前言
1.如何计算价值函数?
为了使模型训练的最好,学习到更多有用的知识即完成任务的最好策略。对策略好坏的评价标准自然是得到最多最好的奖励,那么如何找到最好的最好的奖励,即如何得到最好的价值函数?
首先对于在状态s,根据策略采取行为 a 的总奖励q是 当前奖励R 和 对未来各个可能的状态转化奖励的期望v组成,根据一定的 ϵ 概率每次选择奖励最大q或探索,便可以组成完整的策略,那么目标就变成了计算这个 q 值,然后根据q选择策略就好。
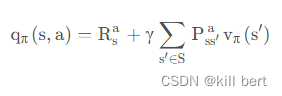
- 穷举法:把所有可能的路径和状况都试一遍计算,直接比较最后哪条路的总价值最大。
- 动态规划(DP):将一个问题拆成几个子问题,分别求解这些子问题,反向推断出大问题的解。即要求最大的价值,那么根据递推关系,根据上一循环得到的价值函数来更新当前循环。但是它需要知道具体环境的转换模型,计算出实际的价值函数。相比穷举法,动态规划即考虑到了所有可能,但不完全走完。
- 蒙特卡洛(MC):采样计算。即通过对采样的多个完整的回合(如玩多次游戏直到游戏结束),在回合结束后来完成参数的计算,求平均收获的期望并对状态对动作的重复出现进行计算,最后再进行更新。
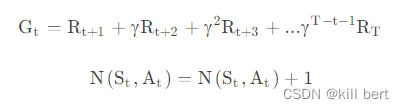
状态价值函数和动作价值函数的更新就为:
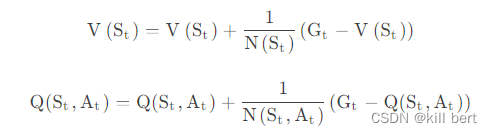
这种方法是价值函数q的无偏估计,但方差高(因为需要评价每次完成单次采样的结果,波动往往很大)。
- 时序差分(TD):步步更新。不用知道全局,走一步看一步的做自身引导。即此时与下一时刻的价值函数差分(也可以理解是现实与预测值的差距)来近似代替蒙特卡洛中的完整价值。
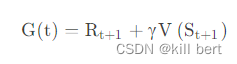
那么:

所以它是有偏估计,但是方差小,也便于计算,在实践中往往用的最多。
一、 Sarsa算法简介
Sarsa 是一种on-policy算法,它优化的是它实际执行的策略,它直接用下一步会执行的动作去优化 Q 表格。
在学习的过程中,只存在一种策略,它用同一种策略去做动作的选取和优化。所以 Sarsa 知道它下一步的动作有可能会跑到悬崖那边去,它就会在优化自己的策略的时候,尽可能离悬崖远一点。
1.更新公式
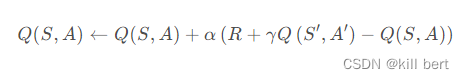
2.预测策略
- Sarsa算法采用ε 贪心搜索的策略
3.代码
链接:https://pan.baidu.com/s/1LOTz2xTbNbu6DrEpYAnnZw?pwd=ps7l
提取码:ps7l
二、Q-Learning算法简介
Sarsa 是一种off-policy算法,它优化的是它所有执行的策略,它用下一步会执行的所有动作去优化 Q 表格。
在学习的过程中,存在两种策略,它用一种策略去做动作的选取,用另一种策略优化。所以 Q-Learning 不知道它下一步的动作有可能会跑到悬崖那边去,它就会在优化自己的策略的时候,找到一条风险比较大的路。
1.更新公式
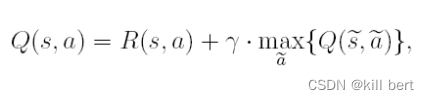
2.二者区别
Q-learning 和 SARSA 这两个公式区别就在Q value 更新方式上,Q-learning 是用max的方式更新Q value ,也就是说这个max方式就是他的更新策略(不带有探索性,完全的贪婪)。但是Q-learning的执行策略是带有epsilon的探索方式。所以他就是Off Policy
3.预测策略
- Q-learning 算法采用ε 贪心搜索的策略
4.代码
链接:https://pan.baidu.com/s/1j3igmVPZ6eTLAaOy2qTp8A?pwd=vca7
提取码:vca7