文章目录
- 一. 网络基础
- 1.2 联网协议和层
- 1.2.1 网络采用分层的思想
- 1.2.2 OSI体系结构(重点!!)
- 1.2.3 TCP/IP协议
- 1.2.3.1 网络接口与物理层
- 1.2.3.2 网络层
- 1.2.3.3 传输层
- 1.2.3.4 应用层
- 1.2.4 网络封包与拆包
- 1.3 TCP和UDP的异同点(重点!!!)
- 1.3.1 TCP --- 稳定
- 13.2 UDP --- 快速
- 1.4 IP地址
- 1.4.1 IP地址的分类
- 1.4.2 IP地址划分
- 1.4.3 点分十进制
- 1.4.4 子网掩码(重点!)
- 1.4.4.1 子网掩码的格式
- 1.4.4.2 子网掩码的使用
- 1.5 网关
- 1.6 域名系统
- 1.7 端口号
- 二. 跨主机传输
- 1. 字节序(重点)
- 1.1 字节序的概念
- 1.2 本地字节序与网络字节序
- 1.3字节序转换函数
- 1.3.1 htons htonl 主机字节序-->网络字节序**
- 1.3.2 ntohs ntohl 网络字节序---->主机字节序
- 1.4 结构体对齐
- 1.5 类型长度
- 2. IP转换
- 2.1点分十进制--->网络字节序
- 2.1.1 inet_aton
- 2.1.2inet_pton
- 2.1.3inet_addr 最常用
- 2.2 网络字节序--->点分十进制
- 2.2.1 inet_ntoa 常用
- 2.2.2 inet_ntop
一. 网络基础
-
网络编程的概念
-
网络编程本质上就是进程间通信,只不过进程分布在不同的主机上。
-
在跨主机传输过程中,需要确定通信协议后,才可以通信。
-
1.2 联网协议和层
联网协议:定义如何在一个网络上传输信息的一组规则
1.2.1 网络采用分层的思想
每一层都有自己独立的功能,但是每一层都不可获取
通常把功能相近的协议们组织在一起,放在一层,协议栈。所以每一层中其实有多个协议。
分层的好处:
- 各层之间独立,每一层不需要知道下一层如何实现,而仅仅只需要知道该层通过层间的接口所提供的的服务。
- 稳定,当任何一层发生变化时,只要层间接口关系保持不变,则这层以上或以下层不受影响。
- 易于实现和维护(知道是什么功能,就到指定层去查找)
- 促进标准化工作
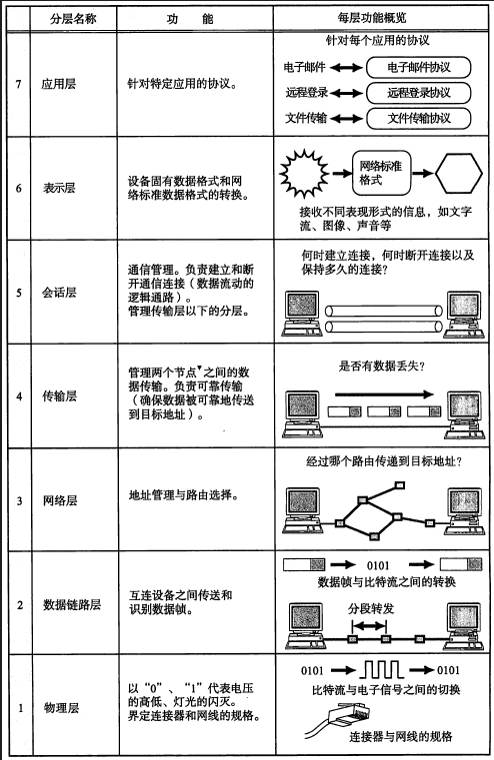
1.2.2 OSI体系结构(重点!!)
ISO(国际标准化组织)制定了一个国际标准OSI(开放式通讯系统互联参考模型),对通讯系统进行了标准化。
定义了7层模型
