原文:Intelligent mobile projects with TensorFlow
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
十一、在移动设备上使用 TensorFlow Lite 和 Core ML
在前九章中,我们使用 TensorFlow Mobile 在移动设备上运行各种由 TensorFlow 和 Keras 构建的强大的深度学习模型。 正如我们在第 1 章,“移动 TensorFlow 入门”中提到的那样,Google 还提供了 TensorFlow Lite(可替代 TensorFlow Mobile 的版本)在移动设备上运行模型。 尽管自 Google I/O 2018 起它仍在开发人员预览中,但 Google 打算“大大简化开发人员针对小型设备的模型定位的体验。” 因此,值得详细研究 TensorFlow Lite 并为未来做好准备。
如果您是 iOS 开发人员,或者同时使用 iOS 和 Android,则 Apple 一年一度的全球开发人员大会(WWDC)是您不容错过的活动。 在 WWDC 2017 中,Apple 宣布了新的 Core ML 框架,以支持 iOS(以及所有其他 Apple OS 平台:macOS,tvOS 和 watchOS)上的深度学习模型和标准机器学习模型的运行。 自 iOS 11 起,Core ML 就可用了,截至 2018 年 5 月,Core ML 已占到 80% 的标记份额。至少了解您可以在 iOS 应用中使用 Core ML 的基本知识绝对有意义。
因此,我们将在本章涵盖 TensorFlow Lite 和 Core ML,并通过以下主题展示两者的优势和局限性:
- TensorFlow Lite - 概述
- 在 iOS 中使用 TensorFlow Lite
- 在 Android 中使用 TensorFlow Lite
- 适用于 iOS 的 CoreML - 概述
- 结合使用 CoreML 和 Scikit-Learn 机器学习
- 将 CoreML 与 Keras 和 TensorFlow 结合使用
TensorFlow Lite – 概述
TensorFlow Lite 是一种轻量级解决方案,可在移动和嵌入式设备上运行深度学习模型。 如果可以将 TensorFlow 或 Keras 内置的模型成功转换为 TensorFlow Lite 格式,请基于 FlatBuffers,与 ProtoBuffers ProtoBuffers 类似,但速度更快,并且大小要小得多。 “检测对象及其位置” 和,然后可以期望模型以低延迟和较小的二进制大小运行。 在您的移动应用中使用 TensorFlow Lite 的基本工作流程如下:
- 使用 TensorFlow 或 Keras 以 TensorFlow 作为后端来构建和训练(或重新训练)TensorFlow 模型,例如我们在前几章中训练的模型。
您还可以选择一个预先构建的 TensorFlow Lite 模型,例如可从以下位置获得的 MobileNet 模型,我们在第 2 章,《使用迁移学习对图像进行分类》中将其用于再训练。 您可以在此处下载的每个 MobileNet 模型tgz文件都包含转换后的 TensorFlow Lite 模型。 例如,MobileNet_v1_1.0_224.tgz文件包含一个mobilenet_v1_1.0_224.tflite文件,您可以直接在移动设备上使用它。 如果使用这样的预构建 TensorFlow Lite 模型,则可以跳过步骤 2 和 3。
-
构建 TensorFlow Lite 转换器工具。 如果您从这里下载 TensorFlow 1.5 或 1.6 版本,则可以从 TensorFlow 源根目录在终端上运行
bazel build tensorflow/contrib/lite/toco:toco。 如果您使用更高版本或获取最新的 TensorFlow 仓库,您应该可以使用此build命令来执行此操作,但如果没有,请查看该新版本的文档。 -
使用 TensorFlow Lite 转换器工具将 TensorFlow 模型转换为 TensorFlow Lite 模型。 在下一节中,您将看到一个详细的示例。
-
在 iOS 或 Android 上部署 TensorFlow Lite 模型-对于 iOS,使用 C++ API 加载和运行模型; 对于 Android,请使用 Java API(围绕 C++ API 的包装器)加载和运行模型。 与我们之前在 TensorFlow Mobile 项目中使用的
Session类不同,C++ 和 Java API 均使用 TensorFlow-lite 特定的Interpreter类来推断模型。 在接下来的两个部分中,我们将向您展示 iOS C++ 代码和 Android Java 代码以使用Interpreter。
如果您在 Android 上运行 TensorFlow Lite 模型,并且 Android 设备为 Android 8.1(API 级别 27)或更高版本,并且通过专用的神经网络硬件,GPU 或某些其他数字信号处理器支持硬件加速,则Interpreter将使用 Android 神经网络 API来加快模型运行。 例如,谷歌的 Pixel 2 手机具有针对图像处理进行了优化的自定义芯片,可以通过 Android 8.1 开启该芯片,并支持硬件加速。
现在让我们看看如何在 iOS 中使用 TensorFlow Lite。
在 iOS 中使用 TensorFlow Lite
在向您展示如何创建新的 iOS 应用并向其添加 TensorFlow Lite 支持之前,让我们首先看一下使用 TensorFlow Lite 的几个示例 TensorFlow iOS 应用。
运行示例 TensorFlow Lite iOS 应用
有两个用于 iOS 的 TensorFlow Lite 示例应用,名为simple and camera,类似于 TensorFlow Mobile iOS 应用 simple 和 camera,但在 TensorFlow 1.5-1.8 的官方版本中的 TensorFlow Lite API 中实现,并且可能也在最新的 TensorFlow 仓库中。 您可以运行以下命令来准备和运行这两个应用,类似地在“iOS 演示应用”下进行了记录:
cd tensorflow/contrib/lite/examples/ios
./download_models.sh
sudo gem install cocoapods
cd camera
pod install
open tflite_camera_example.xcworkspace
cd ../simple
pod install
open simple.xcworkspace
现在,您将有两个 Xcode iOS 项目,分别是 simple 和 camera(在 Xcode 中分别命名为 tflite_simple_example和 tflite_camera_example),并启动了,您可以在您的 iOS 设备中安装和运行它们(简单的应用也可以在您的 iOS 模拟器上运行)。
download_models.sh will download a zip file that contains the mobilenet_quant_v1_224.tflite model file and labels.txt label file, then copy them to the simple/data and camera/data directories. Notice that somehow this script is not included in the official TensorFlow 1.5.0 and 1.6.0 releases. You’ll need to do git clone https://github.com/tensorflow/tensorflow and clone the latest source (as of March 2018) to get it.
您可以查看 Xcode tflite_camera_example项目的CameraExampleViewController.mm文件和tflite_simple_example RunModelViewController.mm文件中的源代码,以了解如何使用 TensorFlow Lite API 加载和运行 TensorFlow Lite 模型。 在逐步指导您如何创建新的 iOS 应用并向其添加 TensorFlow Lite 支持以运行预先构建的 TensorFlow Lite 模型的逐步教程之前,我们将快速以具体数字向您展示使用 TensorFlow Lite-应用的好处之一,如前所述,二进制大小:
位于tensorflow/examples/ios/camera文件夹中的 TensorFlow Mobile 示例应用tf_camera_example 中使用的tensorflow_inception.graph.pb模型文件为 95.7MB,而位于tensorflow/contrib/lite/examples/ios/camera文件夹中的 tflite_camera_example TensorFlow Lite 示例应用中使用的模型文件mobilenet_quant_v1_224.tflite仅 4.3MB。 TensorFlow Mobile 重新训练的 Inception 3 模型文件的量化版本,如我们在第 2 章,“通过迁移学习对图像进行分类”的 HelloTensorFlow 应用中所见,约为 22.4MB,并且重新训练的 MobileNet TensorFlow Mobile 模型文件为 17.6MB。 总之,以下列出了四种不同类型的模型的大小:
- TensorFlow Mobile Inception 3 模型:95.7MB
- 量化和重新训练的 TensorFlow Mobile Inception 3 模型:22.4MB
- 训练有素的 TensorFlow Mobile MobileNet 1.0 224 模型:17.6MB
- TensorFlow Lite MobileNet 1.0 224 模型:4.3MB
如果在 iPhone 上安装并运行这两个应用,则从 iPhone 的设置中将看到 tflite_camera_example的应用大小约为 18.7MB,tf_camera_example的大小约为 44.2MB。
的确,Inception 3 模型的准确率比 MobileNet 模型要高,但是在许多使用情况下,可以忽略很小的准确率差异。 另外,不可否认,如今的移动应用很容易占用数十 MB 的空间,在某些用例中,应用大小相差 20 或 30MB 听起来并不大,但是在较小的嵌入式设备中,大小会更加敏感,如果我们可以以更快的速度和更小的大小获得几乎相同的精度,而不会遇到太多麻烦,对于用户而言,这永远是一件好事。
在 iOS 中使用预构建的 TensorFlow Lite 模型
使用预构建的 TensorFlow Lite 模型进行图像分类,执行以下步骤来创建新的 iOS 应用并向其添加 TensorFlow Lite 支持:
- 使用 Single View 创建一个名为 HelloTFLite 的新 Xcode iOS 项目,将 Objective-C 设置为语言,然后将
tensorflow/contrib/lite/examples/ios文件夹中的ios_image_load.mm和ios_image_load.h文件添加到项目中。
If you prefer Swift as the programming language, you can refer to Chapter 2, Classifying Images with Transfer Learning, or Chapter 5, Understanding Simple Speech Commands, after following the steps here, to see how to convert the Objective-C app to a Swift app. But be aware that the TensorFlow Lite inference code still needs to be in C++ so you’ll end up with a mix of Swift, Objective-C, and C++ code, with your Swift code mainly responsible for the UI and pre- and post-processing of the TensorFlow Lite inference.
