目录
- 1. 前言
- 2. Xpath
- 2.1 插件/库安装
- 2.2 基础使用
- 2.3 Xpath表达式
- 2.4 案例演示
- 2.4.1 某度网站案例
- 3. JsonPath
- 3.1 库安装
- 3.2 基础使用
- 3.2 JsonPath表达式
- 3.3 案例演示
- 4. BeautifulSoup
- 4.1 库安装
- 4.2 基础使用
- 4.3 常见方法
- 4.4 案例演示
- 参考文献
原文地址:https://www.program-park.top/2023/04/13/reptile_2/
1. 前言
在上一篇博客中,讲了如何使用 urllib 库爬取网页的数据,但是根据博客流程去操作的人应该能发现,我们爬取到的数据是整个网页返回的源码,到手的数据对我们来说是又乱又多的,让我们不能快速、准确的定位到所需数据,所以,这一篇就来讲讲如何对爬取的数据进行解析,拿到我们想要的部分。
下面会依次讲解目前市场上用的比较多的解析数据的三种方式:Xpath、JsonPath、BeautifulSoup,以及这三种方式的区别。
2. Xpath
XPath(XML Path Language - XML路径语言),它是一种用来确定 XML 文档中某部分位置的语言,以 XML 为基础,提供用户在数据结构树中寻找节点的能力,Xpath 被很多开发者亲切的称为小型查询语言。
2.1 插件/库安装
首先,我们要安装 Xpath Helper 插件,借助 Xpath Helper 插件可以帮助我们快速准确的定位并获取 Xpath 路径,解决无法正常定位 Xpath 路径的问题,链接如下:https://pan.baidu.com/s/1tXW9ZtFDDiH5ZCIEpx2deQ,提取码:6666 。
安装教程如下:
- 打开 Chrome 浏览器,点击右上角小圆点 → 更多工具 → 扩展程序;

- 拖拽 Xpath 插件到扩展程序中(需开启开发者模式);
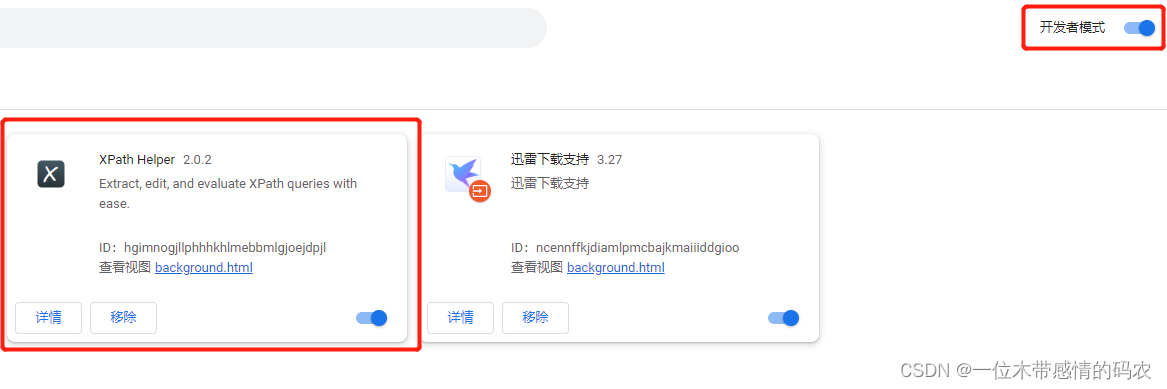
- 关闭浏览器重新打开,打开
www.baidu.com,使用快捷键ctrl + shift + x,出现小黑框即代表安装完毕。
安装 Xpath Helper 插件后,我们还需要在本地的 Python 环境上安装 lxml 库,命令如下:pip3 install lxml。

2.2 基础使用
首先,我们打开Pycharm,创建新脚本,实例化一个etree的对象,并将被解析的页面源码数据加载到该对象中。在用 Xpath 解析文件时,会有两种情况,一种是将本地的文档源码数据加载到etree中:
from lxml import etree
# 解析本地文件
tree = etree.parse('XXX.html')
tree.xpath('Xpath表达式')
另一种是将从互联网上获取的源码数据加载到etree中:
from lxml import etree
# 解析互联网页面源码数据
tree = etree.HTML(response.read().decode('utf‐8'))
tree.xpath('Xpath表达式')
使用 Xpath 解析数据,最重要的便是 Xpath 表达式的书写,对 Xpath 表达式的熟悉程度将直接影响到数据解析的效率和精确度。
2.3 Xpath表达式
| 表达式 | 描述 |
|---|---|
| / | 表示的是从根节点开始定位,表示的是一个层级 |
| // | 表示的是多个层级,可以表示从任意位置开始定位 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是 text 节点 |
示例:
| 路径表达式 | 描述 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore(加入路径起始于 /,则此路径始终代表到某元素的绝对路径) |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素 |
| bookstore/book[1] | 选取属于 bookstore 的子元素的第一个 book 元素 |
| bookstore/book[last()] | 选取属于 bookstore 的子元素的最后一个 book 元素 |
| bookstore/book[last()-1] | 选取属于 bookstore 的子元素的倒数第二个 book 元素 |
| bookstore/book[position()<3] | 选取属于 bookstore 的子元素的前两个 book 元素 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于 bookstore 元素的后代的素有 book 元素,而不管它们位于 bookstore 之下的什么位置 |
| //@lang | 选取名为 lang 的所有属性 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素 |
| //title[@lang='eng'] | 选取所有title元素,且这些元素拥有值为 eng 的 lang 属性 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
| //book/title | //book/price | 选取 book 元素的所有 title 或 price 元素 |
| child::book | 选取所有属于当前节点的子元素的 book 节点 |
| attribute::lang | 选取当前节点的 lang 属性 |
| child::* | 选取当前节点的所有子元素 |
| attribute::* | 选取当前节点的属性 |
| child::text() | 选取当前节点的所有文本子节点 |
| child::node() | 选取当前节点的所有子节点 |
| descendant::book | 选取当前节点的所哟 book 后代 |
| ancestor::book | 选择当前节点的所有 book 先辈 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child::*/child::price | 选取当前节点的所有 price 孙节点 |
| //li[contains(@id,"h")] | 选取 id 属性中包含 h 的 li 标签(模糊查询) |
| //li[starts-with(@id,"h")] | 选取 id 属性中以 h 为开头的 li 标签 |
| //li[@id="h1" and @class="h2"] | 选取 id 属性为 h1 且 class 属性为 h2 的 li 标签 |
2.4 案例演示
2.4.1 某度网站案例
需求: 获取某度一下。
import urllib.request
from lxml import etree
url = 'https://www.某du.com/'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的路径
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
3. JsonPath
JsonPath 是一种信息抽取类库,是从 JSON 文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript、Python、PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 Xpath 对于 XML。
官方文档:http://goessner.net/articles/JsonPath
3.1 库安装
在本地的 Python 环境上安装 JsonPath 库,命令如下:pip3 install jsonpath。
3.2 基础使用
JsonPath 和 Xpath 的区别在于,JsonPath 只能对本地文件进行操作:
import json
import jsonpath
obj = json.load(open('json文件', 'r', encoding='utf‐8'))
ret = jsonpath.jsonpath(obj, 'jsonpath语法')
3.2 JsonPath表达式
| JsonPath | 释义 |
|---|---|
| $ | 根节点/元素 |
| . 或 [] | 子元素 |
| .. | 递归下降(从 E4X 借用了这个语法) |
| @ | 当前节点/元素 |
| ?() | 应用过滤表达式,一般需要结合 [?(@ )] 来使用 |
| [] | 子元素操作符,(可以在里面做简单的迭代操作,如数据索引,根据内容选值等) |
| [,] | 支持迭代器中做多选,多个 key 用逗号隔开 |
| [start:end:step] | 数组分割操作,等同于切片 |
| () | 脚本表达式,使用在脚本引擎下面 |
更多表达式用法可查看官方文档:http://goessner.net/articles/JsonPath。
3.3 案例演示
需求: 获取淘票票数据。
import json
import jsonpath
import urllib.request
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
'cookie': 'miid=536765677517889060; t=78466542de5dbe84715c098fa2366f87; cookie2=11c90be2b7bda713126ed897ab23e35d; v=0; _tb_token_=ee5863e335344; cna=jYeFGkfrFXoCAXPrFThalDwd; xlly_s=1; tfstk=cdlVBIX7qIdVC-V6pSNwCDgVlVEAa8mxXMa3nx9gjUzPOZeuYsAcXzbAiJwAzG2c.; l=eBxbMUncLj6r4x9hBO5aourza77T6BAb4sPzaNbMiInca6BOT3r6QNCnaDoy7dtjgtCxretPp0kihRLHR3xg5c0c07kqm0JExxvO.; isg=BHBwrClf5nUOJrpxMvRIOGsqQT7CuVQDlydQ-WrHREsaJRDPEsmVk5EbfS1FtQzb',
'referer': 'https://dianying.taobao.com/',
'content-type': 'text/html;charset=UTF-8'
}
def create_request():
res_obj = urllib.request.Request(url="https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1644570795658_173&jsoncallback=jsonp174&action=cityAction&n_s=new&event_submit_doGetAllRegion=true",headers=headers)
return res_obj
def get_context(req_obj):
resp = urllib.request.urlopen(req_obj)
origin_context = resp.read().decode('utf-8')
result = origin_context.split('jsonp174(')[1].split(')')[0]
return result
def download_and_parse(context):
with open('jsonpath_淘票票案例.json','w',encoding='utf-8') as fp:
fp.write(context)
def parse_json():
obj = json.load(open('jsonpath_淘票票案例.json', mode='r', encoding='utf-8'))
region_name_list = jsonpath.jsonpath(obj, '$..regionName')
print(region_name_list)
print(len(region_name_list))
if __name__ == '__main__':
req_obj = create_request()
context = get_context(req_obj)
download_and_parse(context)
parse_json()
4. BeautifulSoup
BeautifulSoup 是 Python 的一个 HTML 的解析库,我们常称之为 bs4,可以通过它来实现对网页的解析,从而获得想要的数据。
在用 BeautifulSoup 库进行网页解析时,还是要依赖解析器,BeautifulSoup 支持 Python 标准库中的 HTML 解析器,除此之外,还支持一些第三方的解析器,如果我们不安装第三方解析器,则会试用 Python 默认的解析器,而在第三方解析器中,我推荐试用 lxml,它的解析速度快、容错能力比较强。
| 解析器 | 使用方法 | 优势 |
|---|---|---|
| Python 标准库 | BeautifulSoup(markup, “html.parser”) | Python 的内置标准库、执行速度适中、文档容错能力强 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”]) 或 BeautifulSoup(markup, “xml”) | 速度快、唯一支持 XML 的解析器 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成 HTML5 格式的文档、不依赖外部扩展 |
4.1 库安装
在本地的 Python 环境上安装 BeautifulSoup 库,命令如下:pip3 install bs4。
4.2 基础使用
from bs4 import BeautifulSoup
# 默认打开文件的编码格式是gbk,所以需要指定打开编码格式
# 服务器响应的文件生成对象
# soup = BeautifulSoup(response.read().decode(), 'lxml')
# 本地文件生成对象
soup = BeautifulSoup(open('1.html'), 'lxml')
BeautifulSoup类基本元素:
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,<p>…</p> 的名字是 ’p’,格式:<tag>.name |
| Attributes | 标签的属性,字典组织形式,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的 Comment 类型 |
4.3 常见方法
soup.title # 获取html的title标签的信息
soup.a # 获取html的a标签的信息(soup.a默认获取第一个a标签,想获取全部就用for循环去遍历)
soup.a.name # 获取a标签的名字
soup.a.parent.name # a标签的父标签(上一级标签)的名字
soup.a.parent.parent.name # a标签的父标签的父标签的名字
type(soup.a) # 查看a标签的类型
soup.a.attrs # 获取a标签的所有属性(注意到格式是字典)
type(soup.a.attrs) # 查看a标签属性的类型
soup.a.attrs['class'] # 因为是字典,通过字典的方式获取a标签的class属性
soup.a.attrs['href'] # 同样,通过字典的方式获取a标签的href属性
soup.a.string # a标签的非属性字符串信息,表示尖括号之间的那部分字符串
type(soup.a.string) # 查看标签string字符串的类型
soup.p.string # p标签的字符串信息(注意p标签中还有个b标签,但是打印string时并未打印b标签,说明string类型是可跨越多个标签层次)
soup.find_all('a') # 使用find_all()方法通过标签名称查找a标签,返回的是一个列表类型
soup.find_all(['a', 'b']) # 把a标签和b标签作为一个列表传递,可以一次找到a标签和b标签
for t in soup.find_all('a'): # for循环遍历所有a标签,并把返回列表中的内容赋给t
