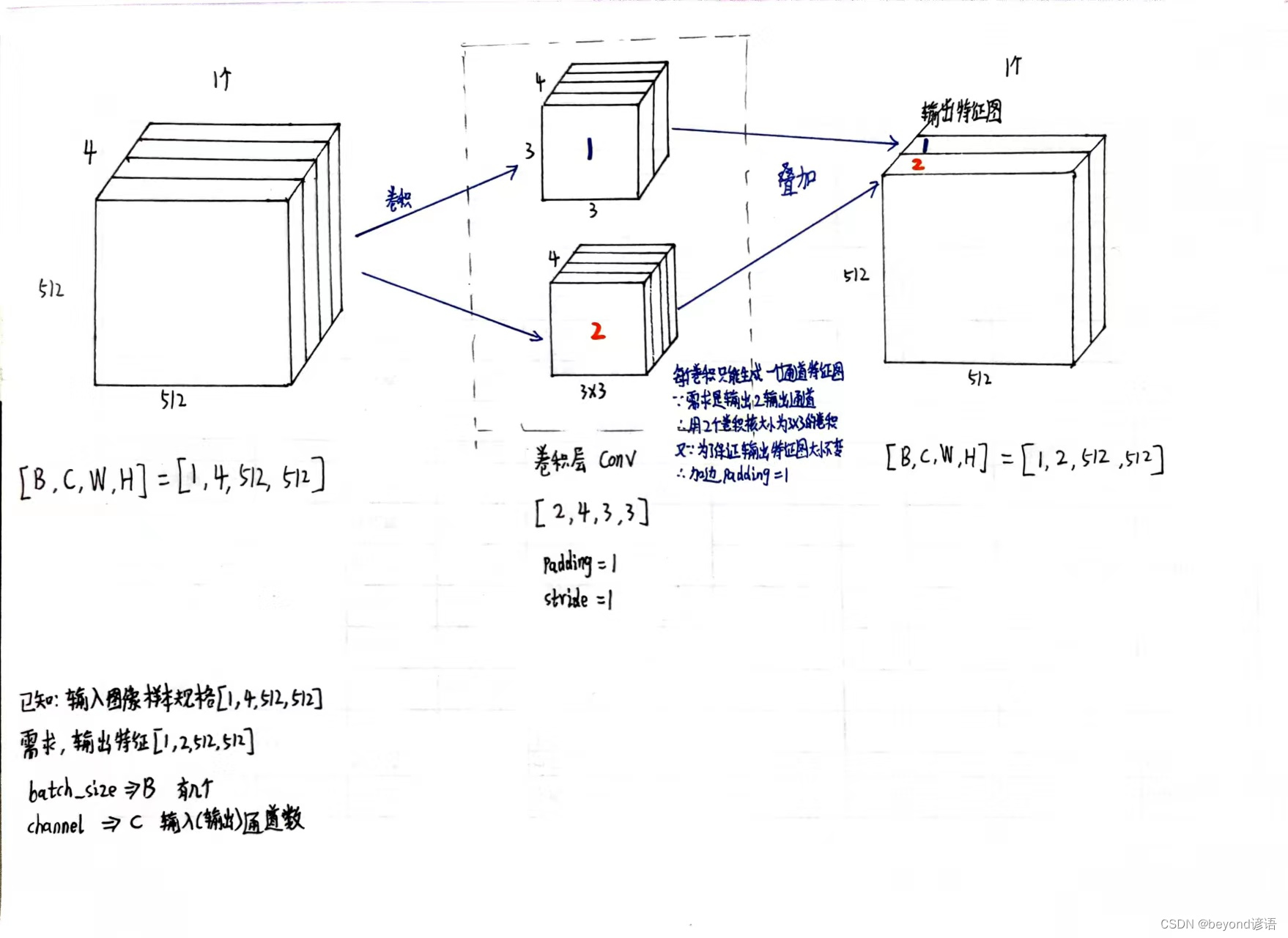
一、确定输入样本特征和输出特征
输入样本通道数4、期待输出样本通道数2、卷积核大小3×3
具体卷积层的构建可参考博文:八、卷积层
设定卷积层
torch.nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=kernel_size,padding=1,stride=1)
必要参数:输入样本通道数in_channels、输出样本通道数out_channels、卷积核大小kernel_size
padding是否加边,默认不加,这里为了保证输出图像的大小不变,加边数设为1
stride步长设置,默认为1
import torch
in_channel, out_channel = 4, 2
width, heigh = 512, 512
batch_size = 1
inputs = torch.randn(batch_size,in_channels,width,heigh)#[B,C,W,H]
kernel_size = 3
conv_layer = torch.nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=kernel_size,padding=1,stride=1)
outputs = conv_layer(inputs)
print(inputs.shape)
"""
torch.Size([1, 4, 512, 512])
"""
print(outputs.shape)
"""
torch.Size([1, 2, 512, 512])
"""
print(conv_layer.weight.shape)#看下卷积层核参数信息