-
将使用
tensorflow/contrib/lite/examples/ios/simple/data文件夹中的前面的download_models.sh脚本生成的模型文件和标签文件,以及第二章源代码文件夹中的测试图像(例如lab1.jpg)添加到项目中。 -
关闭项目并创建一个名为
Podfile的新文件,其内容如下:
platform :ios, '8.0'
target 'HelloTFLite'
pod 'TensorFlowLite'
运行pod install。 然后在 Xcode 中打开 HelloTFLite.xcworkspace,将ViewController.m重命名为ViewController.mm,并添加必要的 C++ 头文件和 TensorFlow Lite 头文件。 您的 Xcode 项目应类似于以下屏幕截图:
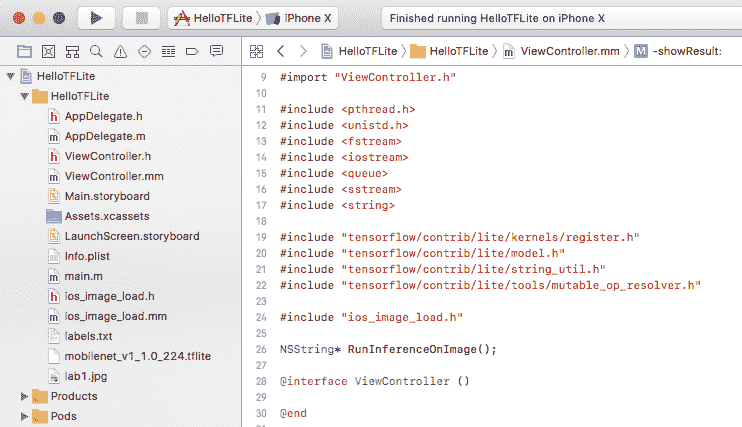
图 11.1:使用 TensorFlow Lite Pod 的新 Xcode iOS 项目
我们仅向您展示如何在 iOS 应用中使用 TensorFlow Lite Pod。 还有另一种将 TensorFlow Lite 添加到 iOS 的方法,类似于构建自定义 TensorFlow Mobile iOS 库的过程,我们在前几章中已经做过很多次了。 有关如何构建自己的自定义 TensorFlow Lite iOS 库的更多信息,请参阅以下位置的文档。
- 将第 2 章,“通过迁移学习对图像进行分类”的 iOS 应用中的类似 UI 代码复制到
ViewController.mm,后者使用UITapGestureRecognizer捕获屏幕上的用户手势,然后调用RunInferenceOnImage方法,该方法将加载 TensorFlow Lite 模型文件:
NSString* RunInferenceOnImage() {
NSString* graph = @"mobilenet_v1_1.0_224";
std::string input_layer_type = "float";
std::vector<int> sizes = {1, 224, 224, 3};
const NSString* graph_path = FilePathForResourceName(graph, @"tflite");
std::unique_ptr<tflite::FlatBufferModel> model(tflite::FlatBufferModel::BuildFromFile([graph_path UTF8String]));
if (!model) {
NSLog(@"Failed to mmap model %@.", graph);
exit(-1);
}
- 创建
Interpreter类的实例并设置其输入:
tflite::ops::builtin::BuiltinOpResolver resolver;
std::unique_ptr<tflite::Interpreter> interpreter;
tflite::InterpreterBuilder(*model, resolver)(&interpreter);
if (!interpreter) {
NSLog(@"Failed to construct interpreter.");
exit(-1);
}
interpreter->SetNumThreads(1);
int input = interpreter->inputs()[0];
interpreter->ResizeInputTensor(input, sizes);
if (interpreter->AllocateTensors() != kTfLiteOk) {
NSLog(@"Failed to allocate tensors.");
exit(-1);
}
与 TensorFlow Mobile 不同,TensorFlow Lite 在馈入 TensorFlow Lite 模型进行推理时使用interpreter->inputs()[0]而不是特定的输入节点名称。
- 在以与在
HelloTensorFlow应用中相同的方式加载labels.txt文件后,也以相同的方式加载要分类的图像,但是使用 TensorFlow Lite 的Interpreter的typed_tensor方法而不是 TensorFlow Mobile 的Tensor类及其tensor方法。 图 11.2 比较了用于加载和处理图像文件数据的 TensorFlow Mobile 和 Lite 代码:

图 11.2:TensorFlow Mobile(左)和 Lite 代码,用于加载和处理图像输入
- 在调用
GetTopN辅助方法以获取前N个分类结果之前,调用Interpreter上的Invoke方法运行模型,并调用typed_out_tensor方法以获取模型的输出。 TensorFlow Mobile 和 Lite 之间的代码差异如图 11.3 所示:

图 11.3:运行模型并获取输出的 TensorFlow Mobile(左)和 Lite 代码
- 以类似于 HelloTensorFlow 中方法的方式实现
GetTopN方法,对于 TensorFlow Lite 使用const float* prediction类型而不是对于 TensorFlow Mobile 使用const Eigen::TensorMap<Eigen::Tensor<float, 1, Eigen::RowMajor>, Eigen::Aligned>& prediction。 TensorFlow Mobile 和 Lite 中GetTopN方法的比较如图 11.4 所示:
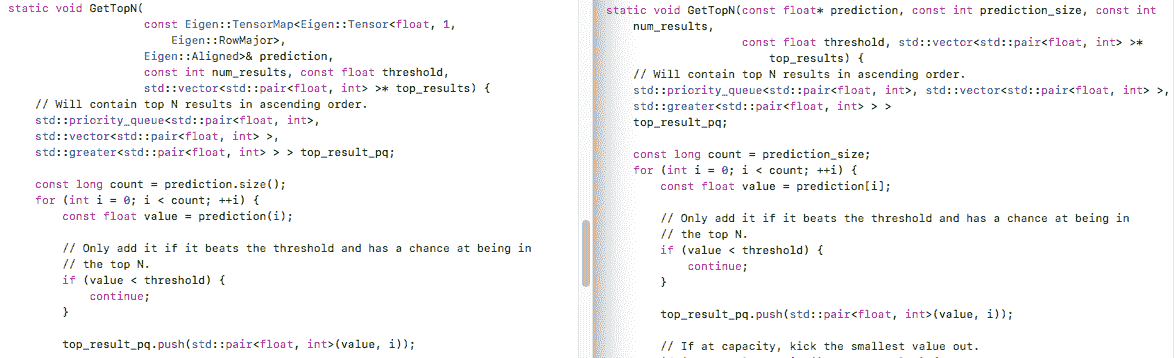
图 11.4:处理模型输出以返回最高结果的 TensorFlow Mobile(左)和 Lite 模型代码
- 如果值大于阈值(设置为
0.1f),则使用简单的UIAlertController显示带有 TensorFlow Lite 模型返回的置信度值的最佳结果:
-(void) showResult:(NSString *)result {
UIAlertController* alert = [UIAlertController alertControllerWithTitle:@"TFLite Model Result" message:result preferredStyle:UIAlertControllerStyleAlert];
UIAlertAction* action = [UIAlertAction actionWithTitle:@"OK" style:UIAlertActionStyleDefault handler:nil];
[alert addAction:action];
[self presentViewController:alert animated:YES completion:nil];
}
-(void)tapped:(UITapGestureRecognizer *)tapGestureRecognizer {
NSString *result = RunInferenceOnImage();
[self showResult:result];
}
立即运行 iOS 应用,然后点击屏幕以运行模型。 对于lab1.jpg测试图像,您将在图 11.5 中看到模型的结果:

图 11.5:测试图像和模型推断结果
这就是您可以在新的 iOS 应用中使用预构建的 MobileNet TensorFlow Lite 模型的方式。 现在让我们看看如何使用经过重新训练的 TensorFlow 模型。
在 iOS 中为 TensorFlow Lite 使用经过重新训练的 TensorFlow 模型
在第 2 章,”通过迁移学习对图像进行分类“中,我们重新训练了 MobileNet TensorFlow 模型来进行狗的品种识别任务,并且要在 TensorFlow Lite 中使用这种模型,我们首先需要使用 TensorFlow Lite 转换工具将其转换为 TensorFlow Lite 格式:
bazel build tensorflow/contrib/lite/toco:toco
bazel-bin/tensorflow/contrib/lite/toco/toco \
--input_file=/tmp/dog_retrained_mobilenet10_224_not_quantized.pb \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--output_file=/tmp/dog_retrained_mobilenet10_224_not_quantized.tflite --inference_type=FLOAT \
--input_type=FLOAT --input_array=input \
--output_array=final_result --input_shape=1,224,224,3
我们必须使用--input_array和--output_array指定输入节点名称和输出节点名称。 有关转换器工具的详细命令行参数,请参阅这里。
添加转换后的dog_retrained_mobilenet10_224_not_quantized.tflite TensorFlow Lite 模型文件,以及相同的dog_retrained_labels.txt 标签文件 HelloTensorFlow到 Xcode 项目,只需将步骤 4 中的行从 NSString* graph = @"mobilenet_v1_1.0_224"; 更改为 NSString* graph = @"dog_retrained_mobilenet10_224_not_quantized"; 和 const int output_size = 1000; 更改为 const int output_size = 121; (回想一下 MobileNet 模型对 1,000 个对象进行分类,而我们的训练后的狗模型则对 121 个犬种进行了分类),然后使用 TensorFlow Lite 格式的训练后的模型再次运行该应用。 结果将大致相同。
因此,在我们成功将其转换为 TensorFlow Lite 模型之后,使用经过重新训练的 MobileNet TensorFlow 模型非常简单。 那本书和其他地方介绍的所有那些定制模型呢?
在 iOS 中使用自定义 TensorFlow Lite 模型
在前面的章节中,我们已经训练了许多定制的 TensorFlow 模型,并将其冻结以供移动使用。 不幸的是,如果您尝试使用上一节中内置的bazel-bin/tensorflow/contrib/lite/toco/toco TensorFlow Lite 转换工具,将模型从 TensorFlow 格式转换为 TensorFlow Lite 格式,则它们都会失败,除了第 2 章, “通过迁移学习对图像进行分类”的再训练模型; 大多数错误属于“转换不受支持的操作”类型。 例如,以下命令尝试将第 3 章, “检测对象及其位置” 中的 TensorFlow 对象检测模型转换为 TensorFlow Lite 格式:
bazel-bin/tensorflow/contrib/lite/toco/toco \
--input_file=/tmp/ssd_mobilenet_v1_frozen_inference_graph.pb \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--output_file=/tmp/ssd_mobilenet_v1_frozen_inference_graph.tflite --inference_type=FLOAT \
--input_type=FLOAT --input_arrays=image_tensor \
--output_arrays=detection_boxes,detection_scores,detection_classes,num_detections \
--input_shapes=1,224,224,3
但是 TensorFlow 1.6 中会出现很多错误,包括:
Converting unsupported operation: TensorArrayV3
Converting unsupported operation: Enter
Converting unsupported operation: Equal
Converting unsupported operation: NonMaxSuppressionV2
Converting unsupported operation: ZerosLike
以下命令尝试将第 4 章的神经风格迁移模型转换为 TensorFlow Lite 格式:
bazel-bin/tensorflow/contrib/lite/toco/toco \
--input_file=/tmp/stylize_quantized.pb \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--output_file=/tmp/stylize_quantized.tflite --inference_type=FLOAT \
--inference_type=QUANTIZED_UINT8 \
--input_arrays=input,style_num \
--output_array=transformer/expand/conv3/conv/Sigmoid \
--input_shapes=1,224,224,3:26
以下命令尝试转换第 10 章中的模型:
bazel-bin/tensorflow/contrib/lite/toco/toco \
--input_file=/tmp/alphazero19.pb \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--output_file=/tmp/alphazero19.tflite --inference_type=FLOAT \
--input_type=FLOAT --input_arrays=main_input \
--output_arrays=value_head/Tanh,policy_head/MatMul \
--input_shapes=1,2,6,7
但是,您还将收到许多“转换不受支持的操作”错误。
截至 2018 年 3 月以及 TensorFlow 1.6 中,TensorFlow Lite 仍在开发人员预览版中,但将来的发行版将支持更多操作,因此如果您想在 TensorFlow 1.6 中尝试 TensorFlow Lite,则应该将自己限制于预训练和重新训练的 Inception 和 MobileNet 模型,同时关注将来的 TensorFlow Lite 版本。 本书前面和其他章节中介绍的更多 TensorFlow 模型有可能会在 TensorFlow 1.7 或阅读本书时成功转换为 TensorFlow Lite 格式。
但是至少到目前为止,对于使用 TensorFlow 或 Keras 构建的自定义复杂模型,很可能您将无法成功进行 TensorFlow Lite 转换,因此您应该继续使用 TensorFlow Mobile,如前几章所述。现在,除非您致力于使它们与 TensorFlow Lite 一起使用,并且不介意帮助添加更多由 TensorFlow Lite 支持的操作-毕竟 TensorFlow 是一个开源项目。
在完成 TensorFlow Lite 的介绍之前,我们将看一下如何在 Android 中使用 TensorFlow Lite。
在 Android 中使用 TensorFlow Lite
为简单起见,我们将仅演示如何在新的 Android 应用中将 TensorFlow Lite 与预构建的 TensorFlow Lite MobileNet 模型一起添加,并在此过程中发现一些有用的技巧。 有一个使用 TensorFlow Lite 的示例 Android 应用,您可能希望首先在具有 API 级别的 Android 设备上与 Android Studio 一起运行。在执行以下步骤在新的 Android 应用中使用 TensorFlow Lite 之前,至少需要 15 个(版本至少为 4.0.3)。 如果您成功构建并运行了演示应用,则在 Android 设备上移动时,应该能够通过设备摄像头和 TensorFlow Lite MobileNet 模型看到识别出的对象。
现在执行以下步骤来创建一个新的 Android 应用,并添加 TensorFlow Lite 支持以对图像进行分类,就像我们在第 2 章,“通过迁移学习对图像进行分类”中的 HelloTensorFlow Android 应用一样:
-
创建一个新的 Android Studio 项目,并将应用命名为
HelloTFLite。 将最低 SDK 设置为 API 15:Android 4.0.3,并接受所有其他默认设置。 -
创建一个新的
assets文件夹,从演示应用tensorflow/contrib/lite/java/demo/app/src/main/assets文件夹中拖放mobilenet_quant_v1_224.tfliteTensorFlow Lite 文件和labels.txt文件,以及测试图像到 HelloTFLite 应用的assets文件夹中。 -
将
ImageClassifier.java文件从tensorflow/contrib/lite/java/demo/app/src/main/java/com/example/android/tflitecamerademo文件夹拖放到 Android Studio 中的 HelloTFLite 应用。ImageClassifier.java包含使用 TensorFlow Lite Java API 加载和运行 TensorFlow Lite 模型的所有代码,我们将在稍后详细介绍。 -
打开应用的
build.gradle文件,在dependencies部分的末尾添加compile 'org.tensorflow:tensorflow-lite:0.1',然后在buildTypes部分的以下三行中添加[android:
aaptOptions {
noCompress "tflite"
}
这是必需的,以避免在运行应用时出现以下错误:
10185-10185/com.ailabby.hellotflite W/System.err: java.io.FileNotFoundException: This file can not be opened as a file descriptor; it is probably compressed
03-20 00:32:28.805 10185-10185/com.ailabby.hellotflite W/System.err: at android.content.res.AssetManager.openAssetFd(Native Method)
03-20 00:32:28.806 10185-10185/com.ailabby.hellotflite W/System.err: at android.content.res.AssetManager.openFd(AssetManager.java:390)
03-20 00:32:28.806 10185-10185/com.ailabby.hellotflite W/System.err: at com.ailabby.hellotflite.ImageClassifier.loadModelFile(ImageClassifier.java:173)
现在,Android Studio 中的 HelloTFLite 应用应类似于图 11.6:
图 11.6:使用 TensorFlow Lite 和预构建的 MobileNet 图像分类模型的新 Android 应用
- 像以前一样,在
activity_main.xml中添加ImageView和Button,然后在MainActivity.java的onCreate方法中,将ImageView设置为测试图像的内容,然后单击Button的监听器以启动新线程,并实例化名为classifier的ImageClassifier实例:
private ImageClassifier classifier;
@Override
protected void onCreate(Bundle savedInstanceState) {
...
try {
classifier = new ImageClassifier(this);
} catch (IOException e) {
Log.e(TAG, "Failed to initialize an image classifier.");
}
- 线程的
run方法将测试图像数据读入Bitmap,调用ImageClassifier的classifyFrame方法,并将结果显示为Toast:
Bitmap bitmap = BitmapFactory.decodeStream(getAssets().open(IMG_FILE));
Bitmap croppedBitmap = Bitmap.createScaledBitmap(bitmap, INPUT_SIZE, INPUT_SIZE, true);
if (classifier == null ) {
Log.e(TAG, "Uninitialized Classifier or invalid context.");
return;
}
final String result = classifier.classifyFrame(croppedBitmap);
runOnUiThread(
new Runnable() {
@Override
public void run() {
mButton.setText("TF Lite Classify");
Toast.makeText(getApplicationContext(), result, Toast.LENGTH_LONG).show();
}
});
如果立即运行该应用,您将看到测试图像和一个标题为“TF Lite 分类”的按钮。 轻按它,您将看到分类结果,例如“拉布拉多犬:0.86 哈巴狗:0.05 达尔马提亚狗:0.04”。
ImageClassifier中与 TensorFlow Lite 相关的代码使用核心org.tensorflow.lite.Interpreter类及其run方法来运行模型,如下所示:
import org.tensorflow.lite.Interpreter;
public class ImageClassifier {
private Interpreter tflite;
private byte[][] labelProbArray = null;
ImageClassifier(Activity activity) throws IOException {
tflite = new Interpreter(loadModelFile(activity));
...
