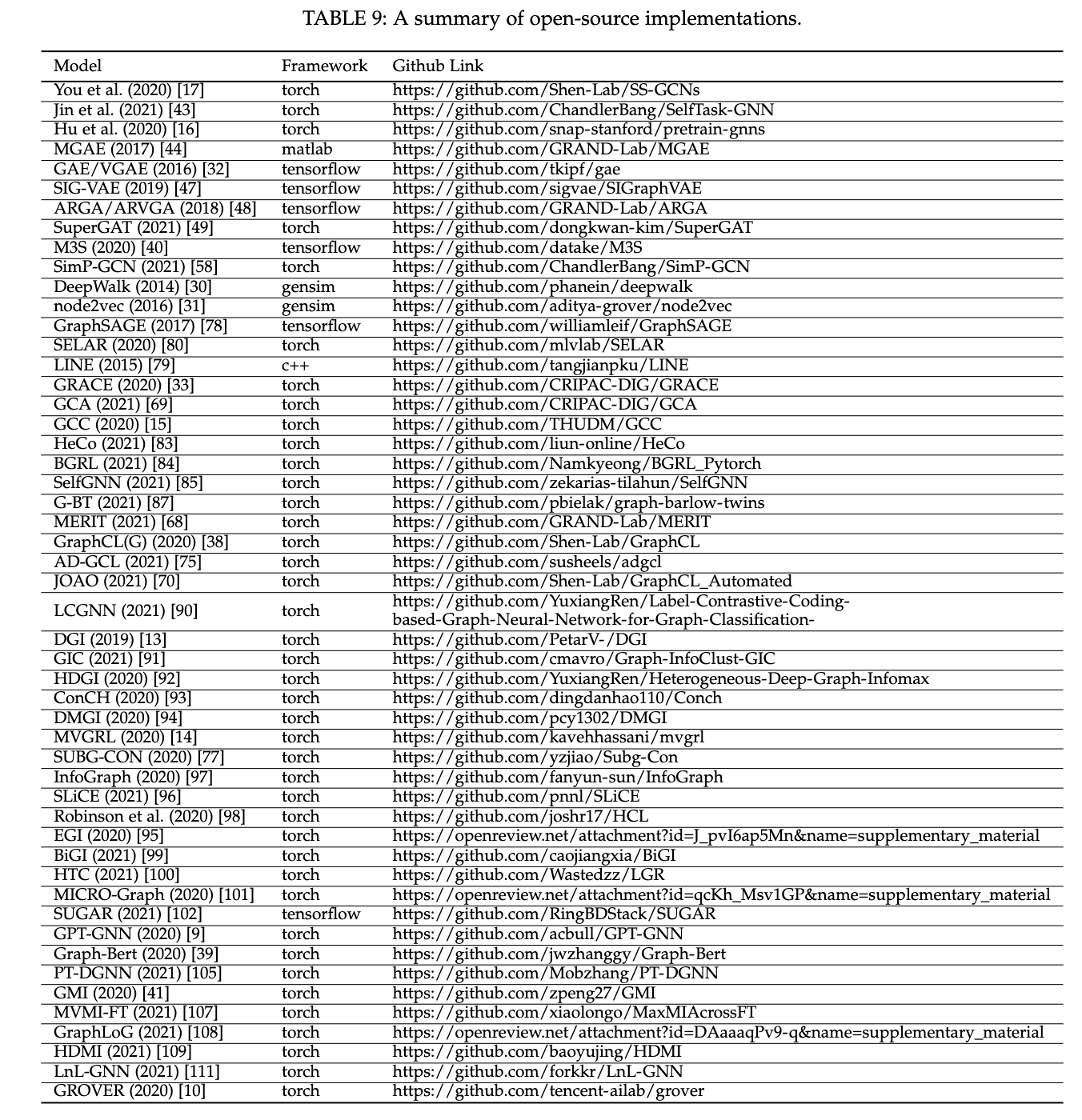
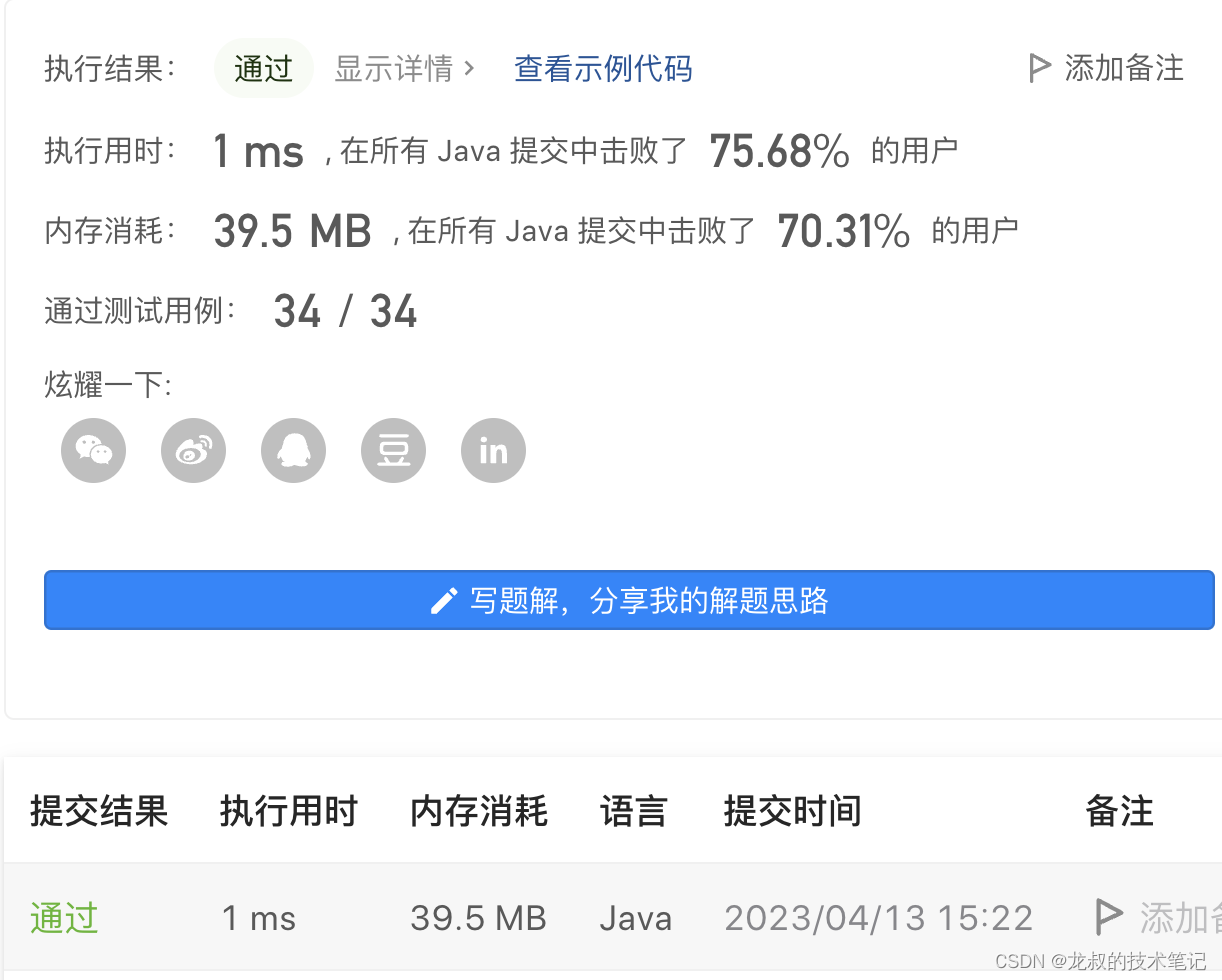
Hadoop 开启 histotryserver
Hadoop自带了一个历史服务,可以通过历史服务在web端查看已经运行完的Mapreduce作业记录,
默认情况下,Hadoop历史服务是没有启动的,需要自行启动。
启动后,在下图中点击history可跳转至历史服务查看信息。

