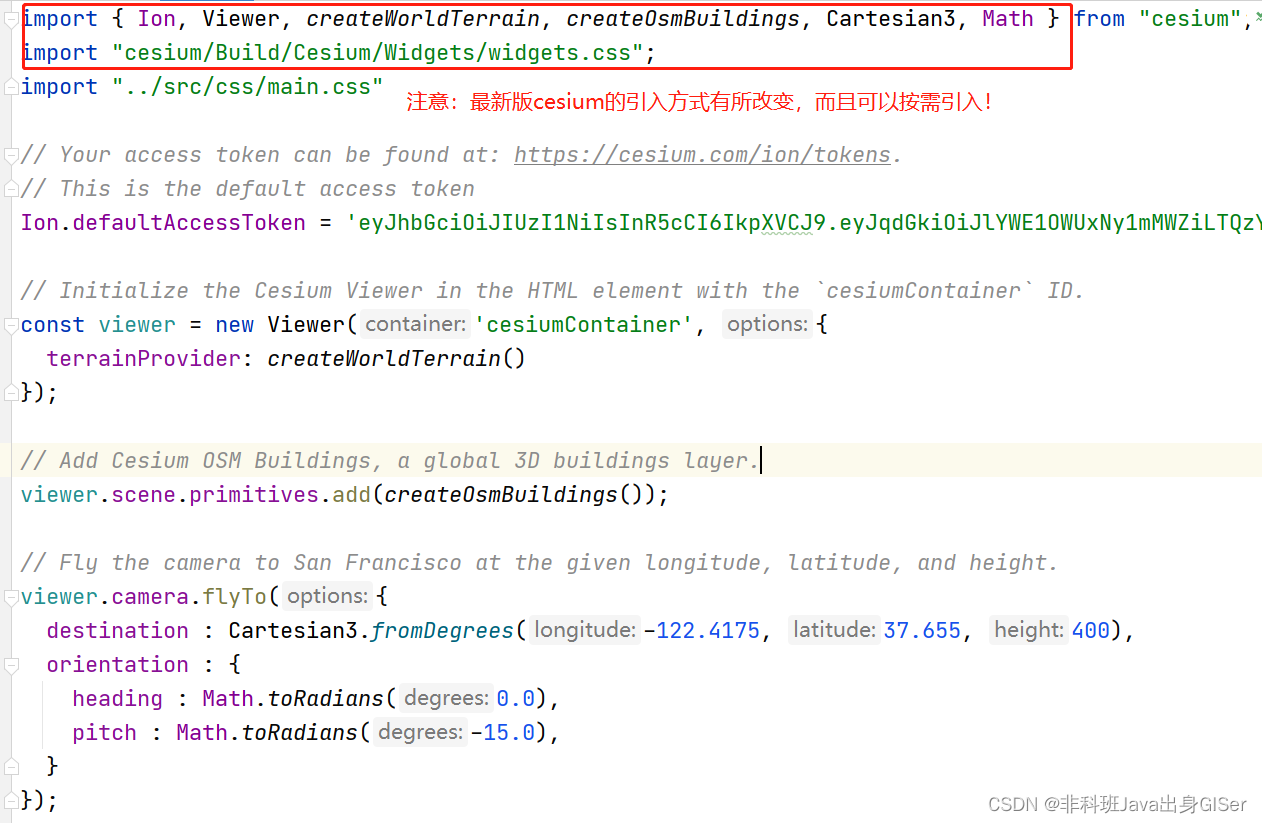
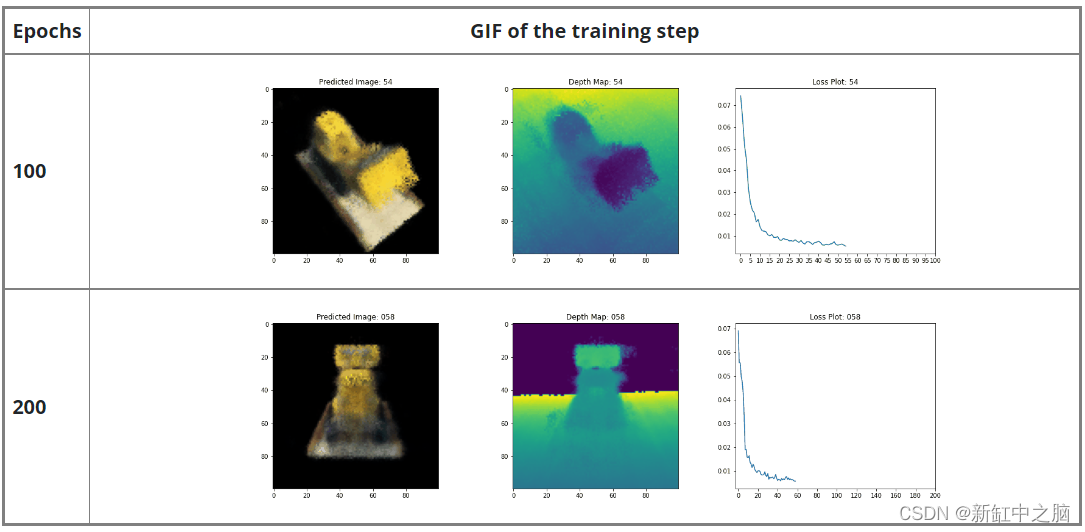
原理
原理类似文章点云梯度下采样中提到的梯度下采样。
大致采样思路如下:
Step1:计算出每个待采样点 p i p_i pi 的梯度 G i G_i Gi,并计算节点点云整体的平均梯度作为梯度阈值 G t G_t Gt。
Step2:比较 G i G_i Gi 与梯度阈值 G t G_t Gt 大小,如果小于梯度阈值 G t G_t Gt,则把采样点 p i p_i pi 划分到节点属性变化剧烈区间,反之划分到节点属性变化缓慢区间。
Step3:采用均匀网格法对两个区域的节点点云进行精简(下采样),剧烈区间和缓慢区间的边长阈值分别设置为 A A A 和 B B B ,并且 A < B A < B A<B。
相对空间离散三维点的梯度下采样,一维离散数据分区采样只是在维度上降到了一维,其余采样点计算流程并无差异。
代码实现
def SamplingDiscrete1D():