}
String classifyFrame(Bitmap bitmap) {
if (tflite == null) {
Log.e(TAG, "Image classifier has not been initialized;
Skipped.");
return "Uninitialized Classifier.";
}
convertBitmapToByteBuffer(bitmap);
tflite.run(imgData, labelProbArray);
...
}
并定义了loadModelFile方法:
private MappedByteBuffer loadModelFile(Activity activity) throws IOException {
AssetFileDescriptor fileDescriptor = activity.getAssets().openFd(MODEL_PATH);
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
回想一下,在步骤 4 中,我们必须在build.gradle文件中添加noCompress "tflite",否则openFd方法将导致错误。 该方法返回模型的映射版本,我们在第 6 章,“使用自然语言描述图像”时使用convert_graphdef_memmapped_format工具将 TensorFlow Mobile 模型转换为映射格式。 和第 9 章,“使用 GAN 生成和增强图像”。
这就是在新的 Android 应用中加载并运行预构建的 TensorFlow Lite 模型所需的一切。 如果您有兴趣使用经过重新训练和转换的 TensorFlow Lite 模型(如我们在 iOS 应用,Android 应用中所做的那样),或者自定义 TensorFlow Lite 模型(如果您成功获得了转换后的模型),则可以在 HelloTFLite 应用。 我们将暂时保留最先进的 TensorFlow Lite,并继续为 iOS 开发人员介绍另一个非常酷的 WWDC 重量级主题。
适用于 iOS 的 Core ML – 概述
苹果的 Core ML 框架使 iOS 开发人员可以轻松地在运行 iOS 11 或更高版本的 iOS 应用中使用经过训练的机器学习模型,并构建 Xcode 9 或更高版本。 您可以下载并使用 Apple 已在这里提供的 Core ML 格式的经过预训练的模型,也可以使用称为 coremltools 的 Python 工具,Core ML 社区工具来将其他机器学习和深度学习模型转换为 Core ML 格式。
Core ML 格式的预训练模型包括流行的 MobileNet 和 Inception V3 模型,以及更新的 ResNet50 模型(我们在第 10 章中简要讨论了残差网络)。 可以转换为 Core ML 格式的模型包括使用 Caffe 或 Keras 构建的深度学习模型,以及传统的机器学习模型,例如线性回归,支持向量机和通过 Scikit Learn 构建的决策树,这是一个非常流行的 Python 机器学习库。
因此,如果您想在 iOS 中使用传统的机器学习模型,那么 Scikit Learn 和 Core ML 绝对是必经之路。 尽管这是一本有关移动 TensorFlow 的书,但构建智能应用有时不需要深度学习。 在某些用例中,经典机器学习完全有意义。 此外,Core ML 对 Scikit Learn 模型的支持是如此流畅,以至于我们不能拒绝快速浏览,因此您将在必要时知道何时短暂使用移动 TensorFlow 技能。
如果要使用 Apple 预训练的 MobileNet Core ML 模型,请在这个页面上查看 Apple 不错的示例代码项目,它使用 Vision 和 Core ML 对图像进行分类,还观看这个页面上列出的有关核心 ML 的 WWDC 2017 视频。
在接下来的两个部分中,我们将向您展示两个教程,该教程以 TensorFlow 为后端,在 Keras 中如何转换和使用 Scikit Learn 模型和股票预测 RNN 模型,它们是在第 8 章, “使用 RNN 预测股票价格”。 您将在 Objective-C 和 Swift 中看到使用源代码从头开始构建的完整 iOS 应用,以使用转换后的 Core ML 模型。 如果短语“从头开始”使您兴奋并使您想起 AlphaZero,则您可能喜欢上一章第 10 章,“构建类似 AlphaZero 的移动游戏应用”。
将 Core ML 与 Scikit-Learn 机器学习结合使用
线性回归和支持向量机是 Scikit Learn 当然支持的两种最常见的经典机器学习算法。 我们将研究如何使用这两种算法为房价预测建立模型。
建立和转换 Scikit Learn 模型
首先,让我们获取房价数据集,该数据集可从这里下载。 下载的 RealEstate.csv文件如下所示:
MLS,Location,Price,Bedrooms,Bathrooms,Size,Price/SQ.Ft,Status
132842,Arroyo Grande,795000.00,3,3,2371,335.30,Short Sale
134364,Paso Robles,399000.00,4,3,2818,141.59,Short Sale
135141,Paso Robles,545000.00,4,3,3032,179.75,Short Sale
...
我们将使用流行的开源 Python 数据分析库 Pandas 来解析 csv 文件。 要安装 Scikit Learn 和 Pandas,只需运行以下命令,最好从您之前创建的 TensorFlow 和 Keras 虚拟环境中运行以下命令:
pip install scikit-learn
pip install pandas
现在,输入以下代码以读取并解析RealEstate.csv文件,将第 4 到第 6 列(卧室,浴室和大小)下的所有行用作输入数据,并使用第 3 列(价格)的所有行作为目标输出:
from sklearn.linear_model import LinearRegression
from sklearn.svm import LinearSVR
import pandas as pd
import sklearn.model_selection as ms
data = pd.read_csv('RealEstate.csv')
X, y = data.iloc[:, 3:6], data.iloc[:, 2]
将数据集分为训练集和测试集,并使用标准fit方法使用 Scikit Learn 的线性回归模型训练数据集:
X_train, X_test, y_train, y_test = ms.train_test_split(X, y, test_size=0.25)
lr = LinearRegression()
lr.fit(X_train, y_train)
使用predict方法,使用经过训练的模型测试三个新输入(3 个卧室,2 个浴室,1,560 平方英尺,等等):
X_new = [[ 3, 2, 1560.0],
[3, 2, 1680],
[5, 3, 2120]]
print(lr.predict(X_new))
这将输出三个值作为预测房价:[319289.9552276 352603.45104977 343770.57498118]。
要训练支持向量机模型并使用X_new输入对其进行测试,类似地添加以下代码:
svm = LinearSVR(random_state=42)
svm.fit(X_train, y_train)
print(svm.predict(X_new))
这将使用支持向量机模型作为[298014.41462535 320991.94354092 404822.78465954]输出预测的房价。 我们不会讨论哪种模型更好,如何使线性回归或支持向量机模型更好地工作,或者如何在 Scikit Learn 支持的所有算法中选择更好的模型-有很多不错的书籍和在线资源介绍了这些内容。 话题。
要将两个 Scikit Learn 模型lr和svm转换为可在您的 iOS 应用中使用的 Core ML 格式,您需要首先安装 Core ML 工具。 我们建议您在我们在第 8 章,“用 RNN 预测股价”和第 10 章“构建支持 AlphaZero 的手机游戏应用”中创建的 TensorFlow 和 Keras 虚拟环境中使用pip install -U coremltools安装这些软件,因为我们还将在下一部分中使用它来转换 Keras 模型。
现在,只需运行以下代码即可将两个 Scikit Learn 模型转换为 Core ML 格式:
import coremltools
coreml_model = coremltools.converters.sklearn.convert(lr, ["Bedrooms", "Bathrooms", "Size"], "Price")
coreml_model.save("HouseLR.mlmodel")
coreml_model = coremltools.converters.sklearn.convert(svm, ["Bedrooms", "Bathrooms", "Size"], "Price")
coreml_model.save("HouseSVM.mlmodel")
有关转换器工具的更多详细信息,请参见其在线文档。 现在,我们可以将这两个模型添加到 Objective-C 或 Swift iOS 应用中,但是我们仅在此处显示 Swift 示例。 您将在下一节中看到使用从 Keras 和 TensorFlow 模型转换而来的股票预测 Core ML 模型得到的 Objective-C 和 Swift 示例。
在 iOS 中使用转换后的 Core ML 模型
在将两个 Core ML 模型文件HouseLR.mlmodel和HouseSVM.mlmodel添加到新的基于 Swift 的 Xcode iOS 项目中之后, HouseLR.mlmodel如图 11.7 所示:
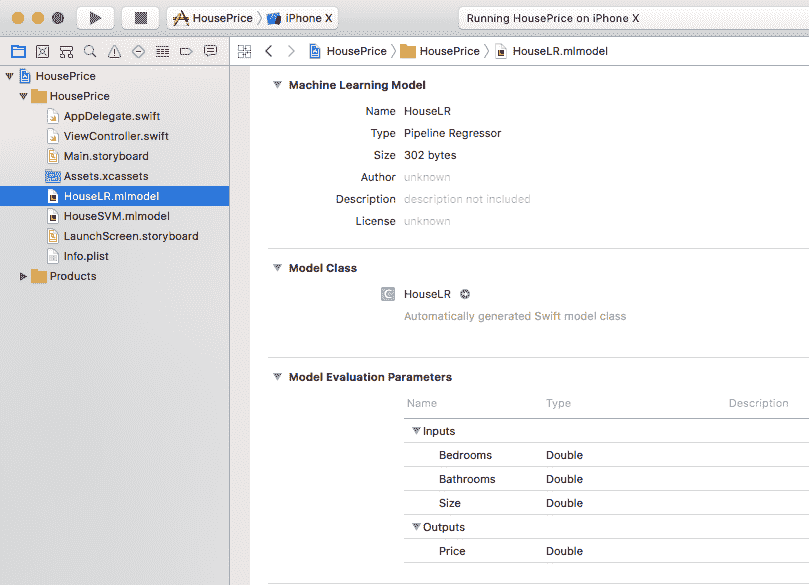
图 11.7:显示 Swift iOS 项目和线性回归 Core ML 模型
其他HouseSVM.mlmodel模型看起来完全一样,只是机器学习模型名称和模型类从HouseLR更改为HouseSVM。
将以下代码添加到ViewController.swift中的class ViewController中:
private let lr = HouseLR()
private let svm = HouseSVM()
override func viewDidLoad() {
super.viewDidLoad()
let lr_input = HouseLRInput(Bedrooms: 3, Bathrooms: 2, Size: 1560)
let svm_input = HouseSVMInput(Bedrooms: 3, Bathrooms: 2, Size: 1560)
guard let lr_output = try? lr.prediction(input: lr_input) else {
return
}
print(lr_output.Price)
guard let svm_output = try? svm.prediction(input: svm_input) else {
return
}
print(svm_output.Price)
}
这应该非常简单。 运行该应用将打印:
319289.955227601 298014.414625352
它们与最后一部分中 Python 脚本输出的两个数组中的前两个数字相同,因为我们将 PythonLR 代码的X_new值中的第一个输入用于 HouseLR 和 HouseSVM 的预测输入。
将 Core ML 与 Keras 和 TensorFlow 结合使用
coremltools 工具还正式支持转换使用 Keras 构建的模型(请参见keras.convert链接)。 截至 2018 年 3 月,最新版本的 coremltools 0.8 的版本可与 TensorFlow 1.4 和 Keras 2.1.5 配合使用,我们在第 8 章,“使用 RNN 预测股票价格”中使用了 Keras 股票预测模型。 您可以使用两种方法使用 coremltools 生成模型的 Core ML 格式。 首先是在训练模型后,直接在 Python Keras 代码中调用 coremltools 的convert和save方法。 例如,将下面的最后三行代码添加到model.fit之后的ch8/python/keras/train.py文件中:
model.fit(
X_train,
y_train,
batch_size=512,
epochs=epochs,
validation_split=0.05)
import coremltools
coreml_model = coremltools.converters.keras.convert(model)
coreml_model.save("Stock.mlmodel")
对于我们的模型转换,您可以在运行新脚本时忽略以下警告:
WARNING:root:Keras version 2.1.5 detected. Last version known to be fully compatible of Keras is 2.1.3。
将生成的Stock.mlmodel文件拖放到 Xcode 9.2 iOS 项目中时,它将使用默认的输入名称input1和默认的输出名称output1,如图 11.8 所示。 基于 Objective-C 和 Swift 的 iOS 应用:
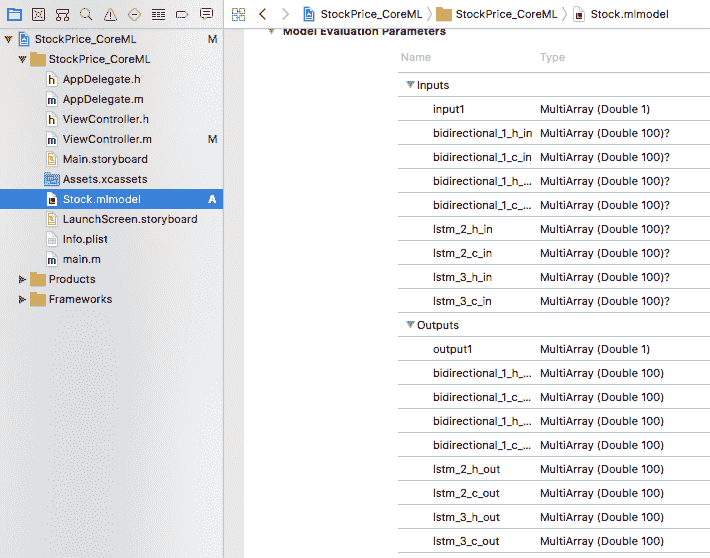
图 11.8:在 Objective-C 应用中显示从 Keras 和 TensorFlow 转换而来的股票预测 Core ML 模型
使用 coremltools 生成模型的 Core ML 格式的另一种方法是,首先将 Keras 构建的模型保存为 Keras HDF5 模型格式,这是我们在第 10 章,“构建类似 AlphaZero 的移动游戏应用”中,在转换为 AlphaZero TensorFlow 检查点文件之前使用的格式。 为此,只需运行model.save('stock.h5')。
然后,您可以使用以下代码片段将 Keras .h5模型转换为 Core ML 模型:
import coremltools
coreml_model = coremltools.converters.keras.convert('stock.h5',