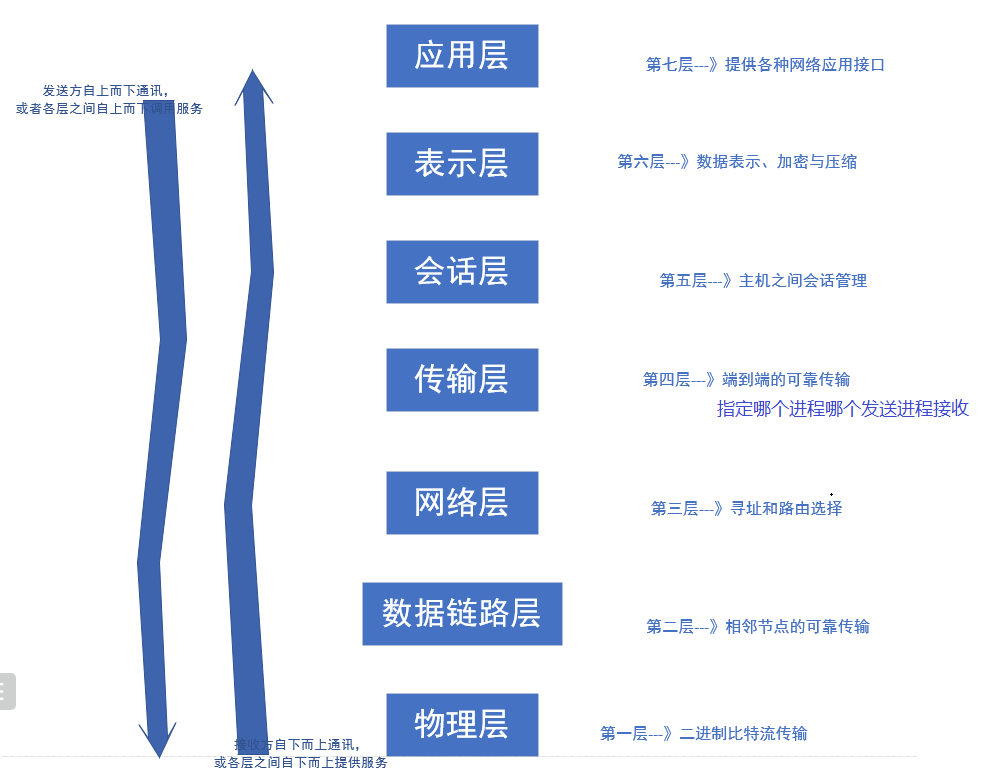
屋里数据要跑路,沿着链路上高速。—》物理层,数据链路层
跑到高速没网络,数据传输靠不住。—》网络层,传输层
掏出手机要叫人,一开会话嘟嘟嘟。—》会话层
老铁表示要玩完,应用技术才懂路。—》表示层、应用层
1.2.3 TCP/IP协议
OSI模型是一个理想化的模型已经很少使用,没有完整的实现,但是模型本身非常通用。
TCP/IP协议 是Internet事实上的工业标准

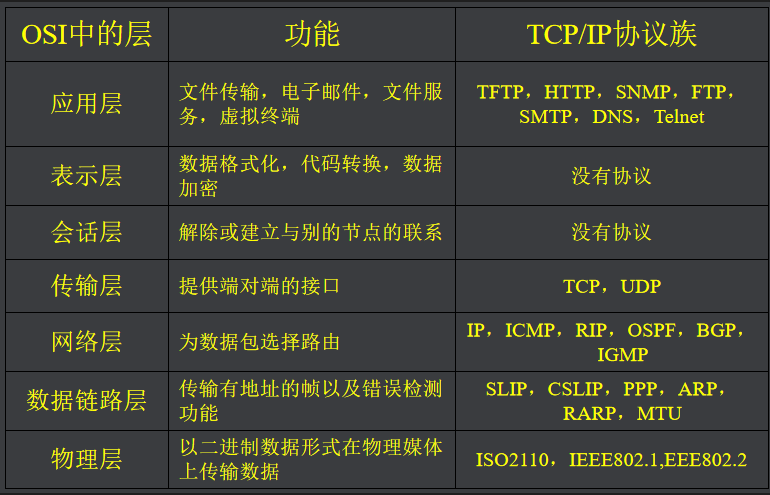
1.2.3.1 网络接口与物理层
也叫做网络访问层
**功能:**包括ip地址与物理地址的映射(MAC),以及将上一层的ip报文封装层帧,转换成二进制比特流传输
MAC:物理地址,48bit全球唯一,网络设备的身份标识(cmd —> ipconfig/all),由厂商出厂后确定
由电气电子工程协会IEEE定义的。
切换网络后,ip地址改变,MAC地址不变
ARP/RARP 地址解析协议/逆向地址解析协议
ARP(Address Resolution Protocol):通过ip地址获取其对应的mac地址。
RARP(Reverse Address Resolution Protocol):通过mac地址获取其对应的ip地址。
PPP(Point to Point Protocol)协议:拨号协议(GPRS/3G/4G)
1.2.3.2 网络层
负责在主机之间的通讯中选择数据包传输的路径,即选择路由。
1. IP协议(Internet Protocol)
ip协议根据数据包的目的ip地址来决定如何投递数据包
如果数据包不能直接投递给目标主机,那么ip协议就为他寻找下一个合适的下一跳路由器
路由器工作在网络层
-
ICMP协议(Internet Control Management Protocol)**
英特网控制管理协议,ping检测网络就是用这个协议
用于在IP主机、路由器之间传递控制消息
-
IGMP协议(Internet Group Management Protocol)**
英特网分组管理协议,组播,广播。
1.2.3.3 传输层
负责提供应用程序之间通讯服务,这种服务又称之为端到端。
传输层与网络层不同,传输层只关心通讯的 起始端 和 目的端,并不在乎数据包的传输中转过程。
TCP:(transmit contort Protocol 传输控制协议):提供面向连接的,一对一的可靠数据传输协议。
UDP:(user datagram Protocol 用户数据报协议):提供无连接的,不可靠的尽力的传输协议,但是效率更高
