大家好,我是微学AI,今天给大家讲述一下人工智能(Pytorch)搭建transformer模型,手动搭建transformer模型,我们知道transformer模型是相对复杂的模型,它是一种利用自注意力机制进行序列建模的深度学习模型。相较于 RNN 和 CNN,transformer 模型更高效、更容易并行化,广泛应用于神经机器翻译、文本生成、问答等任务。
一、transformer模型
transformer模型是一种用于进行序列到序列(seq2seq)学习的深度神经网络模型,它最初被应用于机器翻译任务,但后来被广泛应用于其他自然语言处理任务,如文本摘要、语言生成等。
Transformer模型的创新之处在于,在不使用LSTM或GRU等循环神经网络(RNN)的情况下,实现了序列数据的建模,这使得它具有了与RNN相比的许多优点,如更好的并行性、更高的训练速度和更长的序列依赖性。
二、transformer模型的结构
Transformer模型的主要组成部分是自注意力机制(self-attention mechanism)和前馈神经网络(feedforward neural network)。在使用自注意力机制时,模型会根据输入序列中每个位置的信息,生成一个与序列长度相同的向量表示。这个向量表示很好地捕捉了输入序列中每个位置和其他位置之间的关系,从而为模型提供了一个更好的理解输入信息的方式。
在Transformer中,输入序列由多个编码器堆叠而成,在每个编码器中,自注意力机制和前馈神经网络形成了一个块,多个块组成了完整的编码器。为了保持序列的信息,Transformer还使用了一个注意力机制(attention mechanism)来将输入序列中每个位置的信息传递到输出序列中。
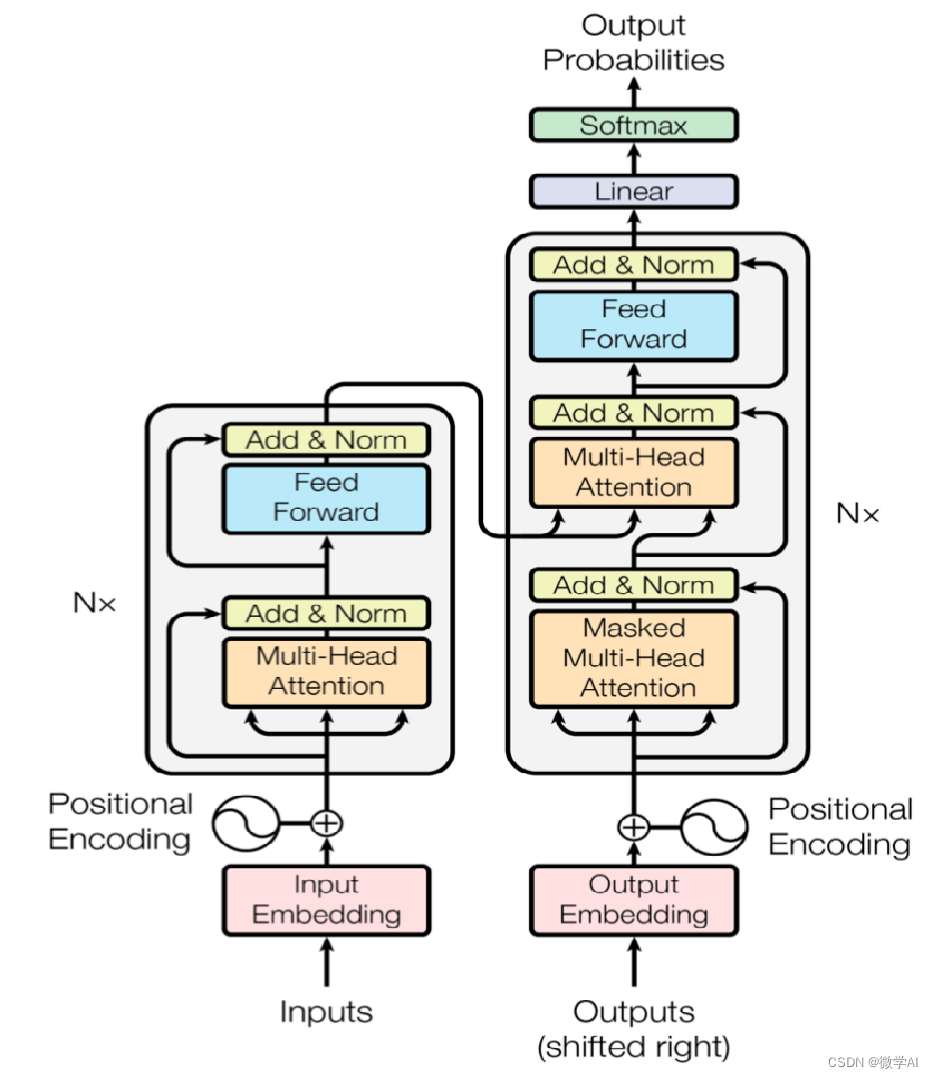
Transformer模型包括部分:
词嵌入层:将每个单词映射到一个向量表示,这个向量表示被称为嵌入向量(embedding vector),词嵌入层也可以使用预训练的嵌入向量。
位置编码:由于Transformer模型没有循环神经网络,因此需要一种方式来处理序列中单词的位置信息。位置编码是一组向量,它们被添加到嵌入向量中,以便模型能够对序列中单词的位置进行编码。
多头自注意力机制:是Transformer模型的核心部分,可以将输入序列中每个位置的信息传递到其他位置,并生成一个与输入序列长度相同的向量表示。
前馈神经网络:在自注意力机制之后,使用一层前馈神经网络来给各个位置的表示添加非线性变换。
残差连接:在自注意力机制和前馈神经网络之间添加了残差连接,来捕捉序列中长距离依赖性。
规范化层:规范化层分为两种:1.在层的维度上进行归一化处理,即对每个样本的所有神经元进行计算,以该样本在所有神经元输出的均值和方差作为归一化的参数。2.在每个mini-batch中进行归一化处理,即对一个mini-batch中所有样本在同一维度上进行归一化处理,然后使用该维度上mini-batch的均值和方差作为归一化的参数。
编码器层:由多个(通常为6-12个)完全相同的块组成,每个块包含一个自注意力机制、一个前馈神经网络和残差连接,用于对输入序列进行编码。
解码器层:在翻译任务中,还需要使用解码器从已经编码的源语言序列中生成目标语言序列。
三、transformer模型的搭建
import math
import torch
import torch.nn as nn
import torch.optim as optim
# 位置编码类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=0.1)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[: x.size(0), :]
return self.dropout(x)
# transformer 模型搭建
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers):
super(TransformerModel, self).__init__()
#词嵌入层
self.embedding = nn.Embedding(ntoken, ninp)