配置历史服务器
配置文件mapred-site.xml
配置文件在hadoop文件夹下的etc/hadoop中。
在该配置文件中添加如下代码:
mapreduce.jobhistory.address 启动历史服务器的端口,
mapreduce.jobhistory.webapp.address 历史服务器web端的端口。
<configuration>
<property>
<name>mapreduce.jobhistory.address</name>
<value>spark01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>spark01:19888</value>
</property>
</configuration>
配置文件yarn-site.xml
配置文件在hadoop文件夹下的etc/hadoop中。
在该配置文件中添加如下代码:
yarn.log-aggregation-enable 是否开启日志聚集功能
yarn.log.server.url 日志聚集服务器地址
yarn.log-aggregation.retain-seconds 日志保留时间
</configuration>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://spark01:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
启动hadoop集群
start-all.sh
启动历史服务
在历史服务器执行以下命令
mr-jobhistory-daemon.sh start historyserver
或者
mapred --daemon start historyserver
mapred --daemon start historyserver
查看历史服务
jps

浏览器访问:http://spark01:19888

测试历史服务
上传一个测试任务,其中 /wordcount/input 中包含有一个txt文件,可以自行创建任意内容,输出到名为 /wordcount/result 的目录中。
hadoop.jar 为自己编写的 单词统计程序
hadoop jar hadoop.jar com.lihaozhe.mapreduce.wordcount.WordCountDriver
等待任务运行完成后,在浏览器查看运行情况: