学习Java web的前置条件就是数据库,只有学了数据库才能更好的处理网站应用产生的数据。
初识数据库
数据库(Database)顾名思义就是一个存储数据的仓库,通过它就可以直接查找到你想要的数据,举个简单的例子,你游戏账号的信息就是从数据库里面读取数据后再反应给你的。
了解数据库的作用后就可能有人会想:excel也可以存储数据啊,为什么不用我电脑自带的excel呢?那就不得不提数据库的另一个优点了:那就是数据的共享和巨大的存储空间。excel相当于一个移动硬盘,我如果使用了这个excel表格,拿别人就不能用了,而数据库就相当于一个网盘,支持多人的同时访问,并且存储空间更大。
那么数据库里面的数据是以怎么样的形式存储的呢?其实和excel差不多,也是一个又一个的二维表单,只不过数据库里面的这些表单可以相互联系。所以学习数据库应该弄清楚各表之间的关系和每一个表的结构。
因为是自己学习用,所以这里使用的是MySQL。
建立数据库
既然每一个数据库里面都有很多的表,每一个表里面又有很多的属性和联系,那么建立之前就要明确自己想要建立一个什么样的表。举个例子:
- 学生表:记录每个学生的学号、姓名、性别、导师编号。
- 教师表:记录教师的教师号和名字。
- 师生联系表:记录每个学生的导师。
其中加粗的代表唯一标记,不可以重复。这样就建立了一个数据库了。
student表单样式如下:
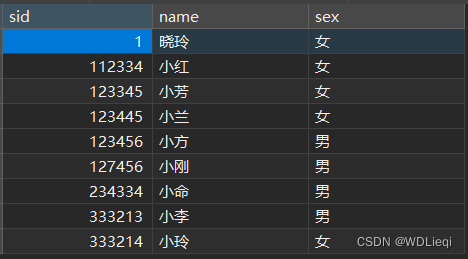
每一列代表这一列的属性,这一行代表的就是存储的数据了。
数据库的规范化
这部分摘抄知乎大佬的文章:数据库的规范化
- 第一范式:消除组中的重复,也就是说列中是否存储了其他列中的信息(字段不可再分)
- 第二范式:消除部分依赖列,也就是说是否有依赖于一部分主键的列(非主键字段完全依赖主键字段)
- 第三范式:消除非依赖列,是否有依赖于非主键的列(消除传递依赖)
例如:学生信息( 学生ID,学生姓名,所在年级,性别,参加课程,课程ID,课程名称,课程描述,教师ID,教师姓名,教授课程)
该关系模式是非规范化的关系,冗余太大,需要转化为第一范式
学生表(学生ID,学生姓名,所在年级,性别)
学生课程表(学生ID,课程ID,课程名称,教师ID,教师姓名,课程描述)
从第一范式到第二范式,我们需要消除表中部分依赖主键的列,使得非主键字段完全依赖于主键字段。 在学生课程表中,许多列仅仅依赖于课程ID,而不依赖于学生ID,这个表的主键是学生ID+课程ID,因此把这个表分成两个表,第二范式如下:
学生表(学生ID,学生姓名,所在年级,性别)
学生课程表(学生ID,课程ID,课程名称)
课程表(课程ID,教师ID,教师名称,课程描述)
在课程表中,教师ID依赖于课程ID,教师名称又依赖于教师ID,有传递依赖,那么分解第三范式
学生表(学生ID,学生姓名,所在年级,性别)
学生课程表(学生ID,课程ID,课程名称)
课程表(课程ID,教师ID,课程描述)
教师表(教师ID,教师名称)
认识SQL语句
我们了解完数据库以后,就不得不面对一个问题:当请求的数据足够多的时候我们总不能再一个一个的手动建表,插入数据吧,所以这里就要学一个数据库的工具SQL语句,通过SQL语句我们可以很方便的建表,插入数据等操作。
- SQL语句不区分大小写(关键字推荐使用大写),它支持多行,并且需要使用
;进行结尾! - 可以用空格和缩进来来增强语句的可读性;
数据库定义语言
数据库操作
通过create database语句创建一个数据库
CREATE DATABASE 数据库名称
为了保障数据库的唯一性所以可以通过添加if not exists语句来判断是否存在
CREATE DATABASE IF NOT EXISTS 数据库名称
删除数据库:drop database
DROP DATABASE IF EXISTS 数据库名称
也可以将数据库的编码格式修改为utf-8
ALTER DATABASE 数据库名称 CHARACTER SET utf8
数据库类型
二进制数据类型包括 Binary、Varbinary 和 Image
- Binary[(n)] 是 n 位固定的二进制数据。
- Varbinary[(n)] 是 n 位变长度的二进制数据。
字符数据类型
- char(n)表示建立一个定长为n的字符串。
- Varchar 长度不固定,但不能超过n。
用于存储数字的基本数据类型
- int用于存储一般的整数,范围在 (-2147483648,2147483647)
- smallint用于存储小的整数,范围在 (-32768,32767)
- bigint用于存储大型整数,范围在 (-9,223,372,036,854,775,808,9,223,372,036,854,775,807)
- float用于存储单精度小数
- double用于存储双精度的小数
用于存储时间的类型
- data 存储日期
- time 存储时间
- year 存储年
操作表
创建格式
CREATE TABLE 表名(
列名 数据类型,
列名 数据类型,
...
