单节点模式(Standalone,不推荐用于生产环境)
standalone模式即单节点模式,指在服务器上只部署一个 mongod 进程用于读写数据。优点是部署简单,可以快速完成部署,缺点是无容灾。只推荐用于日常的开发、测试和学习。
主从复制模式(官方已不建议使用,不推荐用于生产环境)
主从复制模式也比较简单,包含一个主节点(Primary)和一个或多个从节点(Secondary)。主节点提供读写服务,从节点不提供任何服务。也可以修改配置让从节点提供只读服务,以减少主节点的压力,每个从节点会定期轮询主节点的oplog以保持数据与主节点一致。
这种模式相较于单节点模式,可用性高很多,可用于备份、故障恢复、读扩展等。缺点是当主节点出现故障时,只能人工介入指定新的主节点(从节点不会自动升级为主节点),并且在这段时间内,集群处于只读状态。
副本集模式(Relica Set)
副本集模式包含一个主节点(Primary)和一个或多个从节点(Secondary),这一点与主从复制模式类似且主从节点的作用也类似。相较于主从复制模式,副本集模式的优势是当主节点发生故障时,副本集可以自动投票产生新的主节点,并引导其余的从节点连接新的主节点。副本集架构如下图所示:
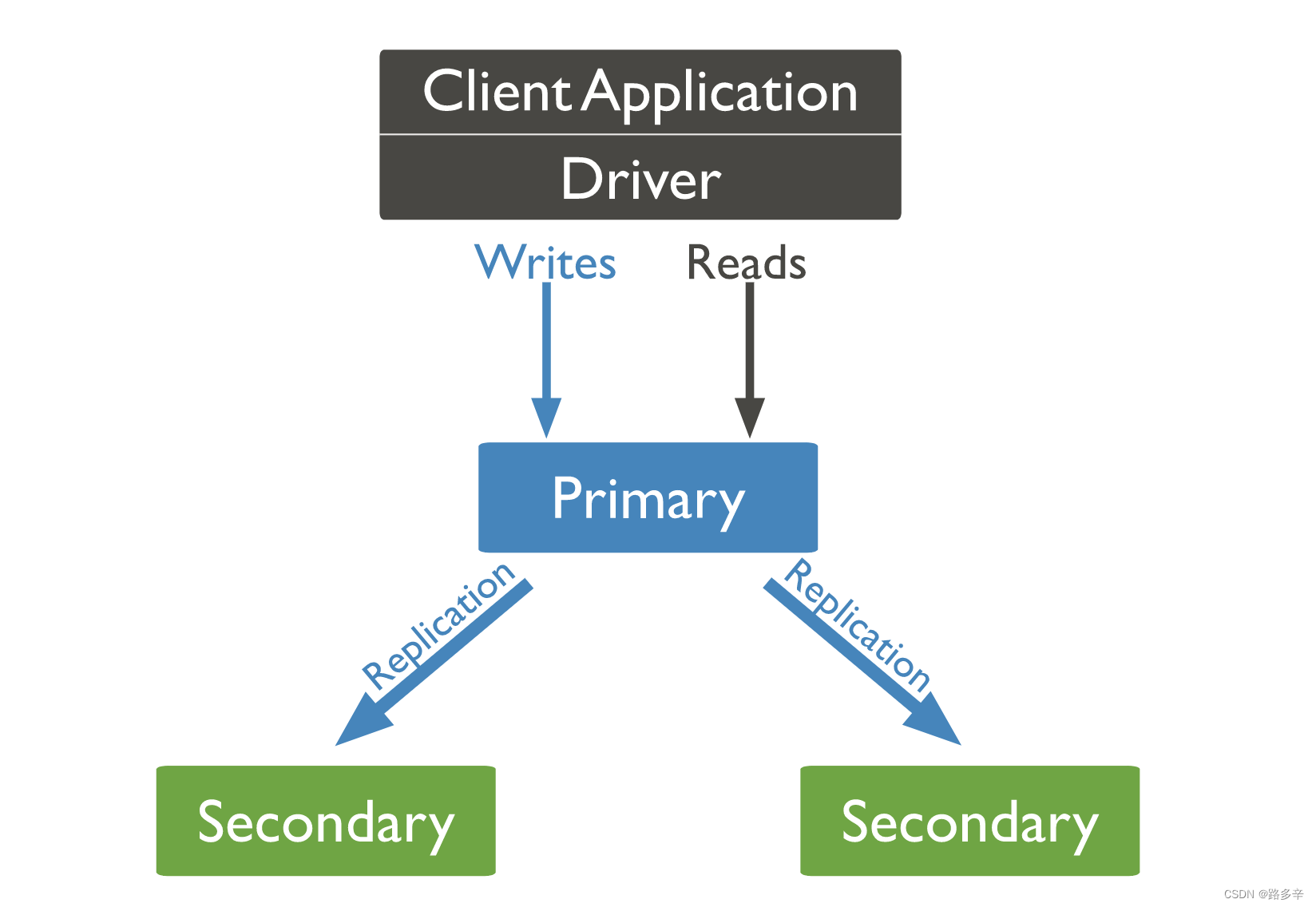
