副本机制的好处
副本在分布式系统下,不同的网络互联的机器保存同一份数据。我们知道在分布式系统中,都会通过数据镜像、数据冗余的方式来提升高可用性。
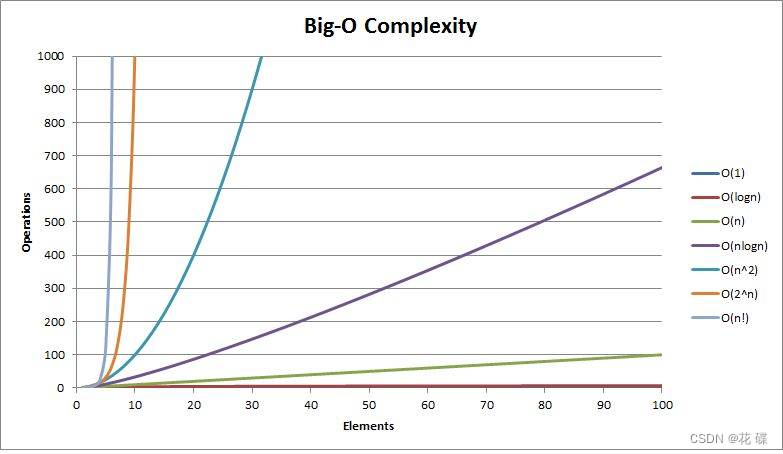
- 提供数据冗余:这点比较好理解,说白了就是通过数据冗余在不同的服务器上,即使一台出现宕机,也不会影响到系统的正常运转,并且因为有数据持久化机制,所以在高可用系统架构中必定使用。
- 高伸缩性:将一份数据存储到多个地方,可以有效提高读的能力。
- 改善数据局部性:可以将不同的数据放在离用户近的地方,比如CDN这种机制。
但是很可惜的是,Kafka只提供了第一种机制,后两者没有提供。
副本定义
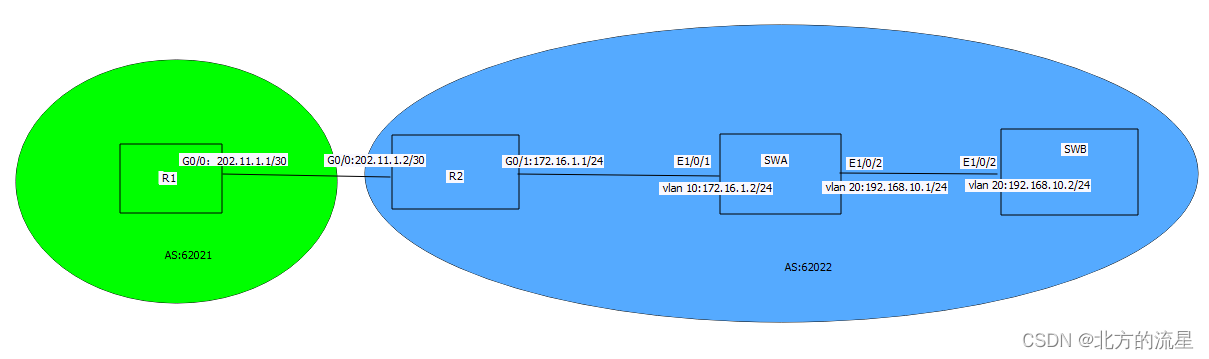
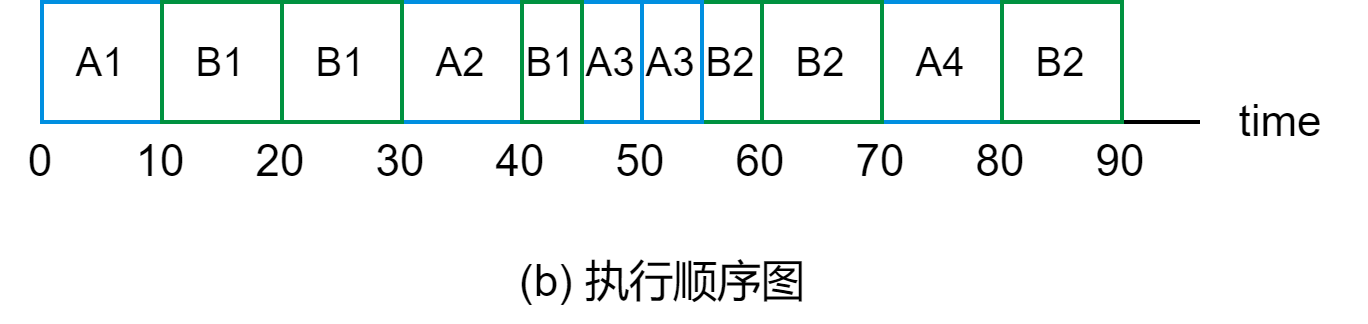