input_names = ['bidirectional_1_input'],
output_names = ['activation_1/Identity'])
coreml_model.save('Stock.mlmodel')
请注意,此处使用与冻结 TensorFlow 检查点文件相同的输入和输出名称。 如果将Stock.mlmodel拖放到 Objective-C 项目,则自动生成的Stock.h中将出现错误,因为 Xcode 9.2 中的错误无法正确处理代码中的/字符activation_1/Identity输出名称。 如果它是 Swift iOS 对象,则自动生成的Stock.swift文件会正确地将/字符更改为_,从而避免了编译器错误,如图 11.9 所示。

图 11.9:在 Swift 应用中显示从 Keras 和 TensorFlow 转换而来的股票预测 Core ML 模型
要在 Objective-C 中使用该模型,请创建具有指定数据类型和形状的Stock对象和MLMultiArray对象,然后使用一些输入数据填充数组对象,并使用StockInput调用predictionFromFeatures方法用MLMultiArray数据初始化的实例:
#import "ViewController.h"
#import "Stock.h"
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
Stock *stock = [[Stock alloc] init];
double input[] = {
0.40294855,
0.39574954,
0.39789235,
0.39879138,
0.40368535,
0.41156033,
0.41556879,
0.41904324,
0.42543786,
0.42040193,
0.42384258,
0.42249741,
0.4153998 ,
0.41925279,
0.41295281,
0.40598363,
0.40289448,
0.44182321,
0.45822208,
0.44975226};
NSError *error = nil;
NSArray *shape = @[@20, @1, @1];
MLMultiArray *mlMultiArray = [[MLMultiArray alloc] initWithShape:(NSArray*)shape dataType:MLMultiArrayDataTypeDouble error:&error] ;
for (int i = 0; i < 20; i++) {
[mlMultiArray setObject:[NSNumber numberWithDouble:input[i]] atIndexedSubscript:(NSInteger)i];
}
StockOutput *output = [stock predictionFromFeatures:[[StockInput alloc] initWithInput1:mlMultiArray] error:&error];
NSLog(@"output = %@", output.output1 );
}
我们在这里使用了硬编码的规范化输入和 NSLog 只是为了演示如何使用 Core ML 模型。 如果立即运行该应用,您将看到 0.4486984312534332 的输出值,该值在非规范化后显示了预测的第二天股价。
前面代码的 Swift 版本如下:
import UIKit
import CoreML
class ViewController: UIViewController {
private let stock = Stock()
override func viewDidLoad() {
super.viewDidLoad()
let input = [
0.40294855,
0.39574954,
...
0.45822208,
0.44975226]
guard let mlMultiArray = try? MLMultiArray(shape:[20,1,1], dataType:MLMultiArrayDataType.double) else {
fatalError("Unexpected runtime error. MLMultiArray")
}
for (index, element) in input.enumerated() {
mlMultiArray[index] = NSNumber(floatLiteral: element)
}
guard let output = try? stock.prediction(input: StockInput(bidirectional_1_input:mlMultiArray)) else {
return
}
print(output.activation_1_Identity)
}
}
请注意,就像使用 TensorFlow Mobile iOS 应用一样,我们使用bidirectional_1_input和activation_1_Identity来设置输入并获取输出。
如果尝试转换在第 10 章,“构建类似 AlphaZero 的移动游戏应用”中在 Keras 中构建和训练的 AlphaZero 模型,则会收到错误消息ValueError: Unknown loss function:softmax_cross_entropy_with_logits。 如果您尝试转换我们在本书中构建的其他 TensorFlow 模型,则可以使用的最佳非官方工具是https://github.com/tf-coreml/tf-coreml上的 TensorFlow 到核心 ML 转换器。 不幸的是,类似于 TensorFlow Lite,它仅支持有限的 TensorFlow 操作集,其中一些原因是 Core ML 的限制,另一些原因是 tf-coreml 转换器的限制。 我们不会详细介绍将 TensorFlow 模型转换为 Core ML 模型的细节。 但是至少您已经了解了如何转换和使用 Scikit Learn 构建的传统机器学习模型以及基于 Keras 的 RNN 模型,该模型有望为您提供构建和使用 Core ML 模型的良好基础。 当然,如果您喜欢 Core ML,则应留意其将来的改进版本,以及 coremltools 和 tf-coreml 转换器的将来版本。 关于 Core ML,我们还没有涉及很多内容-要了解其确切功能,请参阅完整的 API 文档。
总结
在本章中,我们介绍了在移动和嵌入式设备上使用机器学习和深度学习模型的两个前沿工具:TensorFlow Lite 和 Core ML。 尽管 TensorFlow Lite 仍在开发人员预览版中,但对 TensorFlow 操作的支持有限,但其未来版本将支持越来越多的 TensorFlow 功能,同时保持较低的延迟和较小的应用大小。 我们提供了有关如何开发 TensorFlow Lite iOS 和 Android 应用以从头开始对图像进行分类的分步教程。 Core ML 是 Apple 为移动开发人员提供的将机器学习集成到 iOS 应用中的框架,它对转换和使用 Scikit Learn 构建的经典机器学习模型提供了强大的支持,并为基于 Keras 的模型提供了良好的支持。 我们还展示了如何将 Scikit Learn 和 Keras 模型转换为 Core ML 模型,以及如何在 Objective-C 和 Swift 应用中使用它们。 TensorFlow Lite 和 Core ML 现在都有一些严重的限制,导致它们无法转换我们在书中构建的复杂的 TensorFlow 和 Keras 模型。 但是他们今天已经有了用例,他们的未来会变得更好。 我们能做的最好的事情就是了解它们的用途,局限性和潜力,因此我们可以为现在或将来选择最合适的工具来完成不同的任务。 毕竟,我们不仅拥有锤子,而且并非所有东西都看起来像钉子。
在本书的下一章,最后一章中,我们将选择一些以前构建的模型,并添加强化学习的力量-强化学习的成功背后的关键技术,以及 2017 年 10 项突破性技术之一。 麻省理工学院评论–很酷的 Raspberry Pi 平台,一个小巧,价格合理但功能强大的计算机–谁不喜欢这三个的组合? 我们将看到有多少智能-,聆听,步行,平衡,当然还有学习,我们可以在一章中添加到小型 Raspberry-Pi 驱动的机器人中。 如果自动驾驶汽车是当今最热门的 AI 技术之一,那么自动行走机器人可能是我们家里最酷的玩具之一。
十二、在 Raspberry Pi 上开发 TensorFlow 应用
根据 Wikipedia 的说法,“ Raspberry Pi 是 Raspberry Pi 基金会在英国开发的一系列小型单板计算机,旨在促进学校和发展中国家的基础计算机科学教学。” Raspberry Pi 的官方网站将其描述为“一种小型且价格合理的计算机,可以用来学习编程。” 如果您以前从未听说过或使用过 Raspberry Pi,请访问其网站,然后您很快就会爱上这个很棒的小东西。 几乎没有什么功能-实际上,TensorFlow 的开发人员从 2016 年中期开始在早期版本的 Raspberry Pi 上提供了 TensorFlow,因此我们可以在微型计算机上运行复杂的 TensorFlow 模型,您只需花费 35 美元即可购买到。 这可能超出了“基础计算机科学的教学”或“学习编程”的范围,但另一方面,如果我们考虑过去几年中移动设备的所有飞速发展,那么看到如何在越来越小的设备中实现越来越多的功能,我们就不会感到惊讶。
在本章中,我们将进入 Raspberry Pi 的有趣世界,Raspberry Pi 是 TensorFlow 正式支持的最小设备。 我们将首先介绍如何获取和设置新的 Raspberry Pi 3B 板,包括本章中使用的所有必要配件,以使其能够看,听和说。 然后,我们将介绍如何使用 GoPiGo 机器人基础套件,将 Raspberry Pi 板变成一个可以移动的机器人。 之后,我们将提供最简单的工作步骤,以便在 Raspberry Pi 上设置 TensorFlow 1.6 并构建其示例 Raspberry Pi 应用。 我们还将讨论如何集成图像分类,这是我们在第 2 章,“通过迁移学习对图像进行分类”时使用的模型,并通过文字转语音功能使机器人告诉我们它可以识别的内容,以及如何集成音频识别,这是我们在第 5 章,“了解简单语音命令”中使用的模型以及 GoPiGo API,可让您使用语音命令来控制机器人的运动 。
最后,我们将向您展示如何使用 TensorFlow 和 OpenAI Gym,这是一个用于开发和比较强化学习算法的 Python 工具包,如何在模拟环境中实现强大的强化学习算法,以使我们的机器人能够在真实环境中移动和平衡身体。
在 Google I/O 2016 中,有一个名为“如何使用 Cloud Vision 和 Speech API 构建智能的 RasPi Bot”的会话(您可以在 YouTube 上观看视频)。 它使用 Google 的 Cloud API 执行图像分类以及语音识别和合成。 在本章中,我们将了解如何在设备上离线实现演示中的任务以及增强学习,从而展示 TensorFlow 在 Raspberry Pi 上的强大功能。
总而言之,我们将在本章中涵盖以下主题,以构建一个可以移动,看到,聆听,说话和学习的机器人:
- 设置 Raspberry Pi 并使其移动
- 在 Raspberry Pi 上设置 TensorFlow
- 图像识别和文字转语音
- 音频识别和机器人运动
- 在 Raspberry Pi 上进行强化学习
设置 Raspberry Pi 并使其移动
小型单板 Raspberry Pi 计算机系列包括 Raspberry Pi 3B+,3B,2B,1B+,1A+,0 和 0W(有关详细信息,请参见这里)。 我们将在此处使用 Pi 3B 主板,您可以从前面的链接或在 Amazon 上以 35 美元的价格购买。 我们在主板上使用并测试过的配件及其价格如下:
-
CanaKit 5V 2.5A Raspberry Pi 电源约 10 美元,可在开发期间使用。
-
Kinobo - 大约 4 美元的可以记录您的语音命令的 USB 2.0 微型麦克风。
-
USHONK USB 微型扬声器约合 12 美元,可以播放合成声音。
-
Arducam 5 Megapixels 1080p 传感器 OV5647 微型相机约合 14 美元,以支持图像分类。
-
16GB MicroSD 和适配器,价格约为 10 美元,用于存储 Raspbian(Raspberry Pi 的官方操作系统)的安装文件,并用作安装后的硬盘驱动器。
-
一个 USB 磁盘,例如 SanDisk 32GB USB Drive,售价 9 美元,将用作交换分区(有关详细信息,请参阅下一节) 因此我们可以手动构建 TensorFlow 库,这是构建和运行 TensorFlow C++ 代码所必需的。
-
售价 110 美元的 GoPiGo 机器人基础套件或官方网站,将 Raspberry Pi 板变成可以移动的机器人。
您还需要 HDMI 电缆将 Raspberry Pi 板连接到计算机显示器,USB 键盘和 USB 鼠标。 总共要花 200 美元,包括 110 美元的 GoPiGo,来构建一个可以移动,看,听,说的 Raspberry Pi 机器人。 尽管与功能强大的 Raspberry Pi 计算机相比,GoPiGo 套件似乎有点昂贵,但是如果没有它,那么一动不动的 Raspberry Pi 可能会失去很多吸引力。
有一个较旧的博客,“如何用 100 美元和 TensorFlow 构建“可视”的机器人”,由 Lukas Biewald 于 2016 年 9 月撰写,内容涵盖了如何使用 TensorFlow 和 Raspberry Pi 3 以及一些其他部件来构建能够说话和说话的机器人。 这很有趣。 我们这里介绍的内容除了提供语音命令识别和强化学习外,还提供了更详细的步骤来设置带有 GoPiGo 的 Raspberry Pi 3,GoPiGo(易于使用且受 Google 推荐的工具包,可将 Pi 变成机器人)以及更新版本的 TensorFlow 1.6。
现在,让我们首先看看如何设置 Raspbian,Raspberry Pi 开发板的操作系统。
设置 Raspberry Pi
最简单的方法是遵循 Raspbian 软件安装指南,总而言之,这是一个简单的三步过程:
-
为 Windows 或 Mac 下载并安装 SD 格式化程序。
-
使用 SD 格式化程序格式化 MicroSD 卡。