1.2.3.4 应用层
负责处理应用程序的逻辑
-
HTTP/HTTPS
超文本传输协议,万维网数据通信的基础
http:明文发送, https加密传输
-
邮件协议
收:POP3(post office protocol)邮局协议第三个版本
从服务器接收右键,接收完后服务器就没有这个邮件了;
发:SMTP(简单邮件传输协议)
IMAP:交互式邮件存储协议,与POP3类似的邮件访问标准协议之一。
收取邮件后,服务器上邮件依然存在,如果删除、标记服务器也会做相应操作。
- FTP(FILE Transfer Protocol)
文件传输协议,是用于在网络上进行文件传输的一套标准协议,使用TCP传输
- TFTP
简单文件传输协议,适用于在网络上进行文件传输的一套标准协议,使用UDP传输
- DNS:域名解析
Telnet/ssh :远程登录
1.2.4 网络封包与拆包
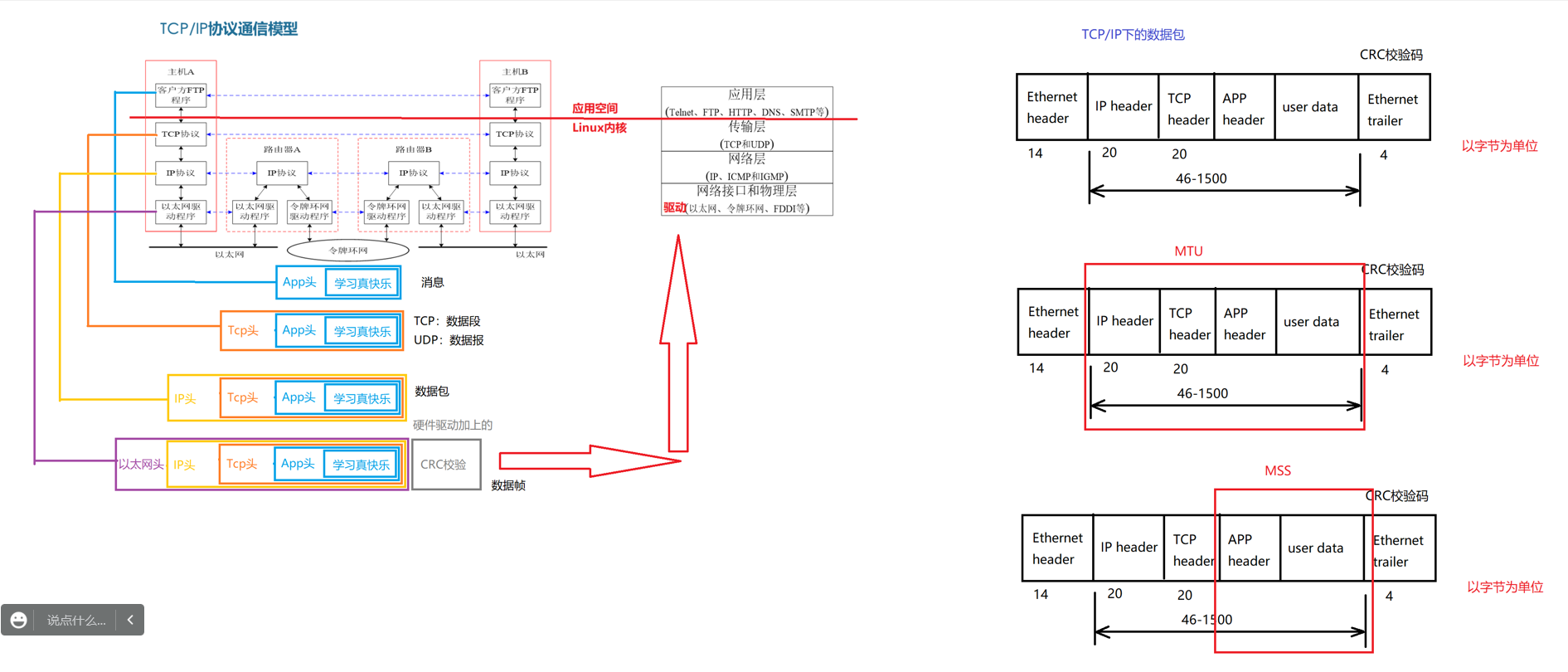
MTU :
Maximum Transmit Unit 最大传输单元
物理接口(数据链路层)提供给上层(网络层(IP层))最大一次传输数据的大小。
规定了数据链路层所能传送最大数据长度
以太网为例,缺省MTU=1500字节,这是以太网接口对IP层的约束
如果IP层<=1500字节需要发送,只需要一个IP包就可以
如果IP层>1500字节需要发送,需要分片才能发送(分片:帧)
限制数据包大小的协议是什么协议:MTU MSS
MSS:
Maximum Segment Size 最大报文长度
TCP提交给IP层最大分段大小,指TCP报文所允许传送数据部分最大长度。
不包含TCP头,MSS式TCP来限制应用层最大发送字节数。
如果MTU=1500,则MSS = 1500-20(IP header)-20(TCP header) =1460字节
如果应用有2000字节要发,需要2 Segment
第一个TCP Segment = 1460 第二个TCP Segment = 540
1.3 TCP和UDP的异同点(重点!!!)
共同点:同属于传输层协议。
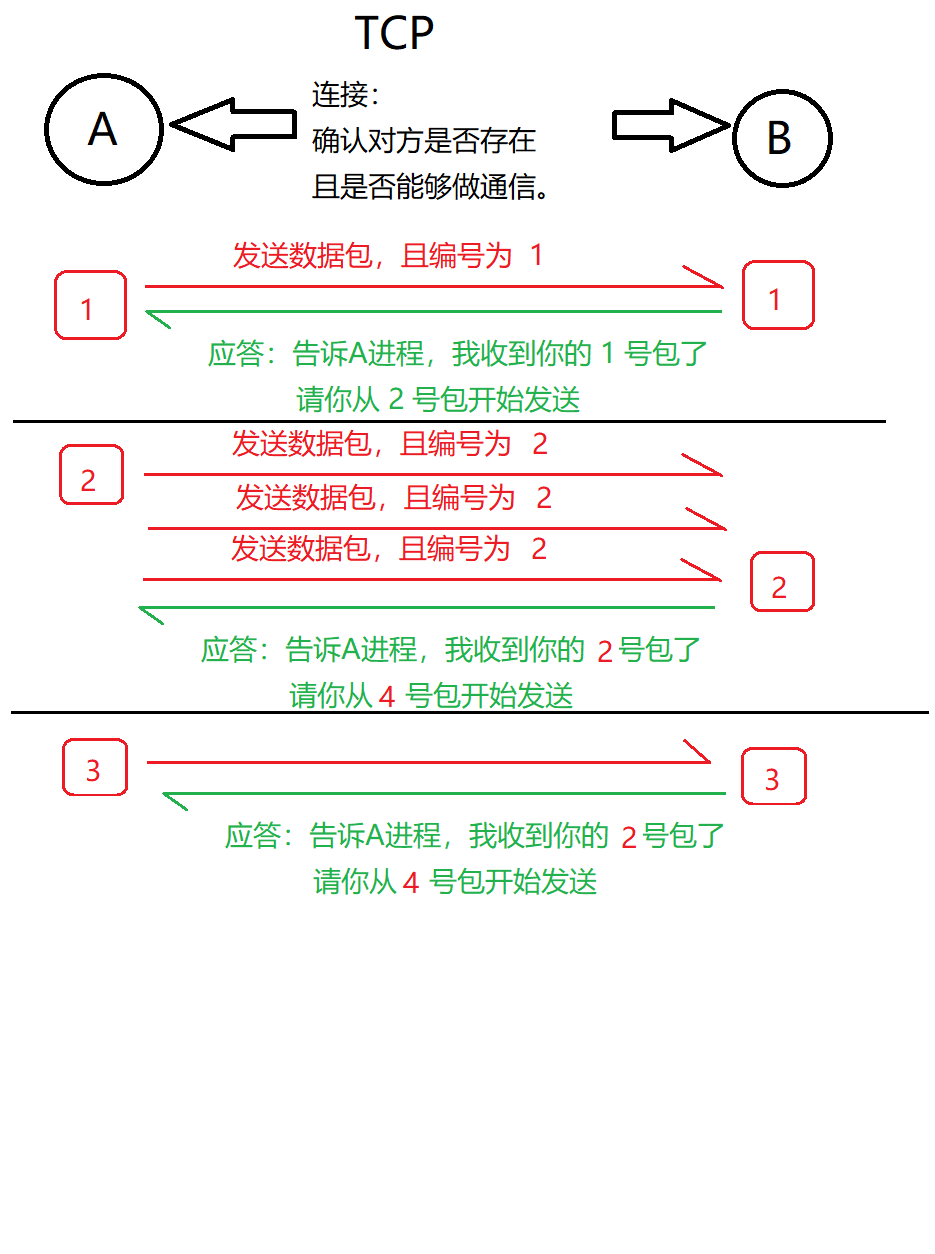
1.3.1 TCP — 稳定
-
提供面向连接的,可靠的数据传输服务;
-
传输过程中,数据无误,数据无丢失,数据无失序,数据无重复到达。
-
- TCP会给每个数据包编上编号,该编号称之为序列号
- 每个序列号都需要应答包应答,如果没有应答,则会将上面的包,重复发送直到正确为止。
-
传输效率低,耗费资源多。
-
数据的收发是不同步的.
