前言
前面通过词法分析,语法分析,DFA最后接受了一个输入实际上是理解了某一句编程语句,编译器的角色是将高级程序语言编译(翻译)为汇编代码,通过词法、语法分析编译器可以理解高级程序语言了,那么如何实现输出汇编代码和创建变量等等这一系列动作?属性文法,通过为产生式配备属性的计算规则,通过计算和传递属性处理语义,实现这一系列动作。
依赖图

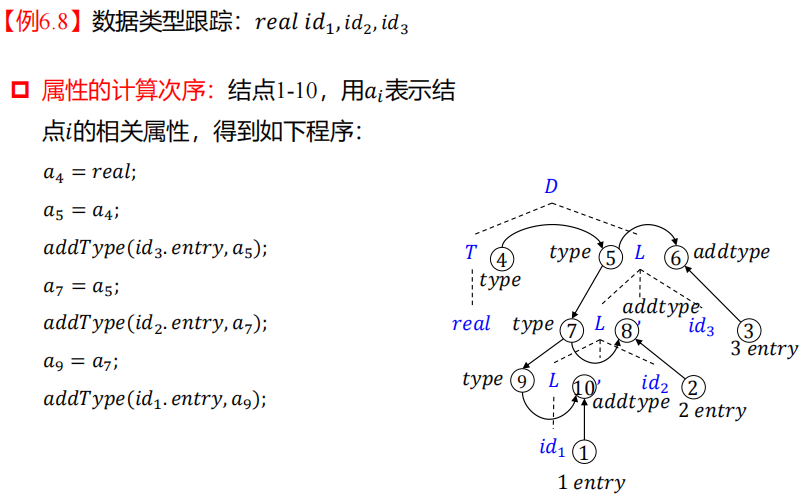
依赖图是DAG图,每个节点是一个属性,这样可以按照拓扑序计算属性。下面是一个跟踪(动作)数据类型的例子,最后可以确定 i d 1 , i d 2 , i d 3 id_1,id_2,id_3 id1,id2,id3的类型为real。
一遍扫描的处理方法

对于DAG,非常直观地,按照拓扑序进行属性的计算即可,关键是根据继承属性之间的依赖关系,确定兄弟节点的计算次序。S-属性文法,没有继承属性;L-属性文法,产生式右侧的非终结符号已经是拓扑序了,即兄弟节点的计算次序已经合适。
语法制导翻译

两个属性文法的例子

动作:建立抽象语法树,这里的属性是指向节点的指针。


动作:构建正规式对应的NFA。
NewState代表创建一个新状态。可以看到节点之间除了赋值、传递操作外还有mknode,mkleaf,AddArc等(绘图)实际动作,影响到属性之外的事物,最终输出的是图。
L-属性文法

翻译模式

引入翻译模式的概念,使得动作更加丰富(产生式中间有动作,实际上可以通过引入 ϵ \epsilon ϵ,使得动作永远在产生式右部末尾)。
消除翻译模式的左递归
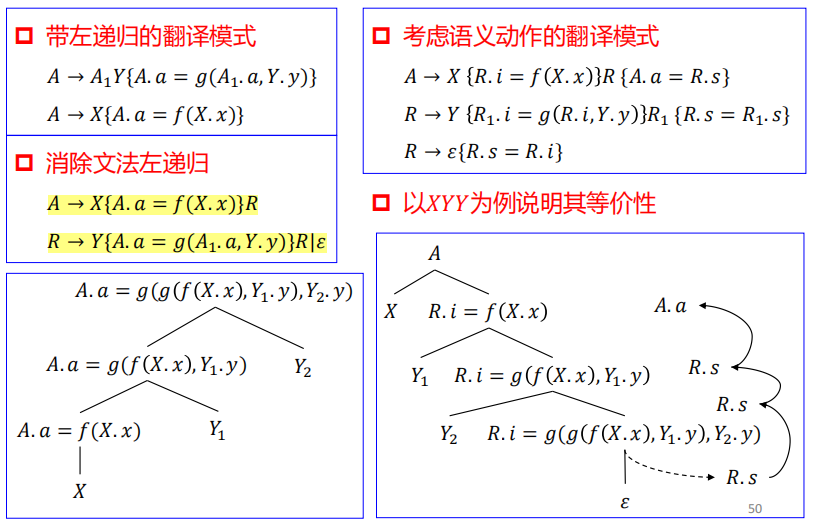
原先,是递归计算儿子节点的综合属性,再返回计算自身的综合属性;修改后增加非终结符R,通过层层计算继承属性R.i,再通过综合属性R.s传回来。