我们知道Kafka的层级是在不同的主题下,将同一个主题拆分成不同的分区,并且在分区层级下有不同的副本,通过存储在不同的Broker中,以提供数据的可用性。而这个副本本质上就是一个可以追加写的日志文件。
所以在实际的生产环境中,可能不同的Broker上同时存储不同主题的分区的副本数据。
如下图所示,三个Broker,主题1分区0的三个副本分别存储在不同的Broker上。即使Broker2宕机了,但是Broker1和3存活,依然可以提供数据访问。
副本角色
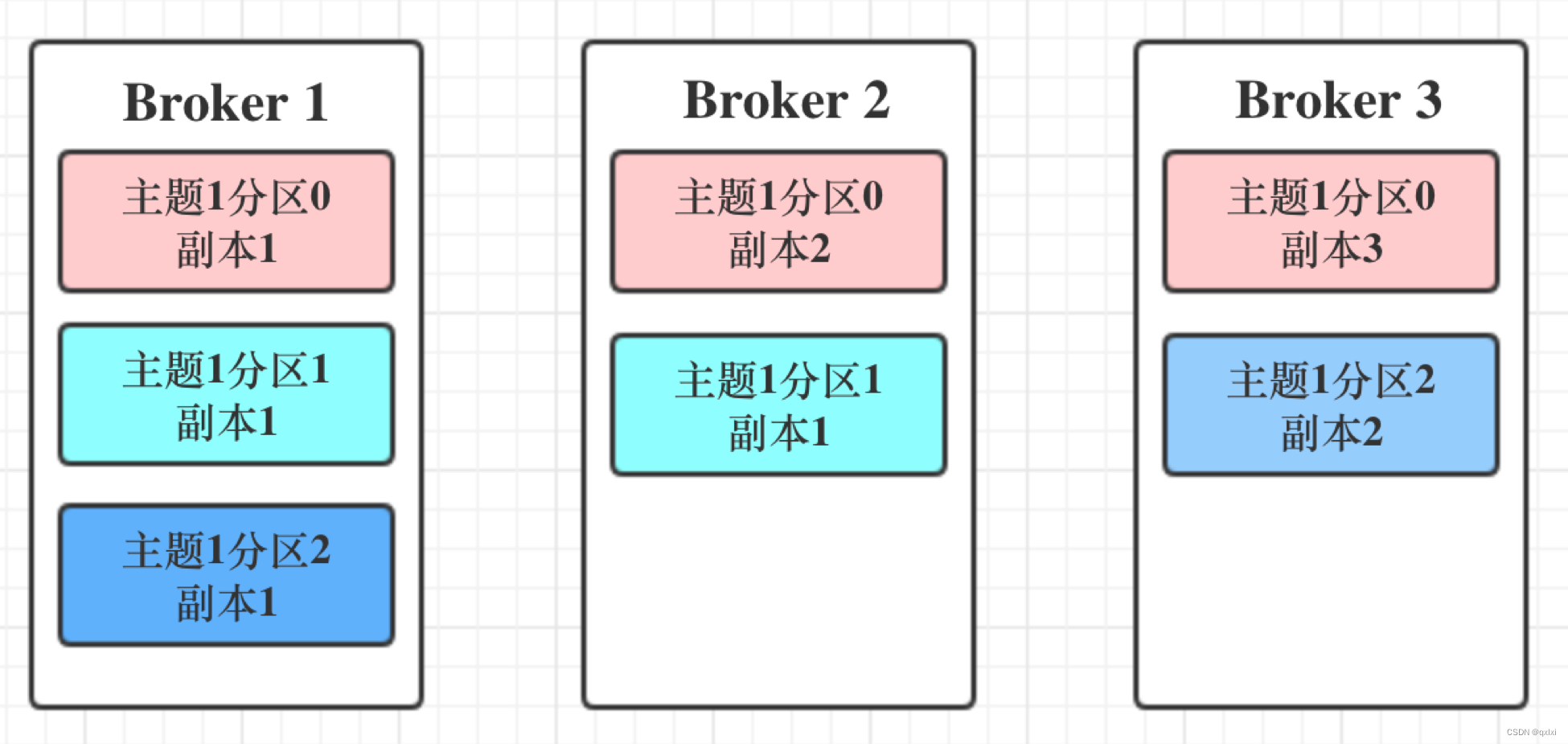
既然分区可以存储多个副本,那么多个副本之间的数据是如何保证数据一致性的,而Kafka采用的就是基于领导者的副本机制
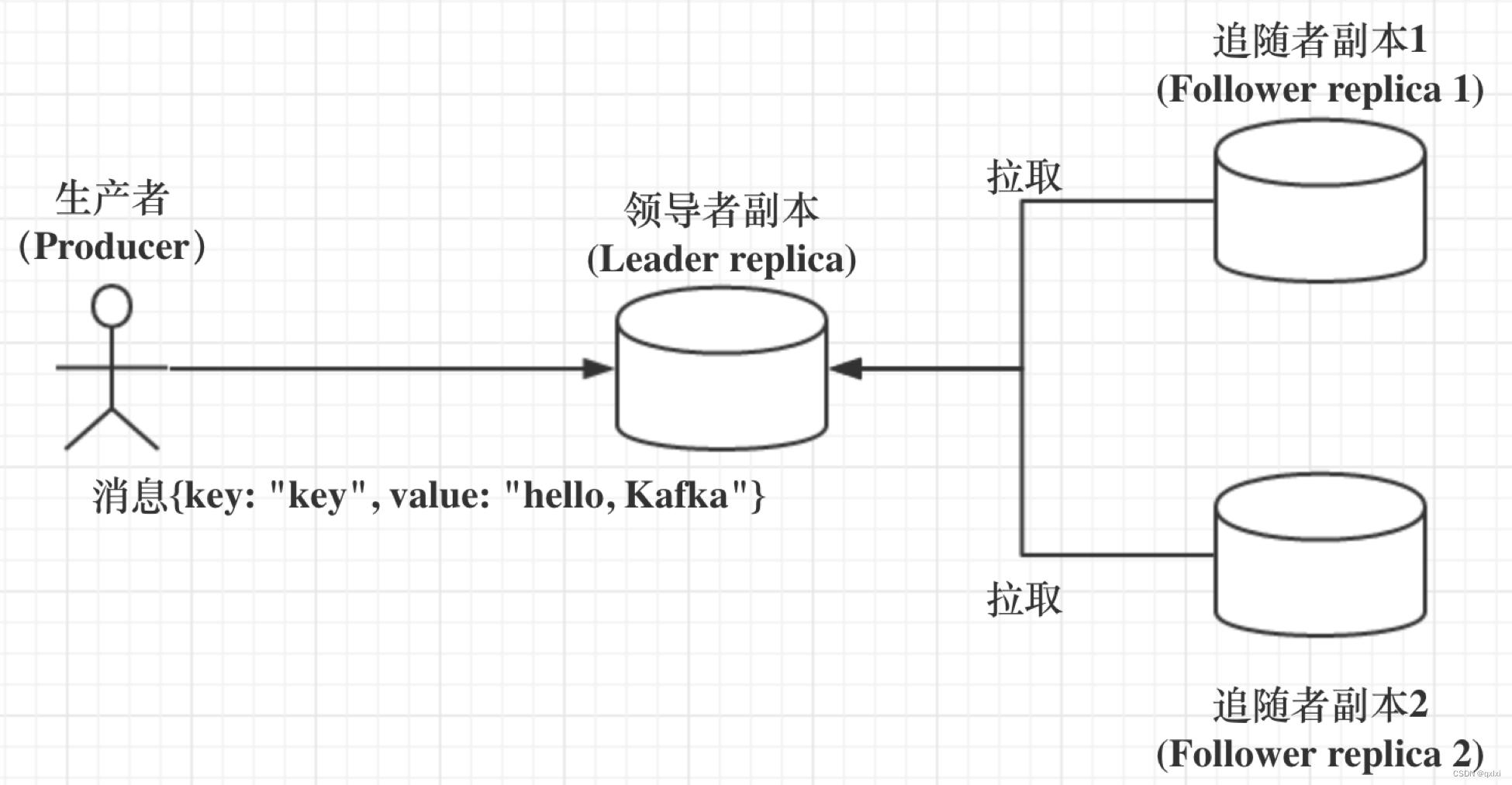
1.副本分为两类,领导者副本和追随者副本。每个分区在创建时都要选举一个领导者副本,而追随者副本进行数据同步
2.对副本的读写操作都集中在领导者副本上,而追随者副本的唯一作用就是从领导者副本异步拉取消息,写入到自己的提交日志中,实现和领导者副本的同步。
