很多同学不知道为什么要用 debugger 来调试,console.log 不行么?
还有,会用 debugger 了,还是有很多代码看不懂,如何调试复杂源码呢?
这篇文章就来讲一下为什么要用这些调试工具:
console.log vs Debugger
相信绝大多数同学使用 console.log 调试的,把想看的变量值打印在控制台。
这样能满足需求,但是遇到对象的打印就不行了。
比如我想看 webpack 源码里的 compilation 对象的值,我打印了一下:
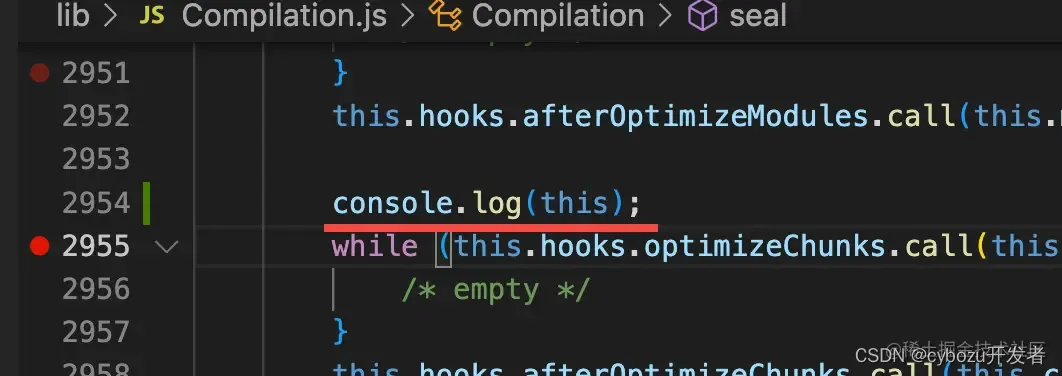
