Embeddings 嵌入向量式文本转换
- 前言
- Overview 概述
- What are embeddings? 什么是嵌入?
- How to get embeddings 如何获取嵌入
- python代码示例
- cURL代码示例
- Embedding models 嵌入模型
- Second-generation models 第二代模型
- First-generation models (not recommended) 第一代模型(不推荐)
- Use cases 用例
- Obtaining the embeddings 获取嵌入
- Data visualization in 2D 二维数据可视化
- Embedding as a text feature encoder for ML algorithms 嵌入作为ML算法的文本特征编码器
- Regression using the embedding features 使用嵌入特征的回归
- Classification using the embedding features使用嵌入特征的分类
- Zero-shot classification 零样本分类
- Obtaining user and product embeddings for cold-start recommendation 获取用于冷启动推荐的用户和产品嵌入
- Clustering 聚类
- Text search using embeddings 使用嵌入的文本搜索
- Code search using embeddings 使用嵌入的代码搜索
- Recommendations using embeddings 使用嵌入的推荐
- Limitations & risks 限制和风险
- Social bias 社会偏差
- Blindness to recent events 对最近发生的事件视而不见
- Frequently asked questions 常见问题
- How can I tell how many tokens a string has before I embed it? 在嵌入字符串之前,如何知道它有多少个标记?
- How can I retrieve K nearest embedding vectors quickly? 如何快速检索K个最近的嵌入向量?
- Which distance function should I use? 我应该使用哪种距离函数?
- Can I share my embeddings online? 我可以在线分享我的嵌入吗?
- 其它资料下载

前言
ChatGPT 嵌入能够将文本转换为固定长度的连续向量,允许对文本数据执行分类、主题聚类、搜索和推荐等功能。这样,以前很难被处理的文本数据可以轻松地被处理了。
使用 ChatGPT 嵌入可以极大地改善用户体验。它能够帮助聊天机器人更准确地处理文本信息,并实现更有效的文本搜索与推荐、体验更为流畅的交互式会话,从而更好地满足用户需求。
Overview 概述
What are embeddings? 什么是嵌入?
OpenAI’s text embeddings measure the relatedness of text strings. Embeddings are commonly used for:
OpenAI的文本嵌入测量文本字符串的相关性。嵌入通常用于:
- Search (where results are ranked by relevance to a query string)
搜索(其中结果按与查询字符串的相关性进行排名) - Clustering (where text strings are grouped by similarity)
聚类(其中文本字符串按相似性分组) - Recommendations (where items with related text strings are recommended)
建议(其中建议包含相关文本字符串的项目) - Anomaly detection (where outliers with little relatedness are identified)
异常检测(其中识别出相关性很小的离群值) - Diversity measurement (where similarity distributions are analyzed)
多样性测量(分析相似性分布) - Classification (where text strings are classified by their most similar label)
分类(其中文本字符串按其最相似的标签进行分类)
An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
嵌入是浮点数的向量(列表)。两个向量之间的距离测量它们的相关性。小的距离表示高相关性,大的距离表示低相关性。
Visit our pricing page to learn about Embeddings pricing. Requests are billed based on the number of tokens in the input sent.
请访问我们的定价页面了解嵌入定价。请求根据发送的输入中的标记数计费。
To see embeddings in action, check out our code samples
要查看嵌入实际使用,请查看我们的代码示例,详见博客下部分 Use Cases
- Classification
- Topic clustering
- Search
- Recommendations
How to get embeddings 如何获取嵌入
To get an embedding, send your text string to the embeddings API endpoint along with a choice of embedding model ID (e.g., text-embedding-ada-002). The response will contain an embedding, which you can extract, save, and use.
要获取嵌入,请将文本字符串发送到嵌入API端点沿着选择嵌入模型ID(例如, text-embedding-ada-002 )。响应将包含一个嵌入,您可以提取、保存和使用它。
Example requests: 请求的示例
python代码示例
response = openai.Embedding.create(
input="Your text string goes here",
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
cURL代码示例
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-ada-002"
}'
Example response: 返回的示例
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
See more Python code examples in the OpenAI Cookbook.
在OpenAI Cookbook中查看更多Python代码示例。
When using OpenAI embeddings, please keep in mind their limitations and risks.