-
- 为了提高效率,TCP会将多个比较小,且发送间隔短的数据包,沾成一个包发送,该现象称之为粘包现象。
- 该粘包算法称之为Nagle算法。
TCP的适用场景:对传输质量比较高的,以及传输大量数据的通信。在需要可靠通信的传输场合,一般使用TCP协议。
例如:账户登录,大型文件下载的时候,
13.2 UDP — 快速
- 无连接的,不保证数据可靠的,尽力的传输协议。
- 数据有可能在传输过程中丢失,或者出现数据重复,数据失序等情况。
- 传输效率高,实时性高。
- 限制每次传输的数据大小,多出部分直接忽略删除。
- 收发是同步的。不会粘包。
UDP的适用场景:发送小尺寸的,在接收到数据给出应答比较困难的环境下。
例如:广播,通讯软件的音视频。
1.4 IP地址
IP地址是因特网中主机的标识,每个数据包都必须携带目的IP地址和源IP地址,路由器依靠此信息为数据包选择路由。
1.4.1 IP地址的分类
-
IPv4:采用4个字节的无符号整数存储,32bit。[0, 2^32-1] == >42.9亿多个
-
-
局域网:为了解决IP地址不够用的问题,让多台主机使用一个IP地址。
-
- LAN:local area network 局域网
- WAN:wide area network 广域网
-
-
IPv6:采用16个字节的无符号整数存储,128bit, IPv4不兼容IPv6。
1.4.2 IP地址划分
IP地址的二级划分:将32位IP地址分为两部分,为了寻径更加有效。
IP = 网络号 + 主机号
网络号:确定计算机从属的网络,
主机号:标识设备在该网络中的主机编号。

ABC类为基本类,可以分配给主机使用。
D类不表示网络,用于组播,多播组
E类保留或实验室使用。
练习:
下列哪些IP地址可以分配给主机使用___AB___
A. 223.1.2.3 B. 192.1.2.3 C.224.1.2.3 D. 225.1.2.3
1.4.3 点分十进制
为了方便记忆,使用点分十进制。
将32位IP地址的二进制数,以8bit为一组,用十进制表示,利用点分割。
| A类地址 | 0.0.0.0~127.255.255.255 | 2^7(网络号) | 2^24(主机号) | 大型网络 |
|---|---|---|---|---|
| B类地址 | 128.0.0.0~191.255.255.255 | 2^14 | 2^16 | 名地址网管中心 |
| C类地址 | 192.0.0.0~223.255.255.255 | 2^21 | 2^8 | 校园网或企业网、家庭网 |
| D类地址 | 224.0.0.0~239.255.255.255 | 组播地址 | ||
| E类地址 | 240.0.0.0~255.255.255.255 | 保留 |
特殊的IP地址:不能分配给主机使用,掐头去尾
-
网络地址:有效网络号 + 全是0的主机号, 代表该网络
-
- 192.168.8.234 —》 192.168.8.0
-
广播地址:有效网络号 + 全是1的主机号,向该IP地址发送数据,代表向该网络下的所有主机发送
-
- 192.168.8.234 —》 192.168.8.255
练习:
- 现有IP: 130.1.2.3,请计算其网络地址:130.1.0.0 ,请计算其广播地址:130.1.255.255
- 现有IP: 130.1.2.3,在该网络下,请问主机号有几个:2^16。
- 现有IP: 130.1.2.3,在该网络下,请问可分配给主机使用的IP地址有几个:2^16 - 2 。 掐头去尾
1.4.4 子网掩码(重点!)
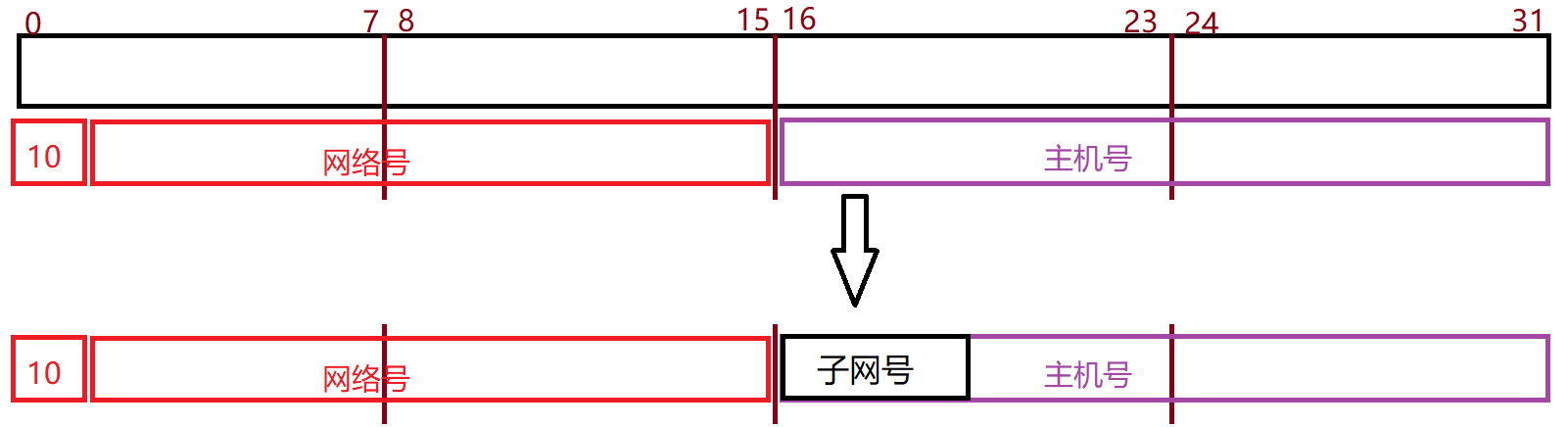
由于二级IP地址主机的基数还是比较大,所以引入了另外一个概念,子网掩码。
子网掩码可以将二级IP地址划分成三级IP地址。
IP = 网络号 + 子网号 + 主机号
子网号比二级划分更加灵活,用户可以自行设置,可以选择划分,也可以选择不划分。
子网掩码:用来划分IP地址中,哪一部分是网络号,哪一部分是子网号,哪一部分是主机号的。
1.4.4.1 子网掩码的格式
- 与IP地址一样长的32位整数,由一串连续的1,后面跟着一串连续的0组成。
- 默认子网掩码中,1的个数与IP地址中网络号的个数一致。0的个数与IP地址中主机号的个数一致。
A类IP地址的默认子网掩码: 11111111 00000000 00000000 00000000 ==》255.0.0.0
B类IP地址的默认子网掩码: 11111111 11111111 00000000 00000000 ==》255.255.0.0
C类IP地址的默认子网掩码: 11111111 11111111 11111111 00000000 ==》255.255.255.0
注意:D类E类IP地址无子网掩码:
C类IP地址的默认子网掩码: 11111111 11111111 11111111 00000000 ==》255.255.255.0
11111111 11111111 11111111 10000000 ==》255.255.255.128