# 卷积层权重参数大小,因为batch_size为1,故卷积核参数的B也为1;
# 因为输入样本的通道数是3,故卷积层传入参数的channel也为3;
# 因为输出样本的通道数是1,故卷积层传入参数的
"""
torch.Size([2, 4, 3, 3])
"""
二、确定卷积核内容进行卷积
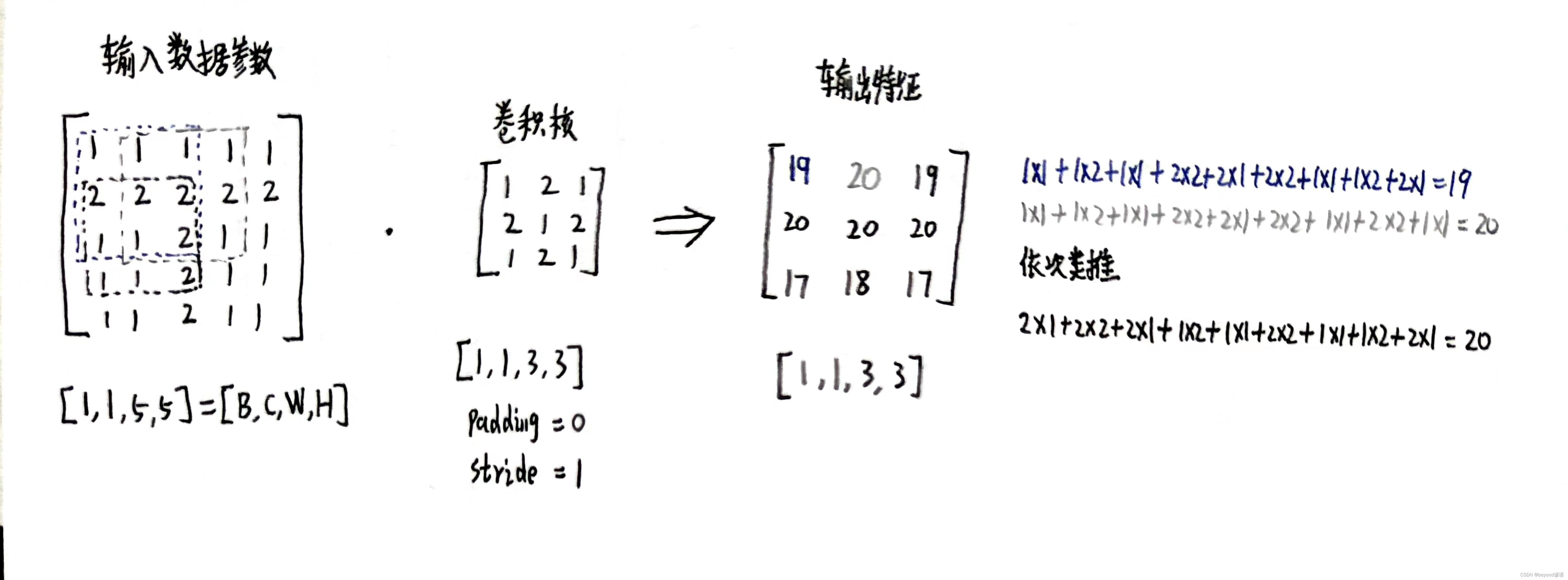
import torch
inputs = [1,1,1,1,1,
2,2,2,2,2,
1,1,2,1,1,
1,1,2,1,1,
1,1,2,1,1]
inputs = torch.Tensor(inputs).view(1,1,5,5)
kernel_size = 3
padding = 0
stride = 1
kernel = torch.Tensor([1,2,1,
2,1,2,
1,2,1]).view(1,1,3,3)
conv_layer = torch.nn.Conv2d(1,1,kernel_size=kernel_size,padding=padding,stride=stride,bias=False)
conv_layer.weight.data = kernel.data
outputs = conv_layer(inputs)
print(outputs)
"""
tensor([[[[19., 20., 19.],
[20., 20., 20.],
[17., 18., 17.]]]], grad_fn=<SlowConv2DBackward0>)
"""
print(inputs)
"""
tensor([[[[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[1., 1., 1., 1., 1.]]]])
"""
print(kernel)
"""
tensor([[[[1., 2., 1.],
[2., 1., 2.],
[1., 2., 1.]]]])
