原文标题:An effective self-supervised framework for learning expressive molecular global representations to drug discovery
代码:https://github.com/pyli0628/MPG.git
一、问题提出
(分子性质预测的背景都是老生常谈的)
药物发现是一个药物从发明到实际市场的漫长过程。同时,由于生物系统的复杂性和大量的实验,药物的发现很容易失败,并且固有的昂贵。为了解决这些问题,许多研究者在早期临床前研究的不同阶段提出了各种计算机辅助药物发现(CADD)方法,用于小分子药物设计,从命中识别和选择,命中先导优化,到临床候选药物。尽管传统的基于分子模拟技术的CADD方法在辅助药物发现方面取得了成功,但其计算成本高、过程耗时长,限制了其在制药工业中的应用。
人工智能与药物发现之间的跨学科研究因其卓越的速度和性能而受到越来越多的关注。许多AI技术已成功应用于药物发现的各种任务中,如分子性质预测、药物-药物相互作用(DDI)和药物-靶点相互作用(DTI)预测。
基本挑战是如何从分子结构中学习表达的信息
由于GNN的优越性能,一些研究者开始研究分子图数据的预训练策略。然而,由于分子图的拓扑结构多变,图数据往往比图像和文本数据更复杂,这给直接采用自监督学习方法的分子图带来了挑战。
受语言模型的启发,一些简单的自监督的大规模数据集预训练方法被提出,如Ngram, AttrMasking, ContextPredict和MotifPredict。然而,这些方法主要集中在节点级表示学习上,并没有显式地学习全局图级表示,导致在图级任务(如分子分类)中的收获有限。
二、模型方法
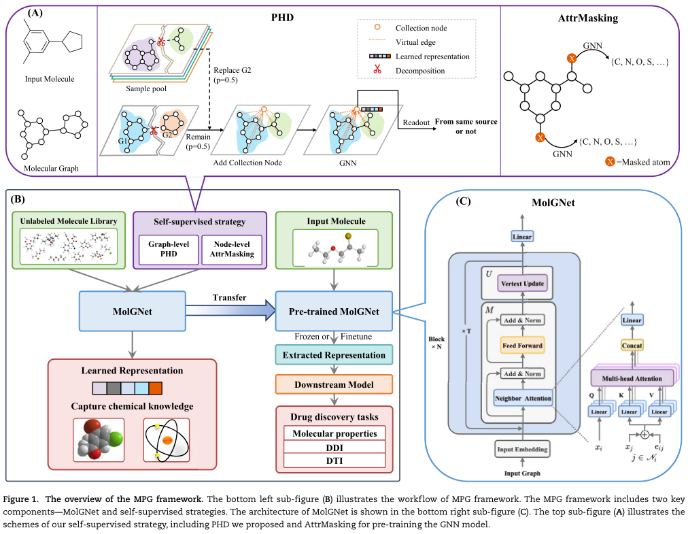
MolGNet是由n = 5个相同的层组成的堆栈;每个层循环执行T = 3次的共享消息传递操作,以支持更大的接收字段和更少的参数。
Self-supervised strategies
目前针对大规模分子图的预训练策略主要集中在节点级表示学习上。提出了一种自监督预训练策略,称为PHD,它明确地在图级预训练GNN。关键思想是学会比较两个半图(每个半图都是从一个图样本中分解出来的),并区分它们是否来自同一来源(二进制分类)。如果假设来自同一来源的两个半图可以组合成一个有效的分子,而来自不同来源的两个半图不能组合成一个有效的分子,PHD就是通过组合两个半图来识别分子的有效性,这可能会教会网络捕捉到一些分子的内在模式。如果假设来自同一来源的两个半图可以组合成一个有效的分子,而来自不同来源的两个半图不能组合成一个有效的分子,PHD就是通过组合两个半图来识别分子的有效性,这可能会教会网络捕捉到一些分子的内在模式。
