kafaka
消息队列:通常用来解决一个进程内,多线程环境下,资源竞争的问题;但是消息队列的锁的粒度太大了,需要进行拆分
消息队列中间组件
一个进程中,同时存在生产者、消费者、消息队列,在分布式系统中,需要把消息队列拆分出来,同时实现消息的持久化、解决幂等性问题。
- 幂等性:网络抖动时,发送多次同样的数据,消息队列应该能过滤去重;同时考虑乱序问题,能让consumer顺序消费消息
分布式系统中,常用服务通信方式的有rpc和消息队列两种,
其中rpc的弊端为:服务A调用服务B的函数,我需要知道B函数的参数以及参数的作用,耦合度太高
消息队列将生产和消费者完全解耦:服务A只给服务B一些消息(消息简单理解就是结构体,也就是包体,但其实也并不是只传数据这么简单),
这些消息中的数据字段的含义以文档提供,这些参数怎么使用,全权由服务B决定
应用场景:
- 异步处理
- 系统解耦
- 流量削峰:后台处理不了那么多请求,就放消息队列里(如12306的排队功能)
- 日志处理:日志一开始存在缓冲,隔一段时间,或者积累到一定数量才写入磁盘
- 生产消费
- 点对点
- 发布订阅
kafaka基本原理
架构图:
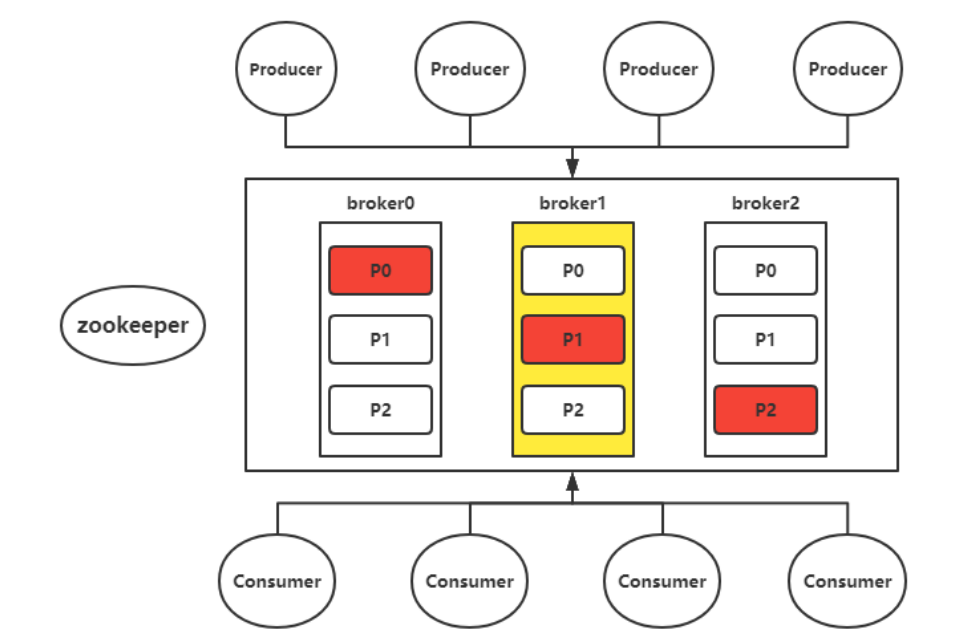
总体上来说,改架构由zookper+kafaka集群组成(zookeeper和etcd都是分布式注册中心)
其中,zk负责注册存储,选举
-
broker: kafka集群由多个broker节点构成,每个节点上都运行着一个kafka实例,
这些实例之间基于zk来发现彼此,并由集群控制器 KafkaController 统筹协调运行,
彼此之间基于socket连接进行通信 -
topic: 将消息分类处理(减少消息队列锁的粒度),以topic的创建为例()
# 一次启动zk、kafaka
# 创建Topic
sh bin/kafaka-topics.sh --create --zookeeper <zookeeper的ip和端口> --replication-factor <副本数>
-- partitions <分区数量> --topic <主题名>
创建主题时,最重要的是指定分区数量,创建的分区越多,消费的并发量越大,吞吐量越高,但到达一定数量,由于broker资源的限制,也无法再继续提高了
- partition:
-
类似数据库的分库分表,分为leader和follower,在kafaka1.0,follower并不提供读的功能,因为follower不能保证同步的数据是最新,但在kafaka2.0版本后,follower已经支持,这使得消费的并发量更大了。
-
每次写partition都要写leader消息队列 (通过查询zk能知道leader在哪).
