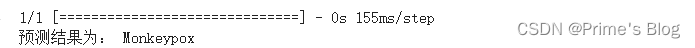各个维度
- 通过模型
- 通过优化器
- 通过batchsize
- 通过数据增强
- 总结
当前网络的博客上都是普遍采用某个迁移学习训练cifar10,无论是vgg,resnet还是其他变种模型,最后通过实例代码,将cifar的acc达到95以上,本篇博客将采用不同的维度去训练cifar10,研究各个维度对cifar10准确率的影响,当然,此篇博客,可能尚不完全准确,如有不对,欢迎指正修改,此篇博客只作为本人实验参考的一部分
通过模型
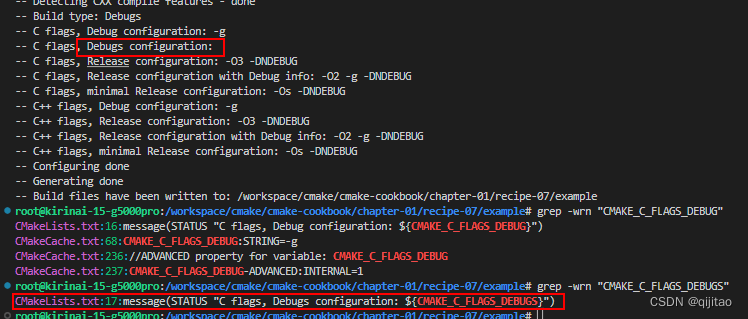
首先,数据集上不变的情况(注意,图片size均为224,loss为交叉熵),第一种考虑的情况自然是模型,现在市场上的分类模型无非就是那么几种,从最小的mobile net到最后的resnet,resnext,desnet等(注意:此处模型不考虑transformer,只考虑cv模型,但是根据排行榜的情况看来,transformer的模型精度效果更高,https://paperswithcode.com/sota/image-classification-on-cifar-10),对于传统模型而言,肯定是模型越大,精度越高,下面我采用torchvision中,最大的两个resnet模型及变体进行了测试,在常规训练20轮后得到以下效果:
resnet152
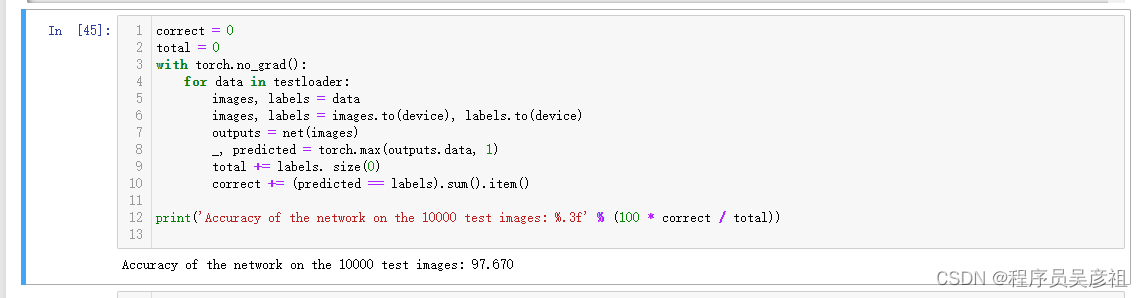
resnext101_32x8d

这两个大模型精度确实高,但是模型本身参数量也很大,大概都在3,40g左右,对于像传统分类数据集而言,如果只追求精度,可以考虑这种情况,下面来试一下小型的模型的精度,以下是测试
vgg16
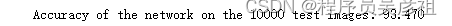
resnet18

moblienetv3

越小的模型同样精度也会稍差一点,如果是一般实验,resnet18看起来就够了
通过优化器
对于优化器而言,这里不采用过多的优化器测试,仅仅使用sgd和adam做测试,所以随便采用一种模型去常规训练即可得到结果
adam

sgd

对于cifar10而言,sgd优化器和adam优化器差异并不大,此次训练中,sgd略优于adam,但是不代表,其他超参数的调整,sgd一直略胜于adam
通过batchsize
由于训练时长原因,这里采用较为简单的resnet18作为测试,通过不同的batchsize,来反应平均loss和acc
| batchsize | loss | acc |
|---|---|---|
| 16 | 0.7 | 94.1 |
| 32 | 0.09 | 94.8 |
| 64 | 0.03 | 95.6 |
| 128 | 0.07 | 95.4 |
最后batchsize为64,当然,其他模型可能反应出不同的效果,上份数据不代表普遍性
通过数据增强
与batchsize一样,下面通过常规的几种数据增强方式,用resnet18作为测试,来反应平均loss和acc(注意:以下数据增强,将采用数据增强后,size统一转为244后,在进行归一化后的操作,也就是T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]))
| batchsize | loss | acc |
|---|---|---|
| T.Resize(256),T.CenterCrop(224), | 0.3 | 95.2 |
| T.RandomGrayscale(p=0.25), | 0.07 | 94.6 |
| T.ColorJitter(hue=.05, saturation=.05), | 0.11 | 93.8 |
| T.RandomResizedCrop((64,64), scale=(0.8, 1)), | 0.07 | 94.5 |
通过表格数据得知,通过放大后,在进行中心裁剪的操作,可以使模型更容易泛化,本人感觉,应该是图形放大后,图像的特征更适合resnet18了,当然了,上份数据不代表普遍性
总结
大模型的参数量高精度更高,对于一般的实验项目而言,想要获得最好的精度,我总结了一下,使用如下配置
backbone:resnet18(在不进行魔改的情况下)
batch_size: 64
数据增强:T.Compose(
[
T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
优化器:sgd
经过50轮迭代训练后,达到如下准确率
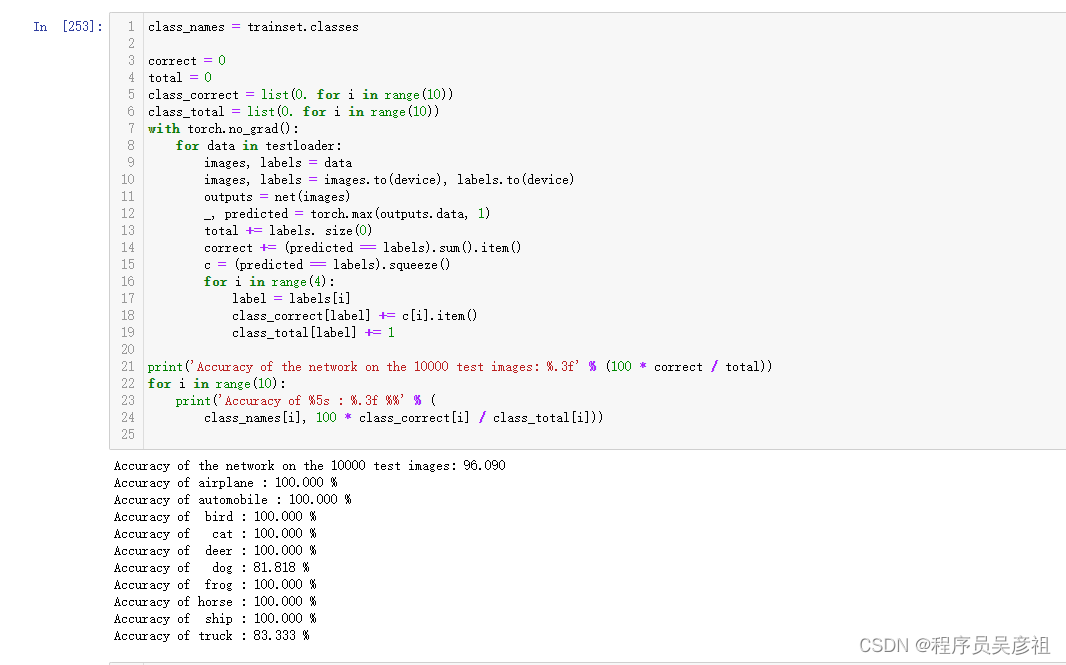
96的准确率,如果将模型换成resnet50或者更大的模型,准确率将会进一步提升