3.当领导者副本所在的Broker挂掉之后,Zk可以通过监听机制,在已有的副本中选择一个新的领导者副本,而当老的领导者副本恢复后,只能成为新的追随者副本。
以上就是副本的相关机制,而这就是Kafka副本只提供了第一种数据冗余,而不能通过追随者副本进行读。
为什么这样设计?
方便实现Read-your-writes
Read-your-writes的意思是在生产者向Kafka写入一条消息后,消费者马上去消费这条消息。如果副本可以提供读的话,因为存在数据同步的延时,在副本上可能读不到这条数据。而直接对领导者副本写读的话不会出现这样的问题。
方便实现单调读(Monotonic Reads)
单调读一致,说白了就是不会出现消费者一会能读到一会读不到。
比如有两个副本A和B,向领导者写入1,2两条消息,A同步了1,2 但是B只同步了1,当从A副本中读到了1,切到B副本中没有读到2,那么此时数据就出现丢失。
In-sync Replicas(ISR)
我们上面说了追随者副本是异步拉取领导者副本的消息,那么什么情况下追随者副本才和领导者副本同步呢,kafka引入了ISR集合,也就是Leader副本天然就在ISR集合中,而只有有Leader副本同步的副本才可以进入ISR集合中。
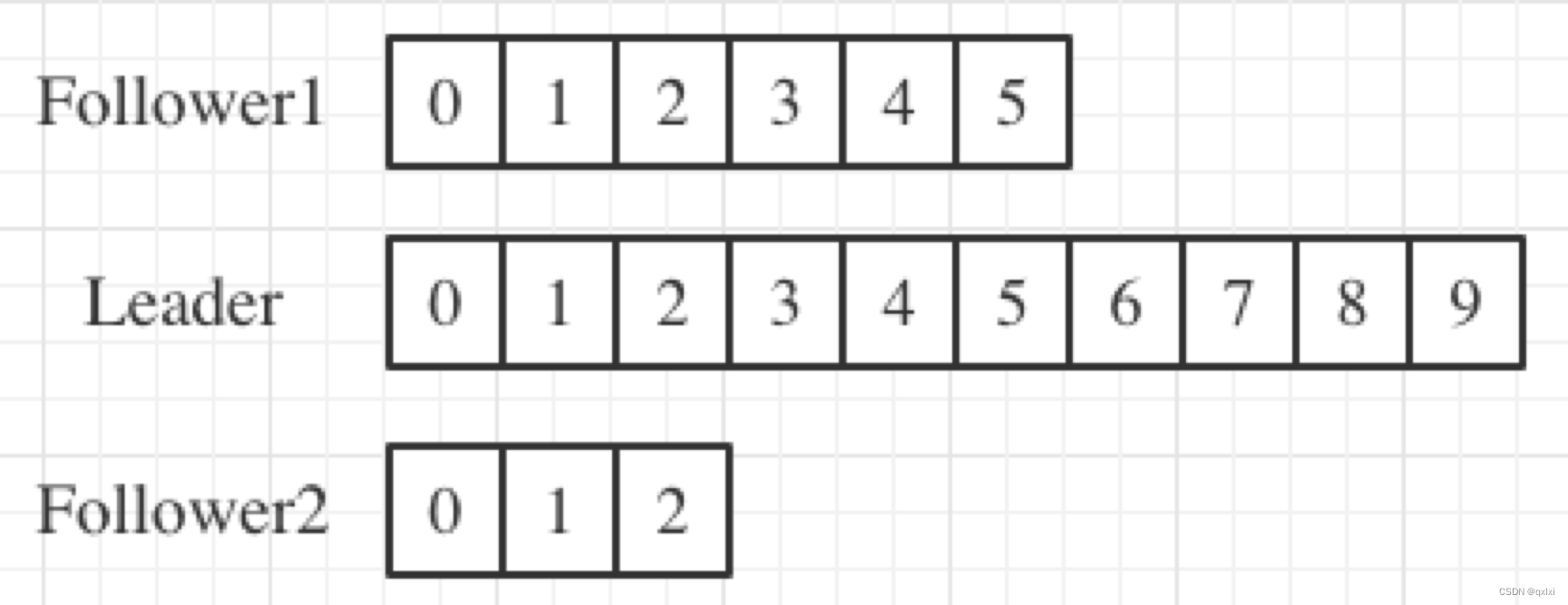
什么情况下追随者副本才满足进入ISR的条件,也就是实时同步Leader副本消息
图中,有一个Leader副本和两个追随者副本,Leader副本写入10条消息,而Follower1同步了6条,Follower2同步了3条,可以说两个追随者副本和Leader副本不同步嘛,答案其实是不一定。
决定是否与Leader副本同步的条件是,Broker 端参数 replica.lag.time.max.ms 参数值,默认是10S,如果连续不超过10S,那么追随者副本就是同步Leader副本。
当追随者副本超过10S不同步时,会被T出ISR集合,反之如果追上来,就会重新加入到ISR集合,而ISR集合是实时动态变化的。
Unclean 领导者选举(Unclean Leader Election)
我们知道Leader副本天然就是ISR中,但是如果ISR集合中为0,说明Leader副本也挂了,这个时候如何进行选举,实际上Kafka将不在ISR集合中的副本成为非同步副本,但是非同步副本明显是落后于Leader副本的,而选举这种非同步副本为Leader过程称为Unclean领导者选举。可以通过unclean.leader.election.enable 控制是否允许 Unclean 领导者选举。默认false。
酸与碱
如果使用Unclean领导者选举,那么势必会出现数据不一致性,但是可以提供服务。如果不使用Unclean选举,虽然保证了数据一致性,但是服务不可用。显然这就是一个不能互相平衡的选举,一般来说我们需要结合具体的业务来进行配置,但是一般还是不建议配置。
小结
副本机制是存在于Broker中的,而副本提供了是那种好处,数据冗余,高伸缩性,改善数据局部性。以及副本是否实时同步的标准。