当使用OpenAI嵌入式时,请记住它们的局限性和风险。详见博客最后一部分 limitations and risks。
Embedding models 嵌入模型
OpenAI offers one second-generation embedding model (denoted by -002 in the model ID) and 16 first-generation models (denoted by -001 in the model ID).
OpenAI提供了一个第二代嵌入模型(在模型ID中表示为 -002 )和16个第一代模型(在模型ID中表示为 -001 )。
We recommend using text-embedding-ada-002 for nearly all use cases. It’s better, cheaper, and simpler to use. Read the blog post announcement.
我们建议在几乎所有用例中使用text-embedding-ada-002。它更好,更便宜,更容易使用。阅读博客文章公告。
| MODEL GENERATION 模型版本 | TOKENIZER 标记 | MAX INPUT TOKENS 最大输入标记 | KNOWLEDGE CUTOFF 截止时间 |
|---|---|---|---|
| V2 | cl100k_base | 8191 | Sep 2021 |
| V1 | GPT-2/GPT-3 | 2046 | Aug 2020 |
Usage is priced per input token, at a rate of $0.0004 per 1000 tokens, or about ~3,000 pages per US dollar (assuming ~800 tokens per page):
使用量按每个输入标记定价,每1000个标记0.0004美元,或每美元约3,000页(假设每页约800个标记):
| MODEL 模型 | ROUGH PAGES PER DOLLAR 每美元估计页数 | EXAMPLE PERFORMANCE ON BEIR SEARCH EVAL BEIR搜索评估的示例性能 |
|---|---|---|
| text-embedding-ada-002 | 3000 | 53.9 |
| *-davinci-*-001 | 6 | 52.8 |
| *-curie-*-001 | 60 | 50.9 |
| *-babbage-*-001 | 240 | 50.4 |
| *-ada-*-001 | 300 | 49.0 |
Second-generation models 第二代模型
| MODEL NAME 模型名称 | TOKENIZER 标记 | MAX INPUT TOKENS 最大输入标记 | OUTPUT DIMENSIONS 输出维度 |
|---|---|---|---|
| text-embedding-ada-002 | cl100k_base | 8191 | 1536 |
First-generation models (not recommended) 第一代模型(不推荐)
All first-generation models (those ending in -001) use the GPT-3 tokenizer and have a max input of 2046 tokens.
所有第一代模型(以-001结尾的模型)都使用GPT-3标记器,最大输入为2046个标记。
由于官方不推荐,故不详细分享其示例,如有需求,请前往地址。
Use cases 用例
Here we show some representative use cases. We will use the Amazon fine-food reviews dataset for the following examples.
在这里,我们展示了一些有代表性的用例。我们将在以下示例中使用Amazon美食评论数据集。
Obtaining the embeddings 获取嵌入
The dataset contains a total of 568,454 food reviews Amazon users left up to October 2012. We will use a subset of 1,000 most recent reviews for illustration purposes. The reviews are in English and tend to be positive or negative. Each review has a ProductId, UserId, Score, review title (Summary) and review body (Text). For example:
该数据集包含截至2012年10月亚马逊用户留下的总共568,454条食品评论。我们将使用1,000个最新评论的子集进行说明。评论是英语的,往往是正面或负面的。每个评论都有ProductId、UserId、Score、评论标题(摘要)和评论主体(文本)。例如:
| PRODUCT ID 产品ID | USER ID 用户ID | SCORE 得分 | SUMMARY 摘要 | TEXT 正文 |
|---|---|---|---|---|
| B001E4KFG0 | A3SGXH7AUHU8GW | 5 | Good Quality Dog Food 优质狗粮 | I have bought several of the Vitality canned…我已经买了几个Vitality罐头… |
| B00813GRG4 | A1D87F6ZCVE5NK | 1 | Not as Advertised 不像宣传的那样 | Product arrived labeled as Jumbo Salted Peanut…产品到达标签为Jumbo Salted Peanut… |
We will combine the review summary and review text into a single combined text. The model will encode this combined text and output a single vector embedding.
