作者🕵️♂️:让机器理解语言か
专栏🎇:PyTorch
描述🎨:PyTorch 是一个基于 Torch 的 Python 开源机器学习库。
寄语💓:🐾没有白走的路,每一步都算数!🐾

介绍💬
数据是深度学习的基础,我们解决的大多数深度学习问题都是需要数据的。而每一种深度学习框架都对数据的格式有自己的要求,因此,本实验主要讲解了 PyTorch 对输入数据的格式要求,以及如何将现实中的数据处理成 PyTorch 能够识别的数据集合。
知识点🍉
- 🍓数据的分批
- 🍓手写字符数据的分批
- 🍓葡萄酒数据的分批(自定义数据集的封装及分批)
数据的分批
由于深度学习中的数据量一般都是极大的,我们无法一次性将所有数据全部加载到内存中。因此,在模型训练之前,一般我们都会对训练集进行分批,将数据随机分成等量的几份,每次迭代只训练一份,如下面的伪代码所示:
# training loop
for epoch in range(num_epochs):
# 遍历所有的批次
for i in range(total_batches):
batch_x, batch_y = ..
上面伪代码可以看出:
- epoch 每增加一次,表示完成了所有数据的一次正向传播和反向传播。
- total_batches 表示分批后的数据集合。
- i 每增加一次,表示完成了一批数据的一次正向传播和反向传播。
那么如何对数据集合进行分批呢?我们可以自己尝试编写数据分批的代码。当然,PyTorch 中也为我们提供了相应的接口,我们可以很容易的实现数据分批的过程。PyTorch 为我们提供了 torch.utils.data.DataLoader 加载器,该加载器可以自动的将传入的数据进行打乱和分批。 DataLoader() 的加载参数如下:
- dataset:需要打乱的数据集。
- batch_size: 每一批的数据条数。
- shuffle:True 或者 False,表示是否将数据打乱后再分批。
当然利用该加载器并不仅仅是对数据进行打乱和分批的操作,该加载器还可以对数据进行格式化处理,使其能够被放入后面的神经网络模型中。接下来,让我们首先利用该加载器对 PyTorch 中自带的数据集合 MNIST 进行分批操作。
MNIST 的分批
首先让我们加载 PyTorch 中的自带数据集合,该数据集合存在于 torchvision.datasets 中,可以直接利用 torchvision.datasets.MNIST 获得:
import torch
import torchvision
# 将数据集合下载到指定目录下
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
train_dataset
从结果可以看出该数据集合共有 60000 条数据。由于这些数据都是图片,因此分批传入内存是非常必要的。
MNIST 数据集合是一个手写字符集合,该数据集合中存储了大量的手写字符图像。我们可以加载一张图片,观察一下:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
a_data, a_label = train_dataset[0]
print("\n打印第一个batch的第一个图像,对应标签数字为{}".format(a_label))
# 显示第一个 batch 中的第一个图像
# 原始数据是归一化后的数据,因此这里需要反归一化
img = np.array(a_data+1)*127.5
img = np.reshape(img, [28, 28]).astype(np.uint8)
plt.imshow(img, 'gray')
plt.show()

该数据集合的分批步骤很简单,只需要将我们得到的数据集合传入 DataLoader 中即可:
from torch.utils.data import DataLoader
train_loader = DataLoader(dataset=train_dataset, batch_size=100, shuffle=True)
num_epochs = 2 # 迭代次数
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
# 每 10 个批次展示一次
if (i+1) % 100 == 0:
print(
f'Epoch: {epoch+1}/{num_epochs},Step {i+1}/{len(train_dataset)/100}| Inputs {inputs.shape} | Labels {labels.shape}')