-
在这个页面上下载 Raspbian 的官方简易安装程序 New Out Of Box Software(NOOBS)的离线 ZIP 版本,将其解压缩,然后将提取的
NOOBS文件夹中的所有文件拖放到格式化的 MicroSD 卡中。
现在弹出 MicroSD 卡并将其插入 Raspberry Pi 板上。 将显示器的 HDMI 电缆以及 USB 键盘和鼠标连接到开发板上。 用电源为开发板供电,然后按照屏幕上的步骤完成 Raspbian 的安装,包括设置 Wifi 网络。 整个安装过程不到一个小时即可完成。 完成后,您可以打开一个终端并输入ifconfig来查找电路板的 IP 地址,然后从您的计算中使用ssh pi@<board_ip_address>来访问它,正如我们稍后将要看到的,这确实很方便并且需要在移动中测试控制 Raspberry Pi 机器人 – 当移动时,您不想或不能将键盘,鼠标和显示器与板子一起使用。
但是默认情况下未启用 SSH,因此,当您首次尝试 SSH 到 Pi 板上时,会出现“SSH 连接被拒绝”错误。 启用它的最快方法是运行以下两个命令:
sudo systemctl enable ssh
sudo systemctl start ssh
之后,您可以使用pi登录的默认密码ssh进行登录。 当然,您可以使用passwd命令将默认密码更改为新密码。
现在我们已经安装了 Raspbian,让我们将 USB 迷你麦克风,USB 迷你扬声器和迷你相机插入 Pi 板上。 USB 麦克风和扬声器均可即插即用。 插入它们后,您可以使用aplay -l命令找出支持的音频播放设备:
aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: Device_1 [USB2.0 Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 2: ALSA [bcm2835 ALSA], device 0: bcm2835 ALSA [bcm2835 ALSA]
Subdevices: 8/8
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
Subdevice #4: subdevice #4
Subdevice #5: subdevice #5
Subdevice #6: subdevice #6
Subdevice #7: subdevice #7
card 2: ALSA [bcm2835 ALSA], device 1: bcm2835 ALSA [bcm2835 IEC958/HDMI]
Subdevices: 1/1
Subdevice #0: subdevice #0
Pi 板上还有一个音频插孔,可用于在开发过程中获得音频输出。 但是 USB 扬声器肯定更方便。
要查找支持的记录设备,请使用arecord -l命令:
arecord -l
**** List of CAPTURE Hardware Devices ****
card 1: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
现在,您可以使用以下命令测试音频记录:
arecord -D plughw:1,0 -d 3 test.wav
-D指定音频输入设备,这意味着它是具有卡 1,设备 0 的即插即用设备,如arecord -l命令的输出所示。 -d以秒为单位指定记录的持续时间。
要在 USB 扬声器上播放录制的音频,首先需要在主目录中创建一个名为 .asoundrc的文件,其内容如下:
pcm.!default {
type plug
slave {
pcm "hw:0,0"
}
}
ctl.!default {
type hw
card 0
}
请注意,"hw:0,0"与aplay -l为 USB 扬声器设备返回的卡 0,设备 0 信息匹配。 现在,您可以使用aplay test.wav命令在扬声器上测试录制的音频播放。
有时,Pi 板重新启动后,系统会自动更改 USB 扬声器的卡号,并且在运行aplay test.wav时您听不到声音。 在这种情况下,您可以再次运行aplay -l来找到为 USB 扬声器设置的新卡号,并相应地更新~/.asoundrc文件。
如果要调节扬声器的音量,请使用amixer set PCM -- 100%命令,其中 100% 将音量设置为最大。
要加载相机的驱动程序,请运行sudo modprobe bcm2835-v4l2命令。 之后,要验证是否已检测到摄像机,请运行vcgencmd get_camera命令,该命令应返回supported=1 detected=1 。 要在每次主板启动时加载摄像机驱动程序(这是我们需要的),请运行sudo vi /etc/modules并在/etc/modules的末尾添加一行 bcm2835-v4l2(或者您可以运行sudo bash -c "echo 'bcm2835-v4l2' >> /etc/modules")。 当我们运行 TensorFlow 图像分类示例时,我们将在后面的部分中测试相机。
这就是为我们的任务设置 Raspberry Pi 的全部内容。 现在,让我们看看如何使其移动。
使树莓派移动
GoPiGo 是一个流行的工具包,可将您的 Raspberry Pi 板变成移动的机器人。 购买并收到我们之前提到的 GoPiGo 机器人基础套件后,请按照这里将其与您的 Pi 板组装在一起。 根据您是同时观看 March March Madness 还是 NBA 季后赛比赛,这大约需要一两个小时。
完成后,您的 Raspberry Pi 机器人以及我们之前列出的所有附件应如下所示:

图 12.1:具有 GoPiGo 套件和相机,USB 扬声器和 USB 麦克风的 Raspberry Pi 机器人
现在,使用 Raspberry Pi 电源打开 Pi 机器人,并在启动后使用ssh pi@<your_pi_board_ip>连接到它。 要安装 GoPiGo Python 库,以便我们可以使用 GoPiGo 的 Python API 控制机器人,请运行以下命令 ,它将执行一个 shell 脚本,该脚本创建一个新的/home/pi/Dexter目录并在其中安装所有库和固件文件:
sudo sh -c "curl -kL dexterindustries.com/update_gopigo3 | bash"
您还应该转到~/Dexter目录并运行以下命令来更新 GoPiGo 板的固件:
bash GoPiGo3/Firmware/gopigo3_flash_firmware.sh
现在运行sudo reboot重新启动板,以使更改生效。 Pi 板重新启动后,您可以从 iPython 测试 GoPiGo 和 Raspberry Pi 的运动,可以使用sudo pip install ipython进行安装。
要测试基本的 GoPiGo Python API,请先运行 iPython,然后逐行输入以下代码:
当 GoPiGo Raspberry Pi 机器人开始移动时,请确保将其放在安全的表面上。 在最终测试期间,应使用 GoPiGo 电池组为机器人供电,使其可以自由移动。 但是在开发和初始测试中,除非您使用充电电池,否则绝对应该使用电源适配器来节省电池。 如果将机器人放在桌子上,请务必小心,因为如果发出命令导致机器人动作不佳,机器人可能会跌落。
import easygopigo3 as easy
gpg3_obj = easy.EasyGoPiGo3()
gpg3_obj.drive_cm(5)
gpg3_obj.drive_cm(-5)
gpg3_obj.turn_degrees(30)
gpg3_obj.turn_degrees(-30)
gpg3_obj.stop()
drive_cm根据其参数值是正值还是负值来向前或向后移动机器人。 turn_degrees顺时针或逆时针旋转机器人,取决于其参数值是正值还是负值。 因此,前面的示例代码将机器人向前移动 5 厘米,然后向后移动 5 厘米,顺时针旋转 30 度,然后逆时针旋转 30 度。 默认情况下,这些调用是阻塞调用,因此直到机器人完成移动后它们才返回。 要进行非阻塞调用,请添加False参数,如下所示:
gpg3_obj.drive_cm(5, False)
gpg3_obj.turn_degrees(30, False)
您还可以使用forward,backward和许多其他 API 调用来控制机器人的运动,但是在本章中,我们仅使用drive_cm和turn_degrees。
我们现在准备使用 TensorFlow 向机器人添加更多智能。
在 Raspberry Pi 上设置 TensorFlow
要在 Python 中使用 TensorFlow,就像我们稍后在“音频识别”和“强化学习”部分中所做的那样,我们可以在 TensorFlow Jenkins 持续集成站点上为 Pi 安装每晚 TensorFlow 1.6 版本:
sudo pip install http://ci.tensorflow.org/view/Nightly/job/nightly-pi/lastSuccessfulBuild/artifact/output-artifacts/tensorflow-1.6.0-cp27-none-any.whl
此方法更为常见,并在一个不错的博客条目中描述,《为 Raspberry Pi 交叉编译 TensorFlow》,作者是 Pete Warden。
一种更复杂的方法是使用makefile,这在您需要构建和使用 TensorFlow 库时是必需的。 TensorFlow 官方 makefile 文档的 Raspberry Pi 部分包含构建 TensorFlow 库的详细步骤,但是它可能不适用于每个版本的 TensorFlow。 此处的步骤与 TensorFlow 的早期版本(0.10)完美配合,但是在 TensorFlow 1.6 中会导致许多“未定义对google::protobuf的引用”错误。
TensorFlow 1.6 版本已经测试了以下步骤,可从下载 https://github.com/tensorflow/tensorflow/releases/tag/v1.6.0 ; 您当然可以在 TensorFlow 发行页面中尝试使用较新的版本,或者通过git clone https://github.com/tensorflow/tensorflow克隆最新的 TensorFlow 源,并修复所有可能的问题。
在cd之后到 TensorFlow 源根目录,然后运行以下命令:
tensorflow/contrib/makefile/download_dependencies.sh
sudo apt-get install -y autoconf automake libtool gcc-4.8 g++-4.8
cd tensorflow/contrib/makefile/downloads/protobuf/
./autogen.sh
./configure
make CXX=g++-4.8
sudo make install
sudo ldconfig # refresh shared library cache
cd ../../../../..
export HOST_NSYNC_LIB=`tensorflow/contrib/makefile/compile_nsync.sh`
export TARGET_NSYNC_LIB="$HOST_NSYNC_LIB"
确保您运行的是make CXX=g++-4.8,而不是运行在正式 TensorFlow Makefile 文档中的make,因为 Protobuf 必须使用与用于构建以下 TensorFlow 的版本相同的gcc版本来编译库,以修复那些“未定义对google::protobuf的引用”错误。 现在尝试使用以下命令构建 TensorFlow 库:
make -f tensorflow/contrib/makefile/Makefile HOST_OS=PI TARGET=PI \
OPTFLAGS="-Os -mfpu=neon-vfpv4 -funsafe-math-optimizations -ftree-vectorize" CXX=g++-4.8
经过几个小时的构建,您可能会收到诸如“虚拟内存耗尽:无法分配内存”之类的错误,否则 Pi 板将由于内存不足而冻结。 要解决此问题,我们需要设置一个交换,因为没有交换,当应用用尽内存时,由于内核崩溃,该应用将被杀死。 设置交换的方法有两种:交换文件和交换分区。 Raspbian 在 SD 卡上使用默认的 100MB 交换文件,如下所示,使用free命令:
pi@raspberrypi:~/tensorflow-1.6.0 $ free -h
total used free shared buff/cache available
Mem: 927M 45M 843M 660K 38M 838M
Swap: 99M 74M 25M
要将交换文件大小提高到 1GB,请通过 sudo vi /etc/dphys-swapfile修改 /etc/dphys-swapfile文件,将CONF_SWAPSIZE=100更改为CONF_SWAPSIZE=1024,然后重新启动交换文件服务:
sudo /etc/init.d/dphys-swapfile stop
sudo /etc/init.d/dphys-swapfile start
此后,free -h将显示交换总量为 1.0GB。
交换分区是在单独的 USB 磁盘上创建的,因此首选交换分区,因为交换分区不会碎片化,但 SD 卡上的交换文件很容易碎片化,从而导致访问速度变慢。 要设置交换分区,请将没有所需数据的 USB 闪存盘插入 Pi 板上,然后运行sudo blkid,您将看到类似以下内容:
/dev/sda1: LABEL="EFI" UUID="67E3-17ED" TYPE="vfat" PARTLABEL="EFI System Partition" PARTUUID="622fddad-da3c-4a09-b6b3-11233a2ca1f6"
/dev/sda2: UUID="E67F-6EAB" TYPE="vfat" PARTLABEL="NO NAME" PARTUUID="a045107a-9e7f-47c7-9a4b-7400d8d40f8c"
/dev/sda2是我们将用作交换分区的分区。 现在卸载并将其格式化为交换分区:
sudo umount /dev/sda2
sudo mkswap /dev/sda2
mkswap: /dev/sda2: warning: wiping old swap signature.
