自定义类加载器
1. 为什么需要自定义类加载器
网上的大部分自定义类加载器文章,几乎都是贴一段实现代码,然后分析一两句自定义
ClassLoader
的 原理。但是我觉得首先得把为什么需要自定义加载器这个问题搞清楚,因为如果不明白它的作用的情况 下,还要去学习它显然是很让人困惑的。
首先介绍自定义类的应用场景:
(1)加密:
Java
代码可以轻易的被反编译,如果你需要把自己的代码进行加密以防止反编译,可以先将 编译后的代码用某种加密算法加密,类加密后就不能再用Java
的
ClassLoader
去加载类了,这时就需要自 定义ClassLoader
在加载类的时候先解密类,然后再加载。
(2)从非标准的来源加载代码:如果你的字节码是放在数据库、甚至是在云端,就可以自定义类加载 器,从指定的来源加载类。
(3)以上两种情况在实际中的综合运用:比如你的应用需要通过网络来传输
Java
类的字节码,为了安 全性,这些字节码经过了加密处理。这个时候你就需要自定义类加载器来从某个网络地址上读取加密后 的字节代码,接着进行解密和验证,最后定义出在Java虚拟机中运行的类。
2. 双亲委派模型
在实现自己的
ClassLoader
之前,我们先了解一下系统是如何加载类的,那么就不得不介绍双亲委派模 型的实现过程。
双亲委派模型的工作过程如下:
(1)当前类加载器从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加 载的类。
(2)如果没有找到,就去委托父类加载器去加载(如代码
c = parent.loadClass(name, false)
所示)。 父类加载器也会采用同样的策略,查看自己已经加载过的类中是否包含这个类,有就返回,没有就委托 父类的父类去加载,一直到启动类加载器。因为如果父加载器为空了,就代表使用启动类加载器作为父 加载器去加载。
(3)如果启动类加载器加载失败(例如在
$JAVA_HOME/jre/lib
里未查找到该
class
),则会抛出一个异 常ClassNotFoundException
,然后再调用当前加载器的
findClass()
方法进行加载。
双亲委派模型的好处:
(1)主要是为了安全性,避免用户自己编写的类动态替换
Java
的一些核心类,比如
String
。
(2)同时也避免了类的重复加载,因为
JVM
中区分不同类,不仅仅是根据类名,相同的
class
文件被不 同的 ClassLoader
加载就是不同的两个类。
3. 自定义类加载器实现
(1)从上面源码看出,调用
loadClass
时会先根据委派模型在父加载器中加载,如果加载失败,则会调 用当前加载器的findClass
来完成加载。
(2)因此我们自定义的类加载器只需要继承
ClassLoader
,并覆盖
findClass
方法,下面是一个实际例 子,在该例中我们用自定义的类加载器去加载我们事先准备好的class
文件。
3.1自定义一个People.java类做例子
public class People {
//该类写在记事本里,在用javac命令行编译成class文件,放在d盘根目录下
private String name;
public People() {}
public People(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return "I am a people, my name is " + name;
}
}3.2自定义类加载器
自定义一个类加载器,需要继承
ClassLoader
类,并实现
findClass
方法。其中
defineClass
方法可以把二 进制流字节组成的文件转换为一个java.lang.Class
(只要二进制字节流的内容符合
Class
文件规范)。
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.nio.ByteBuffer;
import java.nio.channels.Channels;
import java.nio.channels.FileChannel;
import java.nio.channels.WritableByteChannel;
public class MyClassLoader extends ClassLoader
{
public MyClassLoader()
{
}
public MyClassLoader(ClassLoader parent)
{
super(parent);
}
protected Class<?> findClass(String name) throws ClassNotFoundException
{
File file = new File("D:/People.class");
try{
byte[] bytes = getClassBytes(file);
//defineClass方法可以把二进制流字节组成的文件转换为一个java.lang.Class