但你会发现对象的值也是对象的时候不会展开,而是打印一个 [Object] [Array] 这种字符串。
更致命的是打印的太长会超过缓冲区的大小,terminal 里会显示不全:

而你用 debugger 来跑,在这里打个断点来看就没这些问题了:
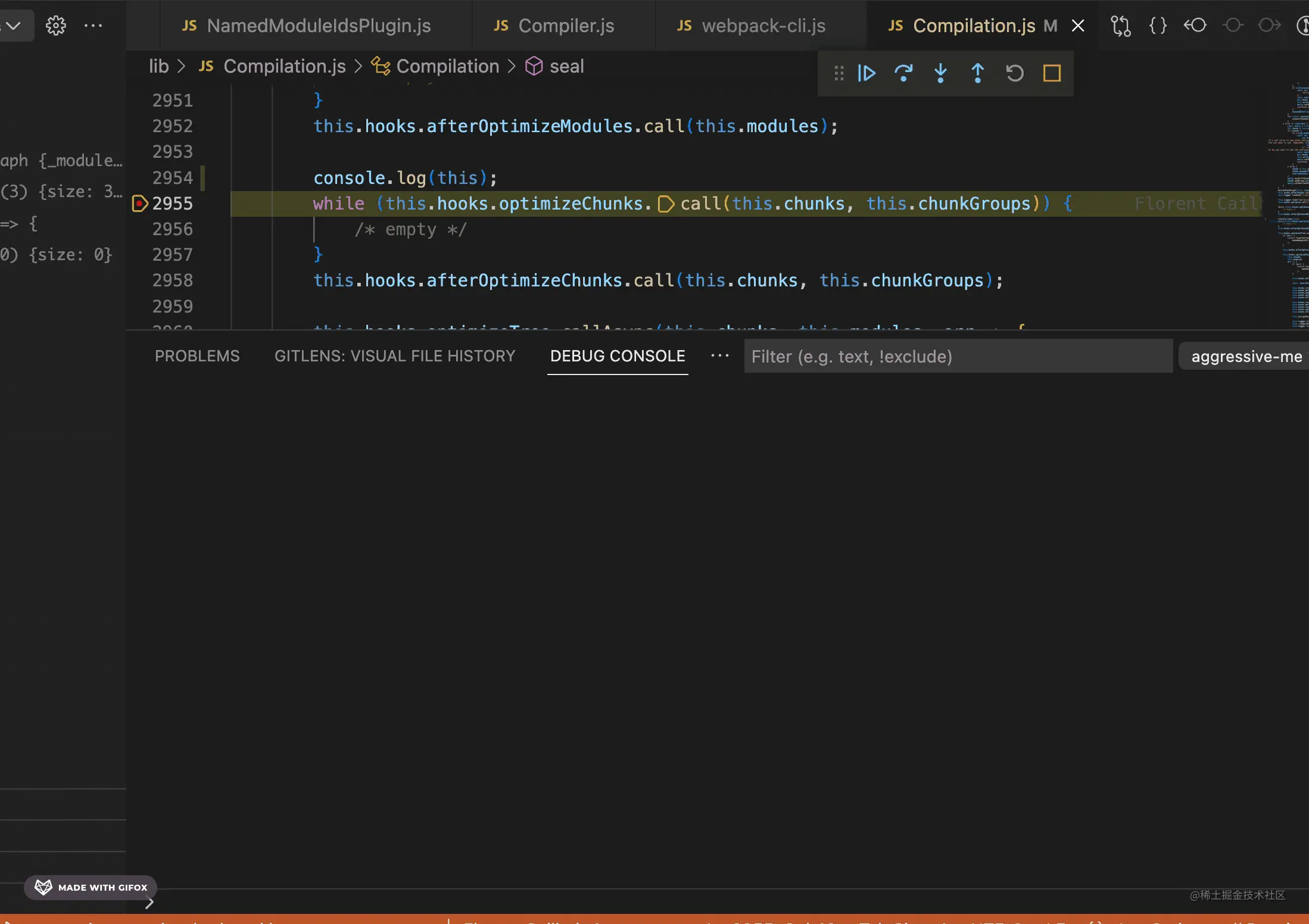
有的同学可能会说,那打印一个简单的值的时候用 console.log 还是很方便呀。
比如这样:
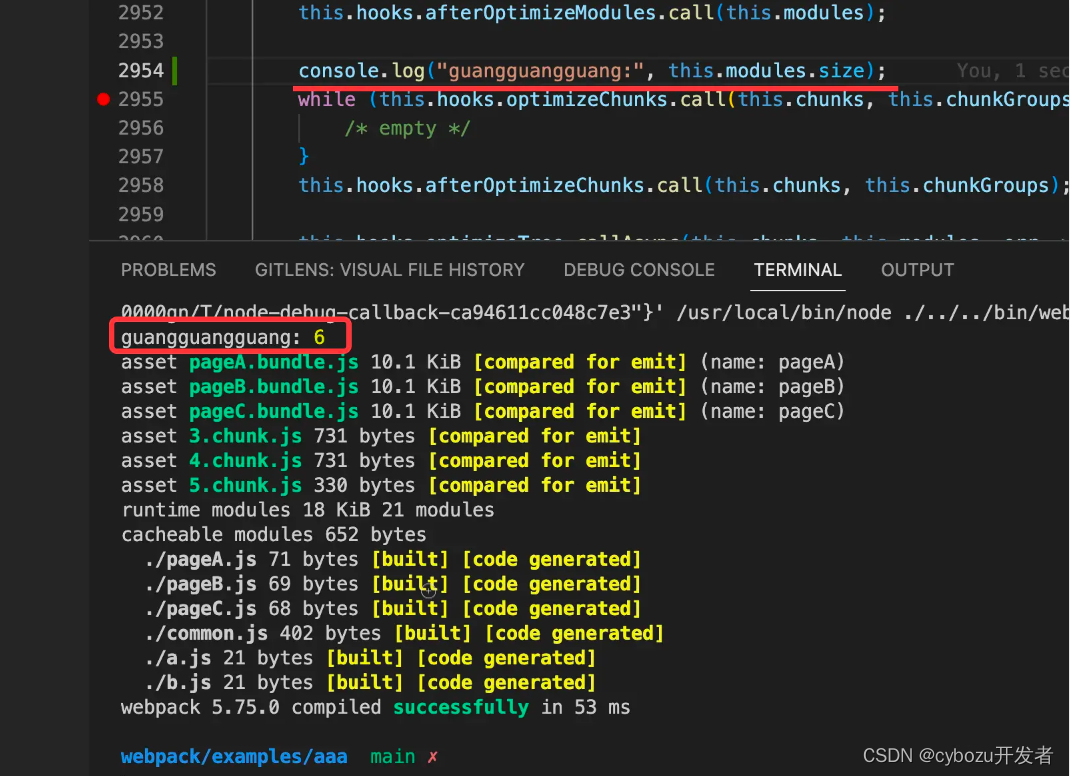
真的么?
那还不如用 logpoint:


代码执行到这里就会打印:

而且没有污染代码,用 console.log 的话调试完之后这个 console 不也得删掉么?
但是 logpoint 不用,它就是个断点的设置,不在代码里。
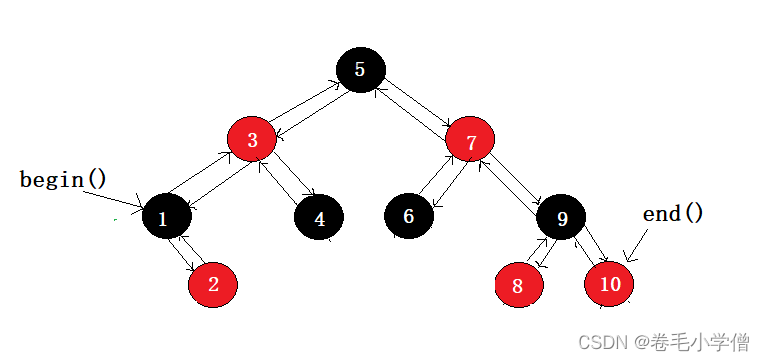
当然,最重要的是 Debugger 调试是可以看到调用栈和作用域的!
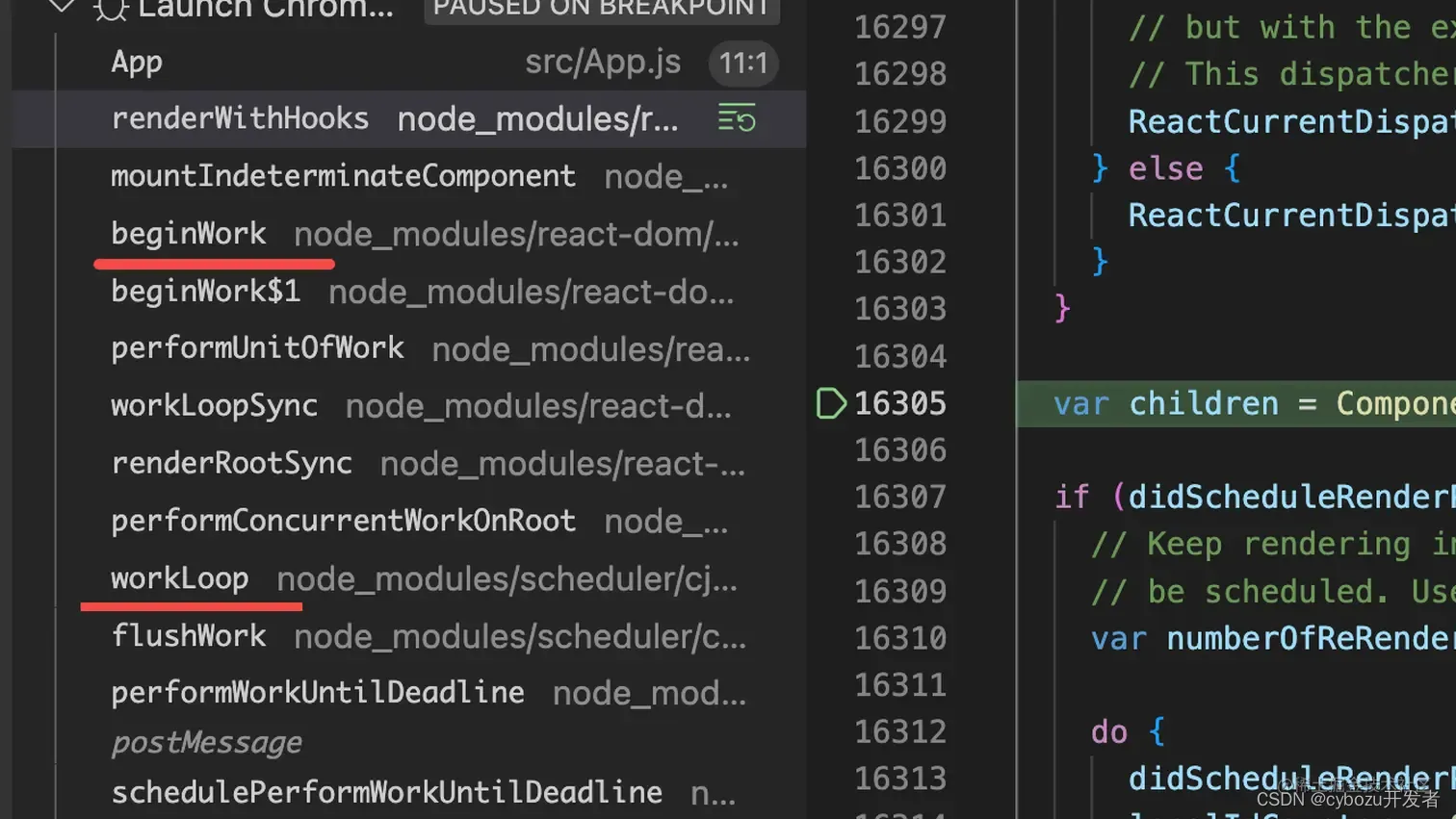
首先是调用栈,它就是代码的执行路线。