print('t的值是:', t) # link得到的是标签对象
print('t的类型是:', type(t))
print('a标签中的href属性是:', t.get('href')) # 获取a标签中的url链接
for i in soup.find_all(True): # 如果给出的标签名称是True,则找到所有标签
print('标签名称:', i.name) # 打印标签名称
soup.find_all('a', href='http://www.xxx.com') # 标注属性检索
soup.find_all(class_='title') # 指定属性,查找class属性为title的标签元素,注意因为class是python的关键字,所以这里需要加个下划线'_'
soup.find_all(id='link1') # 查找id属性为link1的标签元素
soup.head # head标签
soup.head.contents # head标签的儿子标签,contents返回的是列表类型
soup.body.contents # body标签的儿子标签
len(soup.body.contents) # 获得body标签儿子节点的数量
soup.body.contents[1] # 通过列表索引获取第一个节点的内容
type(soup.body.children) # children返回的是一个迭代对象,只能通过for循环来使用,不能直接通过索引来读取其中的内容
for i in soup.body.children: # 通过for循环遍历body标签的儿子节点
print(i.name) # 打印节点的名字
4.4 案例演示
需求: 获取星巴克数据。
from bs4 import BeautifulSoup
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
resp = urllib.request.urlopen(url)
context = resp.read().decode('utf-8')
soup = BeautifulSoup(context,'lxml')
obj = soup.select("ul[class='grid padded-3 product'] div[class='preview circle']")
for item in obj:
completePicUrl = 'https://www.starbucks.com.cn'+item.attrs.get('style').split('url("')[1].split('")')[0]
print(completePicUrl)
参考文献
【1】https://blog.csdn.net/qq_54528857/article/details/122202572
【2】https://blog.csdn.net/qq_46092061/article/details/119777935
【3】https://www.php.cn/python-tutorials-490500.html
【4】https://zhuanlan.zhihu.com/p/313277380
【5】https://blog.csdn.net/xiaobai729/article/details/124079260
【6】https://blog.51cto.com/u_15309652/3154785
【7】https://blog.csdn.net/qq_62789540/article/details/122500983
【8】https://blog.csdn.net/weixin_58667126/article/details/126105955
【9】https://www.cnblogs.com/surpassme/p/16552633.html
【10】https://www.cnblogs.com/yxm-yxwz/p/16260797.html
【11】https://blog.csdn.net/weixin_54542209/article/details/123282142
【12】http://blog.csdn.net/luxideyao/article/details/77802389
【13】https://achang.blog.csdn.net/article/details/122884222
【14】https://www.bbsmax.com/A/gGdXBNBpJ4/
【15】https://www.cnblogs.com/huskysir/p/12425197.html
【16】https://zhuanlan.zhihu.com/p/27645452
【17】https://zhuanlan.zhihu.com/p/533266670
【18】https://blog.csdn.net/qq_39314932/article/details/99338957
【19】https://www.bbsmax.com/A/A7zgADgP54/
【20】https://blog.csdn.net/qq_44690947/article/details/126236736



![责任链设计模式(Chain of Responsibility Pattern)[论点:概念、组成角色、图示、相关代码、框架中的运用、适用场景]](https://img-blog.csdnimg.cn/39f8d82ec1fa4c6b9a0663c1f5f84eff.png)