y = np.loadtxt('y_data.csv', delimiter = ',')
y_t = np.mean(y)
a_x, b_x = [], []
for i, y_i in enumerate(y):
if y_i > y_t:
a_x.append(i + 1)
else:
b_x.append(i + 1)
def uniform_sample(origin_points, interval):
filtered_points = []
# 计算边界点和划分区间数量
x_min, x_max = np.amin(y), np.amax(y)
h = [] # h 为保存索引的列表
for j in range(len(origin_points)):
hx = (origin_points[j] - x_min) // interval
h.append(hx)
h = np.array(h)
# 采样点
h_indice = np.argsort(h) # 返回h里面的元素按从小到大排序的索引
h_sorted = h[h_indice]
begin = 0
for j in range(len(h_sorted)):
point_idx = h_indice[begin: j + 1]
if j == len(h_sorted) - 1: # 到最后一个区间的最后一个点
filtered_points.append(np.round(np.mean(origin_points[point_idx]))) # 计算最后一个体素的采样点
continue
if h_sorted[j] == h_sorted[j + 1]:
continue
else:
filtered_points.append(np.round(np.mean(origin_points[point_idx])))
begin = j + 1
return filtered_points
filter_a = uniform_sample(np.array(a_x), 4)
filter_b = uniform_sample(np.array(b_x), 20)
sample_point = sorted(set(list(map(int, filter_a + filter_b))))