1、MolGNet model
Neighbor attention module
原子、键集合为:
![]()
neighbor attention module将第i个原子的邻居节点j和对应的键eij相加,得到节点i的邻居信息:
![]()
在给定邻居信息和原子表示的情况下,该模块对所有原子执行scaled dot-product attention:
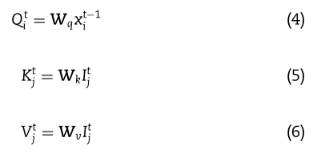

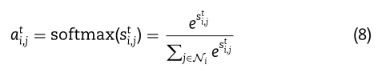
Ni表示i的邻居节点。利用归一化注意系数和邻居值Vj进行加权求和运算,得到每个节点的消息表示:
![]()
邻居注意模块也采用多头注意来稳定自我注意的学习过程,即K个独立注意机制对式(9)进行变换,然后将它们的特征进行串联,线性变换,得到如下输出表示:
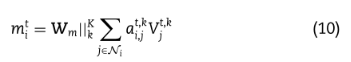
Feed-forward network
![]()
σ为GELU激活函数。实验中,维度dff是d的4倍,即3072 (d = 768)。
Vertex update function(GRU)

PHD strategy
PHD任务的设计目的是区分两个半图是否来自同一来源。如图1所示,首先将the图分解为两个半图,其中一个半图有0.5的可能性被另一个半图所取代,采用交叉熵函数:

Graph decomposition and negative sampling
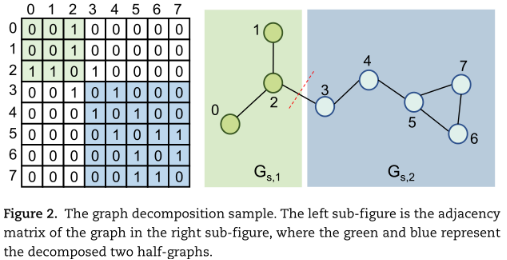
图表示为:G = (V, E),将其划分为Gs,1,Gs,2。G1结点有{v0, v1, v2}、G2结点有 {v3, v4, · · · , v7},这两个半图中的边分别对应邻接矩阵的左上子矩阵和右下子矩阵。为了得到大小均衡的半图,边界节点指数在节点总数的1/3 ~ 2/3范围内随机抽样。
对于负抽样,对数据集中的另一个图进行随机抽样,并使用上述方法将其分离为两个半图,将Gs,2替换为这两个半图中的一个,生成负抽样。负样本的生成方式对学习到的嵌入质量有很大的影响。它可以驱动模型来估计两个图是否可以组合成一个有效的图。通过这种方式,模型可以从节点和边中学习到图的有价值的图级特征,这些特征对下游任务至关重要。