);
举例:
CREATE TABLE student(
sid INT,
name VARCHAR(255),
sex VARCHAR(20)
);
查看表结构
DESC 表名;
删除表
DROP TABLE 表名;
修改表:截取自:史上最全SQL基础知识总结(理论+举例)
-
添加列:给 stu 表添加 classname 列
ALTER TABLE stu ADD (classname varchar(100)); -
修改列的数据类型:修改 stu 表的 gender 列类型为 CHAR(2)
ALTER TABLE stu MODIFY gender CHAR(2); -
修改列名:修改 stu 表的 gender 列名为
sex ALTER TABLE stu change gender sex CHAR(2); -
删除列:删除 stu 表的 classname 列
ALTER TABLE stu DROP classname; -
修改表名称:修改 stu 表名称为 student
ALTER TABLE stu RENAME TO student;
数据库操作语言(DML)
插入数据
使用insert into来为数据库插入一条数据
INSERT INTO 表名 VALUES (数值, 数值, 数值);
上述语句不可以省略某一列,必须把每一列的数值都写上,但这太麻烦了,所以我们可以通过指定列名向指定列表添加数据
INSERT INTO 表名 (列名) VALUES (数值);
我们也可以一次性向数据库中插入多条数据:
INSERT INTO 表名(列名1, 列名2) VALUES(值1, 值2), (值1, 值2), (值1, 值2)
修改数据
通过语句 updata ... set ...来修改表的数据
UPDATE 表名 SET 修改内容 where 约束语句;
比如要把student表中,sid等于1的学生的名字改成小明
UPDATE student SET name='小明' where sid=1;
也可通过逗号进行多项修改
UPDATE student SET name = '小明', sex = '男' where sid = 1;
删除数据
通过delete来删除表中的内容
DELETE FROM 表名
通过上述语句可以删除表中的所有数据,表的属于不变,那要怎么删除指定的行呢,可以通过where添加条件
DELETE FROM 表名 where sid=1;
这样就可以删除学生sid等于1的那一行了,但是添加的条件最好是用主键,不然可能会因为数据重复,造成错误。
数据库查询语句(DQL)
单表查询
单表查询是最简单的一种查询,我们只需要在一张表中去查找数据即可,通过使用select语句来进行单表查询:
-- 指定查询某一列数据
SELECT 列名[,列名] FROM 表名
-- 会以别名显示此列
SELECT 列名 别名 FROM 表名
-- 查询所有的列数据
SELECT * FROM 表名
-- 只查询不重复的值
SELECT DISTINCT 列名 FROM 表名
也可以通过where语句添加查询条件
SELECT * FROM 表名 WHERE 条件
常用插叙条件
- 一般的比较运算符,包括=、>、<、>=、<=、!=等。
- 是否在集合中:in、not in
- 字符模糊匹配:like,not like
- 多重条件连接查询:and、or、not
排序查询
使用ASC表示升序排序,使用DESC表示降序排序,默认为升序。
查询所有学生记录,按学号升序排序
SELECT * FROM studnet order by sid ASC;
查询所有学生记录,按年龄降序排序,年龄相同按学号排序
SELECT * FROM student ORDER BY age DESC, sid ASC;
聚集函数
聚集函数一般用作统计,包括:
count([distinct]*)统计所有的行数(distinct表示去重再统计,下同)count([distinct]列名)统计某列的值总和sum([distinct]列名)求一列的和(注意必须是数字类型的)avg([distinct]列名)求一列的平均值(注意必须是数字类型)max([distinct]列名)求一列的最大值min([distinct]列名)求一列的最小值
查询所有学生的年龄的平均值:
SELECT AVG(age) FROM student;
分组和分页查询
通过使用group by来对查询结果进行分组,它需要结合聚合函数一起使用:
SELECT 聚合函数 FROM 表名 WHERE 条件 GROUP BY 列名
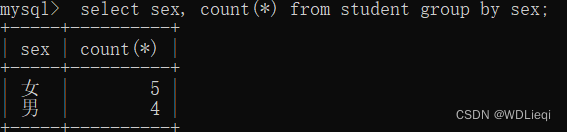
查询以性别分组,每一组的人数:
SELECT sex, COUNT(*) FROM student GROUP BY sex;
结果如下:
使用where语句来添加条件
查询每个部门的部门编号以及每个部门工资大于 1500 的人数:
SELECT deptno ,COUNT(*) FROM emp WHERE sal>1500 GROUP BY deptno;
也可以使用having语句添加限制条件
查询工资总和大于 9000 的部门编号以及工资和:
SELECT deptno, SUM(sal) FROM emp GROUP BY deptno HAVING SUM(sal) > 9000;
我们发现having和where都可以添加条件,那这两个有什么不同呢?我先来分析一下where,where是在筛选完满足条件的数据后才会将数据送到聚集函数中,而having是先调用完聚集函数再去筛选,也就是说where是针对原有的数据来进行的,而having是针对被集聚函数处理完以后的数据。
我们可以通过limit进行分页:
SELECT * FROM 表名 LIMIT 起始位置,数量
多表查询
自身连接查询:
自身连接,就是将自己和自己进行笛卡尔积计算,得到结果,但是由于表名相同,因此要先起一个别名:
SELECT * FROM 表名 别名1, 表名 别名2
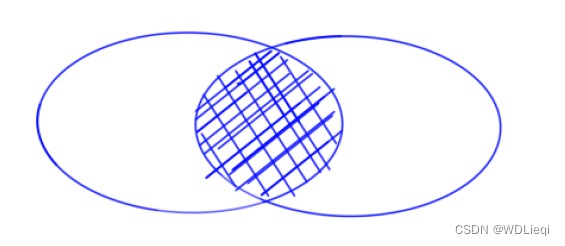
外连接查询
使用inner join进行连接只会显示交集的部分:
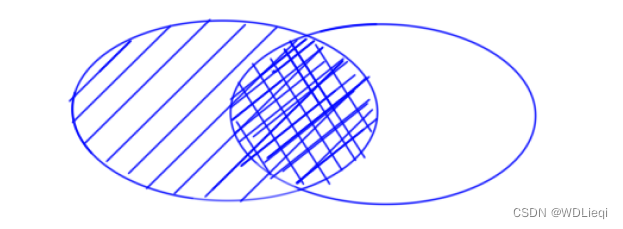
通过使用left join进行左连接,不仅会返回两个表满足条件的交集部分,也会返回左边表中的全部数据,而在右表中缺失的数据会使用null来代替,右连接right join同理
嵌套查询
我们可以将查询的结果作为另一个查询的条件,比如:
SELECT * FROM 表名 WHERE 列名 = (SELECT 列名 FROM 表名 WHERE 条件);
where 后面依旧是一个条件,括号里面的查询语句可以理解成一个for循环,通过for循环查找出来的东西去进行where判断。
比如查找和小方性别相同的学生:
SELECT * FROM student WHERE sex = (SELECT sex FROM student WHERE name='小方');
数据库控制语言(DCL)
一个庞大的数据库不可能只有一个管理员,我们需要多个管理员来一起进行管理。
创建用户
CREATE USER ‘用户名’@地址 IDENTIFIED BY '密码';
我们可以通过@来限制用户登录的登录IP地址,%表示匹配所有的IP地址,默认使用的就是任意IP地址。localhost就是代表本地地址。
用户授权
GRANT 权限 1, … , 权限 n ON 数据库.* TO ‘用户名’@地址;
GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON student.* TO user1@localhost;
删除用户
DROP USER ‘user1’@localhost;
视图
前面我们创建的表单都是实体表,那么除了实体表肯定也有虚拟表,也就是视图。
视图本身是一个不含任何数据的虚拟表,数据库中存放视图的定义,而不存放视图对应的数据。也就是说视图的唯一作用就是将数据展现在你的眼前。而为什么要建立视图呢,而不去用SELCT操作呢,原因也很简单就是简化操作。我们在建立一个视图以后就不需要重复调用SELECT语句了,直接调用视图就可以。
我们可以通过create view来创建视图
CREATE VIEW 视图名称 as 子查询语句 [WITH CHECK OPTION];
通过drop来删除一个视图:
DROP VIEW 视图名称
索引
在数据量变得非常庞大时,通过创建索引,能够大大提高我们的查询效率,就像Hash表一样,它能够快速地定位元素存放的位置,我们可以通过下面的命令创建索引:
-- 创建索引
CREATE INDEX 索引名称 ON 表名 (列名)
-- 查看表中的索引
show INDEX FROM student
我们也可以通过下面的命令删除一个索引:
drop index 索引名称 on 表名