比如这个 App 的函数组件,你可以看到渲染这个函数组件会经历 workLoop、beginWork、renderWithHooks 这些流程:

你可以点开调用栈的每一帧看下都执行了啥逻辑,用到啥数据。比如可以看到这个函数组件的 fiber 节点:
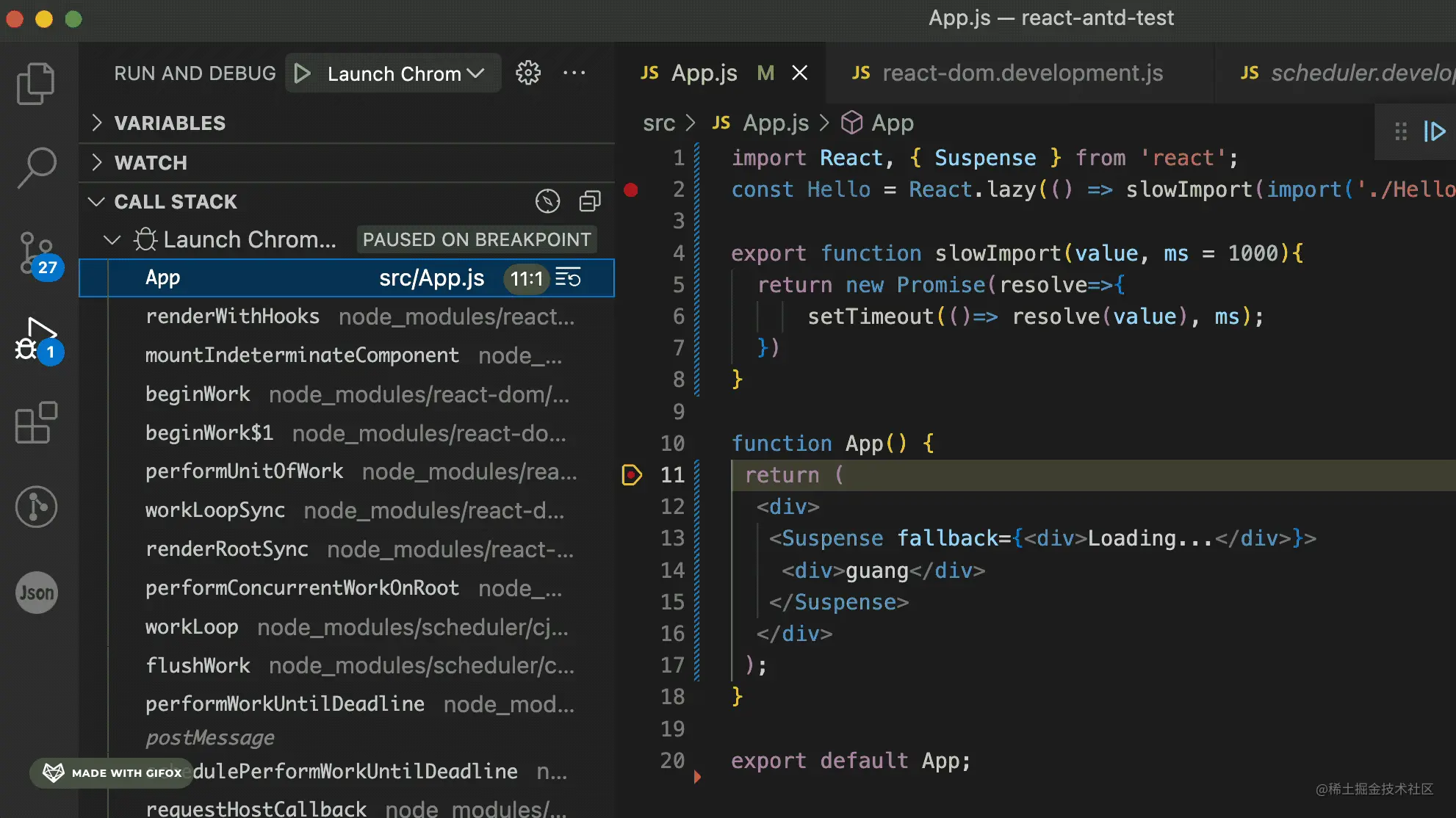
再就是作用域,点击每一个栈帧就可以看到每个函数的作用域中的变量:

用 Debugger 可以看到代码的执行路径,每一步的作用域信息。而你用 console.log 呢?