我们将把评论摘要和评论文本组合成一个单独的合并文本。该模型将对该组合文本进行编码,并输出单个向量嵌入。
Obtain_dataset.ipynb
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)
To load the data from a saved file, you can run the following:
要从已保存的文件加载数据,可以运行以下命令:
import pandas as pd
df = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)
Data visualization in 2D 二维数据可视化
Visualizing_embeddings_in_2D.ipynb
The size of the embeddings varies with the complexity of the underlying model. In order to visualize this high dimensional data we use the t-SNE algorithm to transform the data into two dimensions.
嵌入的大小随底层模型的复杂性而变化。为了可视化这些高维数据,我们使用t-SNE算法将数据转换为二维。
We color the individual reviews based on the star rating which the reviewer has given:
我们会根据点评者给出的星星对每条点评进行着色:
- 1-star: red 红色
- 2-star: dark orange 橙色
- 3-star: gold 金色
- 4-star: turquoise 蓝绿色
- 5-star: dark green 绿色
Amazon ratings visualized in language using t-SNE 使用t-SNE语言可视化亚马逊评级
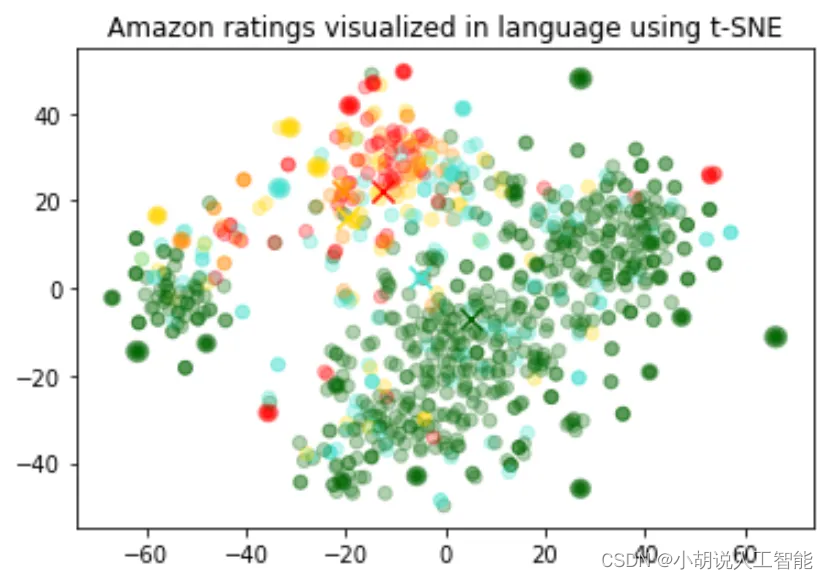
The visualization seems to have produced roughly 3 clusters, one of which has mostly negative reviews.
可视化似乎产生了大约3个集群,其中一个大多是负面评论。
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib
df = pd.read_csv('output/embedded_1k_reviews.csv')
matrix = df.ada_embedding.apply(eval).to_list()
# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
colors = ["red", "darkorange", "gold", "turquiose", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Amazon ratings visualized in language using t-SNE")
Embedding as a text feature encoder for ML algorithms 嵌入作为ML算法的文本特征编码器
Regression_using_embeddings.ipynb
An embedding can be used as a general free-text feature encoder within a machine learning model. Incorporating embeddings will improve the performance of any machine learning model, if some of the relevant inputs are free text. An embedding can also be used as a categorical feature encoder within a ML model. This adds most value if the names of categorical variables are meaningful and numerous, such as job titles. Similarity embeddings generally perform better than search embeddings for this task.
嵌入可以用作机器学习模型内的一般自由文本特征编码器。如果一些相关的输入是自由文本,那么嵌入将提高任何机器学习模型的性能。嵌入也可以用作ML模型内的分类特征编码器。如果分类变量的名称是有意义的并且数量众多,例如职位,则这会增加最大的价值。相似性嵌入通常比搜索嵌入更好地执行此任务。
We observed that generally the embedding representation is very rich and information dense. For example, reducing the dimensionality of the inputs using SVD or PCA, even by 10%, generally results in worse downstream performance on specific tasks.
我们观察到,通常嵌入表示是非常丰富和信息密集的。例如,使用SVD或PCA降低输入的维度,即使降低10%,通常也会导致特定任务的下游性能更差。
This code splits the data into a training set and a testing set, which will be used by the following two use cases, namely regression and classification.
