阶段一:
前段时间,突然发现服务在毫无征兆的情况下发生了重启。去看了一下容器退出的日志,发现内存利用率超过了100%,导致容器重启,进一步看了skyWalking,发现heap内存超了,当时只是简单的以为是流量上涨导致CPU和内存资源不足,所以增加了相应的配置,同时启动命令中增大了指定的堆内存大小。
阶段二:
在做了阶段一的相应变更之后,没过多久,再次发生了服务重启现象,感觉应该是内存泄漏,因为将skyWalking监控时长拉长到以天为单位,发现heap大小一直呈现一个上涨的斜线,说明内存没有被回收掉。如果以分钟为间隔,则看到内存大小是一个波动的线条,发现不了问题。
初步检查代码,发现了一个问题,在线程中传递上下文信息时,用到了MDC,这个类背后其实是ThreadLocal类,但是在使用完成之后,我没有手动去清除,可能会导致内存泄漏,即线程回收,但是对应的ThreadLocal信息还存在,当请求增多,内存就会逐步泄漏。
于是手动在使用完毕的地方显式清除,同时在异常捕获的地方也加入了MEC.clear()。
除了这个问题,顺便指定了垃圾回收器为G1,而取代了JDK1.8默认的CMS。为了吞吐量的考虑。
阶段三:
加入了之后经过一个周末的观察,发现heap大小增加的现象依旧存在。其中还有个小插曲,阶段二中指定了G1,但是腾讯云的pod中执行java命令-XX:+PrintCommandLineFlags -version或者-XX:+PrintFlagsFinal,都显示使用的是ParallelGC,当使用arthas查看时,才显示的是G1。
eg:
使用java命令查看:



使用artheas:
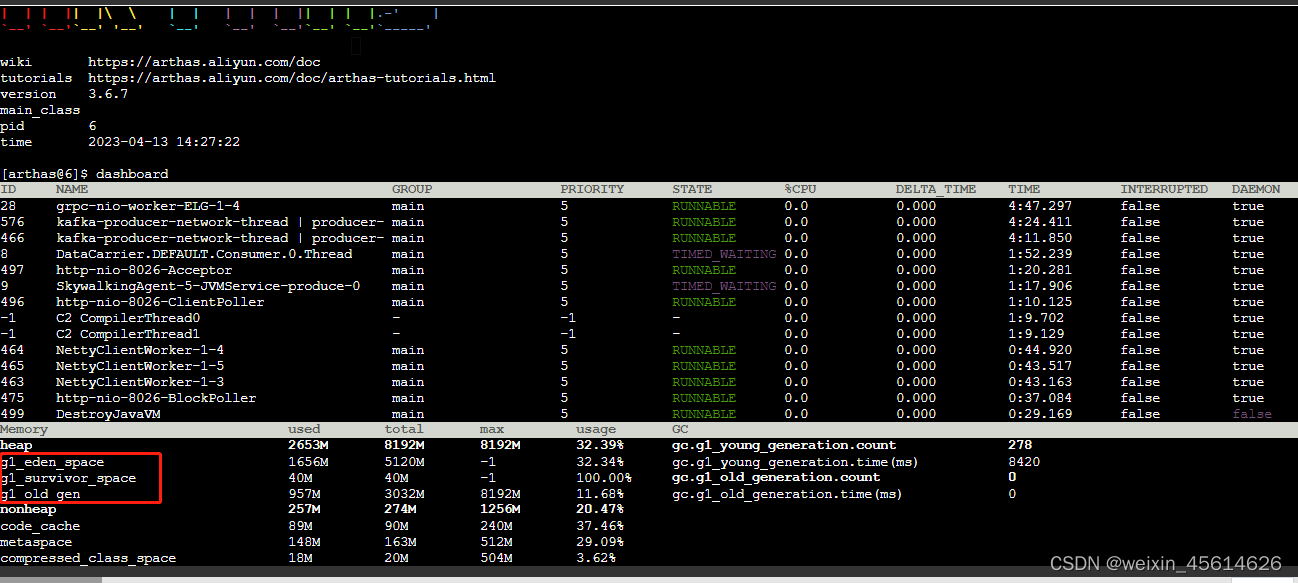
还是阿里开源的工具好用啊!
这次觉得内存泄漏问题可能没那么简单,于是将dump文件下载.
先执行jps命令,得到你的jvm的进程号:

接着执行命令:
jmap -dump:format=b,file=文件名.hprof <进程ID>
之后就能找到这个文件,当内存泄漏时,一般文件可能会过大,注意不要影响线上服务。生成之后可以下载下来,我这个压缩后将近800M。
压缩命令如下:
tar -zcvf filename.tar.gz filename
之后用内存分析工具打开,我用的是MAT,注意安装的时候要根据自己的jdk版本来找对应的MAT版本,例如我的是jdk1.8,下载的MAT版本是20180604-win32.win32.x86_64。还要注意如果hprof打不开,可能是你配置的程序内存大小太小了,MemoryAnalyzer.ini文件打开,-Xmx后边默认是1024M,改大一点就好了。
用内存分析工具打开dump文件,
Leak Suspects提示的是软件分析出来可能的泄漏猜测。
点击dominator_tree,
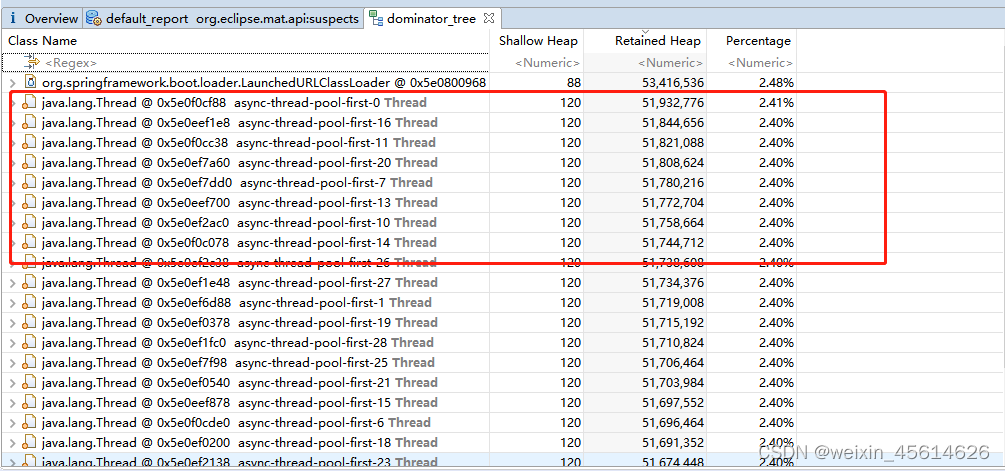
可以看到是异步线程池里边的线程占用了大量内存,进一步点开,发现是我引用的公司内其他组的打印日志jar包出现了问题,使用的vector容器有15W个变量存储,占用了所有的内存。
目前将异步线程这块的引用去掉,重新灰度了一个pod进行观测,对比看是否是这个原因引起的泄漏。
确实引用的打印日志的jar包有问题,异步线程的上下文没有被清除,通过内存分析,发现当前线程的信息中还有这个线程之前执行任务时候的日志,没有被清楚,说是给线程池加上一个装饰器就可以了,目前还在尝试这个解决办法