如上所示,我们对 MNIST 数据集合进行分批,且利用循环对其进行了遍历。在模型训练时,我们将内循环中的代码换成模型训练的代码即可。
上面我们展示的是 PyTorch 中自带的数据集合的分批步骤,但是该库并没有包含全世界所有的数据集合。如果我们需要将自己的数据集合进行分批,应该怎么做呢?
在 DataLoader 传入的参数值,我们需要注意的是 dataset 参数。该参数是一个 Dataset 类,即只有继承了 PyTorch 中的 Dataset 接口的类,才能够被传入 DataLoader 中。因此,针对于自己的数据集合,我们往往需要对原始的数据进行处理,将其封装成一个继承了 Dataset 的 Python 类。这样,我们才能够将其传入 PyTorch 之中,进行数据的分批和模型的训练。
葡萄酒数据的分批
接下来,让我们以葡萄酒的种类预测为例,详细的阐述自定义数据应当如何进行封装和分批。
首先,我们将对葡萄酒数据进行分批操作,让我们先来加载数据集合:
import pandas as pd
df = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/2316/wine.csv", header=None)
df
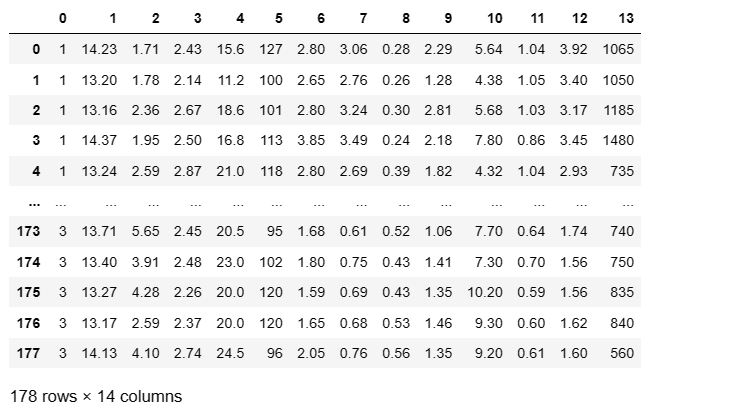
如上表所示,第一列表示该条数据属于哪一种葡萄酒(0,1,2)。而后面 13 列的数据表示的就是葡萄酒的每种化学成分的浓度。这些化学成分分别为:酒精 、苹果酸 、灰分 、灰分的碱度、镁 、总酚、 黄酮类化合物 、非类黄酮酚 、原花色素 、颜色强度 、色相 、稀释酒的 OD280/OD315 和脯氨酸。
🌿数据封装
我们需要对这些数据进行分批,那么我们就需要将该数据转为 PyTorch 认识的数据集合。我们可以建立一个类 WineDataset 去继承 Dataset。
如果继承了 Dataset 类,我们就必须实现下面三个函数:
__init__(self):用于初始化类中所需要的一些变量。__len__(self): 返回数据集合的长度,即数据量大小。__getitem__(self, index):返回第 index 条数据
from torch.utils.data import Dataset
class WineDataset(Dataset):
# 建立一个数据集合继承 Dataset 即可
def __init__(self):
# I初始化数据
# 以pandas的形式读入数据
xy = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/2316/wine.csv", header=None)
self.n_samples = xy.shape[0] # shape[0]:样本数,shape[1]:特征数
# 将 pandas 类型的数据转换成 numpy 类型
self.x_data = torch.from_numpy(xy.values[:, 1:]) # size [n_samples, n_features]
self.y_data = torch.from_numpy(xy.values[:, [0]]) # size [n_samples, 1]
# 返回 dataset[index]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据长度
def __len__(self):
return self.n_samples
# 测试
# 创造 dataset
dataset = WineDataset()
dataset[0]

🌿数据分批
至此,我们将葡萄酒数据也装上了一个“外壳”,使 PyTorch 能够识别出该数据集合。接下来,我们只需要利用 DataLoader 加载该数据集合即可:
import math
# 传入加载器
train_loader = DataLoader(dataset=dataset, batch_size=4, shuffle=True)
# 分批训练
# 迭代次数
num_epochs = 2
total_samples = len(dataset)
# 批次
n_iterations = math.ceil(total_samples/4)
print("该数据集合共有{}条数据,被分成了{}个批次".format(total_samples, n_iterations))
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
# 178 个样本, batch_size = 4, n_iters=178/4=44.5 -> 45 个批次
if (i+1) % 5 == 0:
print(
f'Epoch: {epoch+1}/{num_epochs}, Step {i+1}/{n_iterations}| Inputs {inputs.shape} | Labels {labels.shape}')

从结果可以看出,我们按照每个批次 batch_size 个,将数据集合分成了 45 个批次,并对这些批次进行了 2 次迭代。由于数据总量不是 batch_size 的整数倍,因此最后一个批次的数据量为 total_samples 除以 batc_size 的余数个。
实验总结🔑
本实验详细的阐述了数据分批的重要性。并且以手写字符数据集和葡萄酒数据集为例,阐述了如何将一个数据集合转成 PyTorch 能够使用的数据集。