目录
- 问题提出
- 问题重述与再理解
- 第一个问题:假如样本不均衡,哪种分类器的泛化性能较好?
- 第二个问腿:在样本不均衡的情况下,如何获得更健壮的模型
- 问题解决方法
- 样本不均衡对机器学习模型会造成什么影响
- 什么模型适合样本不均衡的数据集
- 样本不平衡数据集需要注意的泛化评价指标
- 可以采取什么方法对数据集进行处理
- 过采样和欠采样
- SMOTE
- ADASYN
- 调整类的权重
- 数据集例子——信用卡诈骗数据集
- 数据集介绍
- 数据集处理
- 数据集所用模型与方法
- 总结
- 启发与思考
- 参考文章
问题提出
机器学习的老师在一次作业中给出了这几个思考的问题,本文从前两个问题着手,若有不全或者意思错误的地方请向我指出(谢谢!)

问题重述与再理解
第一个问题:假如样本不均衡,哪种分类器的泛化性能较好?
这个问题也可以拓展为:哪种分类器比较不会受到样本不均衡的影响,或者说得不均衡到哪种程度,会对分类器的影响。
第二个问腿:在样本不均衡的情况下,如何获得更健壮的模型
这个问题也就可以理解为,用什么方法去处理数据集才能让自己的模型尽可能正确分类出少数样本
问题解决方法
样本不均衡对机器学习模型会造成什么影响
样本不均衡带来的根本影响是:模型会学习到训练集中样本比例的这种先验性信息,以致于实际预测时就会对多数类别有侧重(可能导致多数类精度更好,而少数类比较差)
什么模型适合样本不均衡的数据集
-
根据搜索文章关于这方面的东西很少,得从模型构建的原理角度分析样本不均衡的处理(Xgboost,pytorch及tensorflow)在这篇文章里提到的集成树方法就比较能够适应样本不均衡的数据集
-
为什么随机森林适合样本不均衡的数据集
在增强模型中,我们给在每个树迭代中被错误分类的情况更多的权重,所以比其他类型模型的效果更好一些
样本不平衡数据集需要注意的泛化评价指标
众所周知,机器学习的评价指标有:ROC曲线,Acc,recall,精度,f1-score等等,可以看我下面给的这篇文章的标注
评价指标
永远不要使用accuracy(准确率)作为不平衡数据集的指标,由于数据集不平衡,会导致虽然模型的准确率非常高但是无法将小样本的类别成功分类,具有很强的误导性,可以使用AUC-ROC、Recall、F1分数等指标综合看待模型的性能。这里也要注意ROC与recall图像中蕴含的内容,因为我们总是只关注结果数字的变化从而忽略了图表中连续过程蕴含的意义
可以采取什么方法对数据集进行处理
-
- 什么也不做。有时好运就这样降临在你的头上:你什么都不需要做。你可以使用所谓的自然(或分层)分布来进行训练,有时不需任何修改就能正常运行。
-
- 通过某些方法使得数据更加平衡:
-
- 对少数类进行过采样(oversampling)
-
- 对多数类进行欠采样(undersampling)
-
- 合成新的少数类 (SMOTE,ADASYN、SMOTE-Boost、DataBoost-IM等)
-
- 舍弃所有少数类,切换成一个异常检测框架。
-
- 在算法层面之上(或之后):
-
- 调整类的权重(错误分类成本)
-
- 调整决策阈值
-
- 使已有的算法对少数类更加敏感
-
- 构造一个在不平衡数据上表现更好的全新算法。
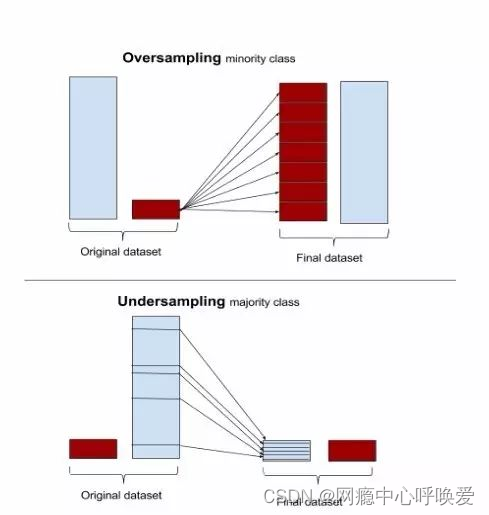
过采样和欠采样
简单的过采样和欠采样是部分人的首要选择,因为原理很简单。
过采样(oversampling)和欠采样(undersampling)
最简单的方法只需要对处理步骤进行一点点修改,并简单地涉及到调整样本集直到它们达到平衡。过采样会随机复制少数样例以增大它们的规模。欠采样则随机地少采样主要的类。一些数据科学家(天真地)认为过采样更好,因为其会得到更多的数据,而欠采样会将数据丢掉。但请记住复制数据不是没有后果的——因为其会得到复制出来的数据,它就会使变量的方差表面上比实际上更小。而过采样的好处是它也会复制误差的数量:如果一个分类器在原始的少数类数据集上做出了一个错误的负面错误,那么将该数据集复制五次之后,该分类器就会在新的数据集上出现六个错误。相对地,欠采样会让独立变量(independent variable)的方差看起来比其实际的方差更高。深度 | 解决真实世界问题:如何在不平衡类上使用机器学习?