Class<?> c = this.defineClass(name, bytes, 0, bytes.length);
return c;
}
catch (Exception e)
{
e.printStackTrace();
}
return super.findClass(name);
}
private byte[] getClassBytes(File file) throws Exception
{
// 这里要读入.class的字节,因此要使用字节流
FileInputStream fis = new FileInputStream(file);
FileChannel fc = fis.getChannel();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
WritableByteChannel wbc = Channels.newChannel(baos);
ByteBuffer by = ByteBuffer.allocate(1024);
while (true){
int i = fc.read(by);
if (i == 0 || i == -1)
break;
by.flip();
wbc.write(by);
by.clear();
}
fis.close();
return baos.toByteArray();
}
}3.3在主函数里使用
MyClassLoader mcl = new MyClassLoader();
Class<?> clazz = Class.forName("People", true, mcl);
Object obj = clazz.newInstance();
System.out.println(obj);
System.out.println(obj.getClass().getClassLoader());//打印出我们的自定义类加载器3.4运行结果

Java 中的异常处理
Java 异常类层次结构图
在
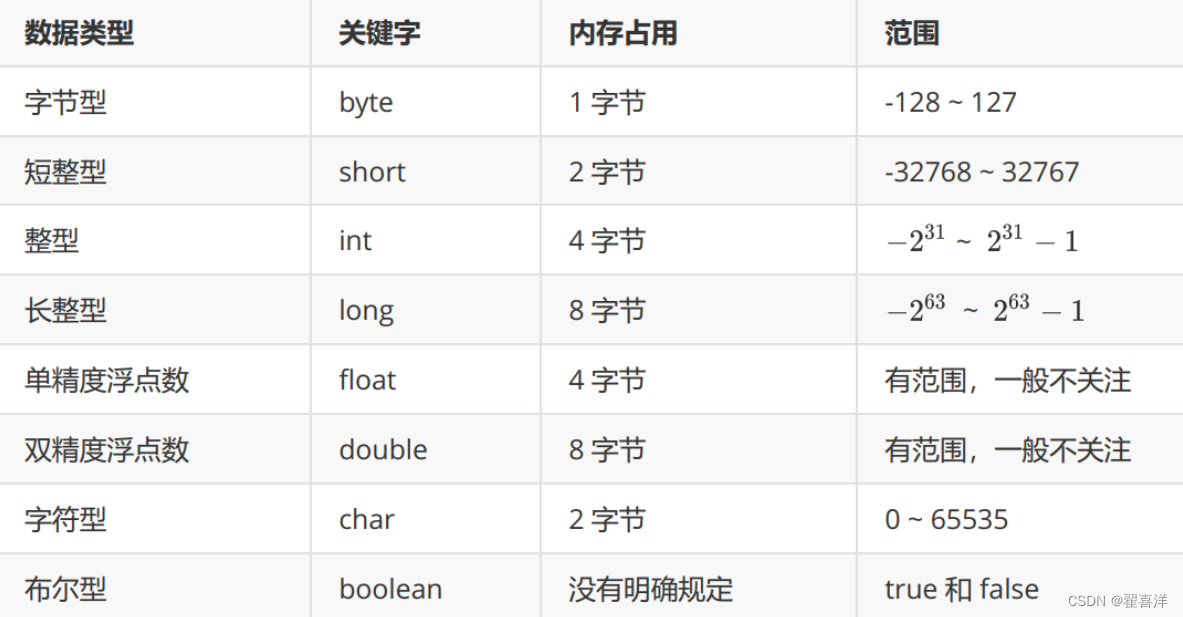
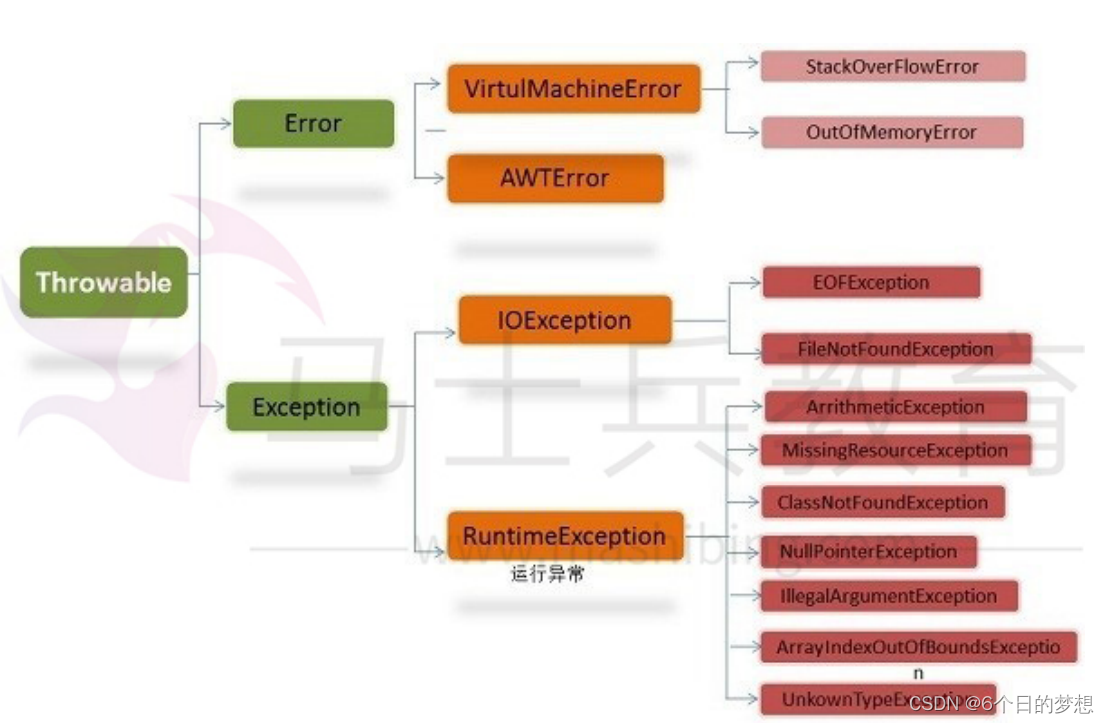
Java
中,所有的异常都有一个共同的祖先
java.lang
包中的
Throwable
类
。
Throwable
: 有两个重 要的子类:Exception
(异常)
和
Error
(错误)
,二者都是
Java
异常处理的重要子类,各自都包含大 量子类。
Error
(错误)
:
是程序无法处理的错误
,表示运行应用程序中较严重问题。大多数错误与代码编写者执 行的操作无关,而表示代码运行时 JVM
(
Java
虚拟机)出现的问题。例如,
Java
虚拟机运行错误 (Virtual MachineError
),当
JVM
不再有继续执行操作所需的内存资源时,将出现
OutOfMemoryError
。这些异常发生时,
Java
虚拟机(
JVM
)一般会选择线程终止。
Exception
(异常)
:
是程序本身可以处理的异常
。
Exception
类有一个重要的子类
RuntimeException
。
RuntimeException
异常由
Java
虚拟机抛出。
NullPointerException
(要访问的变量没有引用任何对象时,抛出该异常)、
ArithmeticException
(算术运算异常,一个整数除以
0
时,抛出该异常)和
ArrayIndexOutOfBoundsException
(下标越界异常)。
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。
4. JAVA8 十大新特性详解
一、接口的默认方法
Java 8
允许我们给接口添加一个非抽象的方法实现,只需要使用
default
关键字即可,这个特征又叫做扩 展方法,示例如下:
代码如下
:
interface Formula {
double calculate(int a);
default double sqrt(int a) {
return Math.sqrt(a);
}
}
Formula
接口在拥有
calculate
方法之外同时还定义了
sqrt
方法,实现了
Formula
接口的子类只需要实现 一个calculate
方法,默认方法
sqrt
将在子类上可以直接使用。
代码如下
:
Formula formula = new Formula() {
@Override
public double calculate(int a) {
return sqrt(a * 100);
}
};
formula.calculate(100); // 100.0
formula.sqrt(16); // 4.0二、Lambda 表达式
首先看看在老版本的
Java
中是如何排列字符串的:
代码如下
:
List names = Arrays.asList("peterF", "anna", "mike", "xenia");
