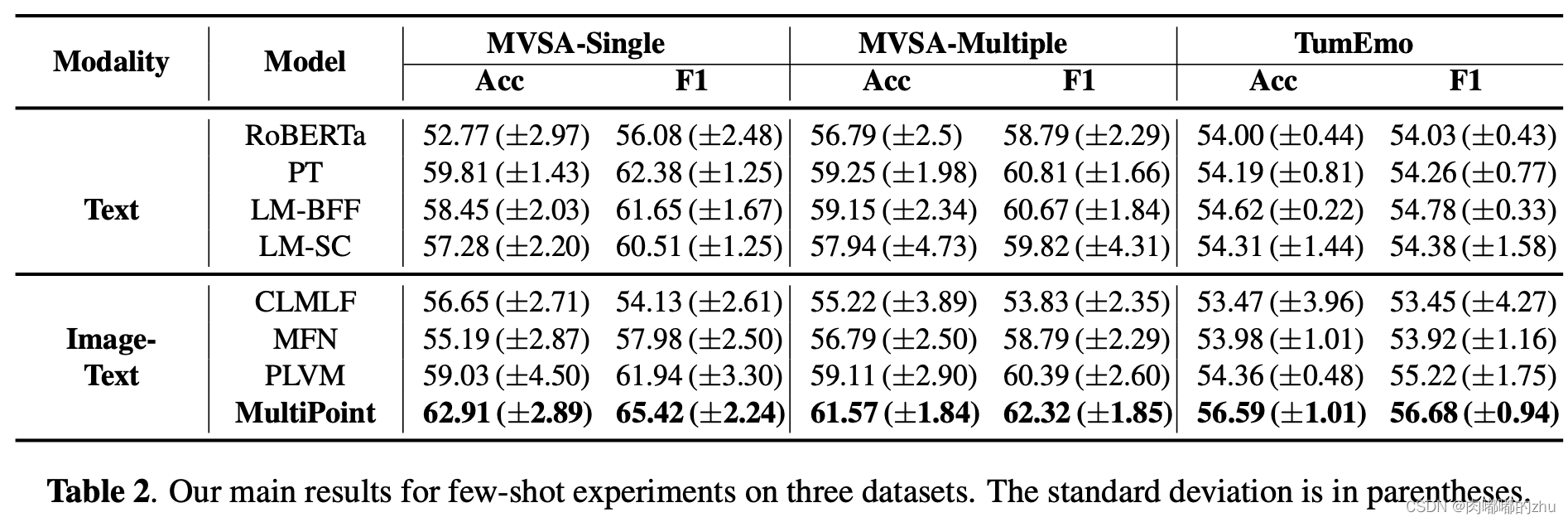
3.实验结果(Result)
消融实验:

总结(Conclusion):作者为FMSA任务提出了一种新的多模态概率融合提示模型。为了减少不同模式提示的差异,设计了由图像描述提示和文本提示组成的统一的多模式提示。进一步利用概率融合模块来融合来自不同多模态提示的多个预测。在FMSA任务中的三个数据集上演示了模型的有效性。在未来的工作中,将为FMSA设计更有效的提示符。