目录
- Pointly-Supervised Instance Segmentation
- 摘要
- 方法
- Annotation format and collection
- 训练点标记
- 模型
- 实验结果
Pointly-Supervised Instance Segmentation
摘要
- 点注释来进行实例分割的弱监督
- 标签除了边界框还有一组随机点
- 对PointRend实例分割模块的修改
- 对于每个对象,新架构称为PointRend,为一个函数生成参数,该函数进行最终的点级掩码预测,隐式PointRend更直接,使用单个point-level掩码损失

一个框,对框随机采样,并标注为对象(红色)或背景(蓝色)
方法
Annotation format and collection
- 随机点,而不是手动点击注释
- 首先,使用任何现成的解决方案收集对象的包围框,对于每个对象,给定边界框和对象类别标签,在其边界框内的N个随机点位置依次呈现给注释器,用于二进制对象/背景分类

点监督的说明。对于规则网格上的10 × 10预测掩码(较深的颜色表示前景预测),我们通过双线性插值得到GT点(红色和蓝色分别表示前景和背景GT点)的精确位置的预测。注意,物体轮廓线仅用于说明
训练点标记
- 使用双线性插值从网格上的预测中近似预测GT点的位置
- 一旦我们在相同的点上有预测和地面真相标签,就可以以与完全监督相同的方式应用损失,其梯度将通过双线性插值传播
- 在点上使用交叉熵损失
- 对于基于区域的模型,一些GT点可能位于预测框之外,我们在训练时选择忽略这些点。相反,对于产生图像级掩模的模型,可以从真实值框的外部采样额外的背景点
- 在本文中,我们研究了最基本的设置,其中仅使用N个注释的地面真值点来训练所有模型。
数据增强
训练过程中的数据增强是现代分割模型的一个重要组成部分。基于点的注释与所有常见的增强兼容,如输入图像的缩放抖动、裁剪或水平翻转。在我们的实验中,我们观察到,对于较长时间的训练(3×schedule)和具有较高容量主干的模型(例如ResNeXt-101),点和全掩码监督之间的性能差距更大。我们假设这是由于当只有少数点可用时,训练数据的可变性降低造成的,并提出了一种极其简单的基于点的数据增强策略:在每次迭代中,我们不是对一个BOX使用所有可用的地面真相点,而是在每次训练迭代中对所有可用点进行子采样(P10的GT为5点)

模型
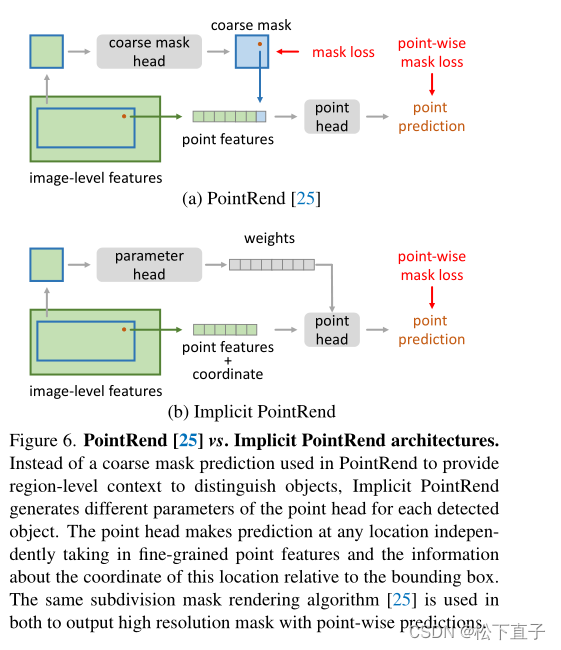
PointRend
为连接两种特征类型的点构造特征表示
(1)通过双线性插值从图像级特征图(例如FPN级特征图)中提取的精确位置的细粒度点表示
(2)对提供特定区域信息的点进行粗掩码预测
Implicit PointRend
使用point head进行逐点掩码预测。
新模型不再依赖于粗糙的掩码预测来区分不同的实例,而是为每个实例生成不同的point head参数。point head的参数隐式表示为对象的MASK,细粒度的点特征仍然和原始设计相同。为了进行掩码预测,point head取该点相对于它所属的边界框的坐标。
选择推理和训练时的点
隐式PointRend在推理时遵循与PointRend相同的选点策略,即自适应细分
在训练过程中,PointRend通过重要抽样策略从粗掩码预测的不确定区域中选择更多的点
隐式PointRend自然适合于点监督,其中我们只需选择具有ground truth注释的点。与掩码R-CNN类似,我们忽略预测框外的点。
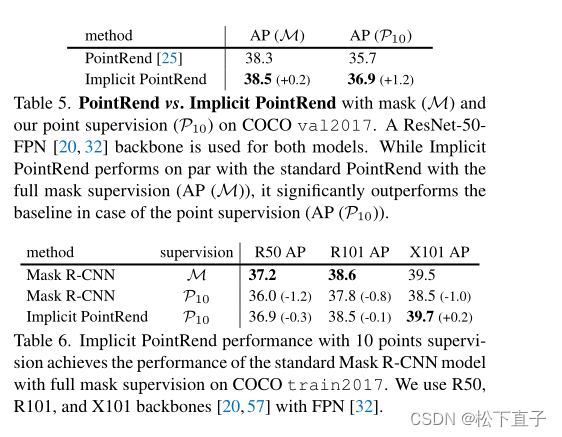
实验结果





![责任链设计模式(Chain of Responsibility Pattern)[论点:概念、组成角色、图示、相关代码、框架中的运用、适用场景]](https://img-blog.csdnimg.cn/39f8d82ec1fa4c6b9a0663c1f5f84eff.png)