项目背景
钢铁厂生产钢筋的过程中会存在部分钢筋长度超限的问题,如果不进行处理,容易造成机械臂损伤。因此,需要通过质检流程,筛选出存在长度超限问题的钢筋批次,并进行预警。传统的处理方式是人工核查,该方式一方面增加了人工成本,降低了生产效率;另一方面也要求工人师傅对业务比较熟练,能够准确地判断钢筋长度是否超限,且该方法可能存在一定的误判率。在AI时代,利用深度学习技术,可以实现端到端全自动的钢筋长度超限监控,从而降低人工成本,提高生产效率。整体技术方案可以归纳为如下步骤:
-
在钢筋一侧安装摄像头,拍摄图像;
-
利用图像分割技术提取钢筋掩膜;
-
根据摄像头位置和角度确定长度界限;
-
最后根据该长度界限和钢筋分割范围的几何关系判断本批次钢筋是否超限。
 钢筋长度超限监控整体流程
钢筋长度超限监控整体流程
钢筋超限监控问题可以转换为图像分割后的几何判断问题。为了实现图像分割,我们使用提供了全流程分割方案的飞桨图像分割套件 PaddleSeg,只需简单地修改配置文件,就可以进行模型训练,获得高精度的分割效果。进一步地,我们挑选使用精度和速度平衡的 PP-LiteSeg 模型,保证在实现高精度的同时,满足工业部署的要求。

安装环境
使用 PaddleSeg 套件,我们需要准备如下环境:
-
Python >= 3.6
-
飞桨框架>= 2.1
-
PaddleSeg
接下来,使用如下命令安装 PaddleSeg 以及相应的依赖:
git clone --branch release/2.6 --depth 1 https://gitee.com/PaddlePaddle/PaddleSeg.git
cd PaddleSeg
pip install -r requirements.txt
数据处理由于钢筋长度超限检测数据集是使用图像标注工具 LabelMe 标注的,其数据格式与 PaddleSeg 支持的格式不同,因此可借助 PaddleSeg 中 tools 目录下的脚本 labelme2seg.py,将 LabelMe 格式标注转换成 PaddleSeg 支持的格式。
python tools/labelme2seg.py ~/data/dataset接下来,使用 PaddleSeg 提供的脚本(split_dataset_list.py)将数据集划分为训练集、验证集和测试集。
python tools/split_dataset_list.py ~/data/dataset . annotations --split 0.7 0.15 0.15
模型训练
此处我们选择轻量级语义分割模型 PP-LiteSeg 模型,对钢筋进行分割。具体介绍可参考 PP-LiteSeg 的 README 说明文件。
-
说明文件链接
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.7/configs/pp_liteseg
为了在自定义数据集上使用 PP-LiteSeg 模型,需要对 PaddleSeg 提供的默认配置文件(PaddleSeg/configs/pp_liteseg/pp_liteseg_stdc1_cityscapes_1024x512_scale0.5_160k.yml)进行轻微修改。
如下所示,添加自定义数据集路径、类别数等信息:
batch_size: 4 # total: 4*4
iters: 2000
optimizer:
type: sgd
momentum: 0.9
weight_decay: 5.0e-4
lr_scheduler:
type: PolynomialDecay
end_lr: 0
power: 0.9
warmup_iters: 100
warmup_start_lr: 1.0e-5
learning_rate: 0.005
loss:
types:
- type: OhemCrossEntropyLoss
min_kept: 130000 # batch_size * 1024 * 512 // 16
- type: OhemCrossEntropyLoss
min_kept: 130000
- type: OhemCrossEntropyLoss
min_kept: 130000
coef: [1, 1, 1]
train_dataset:
type: Dataset
dataset_root: /home/aistudio/data/dataset
train_path: /home/aistudio/data/dataset/train.txt
num_classes: 2
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.125
max_scale_factor: 1.5
scale_step_size: 0.125
- type: RandomPaddingCrop
crop_size: [1024, 512]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize
mode: train
val_dataset:
type: Dataset
dataset_root: /home/aistudio/data/dataset
val_path: /home/aistudio/data/dataset/val.txt
num_classes: 2
transforms:
- type: Normalize
mode: val
test_config:
aug_eval: True
scales: 0.5
model:
type: PPLiteSeg
backbone:
type: STDC1
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
arm_out_chs: [32, 64, 128]
seg_head_inter_chs: [32, 64, 64]接下来,开始执行训练:
python3 train.py --config /home/aistudio/work/pp_liteseg_stdc1.yml \
--use_vdl \
--save_dir output/mask_iron \
--save_interval 500 \
--log_iters 100 \
--num_workers 8 \
--do_eval \
--keep_checkpoint_max 10使用 PaddleSeg 训练过程中可能会出现报错,例如,one_hot_kernel 相关的报错:
Error: /paddle/paddle/phi/kernels/gpu/one_hot_kernel.cu:38 Assertion `p_in_data[idx] >= 0 && p_in_data[idx] < depth` failed. Illegal index value, Input(input) value should be greater than or equal to 0, and less than depth [1], but received [1].这里需要注意类别是否正确设置,考虑背景类是否添加。one_hot_kernel 另一种报错:
Error: /paddle/paddle/phi/kernels/gpu/one_hot_kernel.cu:38 Assertion `p_in_data[idx] >= 0 && p_in_data[idx] < depth` failed. Illegal index value, Input(input) value should be greater than or equal to 0, and less than depth [5], but received [-1].此时需要注意 mask 中标签是否超过 [0, num_classes + 1] 的范围。训练完成后,可使用模型评估脚本对训练好的模型进行评估:
python val.py \
--config /home/aistudio/work/pp_liteseg_stdc1.yml \
--model_path output/mask_iron/best_model/model.pdparams输出结果为:
2023-03-06 11:22:09 [INFO] [EVAL] #Images: 32 mIoU: 0.9858 Acc: 0.9947 Kappa: 0.9857 Dice: 0.9928
2023-03-06 11:22:09 [INFO] [EVAL] Class IoU:
[0.993 0.9787]
2023-03-06 11:22:09 [INFO] [EVAL] Class Precision:
[0.9969 0.9878]
2023-03-06 11:22:09 [INFO] [EVAL] Class Recall:
[0.996 0.9906]由评估输出可见,模型性能为 mIoU:0.9858,Acc:0.9947,能够满足实际工业场景需求。

模型预测
使用 predict.py 可用来查看具体样本的切割样本效果。
python predict.py \
--config /home/aistudio/work/pp_liteseg_stdc1.yml \
--model_path output/mask_iron/best_model/model.pdparams \
--image_path /home/aistudio/data/dataset/ec539f77-7061-4106-9914-8d66f450234d.jpg \
--save_dir output/result预测的结果如下所示。
import matplotlib.pyplot as plt
import cv2
im = cv2.imread("/home/aistudio/work/PaddleSeg/output/result/pseudo_color_prediction/ec539f77-7061-4106-9914-8d66f450234d.png")
# cv2.imshow("result", im)
plt.imshow(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))
plt.figure()
im = cv2.imread("/home/aistudio/work/PaddleSeg/output/result/added_prediction/ec539f77-7061-4106-9914-8d66f450234d.jpg")
plt.imshow(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))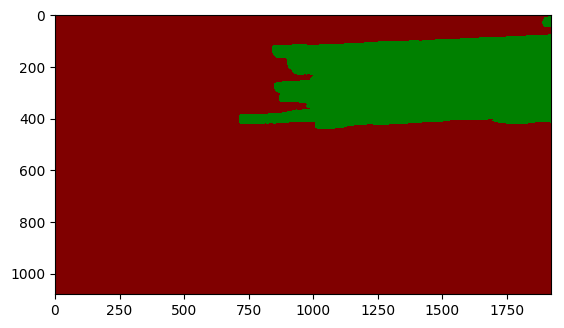

接下来,利用预测的结果,并采用最大联通域处理后,判断钢筋是否超限。
import cv2
def largestcomponent(img_path, threshold=None):
"""
Filter the input image_path with threshold, only component that have area larger than threshold will be kept.
Arg:
img_path: path to a binary img
threshold: connected componet with area larger than this value will be kept
"""
binary = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
binary[binary == binary.min()] = 0
binary[binary == binary.max()] = 255
assert (
binary.max() == 255 and binary.min() == 0
), "The input need to be a binary image, but the maxval in image is {} and the minval in image is {}".format(
binary.max(), binary.min()
)
if threshold is None:
threshold = binary.shape[0] * binary.shape[1] * 0.01
contours, hierarchy = cv2.findContours(
binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE
)
for k in range(len(contours)):
if cv2.contourArea(contours[k]) < threshold:
cv2.fillPoly(binary, [contours[k]], 0)
cv2.imwrite(img_path.split(".")[0] + "_postprocessed.png", binary)
此处,我们可以对比最大联通域处理前后的差别,可以发现滤除了小的联通区域。
prediction = "/home/aistudio/work/PaddleSeg/output/result/pseudo_color_prediction/ec539f77-7061-4106-9914-8d66f450234d.png"
# prediction = "/home/aistudio/work/PaddleSeg/output/result/pseudo_color_prediction/20220705-153804.png"
largestcomponent(prediction)
before_image = cv2.imread(prediction)
after_image = cv2.imread(prediction.replace(".png", "_postprocessed.png"))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(before_image, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(after_image, cv2.COLOR_BGR2RGB))
plt.show()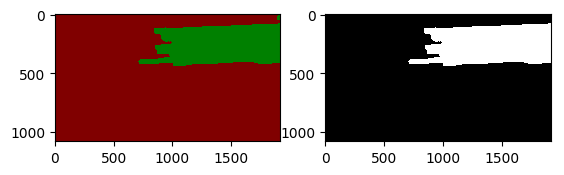
判断钢筋是否超限:
def excesslimit(image_path, direction="right", position=0.6):
"""
Automatically tells if the steel bar excess manually set position.
Arg:
img_path: path to a binary img
direction: which part of the img is the focused area for detecting bar excession.
position: the ratio of the position of the line to the width of the image.
Return:
excess: whether there is steel wheel excess the limit line.
excess_potion: the portion of the excess steel bar to the whole bar.
"""
excess_portion = 0.0
binary = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
binary[binary == binary.min()] = 0
binary[binary == binary.max()] = 255
assert (
binary.max() == 255 and binary.min() == 0
), "The input need to be a binary image, but the maxval in image is {} and the minval in image is {}".format(
binary.max(), binary.min()
)
assert (
direction == "left" or direction == "right"
), "The direction indicates the side of image that iron excess, it should be 'right' or 'left', but we got {}".format(
direction
)
assert (
position > 0 and position < 1
), "The position indicates the relative position to set the line, it should bigger than 0 and smaller than 1, but we got {}".format(
position
)
img_pos = int(binary.shape[1] * position)
if direction == "right":
if binary[:, img_pos:].sum() > 0:
excess_portion = binary[:, img_pos:].sum() / binary.sum()
binary[:, img_pos : img_pos + 3] = 255
else:
if binary[:, :img_pos].sum() > 0:
excess_portion = binary[:, :img_pos].sum() / binary.sum()
binary[:, img_pos - 3 : img_pos] = 255
print(
"The iron is {}excessed in {}, and the excess portion is {}".format(
["", "not "][excess_portion == 0], image_path, excess_portion
)
)
# cv2.imwrite(image_path.split(".")[0] + "_fullpostprocessed.png", binary)
cv2.imwrite(image_path.replace("_postprocessed.png", "_fullpostprocessed.png"), binary)
return excess_portion > 0, excess_portion对预测结果批量判断是否超限。
import os
import glob
output_dir = "/home/aistudio/work/PaddleSeg/output"
pseudo_color_result = os.path.join(output_dir, 'result/pseudo_color_prediction')
os.system(f"rm {pseudo_color_result}/*_*postprocessed.*")
for img_path in glob.glob(os.path.join(pseudo_color_result, "*.png")):
largestcomponent(img_path)
postproc_img_path = img_path.replace(".png", "_postprocessed.png")
excesslimit(postproc_img_path, "left", 0.3)可视化后处理结果。
im = cv2.imread("/home/aistudio/work/PaddleSeg/output/result/pseudo_color_prediction/ec539f77-7061-4106-9914-8d66f450234d_fullpostprocessed.png")
# cv2.imshow("result", im)
plt.imshow(im)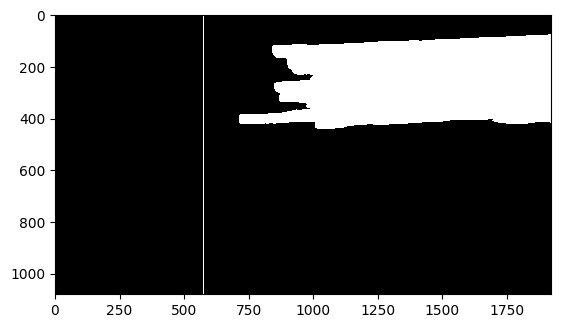

模型推理与部署
我们可以选择使用飞桨原生推理库 Paddle Inference 推理。首先将训练好的模型导出为 Paddle Inference 模型。
export CUDA_VISIBLE_DEVICES=0 # Set a usable GPU.
# If on windows, Run the following command
# set CUDA_VISIBLE_DEVICES=0
python export.py \
--config /home/aistudio/work/pp_liteseg_stdc1.yml \
--model_path output/mask_iron/best_model/model.pdparams \
--save_dir output/inference接下来使用推理模型预测。
python deploy/python/infer.py \
--config output/inference/deploy.yaml \
--save_dir output/infer_result \
--image_path /home/aistudio/data/dataset/bcd33bcd-d48c-4409-940d-51301c8a7697.jpg最后,根据模型输出,判断钢筋是否超限,可视化判断结果。
img_path = "/home/aistudio/work/PaddleSeg/output/infer_result/bcd33bcd-d48c-4409-940d-51301c8a7697.png"
largestcomponent(img_path)
postproc_img_path = img_path.replace(".png", "_postprocessed.png")
excesslimit(postproc_img_path, "right", 0.5)
img_path = "/home/aistudio/work/PaddleSeg/output/infer_result/bcd33bcd-d48c-4409-940d-51301c8a7697_fullpostprocessed.png"
im = cv2.imread(img_path)
plt.imshow(im)我们也可以使用 FastDeploy 进行部署。FastDeploy 是一款全场景、易用灵活、极致高效的AI推理部署工具。其提供开箱即用的云边端部署体验,支持超过160个文本、视觉、语音和跨模态模型,并可实现端到端的推理性能优化。此外,其还可实现包括图像分类、物体检测、图像分割、人脸检测、人脸识别、关键点检测、抠图、OCR、NLP和TTS等任务,满足开发者多场景、多硬件、多平台的产业部署需求。
通过如下命令就可以非常方便地安装 FastDeploy。
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html使用 FastDeploy 进行预测也十分简单:
import fastdeploy as fd
model_file = "/home/aistudio/work/PaddleSeg/output/inference/model.pdmodel"
params_file = "/home/aistudio/work/PaddleSeg/output/inference/model.pdiparams"
infer_cfg_file = "/home/aistudio/work/PaddleSeg/output/inference/deploy.yaml"
# 模型推理的配置信息
option = fd.RuntimeOption()
model = fd.vision.segmentation.PaddleSegModel(model_file, params_file, infer_cfg_file, option)
# 预测结果
import cv2
img_path = "/home/aistudio/data/dataset/8f7fcf0a-a3ea-41f2-9e67-4cbaa61238a4.jpg"
im = cv2.imread(img_path)
result = model.predict(im)
print(result)我们也可以使用 FastDeploy 提供的可视化函数进行可视化。
import matplotlib.pyplot as plt
vis_im = fd.vision.visualize.vis_segmentation(im, result, 0.5)
plt.imshow(cv2.cvtColor(vis_im, cv2.COLOR_BGR2RGB))
接下来判断钢筋是否超限,为了便于演示,兼容上面的判断接口。此处将结果导出为mask图片。
import numpy as np
mask = np.reshape(result.label_map, result.shape)
mask = np.uint8(mask)
mask_path = "/home/aistudio/work/PaddleSeg/output/infer_result/mask.png"
cv2.imwrite(mask_path, mask)
# print(mask_path)
largestcomponent(mask_path)
post_img_path = mask_path.replace(".png", "_postprocessed.png")
# print(post_img_path)
excesslimit(post_img_path, "right", 0.7)
# 可视化判断结果
im_path = "/home/aistudio/work/PaddleSeg/output/infer_result/mask_fullpostprocessed.png"
im = cv2.imread(im_path)
plt.imshow(im)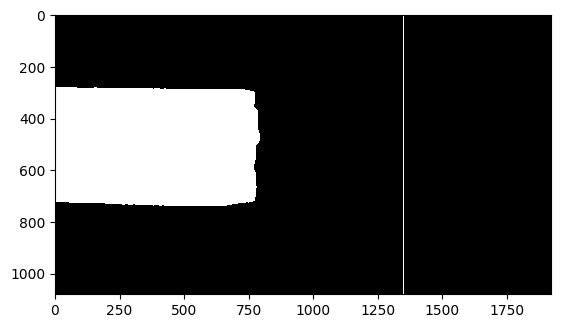

结论
本项目演示了如何在实际工业场景下,使用 PaddleSeg 开发套件进行语义分割模型训练,并使用 FastDeploy 进行部署应用,解决钢筋长度超限的自动监控问题。结果证明,本技术方案切实可行,可实现端到端全自动的钢筋长度超限监控,为企业生产降本增效。希望本应用范例可以给各行业从业人员和开发者带来有益的启发。
![数组(九)-- LC[316][321][402] 去除重复字母](https://img-blog.csdnimg.cn/e615e53a150d408ba816dd107293c694.gif#pic_center)

![[oeasy]python0132_[趣味拓展]emoji_表情符号_抽象话_由来_流汗黄豆](https://img-blog.csdnimg.cn/img_convert/f825b205f79a240e80dff43d6763d507.png)