Setting up swapspace version 1, size = 29.5 GiB (31671701504 bytes)
no label, UUID=23443cde-9483-4ed7-b151-0e6899eba9de
您将在mkswap命令中看到一个 UUID 输出。 运行sudo vi /etc/fstab,将以下行添加到具有 UUID 值的fstab文件中:
UUID=<UUID value> none swap sw,pri=5 0 0
保存并退出 fstab 文件,然后运行sudo swapon -a。 现在,如果再次运行free -h,将会看到“交换总数”接近 USB 存储设备的大小。 我们绝对不需要所有大小的交换空间—实际上,具有 1GB 内存的 Raspberry Pi 3 板的建议最大交换大小为 2GB,但是我们将其保留原样,因为我们只是想成功地构建内存。 TensorFlow 库。
更改任一交换设置后,我们可以重新运行make命令:
make -f tensorflow/contrib/makefile/Makefile HOST_OS=PI TARGET=PI \
OPTFLAGS="-Os -mfpu=neon-vfpv4 -funsafe-math-optimizations -ftree-vectorize" CXX=g++-4.8
完成此操作后,TensorFlow 库将以tensorflow/contrib/makefile/gen/lib/libtensorflow-core.a的形式生成,如果您已经阅读了我们手动构建 TensorFlow 库的前几章,则应该看起来很熟悉。 现在,我们可以使用该库构建图像分类示例。
图像识别和文字转语音
在tensorflow/contrib/pi_examples: label_image和相机中有两个 TensorFlow Raspberry Pi 示例应用。 我们将修改相机示例应用,以将文本集成到语音中,以便该应用在四处走动时可以说出其识别出的图像。 在构建和测试这两个应用之前,我们需要安装一些库并下载预构建的 TensorFlow Inception 模型文件:
sudo apt-get install -y libjpeg-dev
sudo apt-get install libv4l-dev
curl https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015_stripped.zip -o /tmp/inception_dec_2015_stripped.zip
cd ~/tensorflow-1.6.0
unzip /tmp/inception_dec_2015_stripped.zip -d tensorflow/contrib/pi_examples/label_image/data/
要构建label_image和相机应用,请运行:
make -f tensorflow/contrib/pi_examples/label_image/Makefile
make -f tensorflow/contrib/pi_examples/camera/Makefile
构建应用时,您可能会遇到以下错误:
./tensorflow/core/platform/default/mutex.h:25:22: fatal error: nsync_cv.h: No such file or directory
#include "nsync_cv.h"
^
compilation terminated.
要解决此问题,请运行sudo cp tensorflow/contrib/makefile/downloads/nsync/public/nsync*.h /usr/include。
然后编辑tensorflow/contrib/pi_examples/label_image/Makefile或 tensorflow/contrib/pi_examples/camera/Makefile文件,添加以下库,并在再次运行make命令之前包含路径:
-L$(DOWNLOADSDIR)/nsync/builds/default.linux.c++11 \
-lnsync \
要测试运行这两个应用,请直接运行这些应用:
tensorflow/contrib/pi_examples/label_image/gen/bin/label_image
tensorflow/contrib/pi_examples/camera/gen/bin/camera
看看 C++ 源代码tensorflow/contrib/pi_examples/label_image/label_image.cc和tensorflow/contrib/pi_examples/camera/camera.cc,您会看到它们使用与前几章中的 iOS 应用类似的 C++ 代码来加载模型图文件,准备输入张量,运行模型,并获得输出张量。
默认情况下,摄像机示例还使用label_image/data文件夹中解压缩的预构建 Inception 模型。 但是对于您自己的特定图像分类任务,提供通过迁移学习重新训练的模型。您可以像第 2 章,“通过迁移学习对图像进行分类”一样,在运行两个示例应用时使用--graph参数。
通常,语音是 Raspberry Pi 机器人与我们互动的主要 UI。 理想情况下,我们应该运行 TensorFlow 支持的自然声音文本到语音(TTS)模型,例如 WaveNet 或 Tacotron,但运行和部署不在本章范围之内。 这样的模型。 事实证明,我们可以使用称为 CMU Flite 的简单得多的 TTS 库,它提供了相当不错的 TTS,并且只需一个简单的命令即可安装它:sudo apt-get install flite。 如果要安装最新版本的 Flite 以期希望获得更好的 TTS 质量,只需从链接下载最新的 Flite 源并进行构建。
要使用我们的 USB 扬声器测试 Flite,请使用-t参数运行 flite,然后使用双引号引起来的文本字符串,例如 flite -t "i recommend the ATM machine"。 如果您不喜欢默认语音,则可以通过运行 flite -lv找到其他受支持的语音,它们应返回 Voices available: kal awb_time kal16 awb rms slt 。 然后,您可以指定用于 TTS 的语音: flite -voice rms -t "i recommend the ATM machine"。
要使相机应用说出识别出的对象,这是当 Raspberry Pi 机器人四处移动时所期望的行为,可以使用以下简单的pipe命令:
tensorflow/contrib/pi_examples/camera/gen/bin/camera | xargs -n 1 flite -t
您可能会听到太多声音。 要微调图像分类的 TTS 结果,还可以在使用make -f tensorflow/contrib/pi_examples/camera/Makefile重建示例之前,修改camera.cc文件并将以下代码添加到PrintTopLabels函数中:
std::string cmd = "flite -voice rms -t \"";
cmd.append(labels[label_index]);
cmd.append("\"");
system(cmd.c_str());
现在,我们已经完成了“如何使用 Cloud Vision 和 Speech API 来构建智能 RasPi Bot 演示”的图像分类和语音合成任务,而不使用任何 Cloud API。 使用我们在第 5 章,“了解简单语音命令”中使用的相同模型,在 Raspberry Pi 上进行音频识别。
音频识别和机器人运动
要使用 TensorFlow 教程中的预训练音频识别模型或我们之前描述的重新训练模型,我们将重用来自这个页面的 Python 脚本listen.py,并在识别四个基本音频命令后添加 GoPiGo API 调用以控制机器人的运动:"left", "right", "go", "stop"。 预训练模型支持的其他六个命令-"yes", "no", "up", "down", "on", "off",在我们的示例中不太适用,如果需要 ,您可以使用第 5 章 , “了解简单语音命令”中所示的重新训练模型,以支持针对特定任务的其他语音命令。
要运行脚本,请先从这里下载预训练的音频识别模型,然后将其解压缩到/tmp,或者对我们在第 5 章“了解简单语音命令”中使用的模型使用scp到 Pi 板的/tmp目录,然后运行:
python listen.py --graph /tmp/conv_actions_frozen.pb --labels /tmp/conv_actions_labels.txt -I plughw:1,0
或者您可以运行:
python listen.py --graph /tmp/speech_commands_graph.pb --labels /tmp/conv_actions_labels.txt -I plughw:1,0
请注意,plughw value 1,0应该与您的 USB 麦克风的卡号和设备号匹配,可以使用我们之前显示的arecord -l命令找到。
listen.py脚本还支持许多其他参数。 例如,我们可以使用--detection_threshold 0.5代替默认的检测阈值 0.8。
现在,让我们快速了解listen.py的工作原理,然后再添加 GoPiGo API 调用以使机器人移动。 listen.py使用 Python 的subprocess模块及其Popen类产生带有适当参数的运行arecord命令的新过程。 Popen类具有stdout属性,该属性指定arecord执行的命令的标准输出文件句柄,可用于读取记录的音频字节。
加载训练后的模型图的 Python 代码如下:
with tf.gfile.FastGFile(filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
使用tf.Session()创建 TensorFlow 会话,并在加载图并创建会话之后,将记录的音频缓冲区以及采样率作为输入数据发送到 TensorFlow 会话的run方法,该方法返回识别的预测:
run(softmax_tensor, {
self.input_samples_name_: input_data,
self.input_rate_name_: self.sample_rate_
})
在这里,将softmax_tensor定义为 TensorFlow 图的get_tensor_by_name(self.output_name_),将output_name_,input_samples_name_和input_rate_name_分别定义为labels_softmax,decoded_sample_data:0和decoded_sample_data:1,我们在第 5 章,“了解简单语音命令”中的 iOS 和 Android 应用中使用过它。
在之前的章节中,我们主要使用 Python 训练和测试 TensorFlow 模型,然后再使用本机 TensorFlow C++ 库的 Java 接口代码在使用 C++ 或 Android 的 iOS 中运行模型。 在 Raspberry Pi 上,您可以选择直接使用 TensorFlow Python API 或 C++ API 在 Pi 上运行 TensorFlow 模型,尽管通常仍会在功能更强大的电脑上训练模型。 有关完整的 TensorFlow Python API 文档,请参见这里。
要使用 GoPiGo Python API 使机器人根据您的语音命令移动,请首先在listen.py中添加以下两行:
import easygopigo3 as gpg
gpg3_obj = gpg.EasyGoPiGo3()
然后将以下代码添加到def add_data方法的末尾:
if current_top_score > self.detection_threshold_ and time_since_last_top > self.suppression_ms_:
self.previous_top_label_ = current_top_label
self.previous_top_label_time_ = current_time_ms
is_new_command = True
logger.info(current_top_label)
if current_top_label=="go":
gpg3_obj.drive_cm(10, False)
elif current_top_label=="left":
gpg3_obj.turn_degrees(-30, False)
elif current_top_label=="right":
gpg3_obj.turn_degrees(30, False)
elif current_top_label=="stop":
gpg3_obj.stop()
现在将您的 Raspberry Pi 机器人放在地面上,从计算机上用ssh连接到它,然后运行以下脚本:
python listen.py --graph /tmp/conv_actions_frozen.pb --labels /tmp/conv_actions_labels.txt -I plughw:1,0 --detection_threshold 0.5
您将看到以下输出:
INFO:audio:started recording
INFO:audio:_silence_
INFO:audio:_silence_
然后,您可以说左,右,停止,前进和停止,以查看命令被识别并且机器人相应地移动:
INFO:audio:left
INFO:audio:_silence_
INFO:audio:_silence_
INFO:audio:right
INFO:audio:_silence_
INFO:audio:stop
INFO:audio:_silence_
INFO:audio:go
INFO:audio:stop
您可以在单独的终端中运行相机应用,因此,当机器人根据您的语音命令走动时,它会识别出所看到的新图像并说出结果。 这就是构建一个基本的 Raspberry Pi 机器人所需的全部内容,该机器人可以听,动,看和说-Google I/O 2016 演示所做的事情,却不使用任何 Cloud API。 它远不是一个能听懂自然人的语音,进行有趣的对话或执行有用且不重要的任务的幻想机器人。 但是,借助预训练,再训练或其他强大的 TensorFlow 模型,并使用各种传感器,您当然可以为我们构建的 Pi 机器人增加越来越多的智能和物理动力。
在下一节中,您将看到如何在 Pi 上运行经过预训练和再训练的 TensorFlow 模型,我们将向您展示如何向使用 TensorFlow 构建和训练的机器人添加强大的强化学习模型。 毕竟,强化学习的反复试验方式及其与环境交互以获取最大回报的本质,使得强化学习成为机器人非常合适的机器学习方法。
在 Raspberry Pi 上进行强化学习
OpenAI Gym是一个开源 Python 工具包,提供了许多模拟环境来帮助您开发,比较和训练强化学习算法,因此您无需购买所有传感器并在实际环境中训练您的机器人,这在时间和金钱上都是昂贵的。 在本部分中,我们将向您展示如何在 TenAI 健身房的称为 CartPole。
要安装 OpenAI Gym,请运行以下命令:
git clone https://github.com/openai/gym.git
cd gym
sudo pip install -e .