这段代码将数据分为训练集和测试集,它们将被以下两个用例使用,即回归和分类。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
list(df.ada_embedding.values),
df.Score,
test_size = 0.2,
random_state=42
)
Regression using the embedding features 使用嵌入特征的回归
Embeddings present an elegant way of predicting a numerical value. In this example we predict the reviewer’s star rating, based on the text of their review. Because the semantic information contained within embeddings is high, the prediction is decent even with very few reviews.
嵌入提供了一种预测数值的优雅方式。在这个例子中,我们根据评论的文本预测评论者的星级排名。因为嵌入中包含的语义信息很高,所以即使评论很少,预测也很不错。
We assume the score is a continuous variable between 1 and 5, and allow the algorithm to predict any floating point value. The ML algorithm minimizes the distance of the predicted value to the true score, and achieves a mean absolute error of 0.39, which means that on average the prediction is off by less than half a star.
我们假设分数是1到5之间的连续变量,并允许算法预测任何浮点值。ML算法将预测值与真实分数的距离最小化,并实现0.39的平均绝对误差,这意味着平均预测偏差不到半颗星星。
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)
Classification using the embedding features使用嵌入特征的分类
Classification_using_embeddings.ipynb
This time, instead of having the algorithm predict a value anywhere between 1 and 5, we will attempt to classify the exact number of stars for a review into 5 buckets, ranging from 1 to 5 stars.
这一次,我们不再让算法预测1到5之间的值,而是尝试将评论的确切星级数量分为5个桶,范围从1到5颗星。
After the training, the model learns to predict 1 and 5-star reviews much better than the more nuanced reviews (2-4 stars), likely due to more extreme sentiment expression.
在训练之后,模型学习预测1星和5星评论比更细致入微的评论(2-4星)好得多,这可能是由于更极端的情感表达。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
Zero-shot classification 零样本分类
Zero-shot_classification_with_embeddings.ipynb
We can use embeddings for zero shot classification without any labeled training data. For each class, we embed the class name or a short description of the class. To classify some new text in a zero-shot manner, we compare its embedding to all class embeddings and predict the class with the highest similarity.
我们可以在没有任何标记的训练数据的情况下使用嵌入进行零样本分类。对于每个类,我们嵌入类名或类的简短描述。为了对新文本进行零样本分类,我们将新文本的嵌入与所有类的嵌入进行比较,并预测出相似度最高的类。
from openai.embeddings_utils import cosine_similarity, get_embedding
df= df[df.Score!=3]
df['sentiment'] = df.Score.replace({1:'negative', 2:'negative', 4:'positive', 5:'positive'})
labels = ['negative', 'positive']
label_embeddings = [get_embedding(label, model=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
prediction = 'positive' if label_score('Sample Review', label_embeddings) > 0 else 'negative'
Obtaining user and product embeddings for cold-start recommendation 获取用于冷启动推荐的用户和产品嵌入
User_and_product_embeddings.ipynb
We can obtain a user embedding by averaging over all of their reviews. Similarly, we can obtain a product embedding by averaging over all the reviews about that product. In order to showcase the usefulness of this approach we use a subset of 50k reviews to cover more reviews per user and per product.
我们可以通过对所有评论进行平均来获得用户嵌入。类似地,我们可以通过对关于该产品的所有评论进行平均来获得产品嵌入。为了展示这种方法的有用性,我们使用了50k评论的子集来覆盖每个用户和每个产品的更多评论。
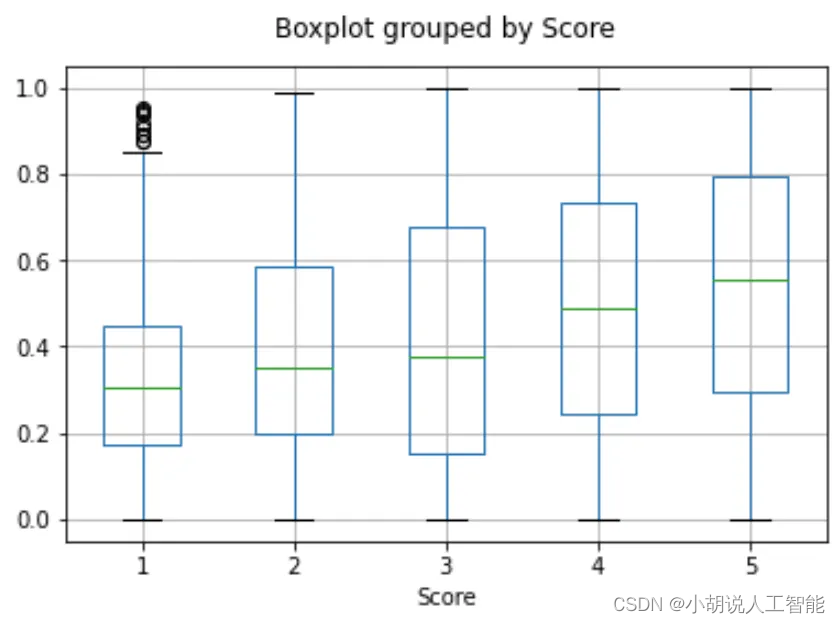
We evaluate the usefulness of these embeddings on a separate test set, where we plot similarity of the user and product embedding as a function of the rating. Interestingly, based on this approach, even before the user receives the product we can predict better than random whether they would like the product.
