这篇文章是用来讲解Resnet(残差网络)代码的,结合代码理解残差网络结构。
目录
Bottleneck类
Conv3×3
Conv1×1
BasicBlock
ResNet
_make_layer代码解析
完整的ResNet代码:
可以直接调用torch内置的resnet官方代码。
from torchvision.models import resnet50
model = resnet50()
print("model:", model)不论是调用resnet50还是resnet101,这些模型都是调用的Resnet模型。因此我们仅需要看这个类就可以。
在ResNet这个类中又由Bottleneck(瓶颈层)、3×3卷积层、1×1卷积层、BasicBlock组成。接下来将逐步解释。
Bottleneck类
拼劲层这个类在resnet50及之后的系列用这个,resnet18、resnet34用BasicBlock
参数说明:
expansion=4:Bottleneck的输出通道数是输入通道数的4背
inplanes:输入通道数
planes:输出通道数
stride:步长
downsample:下采样
groups:分组卷积
base_width:卷积块宽度
dilation:空洞卷积
nor_layer:是否传入norm_layer
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
# 表示如果输入和输出通道数不等,那就通过1x1卷积进行升维后的相加操作,否则可以可以直接相加
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
'''
if downsample:
x -->conv_1x1-->bn-->relu-->conv_3x3-->bn-->relu-->conv_1x1-->bn--add-->relu-->out
|___________downsample____________________________________________|
else:
x -->conv_1x1-->bn-->relu-->conv_3x3-->bn-->relu-->conv_1x1-->bn--add-->relu-->out
|__________________________________________________________________|
'''
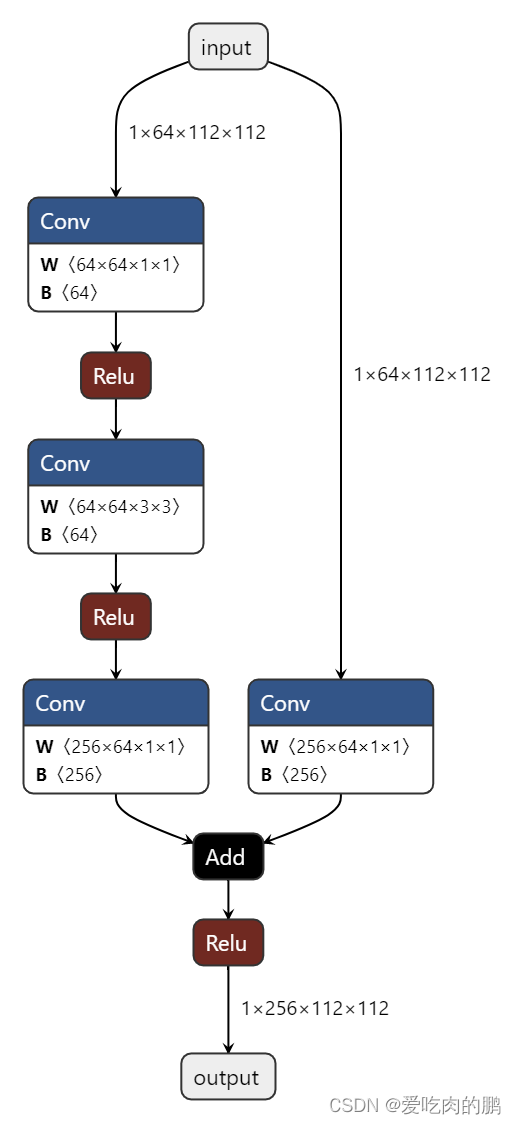
return out下面这张图是一个Bottleneck结构图,残差边为一个1x1的卷积。
Conv3×3
传入参数:
in_planes:输入通道
out_planes:输出通道
stride:步长
groups:卷积分组数
dilation:可以控制空洞卷积
可以看到这个conv3×3中的kernel_size为3,bias为False,padding的大小和dilation一样。
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)Conv1×1
in_planes:输入通道数
out_planes:输出通道数
可以看到kernel_size为1,bias为False
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)BasicBlock
这个BasicBlock当在resnet18、resnet34用这个
传入参数:
inplanes:输入通道数
planes:输出通道数
stride:步长
downsample:下采样
groups:分组数
base_width:宽度
当norm_layer为None的时候,则norm_layer为BN层。当采用groups(分组卷积)或者base_width不为64的时候抛出错误:
'BasicBlock only supports groups=1 and base_width=64'该错误表示在BasicBlock仅支持groups=1和base_width=64
当dilation>1的时候,表示在BasicBlock采用了空洞卷积,抛出错误。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
"""
if norm_layer is None
if downsample is not None:
x -->conv_3x3-->bn-->relu-->conv_3x3-->bn--add--relu-->out
|____________downsample_____________________|
if downsample is None:
x -->conv_3×3-->bn-->relu-->conv_3×3-->bn--add--relu-->out
|___________________________________________|
"""
return out可以看到在BasicBlock(基础块)中当需要进行下采样的时候,残差边需要一次下采样。
ResNet
在正式讲Resnet之前需要讲一下_make_layer函数,因为网络结构中的残差层都是由这个函数决定的。