"""
print(inputs.shape)
"""
torch.Size([1, 1, 5, 5])
"""
print(outputs.shape)
"""
torch.Size([1, 1, 3, 3])
"""
print(kernel.shape)
"""
torch.Size([1, 1, 3, 3])
"""
print(conv_layer.weight.shape)
"""
torch.Size([1, 1, 3, 3])
"""
三、根据需求进行网络模型搭建
①准备数据集
还是以MNIST手写数字数据集为例,数据集细节可参考博文:九、多分类问题
设置batch_size=64,每个batch中有64张样本,至于一共有多少个batch,取决于数据集的总数量
使用transforms.Compose(),组合操作,把数据集都转换为Tensor数据类型,并且全部都取均值和标准差,方便训练,强化训练效果,这里的值都是经过计算过的,直接用就行
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#把图片变成张量形式
transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
②加载数据集
pytorch提供MNIST接口,直接调用相关函数即可
datasets中
参数root表示数据集路径;
参数train表示是否是训练集,True表示下载训练集,False则表示下载测试集;
参数download表示是否下载,True表示若指定路径不存在数据集则联网下载;
将所有的数据集都经过上面定义的transforms组合操作,转换成Tensor格式和均值标准差归一化。
DataLoader中
参数train_dataset指定数据集datasets;
参数shuffle表示是否将数据集中的样本打乱顺序,训练集需要,测试集不需要
参数batch_size表示一次(batch)取多少个样本,至于一共取多少次取决于数据集总样本数
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
③模型构建
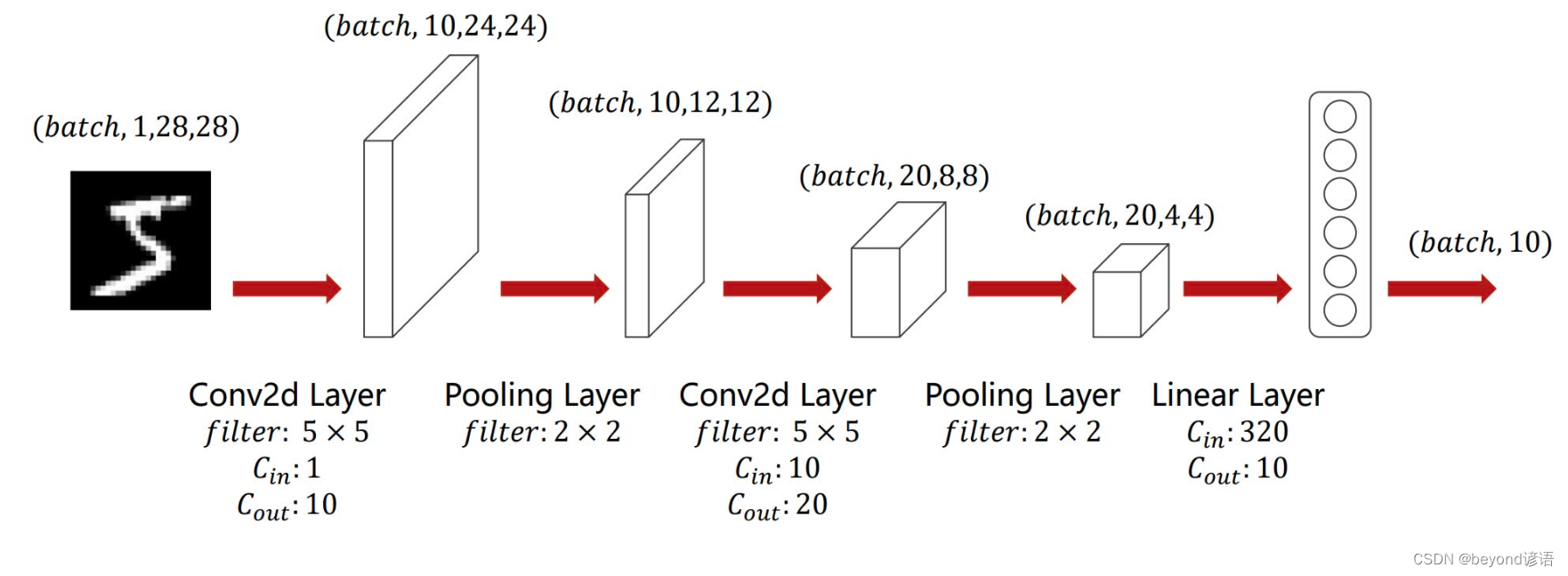

由图可知,输入图像(通道数为1)首先进入一个卷积层,卷积核大小为5×5,输出特征通道数为10,即torch.nn.Conv2d(1,10,kernel_size=5)
之后进入一个ReLU激活函数层,激活函数无需参数,即F.relu()
然后再进入一个核为2×2的MaxPool层,即torch.nn.MaxPool2d(2)
之后将通道数为10的特征参数再送入一个卷积层,卷积核大小为5×5,输出特征通道数为20,即torch.nn.Conv2d(10,20,kernel_size=5)
之后进入一个ReLU激活函数层,激活函数无需参数,即F.relu()
然后再进入一个核为2×2的MaxPool层,即torch.nn.MaxPool2d(2)
有第一张图可知,最终的特征参数个数为20×4×4=320,将这320个特征参数通过线性层(全连接层),转到10个维度上,即torch.nn.Linear(320,10),因为是10分类任务,故需要转到10个维度上
在模型参数函数(def __init__(self):)中,池化层操作都一样,故定义一个即可,最终,卷积操作两个,一个池化操作,一个线性层(全连接)操作
在前向传播函数(def forward(self,x):)中,数据集中x为[B,C,W,H],故通过x.size(0)取出batch_size,即B的值
class yNet(torch.nn.Module):
def __init__(self):
super(yNet,self).__init__()
self.conv_1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.conv_2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv_1(x)))
x = self.pooling(F.relu(self.conv_2(x)))
x = x.view(batch_size,-1)
x = self.fc(x)
return x
model = yNet()
GPU加速
只需要通过.to()方法,将模型、训练函数中数据集、测试函数中数据集调用该方法即可
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
④损失函数和优化器
lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)
⑤训练函数定义
for i, data in enumerate(train_loader,0):
从train_loader这个DataLoader中进行枚举,0表示从DataLoader下标为0处开始,train_loader返回两个值,索引和数据,其中数据包括两类,x和y
i接收索引、data接收数据
x,y = data,x和y分别接收data中的28×28=784个参数,y为所对应的某一个类别
测试
x,y = test_dataset[0]
x.shape
"""
torch.Size([1, 28, 28])
"""
y
"""
7
"""
完整代码
def ytrain(epoch):
loss_total = 0.0
for batch_index ,data in enumerate(train_loader,0):
x,y = data
#x,y = x.to(device), y.to(device)#GPU加速
optimizer.zero_grad()
y_hat = model(x)
loss = lossf(y_hat,y)
loss.backward()
optimizer.step()
loss_total += loss.item()
if batch_index % 300 == 299:# 每300epoch输出一次
print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))
loss_total = 0.0 #每次epoch都将损失清零,方便计算下一次的损失
⑥测试函数定义
def ytest():
correct = 0#模型预测正确的数量
total = 0#样本总数
with torch.no_grad():#测试不需要梯度,减小计算量
for data in test_loader:#读取测试样本数据
images, labels = data
#images, labels = images.to(device), labels.to(device) #GPU加速
pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标
pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标
total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案
correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0
print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率
⑦主函数调用
if __name__ == '__main__':
for epoch in range(100):#训练10次
ytrain(epoch)#训练一次
if epoch%10 == 9:
ytest()#训练10次,测试1次
⑧完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#把图片变成张量形式
transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
class yNet(torch.nn.Module):
def __init__(self):
super(yNet,self).__init__()
self.conv_1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.conv_2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.fc = torch.nn.Linear(320,10)
def forward(self,x):#传入单张样本x
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv_1(x)))
x = self.pooling(F.relu(self.conv_2(x)))
x = x.view(batch_size,-1)
x = self.fc(x)
return x
model = yNet()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)
def ytrain(epoch):
loss_total = 0.0