副本集中各节点通过心跳机制来检测各自的健康状况,当主节点出现故障时,多个从节点会触发选举操作来选举其中一个作为新的主节点。为了保证选举票数不同,副本集的节点数保持为奇数。
在某些情况下(例如只有一个主节点和一个从节点的情况下,由于成本限制不允许添加另一个从节点),可以选择向副本集中添加一个仲裁节点(Arbiter)。仲裁节点参与选举但不会被选为主节点(因为选举节点没有数据集的副本)。
分片集群模式(Sharded Cluster)
副本集模式虽然解决了高可用问题,但不能满足海量数据和需要非常高吞吐的场景。这时候就需要使用到分片技术(sharding,指将数据拆分并分散存储在不同机器上)了,即分片集群模式。
分片集群模式主要利用了水平扩展的特性,将数据和负载分散到多台机器上,并根据需要添加额外的服务器以增加容量和提高性能。虽然单台机器的整体性能或容量可能不高,但每台机器只是处理总体工作负载的一个单元,集群整体效率可能比单台性能和容量非常高的机器更高。
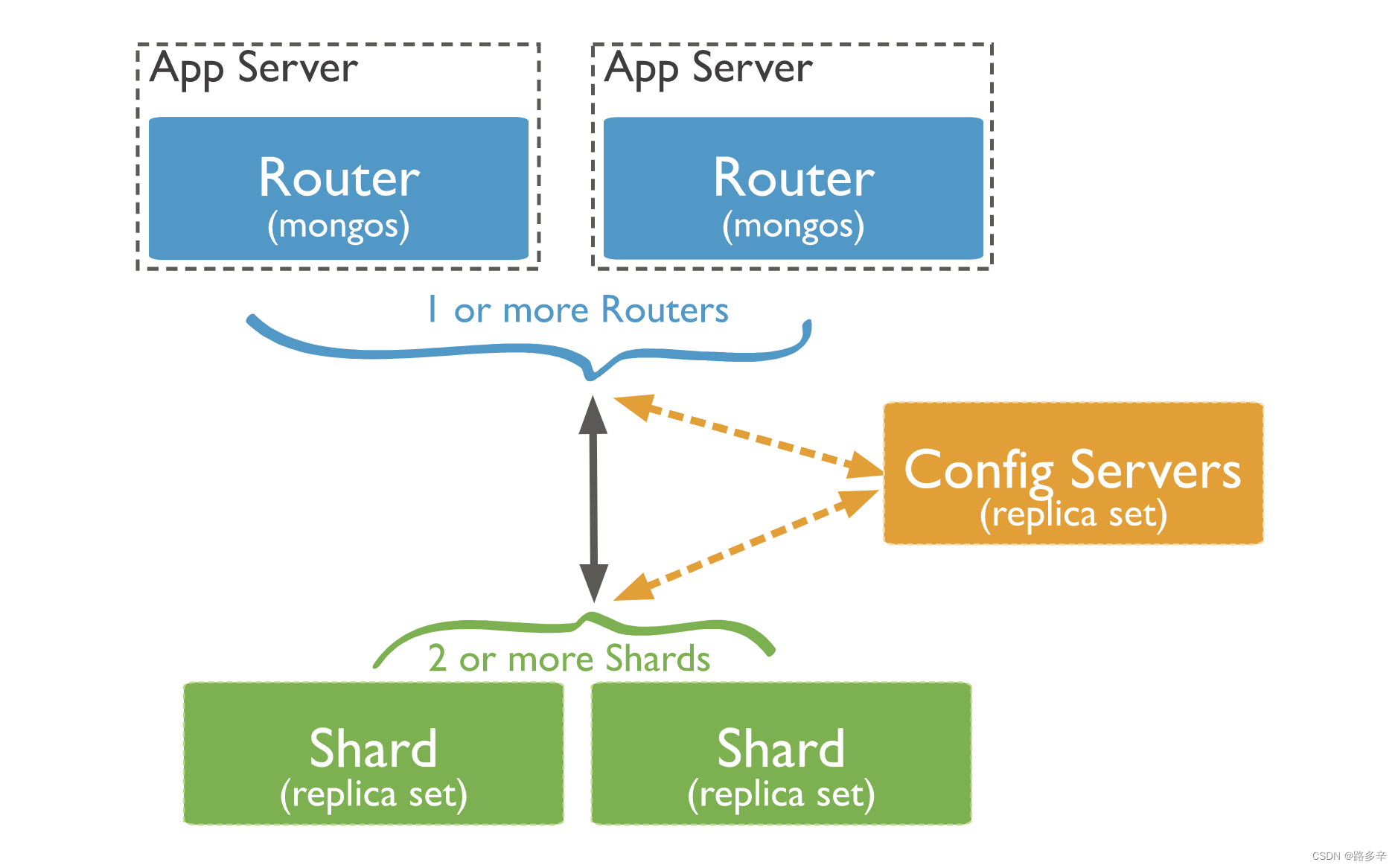
搭建一个分片集群需要如下几个组件:
- shard,每个shard都是一个mongo数据库实例,包含分片数据的一个子集。一个shard可由几台机器组成一个副本集,防止因主节点单点故障导致整个系统崩溃。