# 位置编码
self.pos_encoder = PositionalEncoding(ninp)
#编码器层
encoder_layers = nn.TransformerEncoderLayer(ninp, nhead, nhid)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, nlayers)
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def init_weights(self):
init_range = 0.1
self.embedding.weight.data.uniform_(-init_range, init_range)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-init_range, init_range)
def forward(self, x):
x = self.embedding(x)
x = self.pos_encoder(x)
x = self.transformer_encoder(x)
x = self.decoder(x)
return x
def data_gen(batch_size=20, seq_len=10, limit=500):
for _ in range(limit):
data = torch.randint(1, 10, (batch_size, seq_len))
targets = data * 2
yield data, targets
if __name__ == "__main__":
ntokens = 20
emsize = 200
nhead = 2
nhid = 200
nlayers = 2
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers)
criterion = nn.CrossEntropyLoss()
lr = 0.001
optimizer = optim.Adam(model.parameters(), lr=lr)
num_epochs = 5
for epoch in range(num_epochs):
for i, (data, targets) in enumerate(data_gen()):
optimizer.zero_grad()
output = model(data)
loss = criterion(output.view(-1, ntokens), targets.view(-1))
loss.backward()
optimizer.step()
if i % 50 == 0:
print(f"Epoch: {epoch}, Loss: {loss.item():.6f}")
# Testing on some data
test_data = torch.tensor([[3, 6, 9], [2, 4, 6]])
print("Test input:", test_data)
test_output = torch.argmax(model(test_data), dim=2)
print("Test output:", test_output)为了让大家更容易掌握,这里编码器和解码器过程直接利用nn.TransformerEncoderLayer,根据transformer编码器的结构中其实是包括:多头自注意力机制,前馈神经网络,残差连接、规范化层的。我们在项目在可以直接引用,进行调整。
为了让每个人跑通Transformer模型,我将输入序列中的每个整数乘以2。数据生成器data_gen函数生成用于训练的随机序列。这里设置了一个较小的词汇表大小为20,表示单词无需太多。
在训练完成后,给出一个简单的测试样例。测试数据包括两个序列[3, 6, 9]和[2, 4, 6]。模型的输出是输入整数加倍的序列。给大家举这个例子只是为了展示如何搭建一个Transformer模型,并在实际任务上完成简单的训练,让我们真正零距离地接触Transformer模型。