本章目录:
- 什么是Work Queues
- 模拟场景,使用Work Queues
官网文档:RabbitMQ tutorial - Work Queues — RabbitMQ
一、何为Work Queues
我们先看下它的结构图
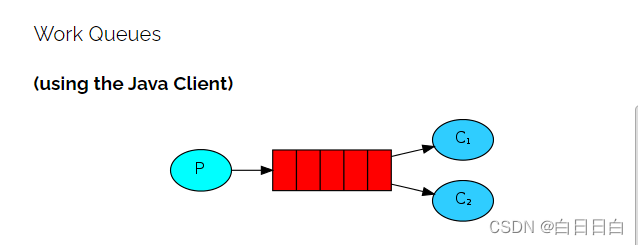
显然,它与入门案例相比只是多了几个消费者。
以下是官方文档说明
In the first tutorial we wrote programs to send and receive messages from a named queue. In this one we'll create a Work Queue that will be used to distribute time-consuming tasks among multiple workers.
The main idea behind Work Queues (aka: Task Queues) is to avoid doing a resource-intensive task immediately and having to wait for it to complete. Instead we schedule the task to be done later. We encapsulate a task as a message and send it to a queue. A worker process running in the background will pop the tasks and eventually execute the job. When you run many workers the tasks will be shared between them.
我大致总结了一下:
工作队列的的主要思想:避免立即执行资源密集型任务,且还需等待它们的完成。而是将任务安排在以后在再去执行,它将任务封装成一条条消息并且发布到队列。如果有多个工作者,它们将共享这些任务
也就是说,当任务量过多,或者任务量过重,我们可以采用Work Queues来提高处理任务的速度
二、模拟场景,使用Work Queues
我们在消费者内使用time.sleep() 来模拟当前任务很“重",“工人”完成它需要耗时更久
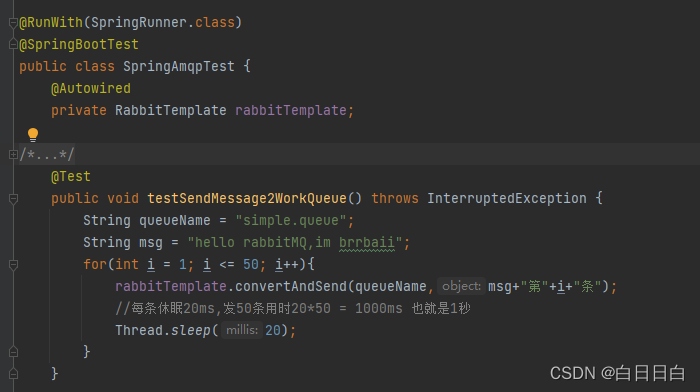
先发布50条任务,每条任务休眠20ms,共计用时1s
接着,创建一个忙工人,和一个轻工人,合作去消费任务
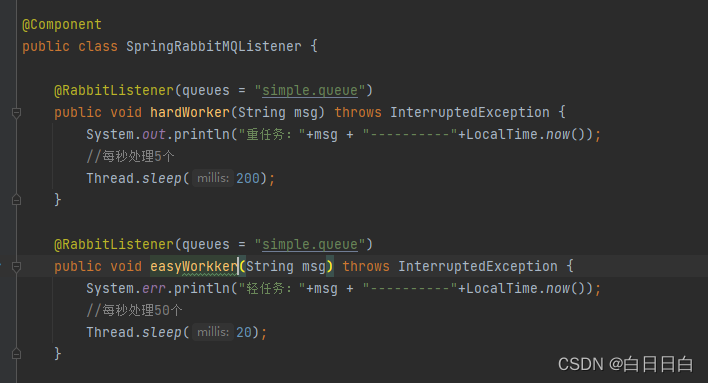
我们预期是轻松工人多消费任务,忙工人少消费任务,能者多劳嘛~
但是结果如下:两个工人完全分享了这些任务,导致了忙的忙的非常忙,轻松的轻松的非常轻松,这显然是不合理的,我们应当是根据每个消费者的性能去分配适量任务。
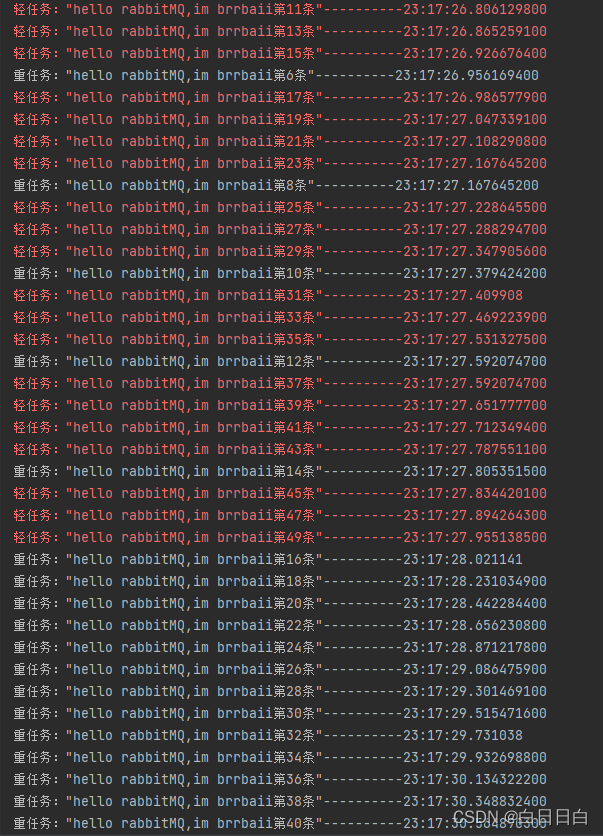
关注后面的时间发现耗时了4秒左右。可是明明我们的easyWoker一秒就可以处理50条消息呀,怎么多加了一个消费者耗时更久了呢? 和官网说的:“当任务量过多,或者任务量过重,我们可以采用Work Queues来提高处理任务的速度”截然相反?