您可以通过运行pip list来验证是否已安装 TensorFlow 1.6 和 Gym(“在 Raspberry Pi 上设置 TensorFlow”的最后部分介绍了如何安装 TensorFlow 1.6):
pi@raspberrypi:~ $ pip list
gym (0.10.4, /home/pi/gym)
tensorflow (1.6.0)
或者您可以启动 iPython,然后导入 TensorFlow 和 Gym:
pi@raspberrypi:~ $ ipython
Python 2.7.9 (default, Sep 17 2016, 20:26:04)
IPython 5.5.0 -- An enhanced Interactive Python.
In [1]: import tensorflow as tf
In [2]: import gym
In [3]: tf.__version__
Out[3]: '1.6.0'
In [4]: gym.__version__
Out[4]: '0.10.4'
现在,我们都准备使用 TensorFlow 和 Gym 来构建一些有趣的在 Raspberry Pi 上运行的强化学习模型。
了解 CartPole 模拟环境
CartPole 是一种可用于训练机器人以保持平衡的环境-如果它携带某些东西并希望在移动时保持其放置状态。 由于本章的范围,我们将仅构建在模拟 CartPole 环境中工作的模型,但是可以肯定地将模型以及模型的构建和训练方式应用于类似于 CartPole 的实际物理环境。
在 CartPole 环境中,将杆连接到推车,该推车沿轨道水平移动。 您可以对购物车执行 1(向右加速)或 0(向左加速)操作。 杆子开始直立,目的是防止其跌落。 杆保持直立的每个时间步长都奖励 1。 当极点与垂直方向的夹角超过 15 度,或者手推车从中心移出 2.4 个单位以上时,剧集就会结束。
现在让我们使用 CartPole 环境。 首先,创建一个新环境并找出智能体可以在该环境中采取的措施:
env = gym.make("CartPole-v0")
env.action_space
# Discrete(2)
env.action_space.sample()
# 0 or 1
每个观察(状态)都由关于购物车的四个值组成:其水平位置,速度,极角和角速度:
obs=env.reset()
obs
# array([ 0.04052535, 0.00829587, -0.03525301, -0.00400378])
环境中的每个步骤(动作)将导致新的观察,动作的奖励,剧集是否完成(如果是,则您无法采取任何进一步的步骤)以及一些其他信息:
obs, reward, done, info = env.step(1)
obs
# array([ 0.04069127, 0.2039052 , -0.03533309, -0.30759772])
记住动作(或步骤)1 表示向右移动,0 表示向左移动。 要查看当您继续向右移动购物车时剧集可以持续多长时间,请运行:
while not done:
obs, reward, done, info = env.step(1)
print(obs)
#[ 0.08048328 0.98696604 -0.09655727 -1.54009127]
#[ 0.1002226 1.18310769 -0.12735909 -1.86127705]
#[ 0.12388476 1.37937549 -0.16458463 -2.19063676]
#[ 0.15147227 1.5756628 -0.20839737 -2.52925864]
#[ 0.18298552 1.77178219 -0.25898254 -2.87789912]
现在,让我们手动执行从头到尾的一系列操作,并打印出观测值的第一个值(水平位置)和第三个值(极点与垂直方向的度数),因为这两个值确定一个剧集是否为完成。
首先,重置环境并正确加速购物车几次:
import numpy as np
obs=env.reset()
obs[0], obs[2]*360/np.pi
# (0.008710582898326602, 1.4858315848689436)
obs, reward, done, info = env.step(1)
obs[0], obs[2]*360/np.pi
# (0.009525842685697472, 1.5936049816642313)
obs, reward, done, info = env.step(1)
obs[0], obs[2]*360/np.pi
# (0.014239775393474322, 1.040038643681757)
obs, reward, done, info = env.step(1)
obs[0], obs[2]*360/np.pi
# (0.0228521194217381, -0.17418034908781568)
您会看到,推车向右移动时,其位置值会越来越大,杆的垂直度会越来越小,最后一步显示的是负度,这意味着杆位于中心的左侧。 所有这一切都是有道理的,在您心目中,您最喜欢的狗用杆子推着推车的画面有些生动。 现在,更改动作以使购物车向左(0)加速几次:
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.03536432554326476, -2.0525933052704954)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.04397450935915654, -3.261322987287562)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.04868738508385764, -3.812330822419413)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.04950617929263011, -3.7134404042580687)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.04643238384389254, -2.968245724428785)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.039465670006712444, -1.5760901885345346)
首先,您可能会惊讶于 0 动作导致位置(obs[0])连续变大几次,但请记住,手推车以一定速度运动,并且一个或多个动作将手推车移至另一个方向不会立即降低位置值。 但是,如果您继续将购物车向左移动,如前两个步骤所示,您会看到购物车的位置开始变小(向左)。 现在继续执行 0 动作,您会看到位置越来越小,负值表示推车进入中心的左侧,而杆的角度越来越大:
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.028603948219811447, 0.46789197320636305)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (0.013843572459953138, 3.1726728882727504)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (-0.00482029774222077, 6.551160678086707)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi
# (-0.02739315127299434, 10.619948631208114)
如我们前面所述,定义 CartPole 环境的方式是剧集“当极距与垂直方向成 15 度以上时结束”,因此让我们再做一些动作并打印出done值, 时间:
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi, done
# (-0.053880356973985064, 15.39896478042983, False)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi, done
# (-0.08428612474261402, 20.9109976051126, False)
obs, reward, done, info = env.step(0)
obs[0], obs[2]*360/np.pi, done
# (-0.11861214326416822, 27.181070460526062, True)
obs, reward, done, info = env.step(0)
# WARN: You are calling 'step()' even though this environment has already returned done = True. You should always call 'reset()' once you receive 'done = True' -- any further steps are undefined behavior.
环境决定何时将done返回True时会有一些延迟-尽管前两个步骤已经返回了大于 15 度的度数(当极点与垂直线成 15 度以上时,剧集结束了) ,您仍然可以对环境执行 0 操作。 第三步将done返回为True,并且环境中的另一步骤(最后一步)将导致警告,因为环境已经完成了该剧集。
对于 CartPole 环境,每个step调用返回的reward值始终为 1,信息始终为{}。 这就是关于 CartPole 模拟环境的全部知识。 现在我们了解了 CartPole 的工作原理,让我们看看可以在每种状态(观察)下制定什么样的策略,我们可以让该策略告诉我们要采取的操作(步骤),以便我们可以保持杆直立。换句话说,就是尽可能长的时间,这样我们才能最大化我们的回报。 请记住,强化学习中的一项策略只是一个函数,该函数以智能体所处的状态为输入,并输出智能体接下来应采取的行动,以实现值最大化或长期回报。
从基本的直观策略开始
显然,每次都执行相同的动作(全 0 或 1s)不会使杆保持太直的状态。 为了进行基线比较,请运行以下代码,以查看在每个剧集中应用相同操作时在 1,000 个剧集中获得的平均奖励:
# single_minded_policy.py
import gym
import numpy as np
env = gym.make("CartPole-v0")
total_rewards = []
for _ in range(1000):
rewards = 0
obs = env.reset()
action = env.action_space.sample()
while True:
obs, reward, done, info = env.step(action)
rewards += reward
if done:
break
total_rewards.append(rewards)
print(np.mean(total_rewards))
# 9.36
因此,所有 1,000 集的平均奖励约为 10。请注意, env.action_space.sample()对 0 或 1 动作进行采样,与随机输出 0 或 1 相同。您可以通过求值np.sum([env.action_space.sample() for _ in range(10000)]),应该接近 5,000。
要查看其他策略如何更好地工作,让我们使用一个简单直观的策略,当极数度数为正(在垂直方向的右侧)时执行 1 动作(向右移动购物车),然后执行 0(将购物车向右移动) 当极数度数为负时(在垂直方向的左侧)。 这项策略是有道理的,因为我们可能会采取尽可能长时间保持平衡的措施:
# simple_policy.py
import gym
import numpy as np
env = gym.make("CartPole-v0")
total_rewards = []
for _ in range(1000):
rewards = 0
obs = env.reset()
while True:
action = 1 if obs[2] > 0 else 0
obs, reward, done, info = env.step(action)
rewards += reward
if done:
break
total_rewards.append(rewards)
print(np.mean(total_rewards))
# 42.19
现在,每 1,000 集的平均奖励为 42,与 9.36 相比有很大提高。
现在让我们看看我们是否可以制定出更好,更复杂的策略。 回想一下,策略只是从状态到操作的映射或函数。 在过去的几年中,我们在神经网络的兴起中了解到的一件事是,如果不清楚如何定义复杂的函数(例如强化学习中的策略),请考虑一下神经网络,毕竟这是通用函数近似器 (有关详细信息,请参见神经网络可以计算任何函数的可视化证明,Michael Nelson)。
在上一章中我们介绍了 AlphaGo 和 AlphaZero,Jim Fleming 撰写了一篇有趣的博客文章,标题为“在 AlphaGo 之前的 TD-Gammon”,这是第一个强化学习应用,它使用神经网络作为评估函数来训练自己,以击败五子棋冠军。 博客条目和 Sutton 和 Barto 的《强化学习:入门》一书都对 TD-Gammon 进行了深入的描述。 如果您想了解有关使用神经网络作为强大的通用函数的更多信息,还可以使用 Google 搜索“时差学习和 TD-Gammon”的原始论文。
使用神经网络建立更好的策略
首先,让我们看看如何使用简单的完全连接的(密集)神经网络构建随机策略,该网络将观察中的 4 个值作为输入,使用 4 个神经元的隐藏层,并输出 0 动作的概率,基于 ,智能体可以采样 0 到 1 之间的下一个动作:
# nn_random_policy.py
import tensorflow as tf
import numpy as np
import gym
env = gym.make("CartPole-v0")
num_inputs = env.observation_space.shape[0]
inputs = tf.placeholder(tf.float32, shape=[None, num_inputs])
hidden = tf.layers.dense(inputs, 4, activation=tf.nn.relu)
outputs = tf.layers.dense(hidden, 1, activation=tf.nn.sigmoid)
action = tf.multinomial(tf.log(tf.concat([outputs, 1-outputs], 1)), 1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_rewards = []
for _ in range(1000):
rewards = 0
obs = env.reset()
while True:
a = sess.run(action, feed_dict={inputs: obs.reshape(1, num_inputs)})
obs, reward, done, info = env.step(a[0][0])
rewards += reward
if done:
break
total_rewards.append(rewards)
print(np.mean(total_rewards))
请注意,我们使用 tf.multinomial 函数根据动作 0 和 1 的概率分布,分别定义为outputs和1-outputs(两个概率之和为 1)对动作进行采样。 总奖励的平均值约为 20 左右,比一心一意的策略好,但比上一节中的简单直观的策略差。 这是一个神经网络,它在没有任何训练的情况下生成随机策略。
为了训练网络,我们使用tf.nn.sigmoid_cross_entropy_with_logits定义了网络输出与所需y_target作用之间的损失函数,该损失函数是使用前面小节中的基本简单策略定义的,因此我们希望该神经网络策略能够实现与基本的非神经网络策略大致相同的奖励:
# nn_simple_policy.py
import tensorflow as tf
import numpy as np
import gym
env = gym.make("CartPole-v0")
num_inputs = env.observation_space.shape[0]
inputs = tf.placeholder(tf.float32, shape=[None, num_inputs])
y = tf.placeholder(tf.float32, shape=[None, 1])
hidden = tf.layers.dense(inputs, 4, activation=tf.nn.relu)
logits = tf.layers.dense(hidden, 1)
outputs = tf.nn.sigmoid(logits)
action = tf.multinomial(tf.log(tf.concat([outputs, 1-outputs], 1)), 1)
cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)
optimizer = tf.train.AdamOptimizer(0.01)
training_op = optimizer.minimize(cross_entropy)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(1000):
obs = env.reset()
while True:
y_target = np.array([[1\. if obs[2] < 0 else 0.]])
a, _ = sess.run([action, training_op], feed_dict={inputs: obs.reshape(1, num_inputs), y: y_target})
obs, reward, done, info = env.step(a[0][0])
if done:
break
print("training done")
我们将outputs定义为logits净输出的sigmoid函数,即动作概率 0,然后使用tf.multinomial采样动作。 请注意,我们使用标准的tf.train.AdamOptimizer及其minimize方法来训练网络。 要测试并查看该策略的表现,请运行以下代码:
total_rewards = []
for _ in range(1000):
rewards = 0
obs = env.reset()
while True:
y_target = np.array([1\. if obs[2] < 0 else 0.])