Collections.sort(names, new Comparator() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});
只需要给静态方法
Collections.sort
传入一个
List
对象以及一个比较器来按指定顺序排列。通常做法都是 创建一个匿名的比较器对象然后将其传递给sort
方法。
在
Java 8
中你就没必要使用这种传统的匿名对象的方式了,
Java 8
提供了更简洁的语法,
lambda
表达 式:
代码如下
:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
对于函数体只有一行代码的,你可以去掉大括号
{}
以及
return
关键字,但是你还可以写得更短点:
代码如下
:
Collections.sort(names, (a, b) -> b.compareTo(a));三、函数式接口
代码实现:
public interface Converter<F,T> {
T convert(F from);
}public class Test {
public static void main(String[] args) {
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer convert = converter.convert("123");
System.out.println(convert);
}
}结果:
四、方法与构造函数引用
前一节中的代码还可以通过静态方法引用来表示:
如下:
public static void main(String[] args) {
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer convert = converter.convert("123");
System.out.println(convert);
Converter<String, Integer> converter1 = Integer::valueOf;
Integer convert1 = converter1.convert("123");
System.out.println(convert1);
}
Java 8
允许你使用
::
关键字来传递方法或者构造函数引用
我们也可以引用一个对象的方法,如下:
public class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}public interface PersonFactory {
Person create(String firstName, String lastName);
} public static void main(String[] args) {
PersonFactory personFactory = Person::new;
Person person = personFactory.create("A", "B");
System.out.println(person.firstName);
}![]()
我们只需要使用
Person::new
来获取
Person
类构造函数的引用,
Java
编译器会自动根据
PersonFactory.create
方法的签名来选择合适的构造函数。
看到这些代码不要在懵了,Java现在已经很普遍了。
五、Lambda 作用域
在
lambda
表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了
final
的 外层局部变量,或者实例的字段以及静态变量。
六、访问局部变量
我们可以直接在lambda表达式中访问外层的局部变量:
代码如下
:
final int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
System.out.println(stringConverter.convert(123));
但是和匿名对象不同的是,这里的变量
num
可以不用声明为
final
,该代码同样正确:
int num1 = 1;
Converter<Integer, String> stringConverter1 =
(from) -> String.valueOf(from + num1);
System.out.println(stringConverter1.convert(125));
不过这里的
num
必须不可被后面的代码修改(即隐性的具有
final
的语义),例如下面的就无法编译:
代码如下
:
int num2 = 1;
Converter<Integer, String> stringConverter3 =
(from) -> String.valueOf(from + num2);
num2 = 3;
在
lambda
表达式中试图修改
num
同样是不允许的
七、访问对象字段与静态变量
和本地变量不同的是,
lambda
内部对于实例的字段以及静态变量是即可读又可写。该行为和匿名对象是 一致的:
代码如下
:
public class Lambda4 {
static int outerStaticNum;
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
outerNum = 23;
return String.valueOf(from);
};
}
public static void main(String[] args) {
Converter<Integer, String> stringConverter2 = (from) -> {
outerStaticNum = 72;
return String.valueOf(from);
};
System.out.println(stringConverter2.convert(123));
}
}八、访问接口的默认方法
还记得第一节中的
formula
例子么,接口
Formula
定义了一个默认方法
sqrt
可以直接被
formula
的实例包
括匿名对象访问到,但是在
lambda
表达式中这个是不行的。
Lambda
表达式中是无法访问到默认方法的。
JDK 1.8 API
包含了很多内建的函数式接口,在老
Java
中常用到的比如
Comparator
或者
Runnable
接口, 这些接口都增加了
@FunctionalInterface
注解以便能用在
lambda
上。 Java 8 API同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自
Google Guava
库 里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda
上使用的。
Predicate
接口
Predicate
接口只有一个参数,返回
boolean
类型。该接口包含多种默认方法来将
Predicate
组合成其他
复杂的逻辑(比如:与,或,非):
Predicate predicate = (str) -> str.toString().length() > 4;
boolean foo = predicate.test("foo");
boolean foo1 = predicate.negate().test("foo");
System.out.println(foo);
System.out.println(foo1);
Predicate nonNull = Objects::nonNull;
nonNull.test(null);
Function 接口 、Supplier 接口、Consumer 接口、Comparator
接口 、
Optional
接口
Stream
接口
java.util.Stream
表示能应用在一组元素上一次执行的操作序列。
Stream
操作分为中间操作或者最终操 作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream
本身,这样你就可以将多个操作 依次串起来。Stream
的创建需要指定一个数据源,比如
java.util.Collection
的子类,
List
或者
Set
, Map不支持。
Stream
的操作可以串行执行或者并行执行。
首先看看
Stream
是怎么用,首先创建实例代码的用到的数据
List
:
List stringCollection = new ArrayList<>();
stringCollection.add("ddd2");
stringCollection.add("aaa2");
stringCollection.add("bbb1");
stringCollection.add("aaa1");
stringCollection.add("bbb3");
stringCollection.add("ccc");
stringCollection.add("bbb2");
stringCollection.add("ddd1");
Java 8
扩展了集合类,可以通过
Collection.stream()
或者
Collection.parallelStream()
来创建一个
Stream
。下面几节将详细解释常用的
Stream
操作:
Java 8
扩展了集合类,可以通过
Collection.stream()
或者
Collection.parallelStream()
来创建一个
Stream
。下面几节将详细解释常用的
Stream
操作:
Filter
过滤
过滤通过一个
predicate
接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过 滤后的结果来应用其他Stream
操作(比如
forEach
)。
forEach
需要一个函数来对过滤后的元素依次执 行。forEach
是一个最终操作,所以我们不能在
forEach
之后来执行其他
Stream
操作。
stringCollection
.stream()