继续观察运行结果:轻工人(性能较高的消费者)确实在1S左右完成了分配给它的任务,但是我们将太多的任务分配给了“重工人”(性能较低的消费者),导致完成全部任务的总体耗时过长
为什么会对半分配任务而不考虑消费者性能呢?我们接着看看官方文档
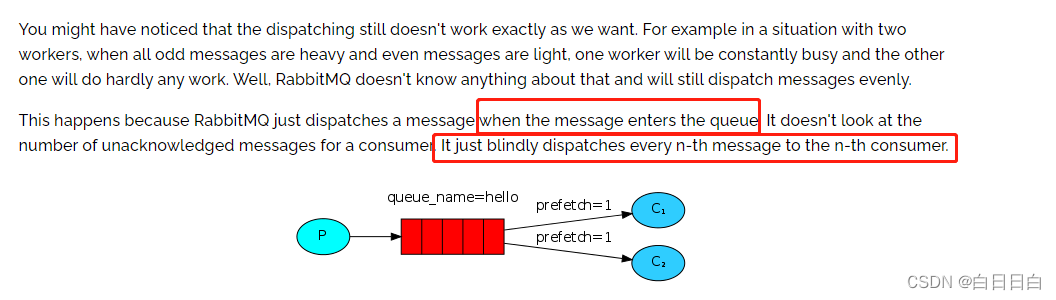
例如,在有两个工人的情况下,当所有的奇数消息都很重,偶数消息都很轻时,一个工人会一直忙碌,而另一个工人几乎不会做任何工作。好吧,RabbitMQ对此一无所知,并且仍然会均匀地发送消息。
之所以会发生这种情况,是因为RabbitMQ只是在消息进入队列时调度消息。它不考虑消费者未确认消息的数量。它只是盲目地将第n条消息发送给第n个消费者。
RabbitMQ只是在消息进入队列的时候就把消息调度给了消费者,并不会考虑消费者未处理消息的数量

我们可以通过 设置prefetch: 1
告诉MQ在发消息之前,观察当前消费者是否已经完成了之前的任务,如果未完成,发送给下一个消费者
我在消费者的yml文件里进行配置
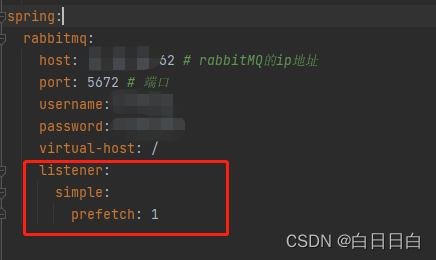
设置后,重新发送消息,并观察消息处理结果
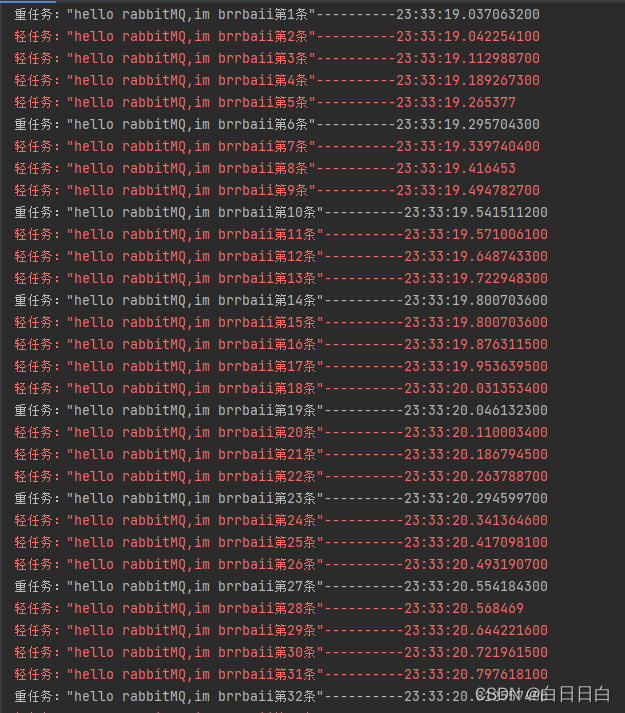
OK,现在可以很明显的看出《能者多劳了》 ,并且任务总耗时也在1S左右完成了
总结:
当任务量过多,或者任务量过重,我们可以采用Work Queues来提高处理任务的速度
通过设置 prefetch: 1,来根据消费者能力协调每个消费者的任务消费数量