a = sess.run(action, feed_dict={inputs: obs.reshape(1, num_inputs)})
obs, reward, done, info = env.step(a[0][0])
rewards += reward
if done:
break
total_rewards.append(rewards)
print(np.mean(total_rewards))
总奖励的平均值约为 40 左右,这与使用无神经网络的简单策略的收益大致相同,这正是我们在训练阶段将y: y_target专门用于简单策略时的期望值 ,以训练网络。
现在,我们都准备探索如何在此基础上实现策略梯度方法,以使我们的神经网络表现更好,获得的奖励要大几倍。
策略梯度的基本思想是,为了训练神经工作以生成更好的策略,当所有智能体从环境中知道的都是从任何给定状态采取行动时所能获得的奖励(这意味着我们不能使用监督学习进行训练),我们可以采用两种新机制:
-
折扣奖励:每个动作的值都需要考虑其未来动作的奖励。 例如,一个动作获得立即奖励 1,但是在两个动作(步骤)之后结束剧集的长期奖励应该比获得立即奖励 1 但在 10 个步骤之后结束剧集的动作具有较少的长期奖励。 动作的折现奖励的典型公式是其立即奖励加上其每个未来奖励的倍数和由未来步骤提供动力的折现率的总和。 因此,如果一个动作序列在剧集结束前有 1、1、1、1、1 个奖励,则第一个动作的折扣奖励为
1+(1*discount_rate)+(1*discount_rate**2)+(1*discount_rate**3)+(1*discount_rate**4)。 -
测试运行当前策略,查看哪些操作导致较高的折扣奖励,然后使用折扣奖励更新当前策略的梯度(权重损失),以使具有较高折扣奖励的操作在网络更新后, 下次被选中的可能性更高。 重复这样的测试运行并多次更新该过程,以训练神经网络以获得更好的策略。
有关更详细的讨论和策略梯度的演练,请参阅 Andrej Karpathy 的博客条目,《深度强化学习:来自像素的乒乓》。 现在,让我们看看如何为 TensorFlow 中的 CartPole 问题实现策略梯度。
首先,导入 tensorflow,numpy 和 gym,并定义一个用于计算标准化和折价奖励的助手方法:
import tensorflow as tf
import numpy as np
import gym
def normalized_discounted_rewards(rewards):
dr = np.zeros(len(rewards))
dr[-1] = rewards[-1]
for n in range(2, len(rewards)+1):
dr[-n] = rewards[-n] + dr[-n+1] * discount_rate
return (dr - dr.mean()) / dr.std()
例如,如果discount_rate为 0.95,则奖励列表[1,1,1]中第一个动作的折扣奖励为1 + 1 * 0.95 + 1 * 0.95 ** 2 = 2.8525,并且第二和最后一个折扣奖励是 1.95 和 1; 奖励列表[1,1,1,1,1]中第一个动作的折扣奖励为1 + 1 * 0.95 + 1 * 0.95 ** 2 + 1 * 0.95 ** 3 + 1 * 0.95 ** 4 = 4.5244,其余动作为 3.7099、2.8525、1.95 和 1 。 [1,1,1]和[1,1,1,1,1]的归一化折扣奖励为[1.2141, 0.0209, -1.2350]和[1.3777, 0.7242, 0.0362, -0.6879, -1.4502]。 每个规范化的折扣清单按降序排列,这意味着动作持续的时间越长(在剧集结束之前),其奖励就越大。
接下来,创建 CartPole 体育馆环境,定义learning_rate和discount_rate超参数,并像以前一样使用四个输入神经元,四个隐藏神经元和一个输出神经元构建网络:
env = gym.make("CartPole-v0")
learning_rate = 0.05
discount_rate = 0.95
num_inputs = env.observation_space.shape[0]
inputs = tf.placeholder(tf.float32, shape=[None, num_inputs])
hidden = tf.layers.dense(inputs, 4, activation=tf.nn.relu)
logits = tf.layers.dense(hidden, 1)
outputs = tf.nn.sigmoid(logits)
action = tf.multinomial(tf.log(tf.concat([outputs, 1-outputs], 1)), 1)
prob_action_0 = tf.to_float(1-action)
cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=prob_action_0)
optimizer = tf.train.AdamOptimizer(learning_rate)
请注意,此处不再像以前的简单神经网络策略示例那样使用minimize函数,因为我们需要手动微调梯度以考虑每个动作的折价奖励。 这就要求我们首先使用compute_gradients方法,然后以所需的方式更新梯度,最后调用apply_gradients方法(我们大多数时候应该使用的minimize方法实际上是在幕后调用compute_gradients和apply_gradients)。
因此,让我们现在为网络参数(权重和偏差)计算交叉熵损失的梯度,并设置梯度占位符,稍后将使用考虑了计算梯度和动作折现奖励的值来填充它,动作在测试运行期间使用当前策略选取:
gvs = optimizer.compute_gradients(cross_entropy)
gvs = [(g, v) for g, v in gvs if g != None]
gs = [g for g, _ in gvs]
gps = []
gvs_feed = []
for g, v in gvs:
gp = tf.placeholder(tf.float32, shape=g.get_shape())
gps.append(gp)
gvs_feed.append((gp, v))
training_op = optimizer.apply_gradients(gvs_feed)
从optimizer.compute_gradients(cross_entropy)返回的gvs是一个元组列表,每个元组都由(可训练变量的cross_entropy的)梯度和可训练变量组成。 例如,如果您在整个程序运行后查看gvs,您将看到类似以下内容:
[(<tf.Tensor 'gradients/dense/MatMul_grad/tuple/control_dependency_1:0' shape=(4, 4) dtype=float32>,
<tf.Variable 'dense/kernel:0' shape=(4, 4) dtype=float32_ref>),
(<tf.Tensor 'gradients/dense/BiasAdd_grad/tuple/control_dependency_1:0' shape=(4,) dtype=float32>,
<tf.Variable 'dense/bias:0' shape=(4,) dtype=float32_ref>),
(<tf.Tensor 'gradients/dense_2/MatMul_grad/tuple/control_dependency_1:0' shape=(4, 1) dtype=float32>,
<tf.Variable 'dense_1/kernel:0' shape=(4, 1) dtype=float32_ref>),
(<tf.Tensor 'gradients/dense_2/BiasAdd_grad/tuple/control_dependency_1:0' shape=(1,) dtype=float32>,
<tf.Variable 'dense_1/bias:0' shape=(1,) dtype=float32_ref>)]
请注意,kernel只是权重的另一个名称,(4, 4),(4, ),(4, 1)和(1, )是权重的形状和对第一个(输入到隐藏)和第二层(隐藏到输出)。 如果您从 iPython 多次运行脚本,则tf对象的默认图将包含先前运行的可训练变量,因此,除非调用tf.reset_default_graph(),否则需要使用gvs = [(g, v) for g, v in gvs if g != None]删除那些过时的训练变量, 将返回 None 梯度(有关computer_gradients的更多信息,请参见这里)。
现在,玩一些游戏并保存奖励和梯度值:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(1000):
rewards, grads = [], []
obs = env.reset()
# using current policy to test play a game
while True:
a, gs_val = sess.run([action, gs], feed_dict={inputs:
obs.reshape(1, num_inputs)})
obs, reward, done, info = env.step(a[0][0])
rewards.append(reward)
grads.append(gs_val)
if done:
break
在测试游戏之后,使用折价奖励更新梯度并训练网络(请记住training_op被定义为optimizer.apply_gradients(gvs_feed)):
# update gradients and do the training
nd_rewards = normalized_discounted_rewards(rewards)
gp_val = {}
for i, gp in enumerate(gps):
gp_val[gp] = np.mean([grads[k][i] * reward for k, reward in
enumerate(nd_rewards)], axis=0)
sess.run(training_op, feed_dict=gp_val)
最终,经过 1000 次迭代的测试和更新,我们可以测试经过训练的模型:
total_rewards = []
for _ in range(100):
rewards = 0
obs = env.reset()
while True:
a = sess.run(action, feed_dict={inputs: obs.reshape(1,
num_inputs)})
obs, reward, done, info = env.step(a[0][0])
rewards += reward
if done:
break
total_rewards.append(rewards)
print(np.mean(total_rewards))
请注意,我们现在使用经过训练的策略网络和sess.run以当前观察为输入来执行下一步操作。 总奖励的输出平均值约为 200,这与我们是否使用神经网络的简单直观策略相比有很大改进。
您也可以在使用tf.train.Saver进行训练后保存训练后的模型,就像我们在前几章中曾经做过的多次:
saver = tf.train.Saver()
saver.save(sess, "./nnpg.ckpt")
然后,您可以使用以下命令在单独的测试程序中重新加载它:
with tf.Session() as sess:
saver.restore(sess, "./nnpg.ckpt")
之前的所有策略实现都在 Raspberry Pi 上运行,甚至使用 TensorFlow 训练强化学习策略梯度模型的模型实现也需要大约 15 分钟才能完成。 这是我们涵盖的每项策略,在 Pi 上运行后返回的总奖励:
pi@raspberrypi:~/mobiletf/ch12 $ python single_minded_policy.py
9.362
pi@raspberrypi:~/mobiletf/ch12 $ python simple_policy.py
42.535
pi@raspberrypi:~/mobiletf/ch12 $ python nn_random_policy.py
21.182
pi@raspberrypi:~/mobiletf/ch12 $ python nn_simple_policy.py
41.852
pi@raspberrypi:~/mobiletf/ch12 $ python nn_pg.py
199.116
现在,您已经拥有了一个强大的基于神经网络的策略模型,可以帮助您的机器人保持平衡,并在模拟环境中进行了全面测试,在将模拟环境的 API 返回值替换为真实环境数据后,您可以将其部署在真实的物理环境中,当然,但是用于构建和训练神经网络强化学习模型的代码当然可以轻松地重用。
总结
在本章中,我们首先详细介绍了使用所有必需的附件和操作系统以及将 Raspberry Pi 板变成移动机器人的 GoPiGo 工具包来设置 Raspberry Pi 的详细步骤。 然后,我们介绍了如何在 Raspberry Pi 上安装 TensorFlow 并构建 TensorFlow 库,以及如何将 TTS 与图像分类集成以及如何使用 GoPiGO API 进行音频命令识别,从而使 Raspberry Pi 机器人可以移动,看到,听到和说出所有内容,而无需使用 Cloud API。 最后,我们介绍了用于强化学习的 OpenAI Gym 工具包,并向您展示了如何使用 TensorFlow 构建和训练功能强大的强化学习神经网络模型,以使您的机器人在模拟环境中保持平衡。
最后的话
因此,该说再见了。 在本书中,我们从三个经过预训练的 TensorFlow 模型开始,这些模型分别是图像分类,对象检测和神经样式迁移,并详细讨论了如何重新训练模型并在 iOS 和 Android 应用中使用它们。 然后,我们介绍了使用 Python 构建的 TensorFlow 教程中的三个有趣的模型(音频识别,图像字幕和快速绘制),并展示了如何在移动设备上重新训练和运行这些模型。
之后,我们从零开始开发了用于预测 TensorFlow 和 Keras 中的股价的 RNN 模型,两个用于数字识别和像素转换的 GAN 模型以及一个用于 Connect4 的类似于 AlphaZero 的模型,以及使用所有这些 TensorFlow 模型的完整 iOS 和 Android 应用 。 然后,我们介绍了如何将 TensorFlow Lite 以及 Apple 的 Core ML 与标准机器学习模型和转换后的 TensorFlow 模型一起使用,展示了它们的潜力和局限性。 最后,我们探索了如何使用 TensorFlow 构建 Raspberry Pi 机器人,该机器人可以使用强大的强化学习算法来移动,观看,聆听,讲话和学习。
我们还展示了同时使用 TensorFlow Pod 和手动构建的 TensorFlow 库的 Objective-C 和 Swift iOS 应用,以及使用即用型 TensorFlow 库和手动构建库的 Android 应用,以修复您在移动设备上部署和运行 TensorFlow 模型时可能遇到的各种问题。
我们已经介绍了很多,但是还有很多要讲的。 TensorFlow 的新版本已经快速发布。 已经构建并实现了采用最新研究论文的新 TensorFlow 模型。 本书的主要目的是向您展示使用各种智能 TensorFlow 模型的足够的 iOS 和 Android 应用,以及所有实用的故障排除和调试技巧,以便您可以在移动设备上为你的下一个杀手级移动 AI 应用快速部署和运行自己喜欢的 TensorFlow 模型。
如果您想使用 TensorFlow 或 Keras 构建自己的出色模型,实现最令您兴奋的算法和网络,则需要在本书结束后继续学习,因为我们没有详细介绍如何做到这一点, 但希望我们能激发您足够的动力来开始这一旅程,并从书中获得保证,一旦您构建并训练了模型,便知道如何快速,随时随地在移动设备上部署和运行它们。
关于走哪条路和要解决哪些 AI 任务,Ian Goodfellow 在接受 Andrew Ng 采访时的建议可能是最好的:“问问自己,下一步做什么是最好的,选取哪条路是最适合的:强化学习,无监督学习或生成对抗网络”。 无论如何,这将是一条充满兴奋的绝妙之路,当然还要有艰苦的工作,而您从本书中学到的技能就像您的智能手机一样,随时可以为您服务,并准备好将使您的甜蜜而聪明的小设备变得更加甜蜜和智能。