for batch_index ,data in enumerate(train_loader,0):
x,y = data
x,y = x.to(device), y.to(device)#GPU加速
optimizer.zero_grad()
y_hat = model(x)
loss = lossf(y_hat,y)
loss.backward()
optimizer.step()
loss_total += loss.item()
if batch_index % 300 == 299:# 每300epoch输出一次
print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))
loss_total = 0.0
def ytest():
correct = 0#模型预测正确的数量
total = 0#样本总数
with torch.no_grad():#测试不需要梯度,减小计算量
for data in test_loader:#读取测试样本数据
images, labels = data
images, labels = images.to(device), labels.to(device) #GPU加速
pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标
pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标
total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案
correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0
print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率
if __name__ == '__main__':
for epoch in range(10):#训练10次
ytrain(epoch)#训练一次
if epoch%10 == 9:
ytest()#训练10次,测试1次
⑨测试一下
x,y = train_dataset[9]#第9个数据x为图片,对应的结果为2
y
"""
2
"""
x = x.view(-1,1,28,28)#因为tensor需要格式为(B,C,W,H)转换一下格式
y_hat = model(x)#放入模型中进行预测,因为时十分类任务,输出十个值
y_hat
"""
tensor([[-2.8711, -2.2891, -0.5218, -2.0884, 6.2099, -0.1559, 1.9904, -0.8938,
1.3734, 2.9303]], grad_fn=<AddmmBackward0>)
"""
pred_maxvalue, pred_maxindex = torch.max(y_hat,dim=1)#选出值最大的,和相对于的下标索引
pred_maxvalue#最大值
"""
tensor([6.2099], grad_fn=<MaxBackward0>)
"""
pred_maxindex#最大值所对应的索引下标值
"""
tensor([4])
"""
预测错了,得多训练几轮
四、课后作业

除网络模型外,其他的都可以复用
这里就不再赘述,直接对模型结构进行搭建
查看下官网给的卷积层padding的计算公式

以下是我个人设计的网络模型,接下来开始去实现模型架构
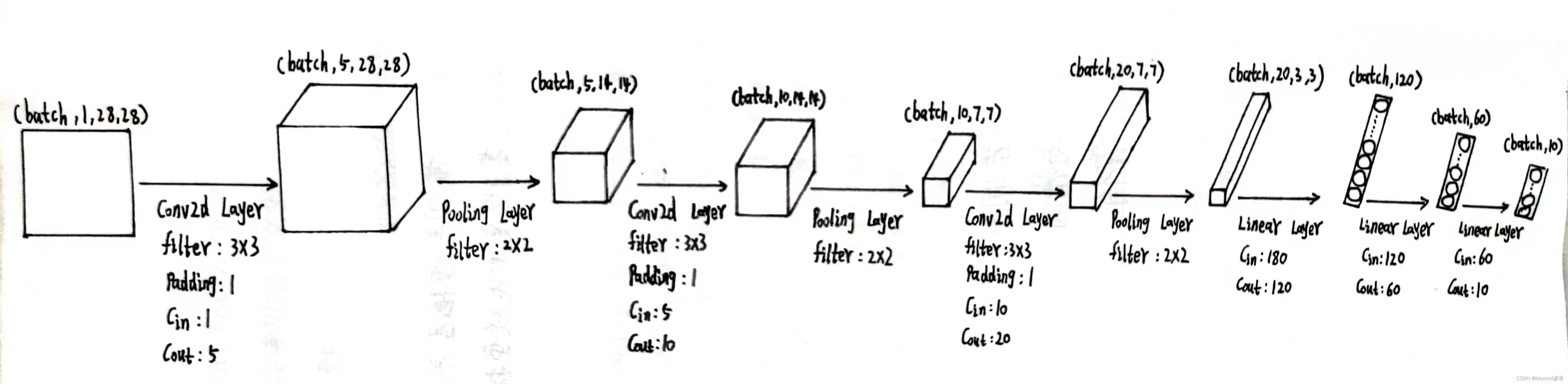
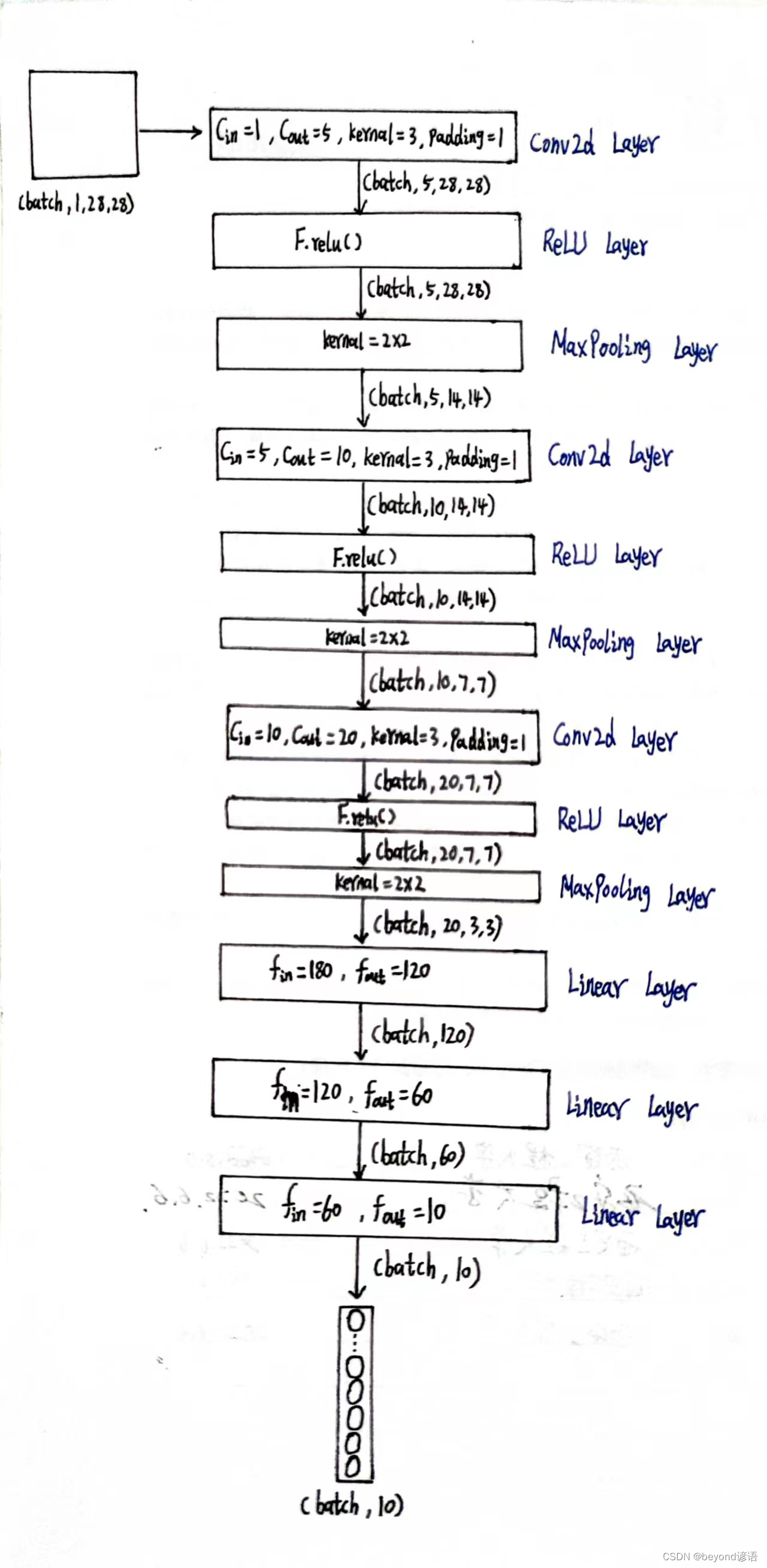
①调试
加载数据集
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#把图片变成张量形式
transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
#这里取测试集中的一个样本
x,y = test_dataset[1]
x.shape
"""
torch.Size([1, 28, 28])
"""
y
"""
2
"""
第一个卷积层
因为数据集中样本shape是torch.Size([1, 28, 28]),而pytorch提供的接口都得适应[B,C,W,H]形式,故需要先通过x = x.view(-1,1,28,28)转换一下类型
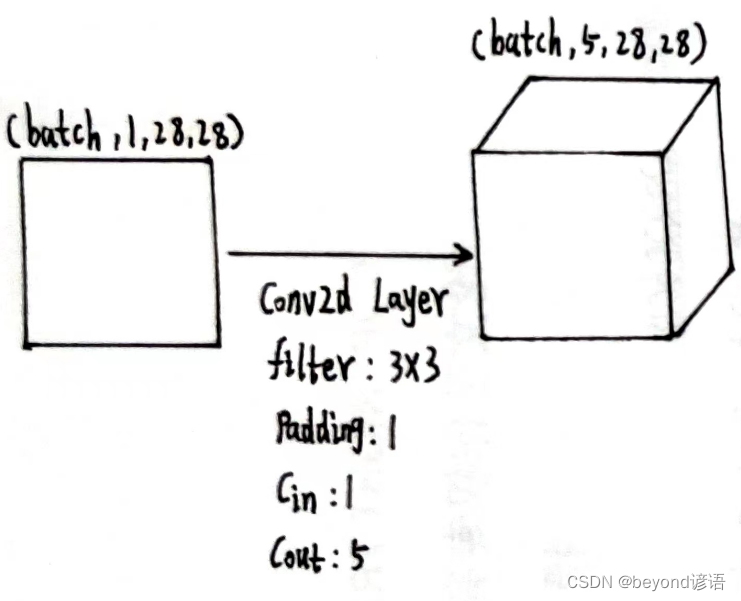
根据结构需要,定义第一个卷积层,为了后续计算方便,这里加边padding=1,保证输入和输出特征图大小一致,这里仅为了测试,batch取1
conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)
x = x.view(-1,1,28,28)
x.shape
"""
torch.Size([1, 1, 28, 28])
"""
conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)
x1 = conv_1(x)
x1.shape
"""
torch.Size([1, 5, 28, 28])
"""
由输出结果可知,通过第一个卷积层之后,特征图x1为[1,5,28,28]
将x1传入第一个最大池化层
第一个最大池化层
x1的形状为[1,5,28,28]
定义最大池化层:pooling = torch.nn.MaxPool2d(2)
将x1传入最大池化层,得到特征x2
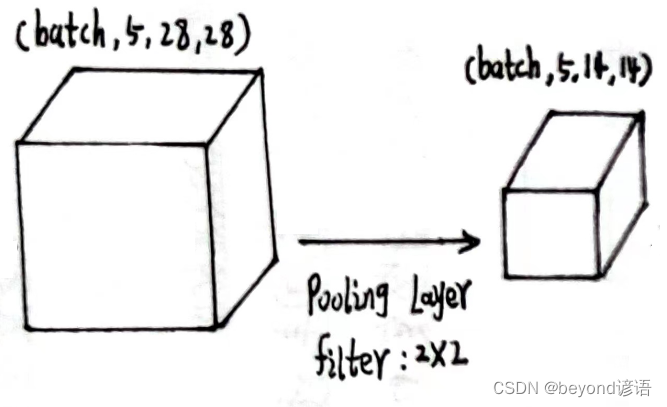
pooling = torch.nn.MaxPool2d(2)
x2 = pooling(x1)
x2.shape
"""
torch.Size([1, 5, 14, 14])
"""
输出结果x2的形状为[1, 5, 14, 14]
将x2传入第二个卷积层中
第二个卷积层
x2的形状为[1, 5, 14, 14]
定义第二个卷积层:conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)
将x2传入第二个卷积层,得到特征x3
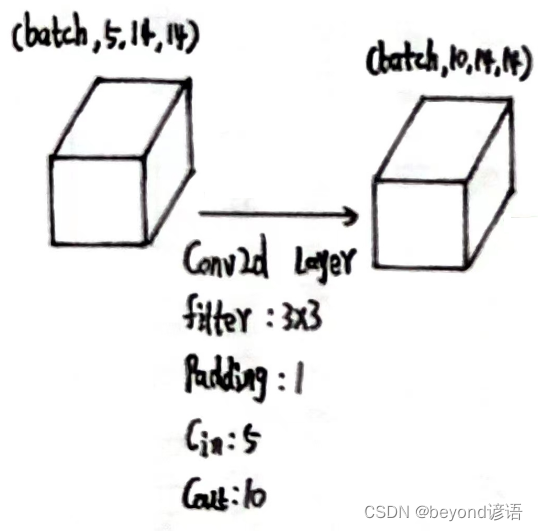
conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)
x3 = conv_2(x2)
x3.shape
"""
torch.Size([1, 10, 14, 14])
"""
输出结果x3的形状为[1, 10, 14, 14]
将x3传入第二个最大池化层中
第二个最大池化层
x3的形状为[1, 10, 14, 14]
使用上述同样的最大池化层:pooling = torch.nn.MaxPool2d(2)
将x3传入第二个最大池化层,得到特征x4
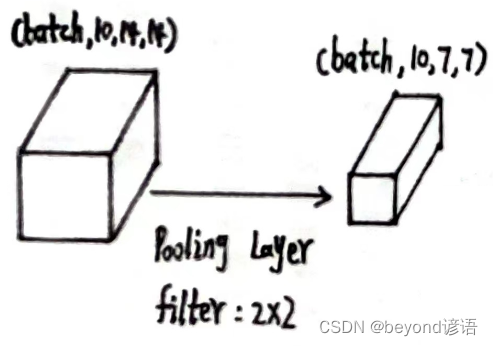
pooling = torch.nn.MaxPool2d(2)
x4 = pooling(x3)
x4.shape
"""
torch.Size([1, 10, 7, 7])
"""
输出结果x4的形状为[1, 10, 7, 7]
将x4传入第三个卷积层中
第三个卷积层
x4的形状为[1, 10, 7, 7]
定义第三个卷积层:conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)
将x4传入第三个卷积层,得到特征x5
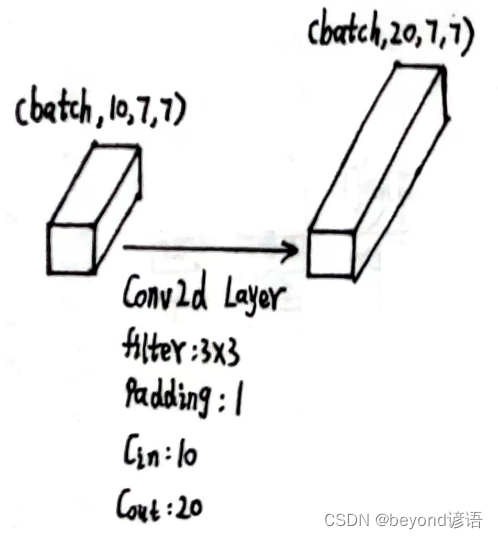
conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)
x5 = conv_3(x4)
x5.shape
"""
torch.Size([1, 20, 7, 7])
"""
输出结果x5的形状为[1, 20, 7, 7]
将x5传入第三个最大池化层中
第三个最大池化层
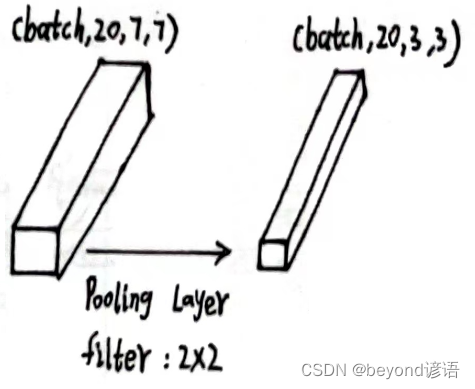
x5的形状为[1, 20, 7, 7]
使用上述同样的最大池化层:pooling = torch.nn.MaxPool2d(2)
将x5传入第二个最大池化层,得到特征x6
pooling = torch.nn.MaxPool2d(2)
x6 = pooling(x5)
x6.shape
"""
torch.Size([1, 20, 3, 3])
"""
输出结果x6的形状为[1, 20, 3, 3]
将x6传入第一个线性层中
第一个全连接层
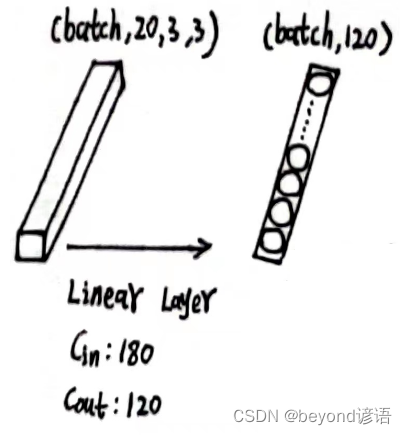
x6的形状为[1, 20, 3, 3],此时特征图x6共有1×20×3×3=180个参数
因为线性层传入的特征是二维矩阵形式,每个batch占一行,每行存放单个样本的所有参数信息,故需要将x6形状进行转变,x6.size(0)获取batch,这里的batch是1,剩下的,系统进行自动排列,x_all = x6.view(x6.size(0),-1),此时的x_all的形状为[1,180]