.filter((s) -> s.toString().startsWith("a"))
.forEach(System.out::println);Sort 排序
排序是一个中间操作,返回的是排序好后的
Stream
。如果你不指定一个自定义的
Comparator
则会使用 默认排序。
stringCollection
.stream()
.sorted()
.filter((s) -> s.toString().startsWith("a"))
.forEach(System.out::println);
Map
映射
中间操作
map
会将元素根据指定的
Function
接口来依次将元素转成另外的对象,下面的示例展示了将字 符串转换为大写字符串。你也可以通过map
来讲对象转换成其他类型,
map
返回的
Stream
类型是根据你 map传递进去的函数的返回值决定的。
stringCollection
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);
Match
匹配
Stream
提供了多种匹配操作,允许检测指定的
Predicate
是否匹配整个
Stream
。所有的匹配操作都是最 终操作,并返回一个boolean
类型的值。
boolean anyStartsWithA =
stringCollection
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA);// true
Count
计数
计数是一个最终操作,返回
Stream
中元素的个数,返回值类型是
long
。
代码如下
:
long startsWithB =
stringCollection
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB);b开头元素个数: 3
Reduce
规约
这是一个最终操作,允许通过指定的函数来讲
stream
中的多个元素规约为一个元素,规越后的结果是通 过Optional
接口表示的:
Optional reduced =
stringCollection
.stream()
.sorted()
.reduce((s1, s2) -> s1 + "," + s2);
System.out.println(reduced.get());逗号隔开
并行
Streams
// 量小的话可以可以不考虑
前面提到过
Stream
有串行和并行两种,串行
Stream
上的操作是在一个线程中依次完成,而并行
Stream 则是在多个线程上同时执行。
下面的例子展示了是如何通过并行
Stream
来提升性能:
首先我们创建一个没有重复元素的大表:
int max = 1000000;
List values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}
然后我们计算一下排序这个
Stream
要耗时多久,
串行排序:
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
// 串行耗时: 899 ms
并行排序:
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
// 并行排序耗时: 472 ms
上面两个代码几乎是一样的,但是并行版的快了
50%
之多,唯一需要做的改动就是将
stream()
改为
parallelStream()
。
Map
前面提到过,
Map
类型不支持
stream
,不过
Map
提供了一些新的有用的方法来处理一些日常任务。
代码如下
:
Map<Integer, String> map = new HashMap<>();for (int i = 0; i < 10; i++) {map.putIfAbsent(i, "val" + i);}map.forEach((id, val) -> System.out.println(val));
map.computeIfPresent(3, (num, val) -> val + num);
map.get(3); // val33
map.computeIfPresent(9, (num, val) -> null);
map.containsKey(9); // false
map.computeIfAbsent(23, num -> "val" + num);
map.containsKey(23); // true
map.computeIfAbsent(3, num -> "bam");
map.get(3); // val33
对
Map
的元素做合并也变得很容易了:
代码如下
:
map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
map.get(9); // val9
map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
map.get(9); // val9concat