Virtual collection node
半图对是两个互不关联的独立图。将这两个半图连接成一个完整的图,并引入一个虚拟集合节点,通过聚合每个节点的信息来获得全局图级表示。收集节点的特征可以掌握半图对的全局表示,并将其输入前馈神经网络进行最终预测。
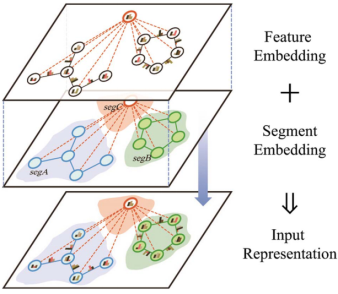
Input representation
由Feature embedding + Segment embedding组成。Feature embedding是一组节点特征和边缘特征经过embedding transformation得到,Segment embedding是对每个节点和每条边进行学习后的segment,表示它属于哪个半图,不同的颜色代表不同的分段。
三、实验
MoleculeNet:
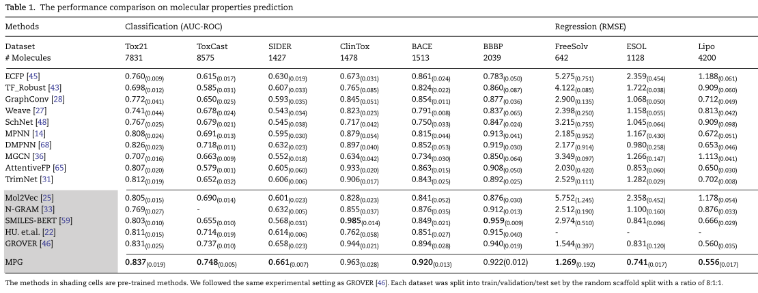
可视化:
1)区分是否具备区分度。从ZINC数据集中随机选择1000个分子,通过打乱原子特征来扰乱分子结构,生成无效分子。对于每个有效和无效的分子,我们从预训练的最后一层MolGNet中提取集合节点的嵌入作为分子表示。(这个应该是需要可区分的,因为大量预训练了)
得到有效分子和无效分子的表示形式后,通过UMAP在投影二维空间中可视化:
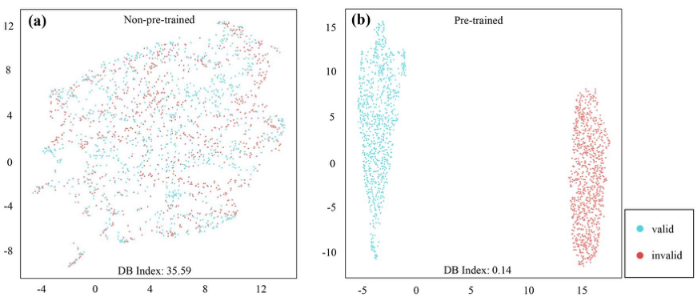
2)是否预训练。与未经过预训练的MolGNet相比,经过预训练的MolGNet显示出与这10个分子支架相对应的更有特色的簇。
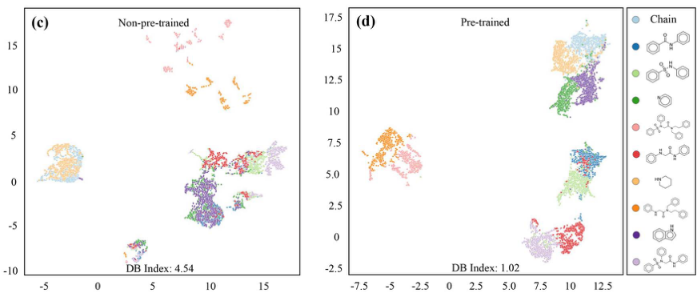
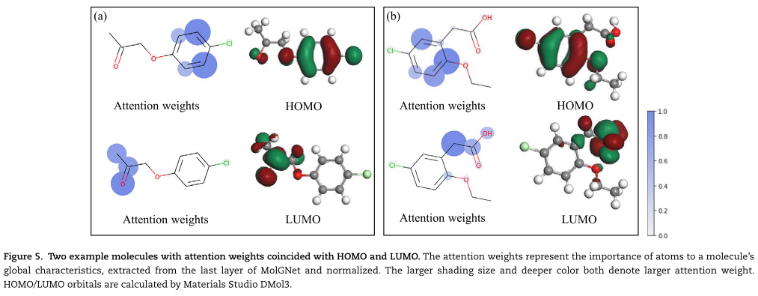
3)案例研究。以更细粒度的方式研究MPG的解释。用从预训练的MolGNet的最后一层获得的收集节点上的注意权值对所选分子的每个原子进行着色。注意力权重表示原子对全局特征的贡献。
MPG predicts the drug–drug interaction accurately and rationally

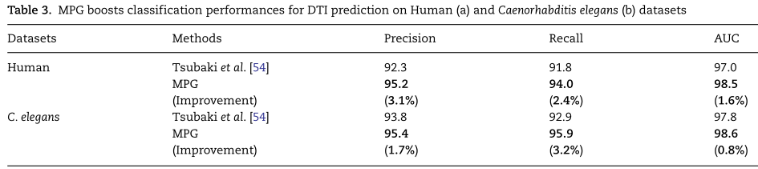
MPG boosts the performance of drug-target interaction prediction
Ablation studies