只能看到那个变量值而已。
拿到的信息量的差距不是一点半点,调试时间长了,别人会对代码的运行流程越来越清晰,而你用 console.log 呢?还是老样子,因为你看不到代码执行路径。
所以,不管是调试库的源码还是业务代码,不管是调试 Node.js 还是网页,都推荐用 Debugger 打断点,别再用 console.log 了,就算想打印日志,也可以用 LogPoint。
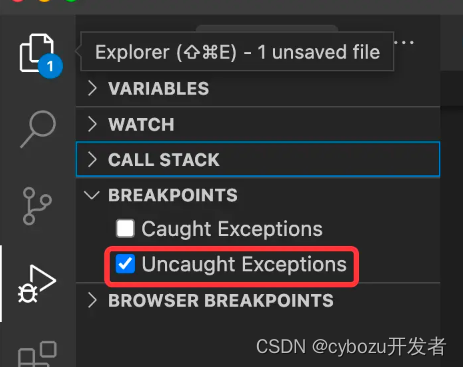
而且在排查问题的时候,用 Debugger 的话可以加一个异常断点,代码跑到抛异常的地方就会断住:
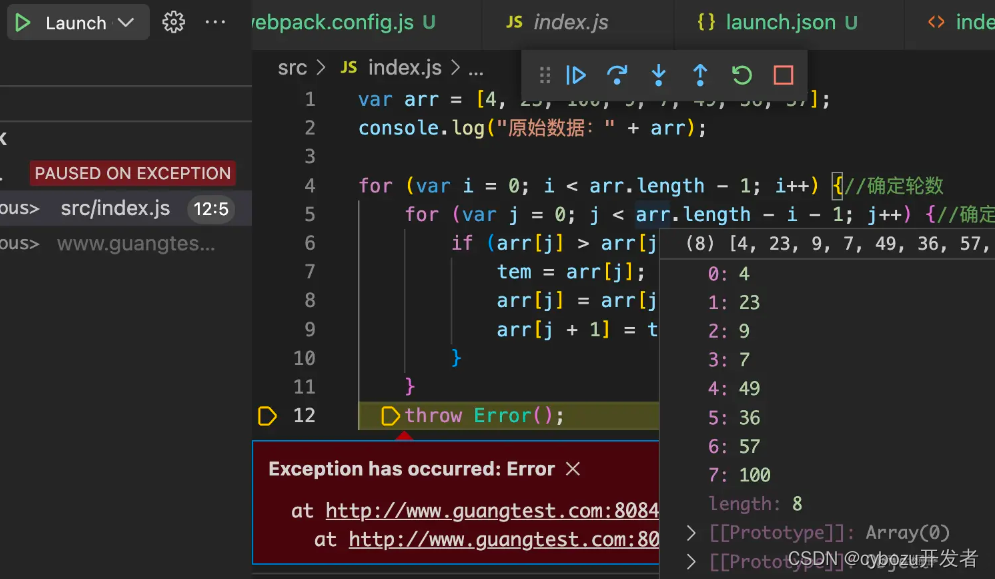
可以看到调用栈来理清出错前都走了哪些代码,可以通过作用域来看到每一个变量的值。
有了这些东西,排查错误不就很轻松了么!
而你用 console.log 呢?
啥也没,只能自己猜。
由于本篇文章都是gif动图,今天上传太累了,要看全文,请点击以下链接:
开发者网站--放弃console.log吧!