SMOTE
其思想是通过在已有的样本间插值来创造新的少数类样本。
SMOTE的原理与实现
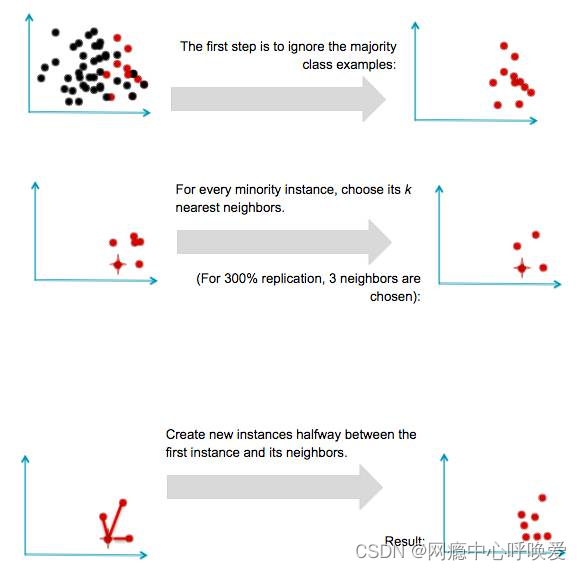
SMOTE实现简单,但其弊端也很明显,由于SMOTE对所有少数类样本一视同仁,并未考虑近邻样本的类别信息,往往出现样本混叠现象,导致分类效果不佳。
ADASYN
这个方法是我在kaggle上看到有人用的,从而了解了一下。 ADASYN (adaptive synthetic sampling)自适应合成抽样。ADASYN算法的关键思想是使用密度分布作为准则来自动确定每个少数数据示例需要生成的合成样本的数量,即在少数实例的密度较低的特征空间区域中生成更多的合成实例,而在密度较高的特征空间区域生成较少的合成实例。
不平衡数据处理之SMOTE、Borderline SMOTE和ADASYN详解及Python使用
数据预处理与特征工程—1.不均衡样本集采样—SMOTE算法与ADASYN算法
调整类的权重
许多机器学习工具包都有调整类的「重要性」的方法。比如 Scikit-learn 有许多可以使用可选的 class_weight 参数(可以设置成大于 1)的分类器。这里有一个直接从 scikit-learn 文档中引用的例子,展示了将少数类的权重增加为 10 倍时的效果。
注意点:应该指出的是调整类的重要性通常只能影响类的误差(假阴性(False Negatives),如果少数类是阳性的话)成本。它会调整一个分离的平面并借此降低这些误差。当然,如果该分类器在训练集误差上没有错误,那也就不需要调整,所以调整类权重可能就没有效果。
数据集例子——信用卡诈骗数据集
数据集介绍
数据集链接来自Kaggle的一个关于信用卡检测诈骗的例子。数据集中包含了2013年9月在欧洲的持卡人通过信用卡进行的交易目录。在两天的284807笔交易中,总共有492笔欺诈事件。数据集高度不平衡,正类(欺诈)占所有交易的0.172%。
