前几天的文章,我们已经简单的介绍过Pandas 和Polars的速度对比。刚刚发布的Pandas 2.0速度得到了显著的提升。但是本次测试发现NumPy数组上的一些基本操作仍然更快。并且Polars 0.17.0,也在上周发布,并且也提到了性能的改善,所以我们这里做一个更详细的关于速度方面的评测。

本文将比较Pandas 2.0(使用Numpy和Pyarrow作为后端)和Polars 0.17.0的速度。并且介绍使用Polars库复现一些简单到复杂的Pandas代码,这样也算是对Polars的一个简单介绍。另外测试将在4 cpu和32 GB RAM上进行。
安装
可以通过pip命令进行安装
pipinstallpolars==0.17.0# Latest version
pipinstallpandas==2.0.0 # Latest pandas version
我们需要使用下面的库:
importpandasaspd
importpolarsaspl
importnumpyasnp
importtime
为了评估性能,我们将使用一个由3000万行和15列组成的合成数据集。该数据集由8个分类特征和7个数字特征组成,是人工生成的。数据集的链接在最后会提供。
下面显示了该数据集的一个示例

读取数据集
比较两个库读取parquet文件的时间。我使用了下面的代码,并使用%%time来获取代码执行的时间。
train_pd=pd.read_parquet('./train.parquet') #Pandas dataframe
train_pl=pl.read_parquet('./train.parquet') #Polars dataframe

可以看到Polars和Pandas 2.0在速度方面表现相似(因为都是arrow)但是Pandas(使用Numpy后端)需要两倍的时间来完成这个任务(这可能是因为有类型转换的原因,因为最终要把类型转成np的类型)。
聚合操作
下面的代码,该代码计算聚合(最小值、最大值、平均值)。
# pandas query
train_pd[nums].agg(['min','max','mean','median','std')
train[cats].agg(['nunique'])
# Polars query
train_pl.with_columns([
pl.col(nums).min().suffix('_min'),
pl.col(nums).max().suffix('_max'),
pl.col(nums).mean().suffix('_mean'),
pl.col(nums).median().suffix('_median'),
pl.col(nums).std().suffix('_std'),
pl.col(cats).nunique().suffix('_unique'),
])

对于简单的聚合,Pandas在语法和性能方面会更好,但是差距并不大。
筛选操作
选择操作涉及根据条件进行查询和提取,例如下面代码
查询1:当nums_8小于10时,统计唯一值。
# Polars filter and select
train_pl.filter(pl.col("num_8") <=10).select(pl.col(cats).n_unique())
# Pandas filter and select
train_pd[train_pd['num_8']<=10][cats].nunique()
查询2:当cat_1 = 1时,计算所有数值列的平均值。
# Polars filter and select
train_pl.filter(pl.col("cat_1") ==1).select(pl.col(nums).mean())
# Pandas filter and select
train_pd[train_pd['cat_1']==1][nums].mean()
两个查询的结果如下:

在性能方面,Polars的数值filter速度要快2-5倍,而Pandas需要编写的代码更少。Pandas在处理字符串(分类特征)时速度较慢,这个我们在以前的文章中已经提到过,并且使用df.query函数在语法上更简洁,并且在大数据量的情况下会更快,这个如果有人有兴趣,我们再单独总结。
分组操作
分组操作是机器学习中用于创建聚合特征的基本操作之一,我在下面的通过user进行分组后,进行聚合来测试性能
函数1:统计cat_1的聚合特征
函数2:num_7的均值特征
函数3:所有数值列的平均聚合特征
函数4:计算分类列的聚合特性
nums=['num_7','num_8', 'num_9', 'num_10', 'num_11', 'num_12', 'num_13', 'num_14','num_15']
cats=['cat_1', 'cat_2', 'cat_3', 'cat_4', 'cat_5', 'cat_6']
# Pandas Functions
Function_1=train_pd.groupby(['user'])['cat_1'].agg('count') #Function 1
Function_2=train_pd.groupby(['user'])['num_7'].agg('mean') #Function 2
Function_3=train_pd.groupby(['user'])[nums].agg('mean') #Function 3
Function_4=train_pd.groupby(['user'])[cats].agg('count') #Function 4
# Polars Functions
Function_1=train_pl.groupby('user').agg(pl.col('cat_1').count()) #Function 1
Function_2=train_pl.groupby('user').agg(pl.col('num_7').mean()) #Function 2
Function_3=train_pl.groupby('user').agg(pl.col(nums).mean()) #Function 3
Function_4=train_pl.groupby('user').agg(pl.col(cats).count()) #Function 4