_make_layer代码解析
参数说明:
block:传入BasicBlock还是Bottleneck
planes:输出通道数
blocks:传入的layer
stride:步长,默认为1
dilate:是否采用空洞卷积,默认为False
这里以不采用空洞卷积,也就是dilate=False,block取Bottlenenck为例。
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)上面这段代码表示什么时候采用下采样的情况,当stride不为1,或者通道数inplanes(初始默认取值64) ≠ planes * block.expansion(此时block.expansion=4)。输入和输出通道不相等时候,下采样结构定义为:
downsample:
(conv1×1:conv2d(inplanes,4*planes,stride),
norm_layer:BN)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion上面这段代码表示,创建一个空的列表layers, 此时的block为Bottleneck,将获得的Bottlenck放入layers列表中。放入以后下一层的inplanes输入通道数为变成上一层输出通道数planes的4倍【也就是为下一个block做准备】。
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))而上面这一段代码就是表示当前的Bottleneck会重复几次(不过需要注意的是,在每个layer中只在第一个bottleneck用了1x1的残差边)。
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)接下来是一步一步看ResNet中的代码。
参数说明:
block:表示传入BasicBlock或者Bottleneck层。
layers:传入的是个列表,可以通过获取layers[index]来控制stride,以及是否采用空洞卷积。
num_classes:分类数量
zero_init_residual:初始化
groups:分组数
replace_stride_with_dilation:表示是否传入空洞卷积参数。如果不指定,则赋值为 [False, False, False],表示不使用空洞卷积。
norm_layer:是否传入norm_layer层,不传入的时候则为BN层。
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):代码讲解将以Resnet50为例,那么此时传入的block就为Bottleneck,layer=[3,4,6,3],num_classes=1000,其他Resnet系列可以看下面这张图。在看代码的时候希望大家可以对着下面这个图来看,方便理解。
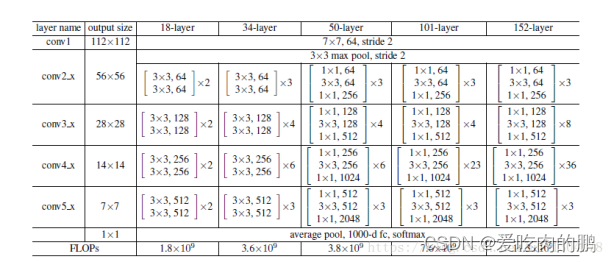
先看下下面这几行代码,可以看到这三行代码是由一个输入通道为3,输出通道为64,k=7,s=2,paddind=3,bn层,relu函数构成的,这正好就对应到上面图中的conv1。
# conv1结构代码
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)然后再看conv2_x。conv2_x是由一个最大池化,还有3个Bottleneck组成(你可以理解为图中的3,4,6,3就是这类结构重复次数)。
# conv2_x
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])代码中的layer1调用的是_make_layer函数,
下面这张图为layer1,表示为第一个bottleneck结构。在Resnet的每个Bottlenck中,只在第一个Bottlenck处的残差边会用1x1的卷积进行升维,其他的都是输入和输出直接相加,这个特点需要注意一下。

self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0]) #
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])然后看layer2,3,4,过程和layer1是一样的,只不过这里传入的stride=2.
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)最后就是连接一个平均池化和全连接用来分类。
完整的ResNet代码:
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x所以可以进行一个总结:
_make_layer函数用来制作残差块的结构,参数layer可以用来控制每个残差层是由多少个残差块组成的,在残差块结构中判断是否采用downsample(1x1卷积进行升维)是根据步长或者输入输出通道数是否相等,如果步长为1,输入通道数不等于输出通道数就会采用一个1x1卷积进行升维。每个残差层layer只有第一个残差块是采用了downsample。
后续将结合这一部分做知识蒸馏的讲解,请持续关注