11111111 11111111 11111111 11000000 ==》255.255.255.192
11111111 11111111 11111111 11100000 ==》255.255.255.224
11111111 11111111 11111111 00000011 ==》255.255.255.3 错误的1不连续
1.4.4.2 子网掩码的使用
IP地址 & 子网掩码 == 子网网段
192.168.8.234 & 255.255.255.0
11000000 10101000 00001000 11101010
11111111 11111111 11111111 00000000
_______________________________________
11000000 10101000 00001000 00000000 ====》 192.168.8.0 子网网段
192.168.8网络号,主机号的范围为[0,255]。该主机号范围内的所有IP与255.255.255.0计算后,得出来的结果均为192.168.8.0。
所以[0, 255]这个主机范围内的IP地址均从属于192.168.8.0子网,即没有划分出多个子网。
192.168.8.0子网网段与源IP地址,后面8bit被0遮掩了,因为我们在计算子网网段的时候,不关心后面8bit的主机号是什么。
192.168.8.0就是所谓的子网网段,234就是该子网网段中的其中一个主机号。
该子网网段还可以写作:192.168.8.0/24(子网掩码中有24个1);
192.168.8.234 & 255.255.255.128
11000000 10101000 00001000 1 1101010
11111111 11111111 11111111 1 0000000
_______________________________________
11000000 10101000 00001000 1 0000000 ====》 192.168.8.128 子网网段
IP地址范围:为如下范围的IP地址,& 255.255.255.128,得到的结果均为192.168.8.128 子网网段
11000000 10101000 00001000 1 0000000 ---》192.168.8.128
11000000 10101000 00001000 1 1111111 ---》192.168.8.255
所以192.168.8.234该IP地址从属于,192.168.8.128/25的这个子网网段。
___________________________________________________________________________________
192.168.8.7 & 255.255.255.128
11000000 10101000 00001000 0 0000111
11111111 11111111 11111111 1 0000000
_______________________________________
11000000 10101000 00001000 0 0000000 ====》 192.168.8.0 子网网段
IP地址范围:为如下范围的IP地址,& 255.255.255.128,得到的结果均为192.168.8.0 子网网段
11000000 10101000 00001000 0 0000000 ---》192.168.8.0
11000000 10101000 00001000 0 1111111 ---》192.168.8.127
所以192.168.8.7,该IP地址从属于,192.168.8.0/25的这个子网网段。
该255.255.255.128 子网掩码划分出了两个子网网段,每个子网网段中主机号的个数为128 == 2^7
注意:
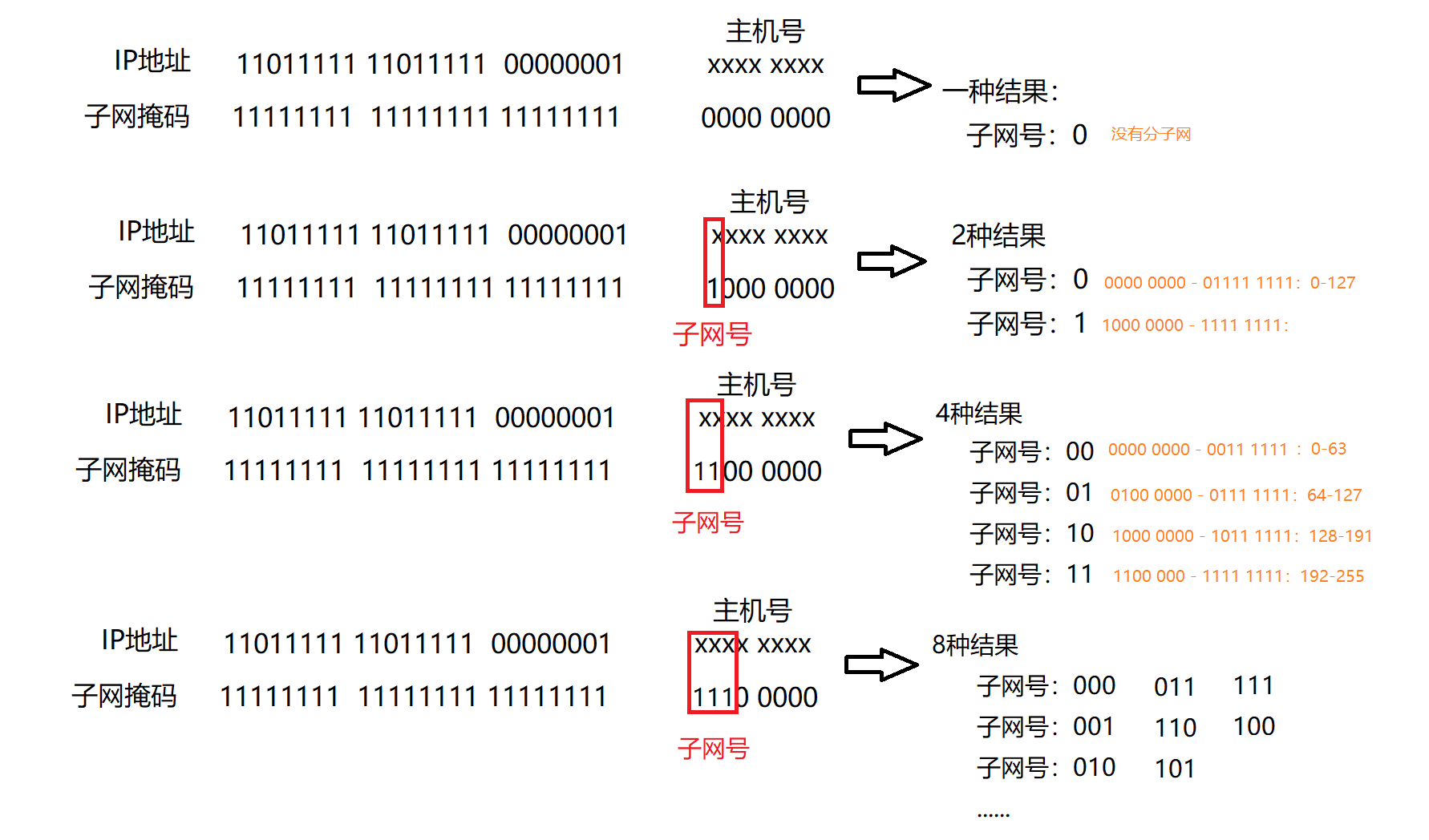
子网网段的个数 = 2^ (子网号中1的个数)
每个子网网段中主机号的个数 = 2^ (子网掩码中0的个数)
- 默认子网掩码分别是什么
- 已知120.1.2.3,想要将该IP地址所属网络划分出4个子网网段,子网掩码:255.192.0.0,每个子网网段主机号__222___,每个网段**可用**主机号是___222-2___,
- 给定子网掩码255.255.255.224,问该子网掩码在192.168.8.0的网络上能划分出_23=8_个子网,每个子网主机号___25=32__个
特殊的IP地址:
- 每个子网网段中,都有自己的子网网段地址。有效网络号+有效子网号+全是0的主机号 。 掐头
- 每个子网网段中,都有自己的子网广播地址。 去尾
练习
某个公司有4 部门:行政 研发 售后 营销,每个部门20台电脑接入公司局域网交换机。
如果在192.168.1.0网段划分每个部分的子网,写出所有可用的子网掩码?子网的地址范围是什么?