可以看到Polars非常快。但是Pyarrow后端的Pandas 2.0在所有情况下都明显比Polars和Pandas 2.0 (numpy后端)慢。
我们将分组变量的数量从1增加到5,看看结果:
# PANDAS: TESTING GROUPING SPEED ON 5 COLUMNS
forcatin ['user', 'cat_1', 'cat_2', 'cat_3', 'cat_4']:
cols+=[cat]
st=time.time()
temp=train_pd.groupby(cols)['num_7'].agg('mean')
en=time.time()
print(cat,':',en-st)
# POLARS: TESTING GROUPING SPEED ON 5 COLUMNS
forcatin ['user', 'cat_1', 'cat_2', 'cat_3', 'cat_4']:
cols+=[cat]
st=time.time()
temp=train_pl.groupby(cols).agg(pl.col('num_7').mean())
en=time.time()
print(cat,':',en-st)
deltemp
下图中没有显示Pyarrow的Pandas 2.0,因为求值需要1000多秒。

对于group操作来说Polars是首选,但是Pandas在分组时默认删除空值,而Polars库则不会,这是一个小小的差异,在使用时需要注意。
排序操作
下面的代码,可以基于一个或多个列(升序或降序)快速对数据进行排序。
cols=['user','num_8'] # columns to be used for sorting
#Sorting in Polars
train_pl.sort(cols,descending=False)
# Sorting in Pandas
train_pd.sort_values(by=cols,ascending=True)
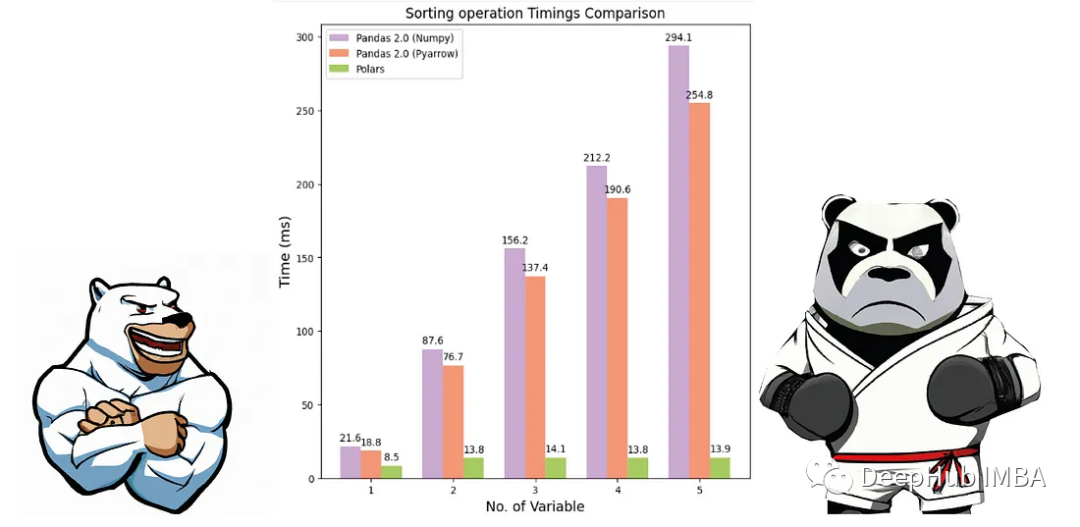
从上图可以看出,对于排序和分组等复杂情况,Polars仍然是最快的库。Pandas对数据进行简单排序需要几分钟的时间,但在polar中,复杂的排序函数可以在不超过15秒的时间内计算出来。
总结
本文对Pandas和polar之间性能差异做了一个对比总结。Pandas在语法上更有吸引力(因为用的多习惯了),而Polars在处理更大的数据时提供了更好的吞吐量。
但是由于Polars是一个较新的库,从Pandas过渡到其他库具是有挑战性的。通过了解这两种强大工具之间的差异,我们可以根据自己的特定需求选择最佳选项,并实现更高效和有效的数据分析。
本文的数据下载:
https://avoid.overfit.cn/post/9d617b39040441e39433fc906cafefc9
作者:Priyanshu Chaudhary