之后根据需求,定义第一个线性层:fc_1 = torch.nn.Linear(180,120),这里的输入180,必须和最终的特征x_all吻合
将x_all传入第一个全连接层,得到特征x_x1
x6.shape
"""
torch.Size([1, 20, 3, 3])
"""
x6.size(0)
"""
1
"""
x_all = x6.view(x6.size(0),-1)
x_all.shape
"""
torch.Size([1, 180])
"""
fc_1 = torch.nn.Linear(180,120)
x_x1 = fc_1(x_all)
x_x1.shape
"""
torch.Size([1, 120])
"""
输出结果x_x1的形状为[1, 120]
将x_x1传入第二个全连接层中
第二个全连接层
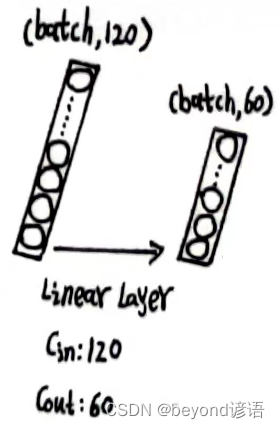
x_x1的形状为[1, 120]
根据需求,定义第二个全连接层,fc_2 = torch.nn.Linear(120,60)
将x_x1传入第二个全连接层,得到特征x_x2
fc_2 = torch.nn.Linear(120,60)
x_x2 = fc_2(x_x1)
x_x2.shape
"""
torch.Size([1, 60])
"""
输出结果x_x2的形状为[1, 60]
将x_x2传入第三个全连接层中
第三个全连接层
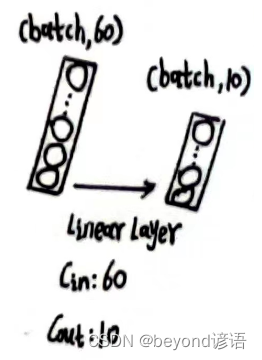
x_x2的形状为[1, 60]
根据需求,定义第三个全连接层,fc_3 = torch.nn.Linear(60,10)
将x_x2传入第三个全连接层,得到特征x_x3
fc_3 = torch.nn.Linear(60,10)
x_x3 = fc_3(x_x2)
x_x3.shape
"""
torch.Size([1, 10])
"""
最终结果为x_x3,形状为[1, 10],十分类任务,十个概率值,取最大的,就是最终预测的结果
②模型构建
class yNet(torch.nn.Module):
def __init__(self):
super(yNet,self).__init__()
self.conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)
self.pooling = torch.nn.MaxPool2d(2)
self.conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)
self.conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)
self.fc_1 = torch.nn.Linear(180,120)
self.fc_2 = torch.nn.Linear(120,60)
self.fc_3 = torch.nn.Linear(60,10)
def forward(self,x):
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv_1(x)))
x = self.pooling(F.relu(self.conv_2(x)))
x = self.pooling(F.relu(self.conv_3(x)))
x = x.view(batch_size,-1)
x = self.fc_1(x)
x = self.fc_2(x)
x = self.fc_3(x)
return x
model = yNet()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#GPU加速
model.to(device)
③完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),#把图片变成张量形式
transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
class yNet(torch.nn.Module):
def __init__(self):
super(yNet,self).__init__()
self.conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)
self.pooling = torch.nn.MaxPool2d(2)
self.conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)