- 所以至少划分出4个子网网段:255.255.255. 1100 0000 --》 255.255.255.192 每个子网网段中,主机号的个数为:64个
- 划分出8个子网网段:255.255.255. 1110 0000 --》 255.255.255.224 每个子网网段中,主机号的个数为:32个
192.168.1.2~192.168.1.62 192.168.1.0/26
192.168.1.65~192.168.1.126 192.168.1.64/26
192.168.1.129~192.168.1.190 192.168.1.128/26
192.168.1.193~192.168.1.254 192.168.1.192/26
1.5 网关
网关是一个网络通向其他网络的IP地址
目前家用路由器一般使用192.168.1.1和192.168.0.1作为LAN接口的地址,这个两个也是最常用的网关地址。
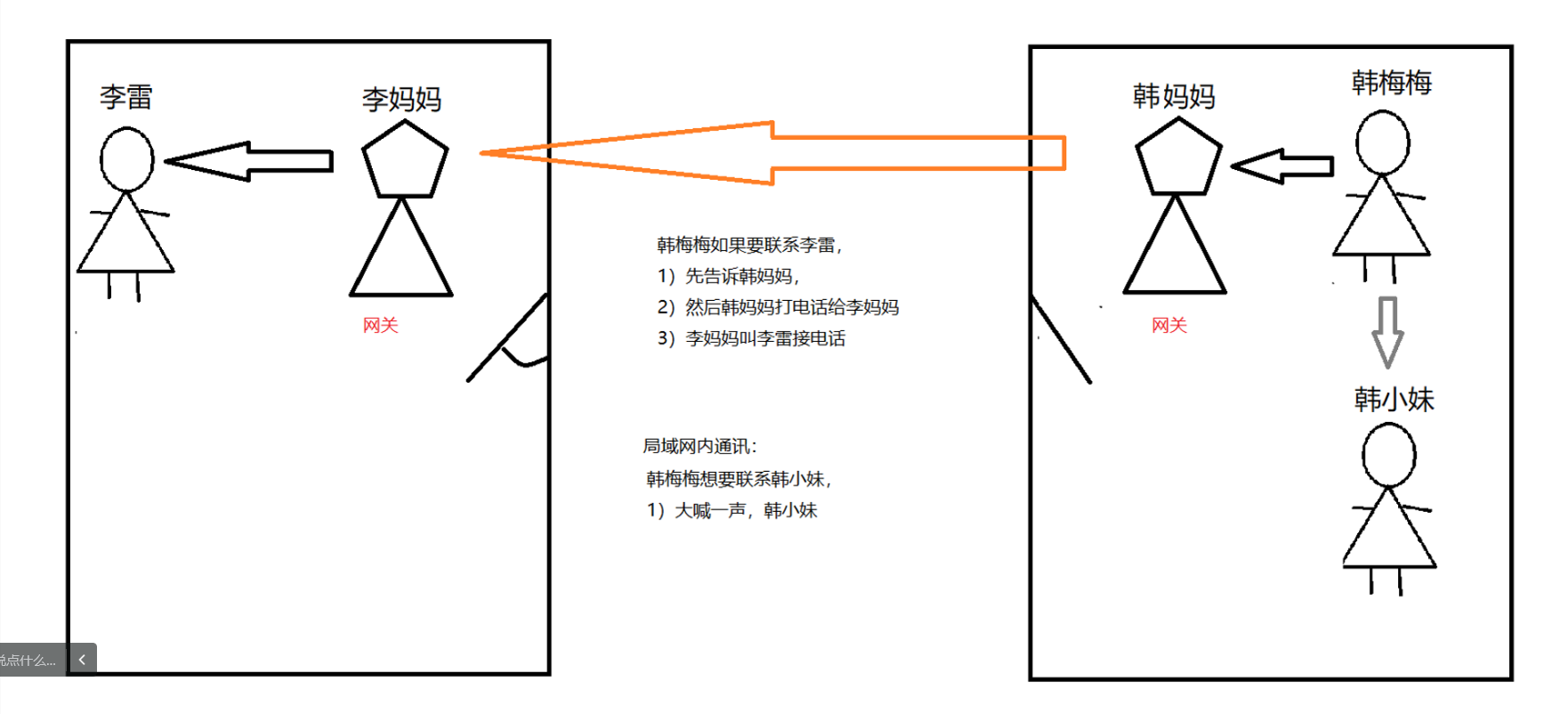
1.6 域名系统
由于使用IP地址来指定计算机不方便人们记忆,且输入时候容易出错,用字符标识网络种计算机名称方法。
这种命名方法就像每个人的名字,这就是域名(Domian Name)
域名服务器(Domain Name server):用来处理IP地址和域名之间的转换。
域名系统(Domain Name System,DNS):域名翻译成IP地址的软件
一个域名,可以绑定多个ip
域名结构:
例如域名 www.baidu.com.cn 从右向左看
cn为高级域名,也叫一级域名,它通常分配给主干节点,取值为国家名,cn代表中国
com为网络名,属于二级域名,它通常表示组织或部门