数据集属性解释如下:

数据集处理
这一步主要是对数据集里面的几项属性(time和amount)进行处理,这里不赘述,在我的代码里可以看到过程。
数据集所用模型与方法
本人用了6种不同的机器学习模型分别是(KNN,逻辑回归,NB,支持向量机,随机森林,ADAboost)进行训练并比较。并且对每种模型都对五种处理方法进行比较。
可以看到随机森林模型霸占了前四个排名,可以确定随机森林模型是该数据集的最优模型,其次是SVM和ADAboost。横向对比随机森林模型的五种处理方法,通过对recall和f1分数,AUC的指标排序,可以发现通过SMOTE和ADASYN方法后处理的数据集在这三项数值都明显比没有经过处理的数值高,说明我们的方法成功提升了模型在分类少样本的正确率。
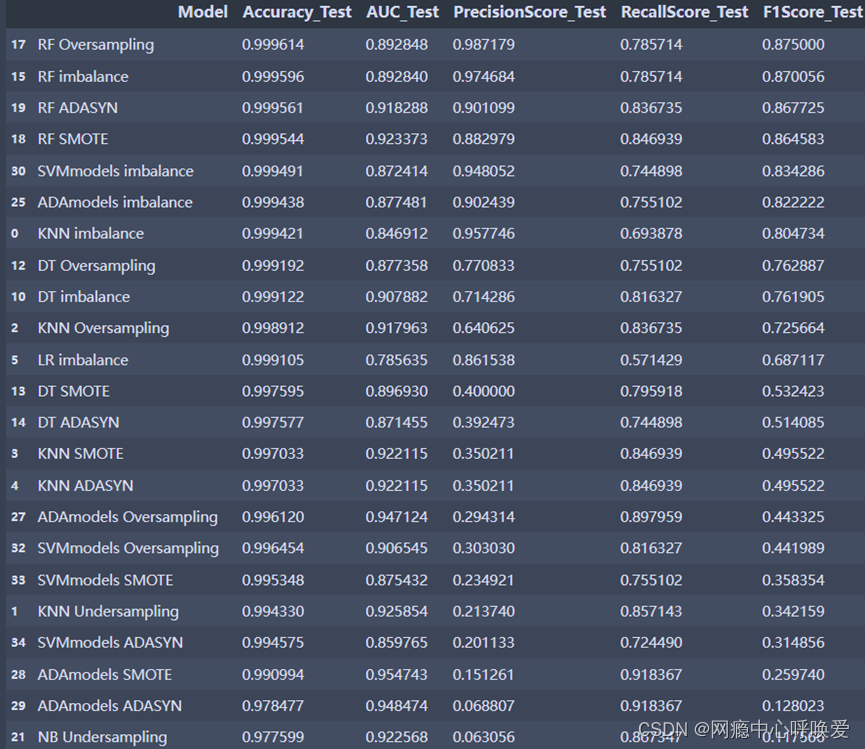
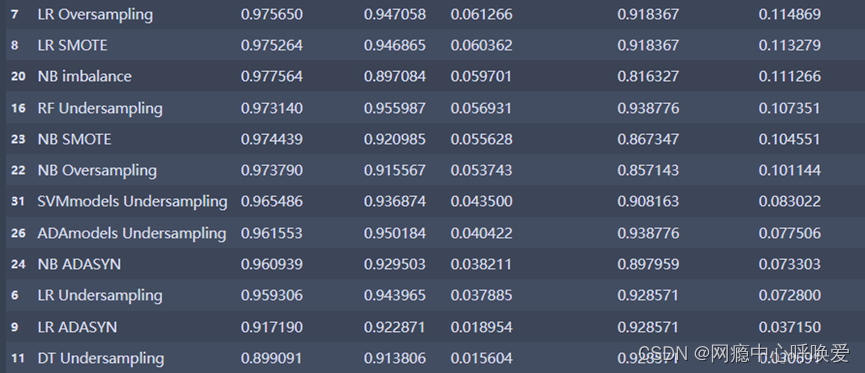
如果想运行一下本人的代码,已发布在Kaggle上代码链接,这是本人综合了几位大佬的代码做的总结,可能还有一些不完善,其他vote高的代码都可以看看借鉴
总结
启发与思考
- 关于样本不平衡这种现象肯定很常见,比如自动驾驶中的事故总比正常驾驶少的多等等,需要不断尝试不同的做法。
- 本人的理解还比较局限,目前只针对了信用卡数据集,没有对其他数据集进行一样的操作探讨,并且对深度学习领域的相关问题没有尝试过,未来会尝试在深度学习领域关注样本不均衡问题
参考文章
数据集How to create a meaningful EDA
MIT大佬对怎么处理的理解
数据类别不平衡/长尾分布?不妨利用半监督或自监督学习
非均衡分类问题的性能评价指标
常见分类模型( svm,决策树,贝叶斯等)的优缺点,适用场景以及如何选型?
深度 | 解决真实世界问题:如何在不平衡类上使用机器学习?