self.conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)
self.fc_1 = torch.nn.Linear(180,120)
self.fc_2 = torch.nn.Linear(120,60)
self.fc_3 = torch.nn.Linear(60,10)
def forward(self,x):
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv_1(x)))
x = self.pooling(F.relu(self.conv_2(x)))
x = self.pooling(F.relu(self.conv_3(x)))
x = x.view(batch_size,-1)
x = self.fc_1(x)
x = self.fc_2(x)
x = self.fc_3(x)
return x
model = yNet()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)
def ytrain(epoch):
loss_total = 0.0
for batch_index ,data in enumerate(train_loader,0):
x,y = data
x,y = x.to(device), y.to(device)#GPU加速
optimizer.zero_grad()
y_hat = model(x)
loss = lossf(y_hat,y)
loss.backward()
optimizer.step()
loss_total += loss.item()
if batch_index % 300 == 299:# 每300epoch输出一次
print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))
loss_total = 0.0
def ytest():
correct = 0#模型预测正确的数量
total = 0#样本总数
with torch.no_grad():#测试不需要梯度,减小计算量
for data in test_loader:#读取测试样本数据
images, labels = data
images, labels = images.to(device), labels.to(device) #GPU加速
pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标
pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标
total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案
correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0
print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率
if __name__ == '__main__':
for epoch in range(10):#训练10次
ytrain(epoch)#训练一次
if epoch%10 == 9:
ytest()#训练10次,测试1次
④测试一下
x,y = train_dataset[12]#第12个数据x为图片,对应的结果为3
y
"""
3
"""
x = x.view(-1,1,28,28)#因为tensor需要格式为(B,C,W,H)转换一下格式
y_hat = model(x)#放入模型中进行预测,因为时十分类任务,输出十个值
y_hat
"""
tensor([[ 0.0953, 0.0728, 0.0505, 0.0618, -0.0512, -0.1338, -0.0261, -0.0677,
-0.0265, 0.0236]], grad_fn=<AddmmBackward0>)
"""
pred_maxvalue, pred_maxindex = torch.max(y_hat,dim=1)#选出值最大的,和相对于的下标索引
pred_maxvalue#最大值
"""
tensor([0.0953], grad_fn=<MaxBackward0>)
"""
pred_maxindex#最大值所对应的索引下标值
"""
tensor([0])
"""
好家伙,又预测错了,确实得多训练几轮
又是动笔画,又是单步调试,若各位客官姥爷有所收获,还请点个小小的赞,这将是对我的最大的鼓励,万分感谢~