中国互联网二级域名共40个,edu表示教育部门,com表示商业部门,gov表示政府,军队mil等等
baidu为机构名,在此为三级域名,表示百度
www:万维网world wide web,也叫环球信息网,是一种特殊的信息结构框架。
1.7 端口号
为了区分一台主机收到的数据包交给哪个进程处理,使用端口号来区分。程序启动后将端口号和进程绑定在一起。
网络里面的通讯是由 IP地址+端口号 来决定
端口号存储在 2个字节 无符号整数中 (short int)。[1, 65535]
众所周知的端口号:
1~1023端口我们编程时候不要使用,是那些”VIP“应用程序占了
TCP 21端口:FTP文件传输服务
TCP 23端口:TELNET终端仿真服务
TCP 25端口:SMTP简单邮件传输服务
TCP 110端口:POP3邮局协议版本3
TCP 80端口:HTTP超文本传输服务
TCP 443端口:HTTPS加密超文本传输服务
UDP 53端口:DNS域名解析服务
UDP 69端口:TFTP文件传输服务
TCP和UDP的端口号是相互独立的
可以使用的:1024~49151,就是我们平时编写服务器使用的端口号
临时端口号:49152~65535,这部分是客户端运行时候动态选择的
二. 跨主机传输
1. 字节序(重点)
1.1 字节序的概念
- 字节序是指不同类型的cpu主机,内存存储 “多字节整数” 序列的方式
- 浮点类型,字符类型,字符串没有字节序。
- 小端字节序:低序字节存储在低地址上
- 大端字节序:低序字节存储在高地址上
注意:数据的读取顺序都是从低地址往高地址读取,通过大小端转换得到结果
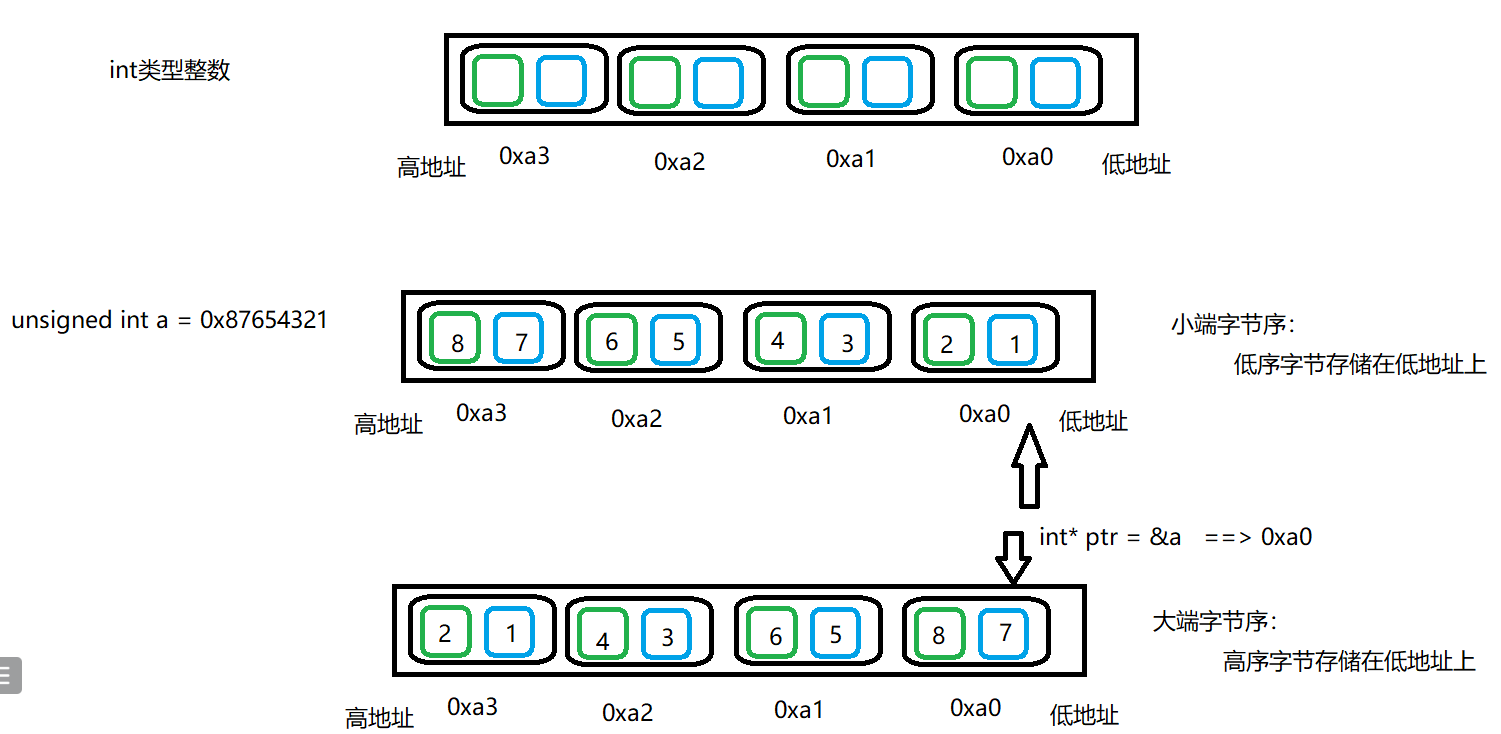
练习
请简述字节序的概念,并用联合体(共用体)的方式验证计算机是大端还是小端?