我们在一个单独的测试集上评估这些嵌入的有用性,在那里我们绘制用户和产品嵌入的相似性作为评级的函数。有趣的是,基于这种方法,即使在用户收到产品之前,我们也可以比随机预测更好地预测他们是否喜欢该产品。
Boxplot grouped by Score 箱线图按分数分组
user_embeddings = df.groupby('UserId').ada_embedding.apply(np.mean)
prod_embeddings = df.groupby('ProductId').ada_embedding.apply(np.mean)
Clustering 聚类
Clustering.ipynb
Clustering is one way of making sense of a large volume of textual data. Embeddings are useful for this task, as they provide semantically meaningful vector representations of each text. Thus, in an unsupervised way, clustering will uncover hidden groupings in our dataset.
聚类是理解大量文本数据的一种方法。嵌入对于这项任务很有用,因为它们提供了每个文本的语义上有意义的向量表示。因此,以无监督的方式,聚类将揭示数据集中隐藏的分组。
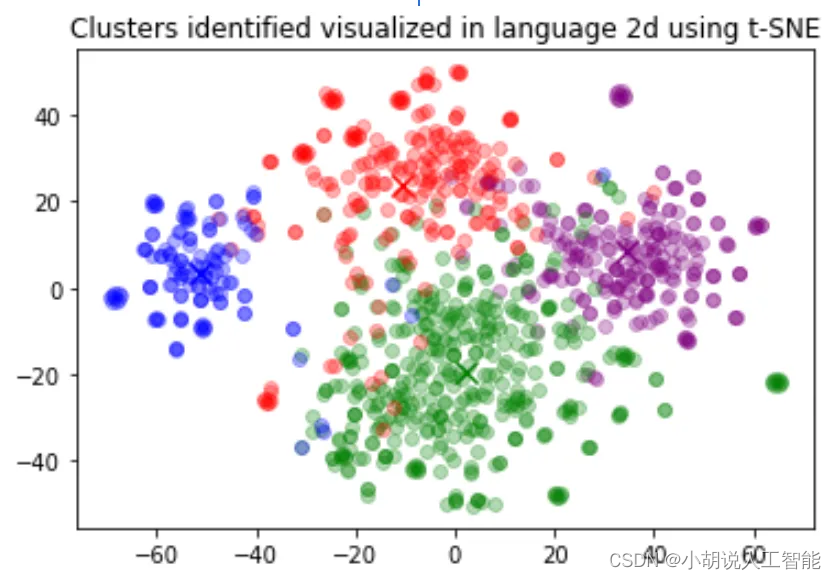
In this example, we discover four distinct clusters: one focusing on dog food, one on negative reviews, and two on positive reviews.
在这个例子中,我们发现了四个不同的集群:一个关注狗粮,一个关注负面评价,两个关注正面评价。
Clusters identified visualized in language 2d using t-SNE 使用t-SNE在语言2d中可视化地识别集群
import numpy as np
from sklearn.cluster import KMeans
matrix = np.vstack(df.ada_embedding.values)
n_clusters = 4
kmeans = KMeans(n_clusters = n_clusters, init='k-means++', random_state=42)
kmeans.fit(matrix)
df['Cluster'] = kmeans.labels_
Text search using embeddings 使用嵌入的文本搜索
Semantic_text_search_using_embeddings.ipynb
To retrieve the most relevant documents we use the cosine similarity between the embedding vectors of the query and each document, and return the highest scored documents.