- config servers,用于配置服务器存储集群的元数据和配置设置。
- mongos,在集群中作为查询路由器,客户端程序由此接入,让整个集群看起来像是一个单一的数据库,提供客户端应用程序和分片集群之间的接口。mongos本身不保存数据,启动时从config servers加载集群信息到缓存中,并将客户端的请求路由给每个shard,聚合各shard返回的结果返回给客户端。
分片集群内组件间的交互如下图:
分片集群模式有以下几个优势:
- 将读写负载分布在集群中的各个分片上,允许每个分片处理集群操作的一个子集。通过添加更多的分片,读写工作负载都可以在集群中水平扩展。
- 将数据分布到集群中的各个分片上,允许每个分片包含整个集群数据的一个子集。随着数据集的增长,额外的分片会增加集群的存储容量。
- 高可用性,即使一个或多个分片副本集完全不可用,分片集群也可以继续执行部分读写。也就是说,虽然无法访问不可用分片上的数据,但对可用分片的读写仍然可以成功。
小结
本文介绍了MongoDB的四种部署模式:单节点模式和三种集群模式。副本集模式已经替代了主从复制模式,保障了集群的可靠性;分片集群模式的可扩展性,可以满足海量数据的存储和高吞吐的需求。生产环境中,不建议使用单实例模式和主从复制模式,副本集模式和分片集模式根据业务场景来选择。