#include <stdio.h>
union node
{
unsigned int a;
char b;
};
int main(int argc, const char *argv[])
{
unsigned int a = 0x87654321;
char* ptr = (char*)&a;
if(0x21 == *ptr)
{
printf("little endian\n");
}
else if(0x87 == *ptr)
{
printf("big endian\n");
}
union node t;
t.a = 1;
if(1 == t.b)
{
printf("little endian\n");
}
else
{
printf("big endian\n");
}
return 0;
}
1.2 本地字节序与网络字节序
本地字节数:主机字节序(Host Byte Order) HBO
网络字节序(Network Byte Order) NBO,网络字节序规定使用大端字节序
在跨主机传输过程中,需要使用统一的字节序,即网络字节序,避免兼容性问题
1.3字节序转换函数
1.3.1 htons htonl 主机字节序–>网络字节序**
头文件:
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
参数:
- 要转换成网络字节序的整型:分别是32bit和16bit;
返回值:
- 成功,返回转换后网络字节序的整型
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, const char *argv[])
{
unsigned int a = 0x87654321;
printf("%#x\n", a); //0x87654321
printf("%#x\n", htonl(a)); //0x21436587
printf("%#x\n", htons(a)); //0x2143
return 0;
}
1.3.2 ntohs ntohl 网络字节序---->主机字节序
头文件:
#include <arpa/inet.h>
原型:
-
uint32_t ntohl(uint32_t netlong);
-
uint16_t ntohs(uint16_t netshort);
参数:
- uint32_t hostlong:32位网络字节序整型;
- uint16_t hostshort:16位网络字节序整型;
返回值:
- 成功,返回转换成主机字节序的整型;
1.4 结构体对齐
编译器会对结构体进行对齐,加速CPU取值周期,由于数据对齐也是与操作系统相关,不同的主机如果使用不同的对齐方式,会导致数据无法解析。
所以网络传输结构体的时候需要取消结构体对齐;
#include <stdio.h>
#pragma pack(1) //设置默认对齐系数 :()中的参数只能填2^n (n=0,1,2,3,4,5......)
typedef struct
{
char a; //1
int b; //4
int d; //4
}_A;
#pragma pack() //重置默认对其系数,重新置为8
typedef struct
{
char a; //1
int b; //4
int d; //4
} __attribute__((packed)) B; //取消结构体对齐
typedef struct
{
char a; //1
//3
int b; //4
int d; //4
}_C;
int main(int argc, const char *argv[])
{
printf("%ld\n", sizeof(_A)); //9
printf("%ld\n", sizeof(_B)); //9
printf("%ld\n", sizeof(_C)); //12
return 0;
}
1.5 类型长度
int long int不同操作系统这两个数据类型所占的字节数可能是不一样的
解决方式:可以通过通用类型:uint8_t uint16_t uint32_t
因为涉及到跨平台,不同平台会有不同的字长
#include <stdint.h>
typedef struct
{
uint8_t a; //1
uint32_t b; //4
uint16_t d; //2
}_A;
2. IP转换
由于IP地址本质上是一个4个字节的整数,所以在跨主机传输中也有字节序的概念。
所以需要将IP地址转换成网络字节序。
“192.168.8.189” ---->本机字节序的整型 0xC0A808BD---->网络字节序0xBD08A8C0
2.1点分十进制—>网络字节序
2.1.1 inet_aton
头文件:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
原型:
- int inet_aton(const char *cp, struct in_addr *inp);
参数:
-
char *cp:源IP地址的点分十进制字符串,例如 “192.168.1.10”;
-
struct in_addr *inp:存储转换成网络字节序的IP;
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
返回值:
-
成功,返回非0;
-
失败,返回0;
注意:只能转换IPv4
例子:
#define IP "192.168.1.10" //0xC0A8010A
int main(int argc, const char *argv[])
{
struct in_addr inp;
if(inet_aton(IP, &inp) == 0)
{
printf("转换失败\n");
return -1;
}
printf("%#X\n", inp.s_addr); //0X0A01A8C0
return 0;
}
2.1.2inet_pton
既可以转IPv4也能处理IPv6
头文件:
#include <arpa/inet.h>
原型:
- int inet_pton(int af, const char *src, void *dst);
参数:
-
int af:协议族
AF_INET IPV4
AF_INET6 IPV6 -
char *src:指定要转换成网络字节序的点分十进制字符串;
-
void* dst
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
af == AF_INETa;
struct in6_addr
{
}
返回值:
- 成功,返回1;
- 失败,返回0或者-1,更新errno;
#define IP "192.168.1.3" //0xC0A80103 --> 0x301A8C0*
struct in_addr inp;
inet_pton(AF_INET, IP, &inp);
printf("%#X\n", inp.s_addr); //0x301A8C0
2.1.3inet_addr 最常用
头文件:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
原型:
- uint32_t inet_addr(const char *cp);
参数:
- char *cp:源IP地址的 点分十进制字符串,例如 “192.168.1.10”;
返回值:
- 成功,返回转换后的网络字节序IP地址;
typedef uint32_t in_addr_t; - 失败,返回INADDR_NONE (usually -1);
只能转换IPv4;
例子:
printf("%#X\n", inet_addr(IP));
2.2 网络字节序—>点分十进制
2.2.1 inet_ntoa 常用
头文件:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
原型:
- char *inet_ntoa(struct in_addr in);
参数:
struct in_addr in:指定要转换成点分十进制字符串的IP地址;
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
返回值:
- 成功,返回点分十进制字符串的首地址;
只能转换IPv4;
printf("%s\n", inet_ntoa(inp));
2.2.2 inet_ntop
头文件:
#include <arpa/inet.h>
原型:
- const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);
参数:
int af:协议族
AF_INET IPV4
AF_INET6 IPV6
void* src:存储要转换成点分十进制字符串的IP首地址;
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
af == AF_INETa;
struct in6_addr
{
}
char *dst:存储转换后的结果,点分十进制的首地址;
socklen_t size:缓冲区大小,其实就是指定多大的空间用于转换IP;
返回值:
- 成功,返回字符串的首地址,就是dst;
- 失败,返回NULL,更新errno;
例子:
char ip[20];
if(inet_ntop(AF_INET, &inp, ip, sizeof(ip)) == NULL)
{
perror("ient_ntop");
return -1;
}
printf("%s\n", ip);
**返回值:**
- 成功,返回点分十进制字符串的首地址;
**只能转换IPv4;**
printf(“%s\n”, inet_ntoa(inp));
#### 2.2.2 inet_ntop
**头文件:**
#include <arpa/inet.h>
**原型:**
- const char \*inet_ntop(int af, const void \*src, char \*dst, socklen_t size);
**参数:**
```c
int af:协议族
AF_INET IPV4
AF_INET6 IPV6
void* src:存储要转换成点分十进制字符串的IP首地址;
typedef uint32_t in_addr_t;
struct in_addr {
in_addr_t s_addr;
};
af == AF_INETa;
struct in6_addr
{
}
char *dst:存储转换后的结果,点分十进制的首地址;
socklen_t size:缓冲区大小,其实就是指定多大的空间用于转换IP;
返回值:
- 成功,返回字符串的首地址,就是dst;
- 失败,返回NULL,更新errno;
例子:
char ip[20];
if(inet_ntop(AF_INET, &inp, ip, sizeof(ip)) == NULL)
{
perror("ient_ntop");
return -1;
}
printf("%s\n", ip);