为了检索最相关的文档,我们使用查询和每个文档的嵌入向量之间的余弦相似度,并返回得分最高的文档。
from openai.embeddings_utils import get_embedding, cosine_similarity
def search_reviews(df, product_description, n=3, pprint=True):
embedding = get_embedding(product_description, model='text-embedding-ada-002')
df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_reviews(df, 'delicious beans', n=3)
Code search using embeddings 使用嵌入的代码搜索
Code_search.ipynb
Code search works similarly to embedding-based text search. We provide a method to extract Python functions from all the Python files in a given repository. Each function is then indexed by the text-embedding-ada-002 model.
代码搜索的工作原理与基于嵌入的文本搜索类似。我们提供了一种方法,可以从给定存储库中的所有Python文件中提取Python函数。然后每个函数由 text-embedding-ada-002 模型索引。
To perform a code search, we embed the query in natural language using the same model. Then we calculate cosine similarity between the resulting query embedding and each of the function embeddings. The highest cosine similarity results are most relevant.
为了执行代码搜索,我们使用相同的模型将查询嵌入到自然语言中。然后,我们计算得到的查询嵌入和每个函数嵌入之间的余弦相似度。最高余弦相似性结果是最相关的。
from openai.embeddings_utils import get_embedding, cosine_similarity
df['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
def search_functions(df, code_query, n=3, pprint=True, n_lines=7):
embedding = get_embedding(code_query, model='text-embedding-ada-002')
df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_functions(df, 'Completions API tests', n=3)
Recommendations using embeddings 使用嵌入的推荐
Recommendation_using_embeddings.ipynb
Because shorter distances between embedding vectors represent greater similarity, embeddings can be useful for recommendation.
因为嵌入向量之间的较短距离表示较大的相似性,所以嵌入对于推荐是有用的。
Below, we illustrate a basic recommender. It takes in a list of strings and one ‘source’ string, computes their embeddings, and then returns a ranking of the strings, ranked from most similar to least similar. As a concrete example, the linked notebook below applies a version of this function to the AG news dataset (sampled down to 2,000 news article descriptions) to return the top 5 most similar articles to any given source article.
下面,我们展示一个基本的推荐器。它接受一个字符串列表和一个“源”字符串,计算它们的嵌入,然后返回字符串的排序,从最相似到最不相似排序。作为一个具体的例子,下面的链接笔记本将此函数的一个版本应用于AG新闻数据集(采样到2,000篇新闻文章描述),以返回与任何给定源文章最相似的前5篇文章。
def recommendations_from_strings(
strings: List[str],
index_of_source_string: int,
model="text-embedding-ada-002",
) -> List[int]:
"""Return nearest neighbors of a given string."""
# get embeddings for all strings
embeddings = [embedding_from_string(string, model=model) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
return indices_of_nearest_neighbors
Limitations & risks 限制和风险
Our embedding models may be unreliable or pose social risks in certain cases, and may cause harm in the absence of mitigations.
我们的嵌入模型在某些情况下可能不可靠或构成社会风险,并且在缺乏缓解措施的情况下可能造成伤害。
Social bias 社会偏差
Limitation: The models encode social biases, e.g. via stereotypes or negative sentiment towards certain groups.
局限性:这些模型对社会偏差进行了编码,例如通过对某些群体的刻板印象或负面情绪。
We found evidence of bias in our models via running the SEAT (May et al, 2019) and the Winogender (Rudinger et al, 2018) benchmarks. Together, these benchmarks consist of 7 tests that measure whether models contain implicit biases when applied to gendered names, regional names, and some stereotypes.
我们通过运行SEAT(May et al,2019)和Winogender(Rudinger et al,2018)基准测试发现了模型中存在偏差的证据。这些基准包括7个测试,用于衡量模型在应用于性别名称,地区名称和一些刻板印象时是否包含隐含的偏见。
For example, we found that our models more strongly associate (a) European American names with positive sentiment, when compared to African American names, and (b) negative stereotypes with black women.