print(len(sample_point))
# print(sample_point)
return sample_point
其中通过如下两行代码进行分区均匀采样。
filter_a = uniform_sample(np.array(a_x), 4)
filter_b = uniform_sample(np.array(b_x), 20)
4和20分别为filter_a(变化剧烈分区)和filter_b(变化缓慢分区)的采样间隙大小。
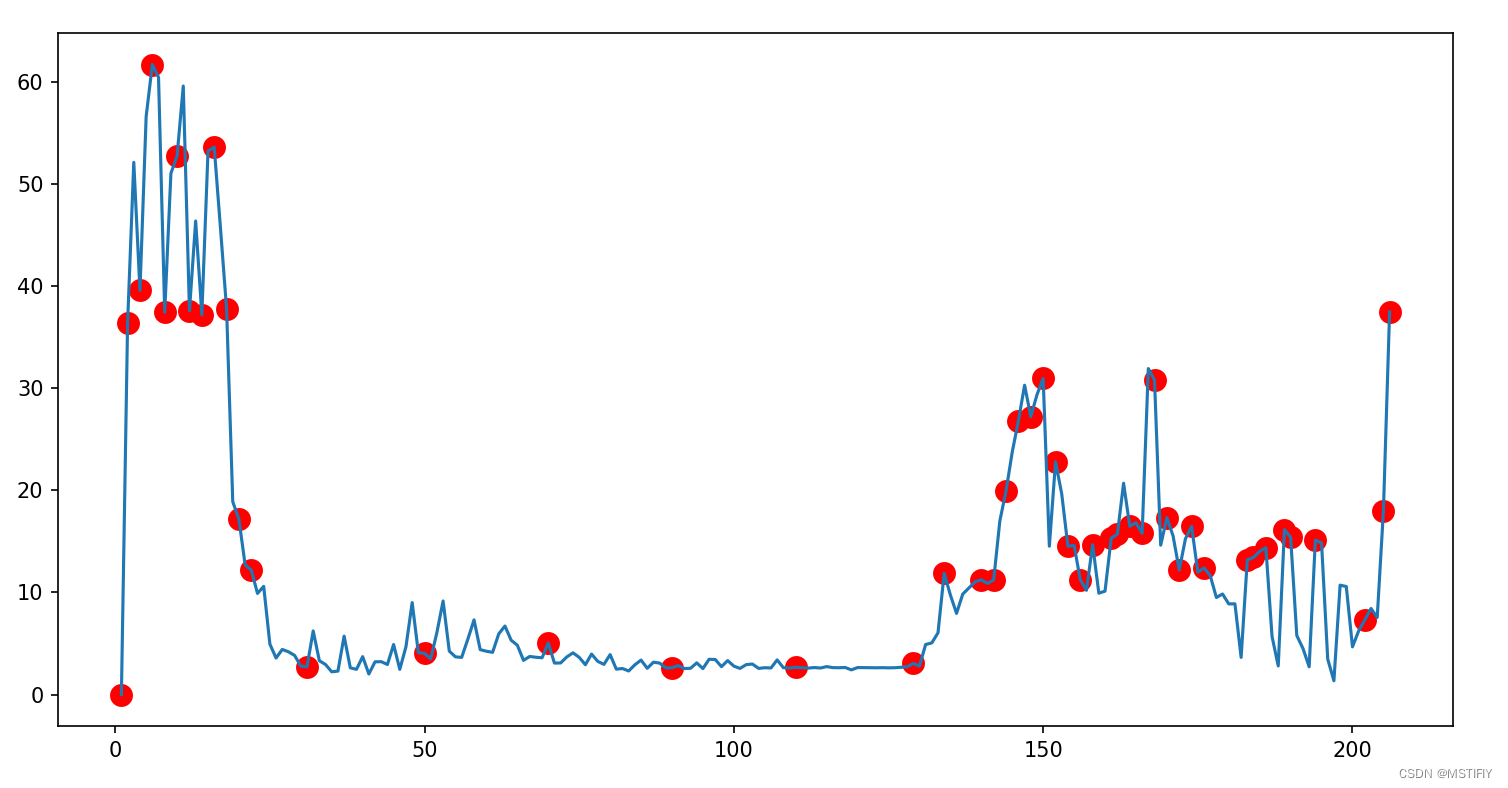
测试结果
filter_a=4,filter_b=20。
待采样点总数206,采样点总数32。
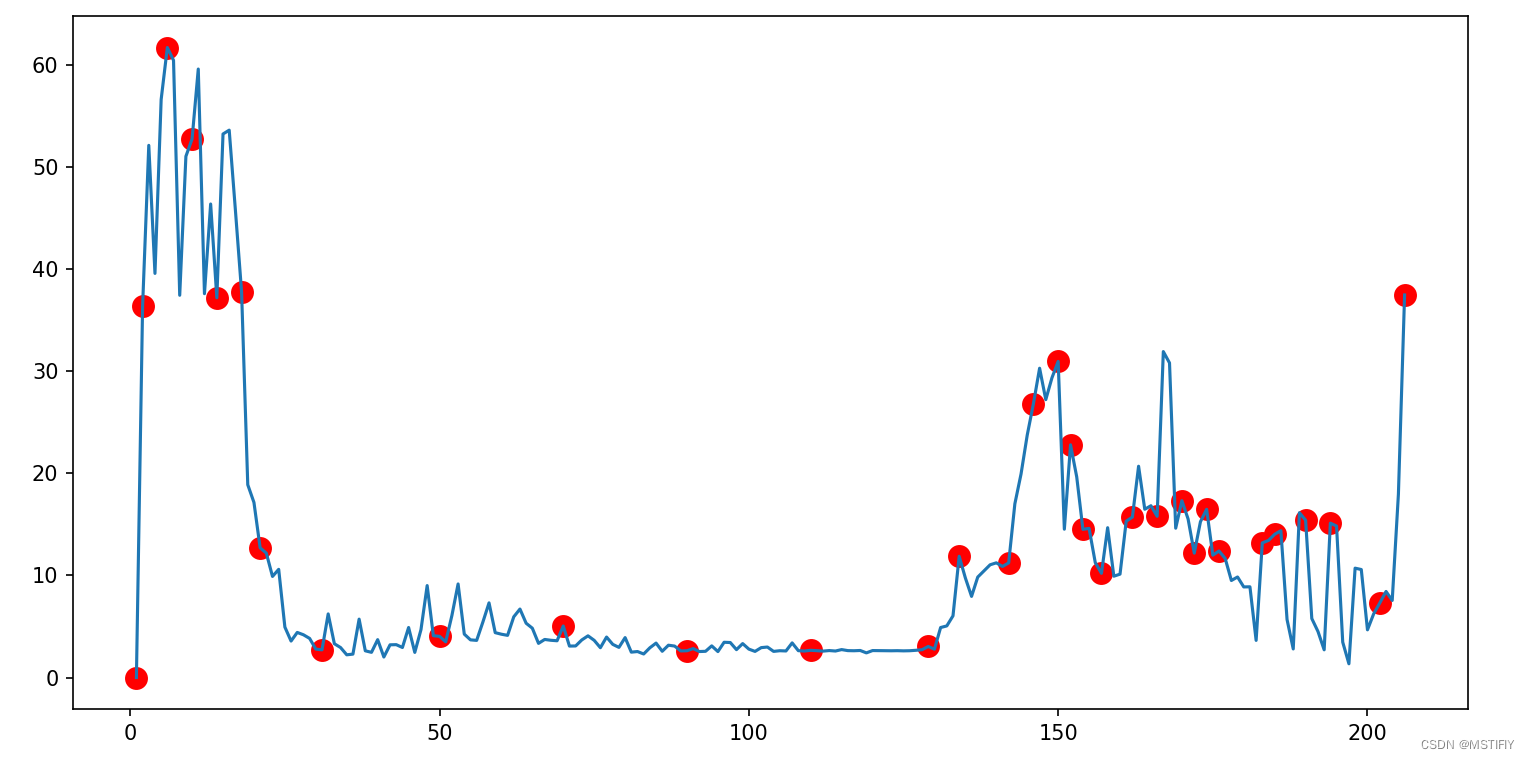
filter_a=2,filter_b=20。
待采样点总数206,采样点总数47。





![[glacierctf 2022] 只会3个](https://img-blog.csdnimg.cn/28f8e956b66042c490a77ab0fd46c28d.jpeg)