例如,我们发现,我们的模型更强烈地将(a)欧洲裔美国人的名字与积极情绪相关联,与非洲裔美国人的名字相比,以及(B)与黑人女性的负面刻板印象。
These benchmarks are limited in several ways: (a) they may not generalize to your particular use case, and (b) they only test for a very small slice of possible social bias.
这些基准在几个方面受到限制:(a)它们可能不会推广到您的特定用例,(B)它们只测试可能的社会偏见的一小部分。
These tests are preliminary, and we recommend running tests for your specific use cases. These results should be taken as evidence of the existence of the phenomenon, not a definitive characterization of it for your use case. Please see our usage policies for more details and guidance.
这些测试是初步的,我们建议您针对特定用例运行测试。这些结果应该被视为现象存在的证据,而不是对您的用例的明确描述。请参阅我们的使用政策了解更多详情和指导。
Please contact our support team via chat if you have any questions; we are happy to advise on this.
如果您有任何问题,请通过聊天联系我们的支持团队;我们很乐意就此提供意见。
Blindness to recent events 对最近发生的事件视而不见
Limitation: Models lack knowledge of events that occurred after August 2020.
局限性:模型缺乏对2020年8月之后发生的事件的了解。
Our models are trained on datasets that contain some information about real world events up until 8/2020. If you rely on the models representing recent events, then they may not perform well.
我们的模型是在包含一些真实的世界事件信息的数据集上训练的,直到2020年8月。如果你依赖于代表最近事件的模型,那么它们可能表现不佳。
Frequently asked questions 常见问题
How can I tell how many tokens a string has before I embed it? 在嵌入字符串之前,如何知道它有多少个标记?
In Python, you can split a string into tokens with OpenAI’s tokenizer tiktoken.
在Python中,你可以使用OpenAI的标记器 tiktoken 将一个字符串分割成多个标记。
Example code:
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")
For second-generation embedding models like text-embedding-ada-002, use the cl100k_base encoding.
对于像 text-embedding-ada-002 这样的第二代嵌入模型,请使用 cl100k_base 编码。
More details and example code are in the OpenAI Cookbook guide how to count tokens with tiktoken.
更多细节和示例代码在OpenAI Cookbook指南中如何使用tiktoken进行标记计数。
How can I retrieve K nearest embedding vectors quickly? 如何快速检索K个最近的嵌入向量?
For searching over many vectors quickly, we recommend using a vector database. You can find examples of working with vector databases and the OpenAI API in our Cookbook on GitHub.
为了快速搜索多个矢量,我们建议使用矢量数据库。您可以在GitHub上的Cookbook中找到使用矢量数据库和OpenAI API的示例。
Vector database options include: 矢量数据库选项包括:
- Pinecone, a fully managed vector database
Pinecone,一个完全管理的矢量数据库 - Weaviate, an open-source vector search engine
Weaviate,一个开源矢量搜索引擎 - Redis as a vector database
Redis作为矢量数据库 - Qdrant, a vector search engine
Qdrant,一个矢量搜索引擎 - Milvus, a vector database built for scalable similarity search
- Milvus,一个为可扩展的相似性搜索而构建的矢量数据库
- Chroma, an open-source embeddings store
Chroma,一个开源嵌入式商店 - Typesense, fast open source vector search
Typesense,快速开源矢量搜索
Which distance function should I use? 我应该使用哪种距离函数?
We recommend cosine similarity. The choice of distance function typically doesn’t matter much.
我们推荐余弦相似性。距离函数的选择通常并不重要。
OpenAI embeddings are normalized to length 1, which means that:
OpenAI嵌入规范化为长度1,这意味着:
- Cosine similarity can be computed slightly faster using just a dot product
仅使用点积可以稍微更快地计算余弦相似性 - Cosine similarity and Euclidean distance will result in the identical rankings
余弦相似度和欧氏距离将导致相同的排名
Can I share my embeddings online? 我可以在线分享我的嵌入吗?
Customers own their input and output from our models, including in the case of embeddings. You are responsible for ensuring that the content you input to our API does not violate any applicable law or our Terms of Use.
客户拥有他们的输入和我们模型的输出,包括嵌入的情况。您有责任确保您输入我们API的内容不违反任何适用法律或我们的使用条款。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。