-
单个p内消息有序,但多个p会使得消息全局乱序,如果要保证全局有序性,一个主题指定一个p.
-
为什么要划分多个分区
- 水平扩展,在本节点资源不够用了,可以在其他节点划分分区
- 并发处理,向一个主题所发送的消息会发送给该主题所拥有的不同的分区中,这样消息就可以实现并行发送与处理,由多个分区来接收所发送的消息
分区与分段
-
repica:副本,也就是follower,副本节点监听leader进行备份
-
消费者组:一个消费者的集合,如一组消费者操作数据库写db,一组消费者用来做数据分析写es
- 消费者组中的消费者数量大于分区数:有些消费者读不了消息队列
- 消费者组中的消费者数量等于分区数:最好的状态,一个消费者读一个分区
- 消费者组中的消费者数量小于分区数:一个消费者读多个分区
tip: 一个组中,一个消费者可以读多个分区,但一个分区只能被一个消费者读 (分区可以被不同消费者组的多个消费者读)
消费者监听一个主题(订单,活动,日志三个主题),当发布者发送了这一类主题消息,消费者就会去处理。
kafaka保证幂等性
给每个生产者一个pid,每次发消息都添加pid+seq,消息队列检查这两个值,如果已经存在了则丢弃,否则发送ack给生产者,生产者收到ack后,seq++
两个选举:
- controller选举:zk实现
- partition选举,由controller实现 => leader尽量分散在不同的broker
- leader:负责数据读写
- foller:负责数据备份,不提供读的功能(2.0版本支持了)
kafaka读写机制
读写策略
生产者:
- High level api:随机、轮询(默认)、哈希{hash(key)%p_num}
- low level api:自己指定分区,ack机制
消费者:主要是保存offset的值,
- High level api:存在kafaka内部的一个主题
- low level api:自己选择存哪(如数据库)
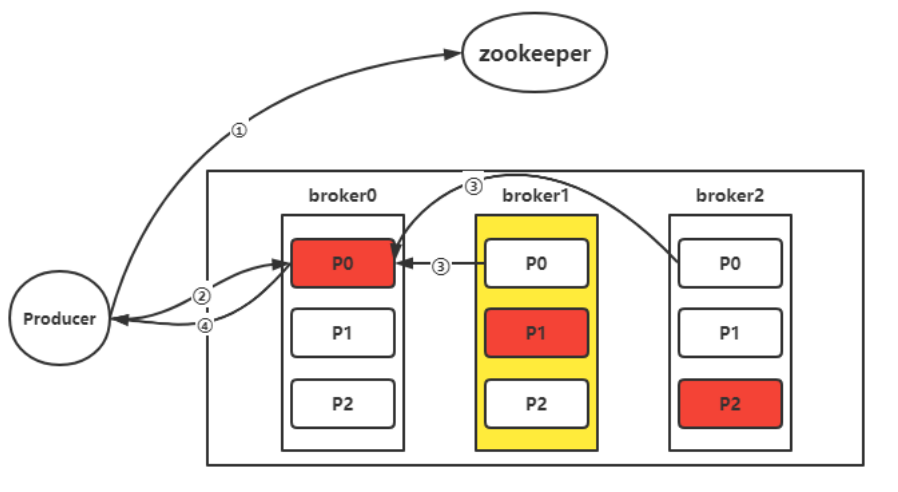
生产者写
生产者先访问zk,得到往哪几个主题写,然后找到主题对应的leader partition,生产者先给它发送个写请求,
ack的值以及对应的吞吐量
- 0:不需要回复,直接写消息队列 20w/s
- 1:无需等待同步
- -1:需要等待副本同步,再回复生产者 8w/s
消费者读
假设消费者是取出消息,操作数据库,其大致流程为:取出消息,数据操作成功,offset偏移,指向下一个消息;
此时,如果数据库操作成功了,但是消费者宕机了,这个消息就会重复消费
解决方法:db操作+offset偏移编程原子操作,将offset存储在db,如果宕机了就回滚
在kafaka1.0,zk存储上一次消息的partition,以及之前的offset(后续版本有一个专门的主题存储offset)
kafaka总结
消息持久化:消息队列的数据默认保存一周,写分区其实就是写多段的日志
读写高吞吐量: 通过节点 + 分区的方式实现负载均衡, 把消息写到不同的节点
高可用:leader所在节点宕机了,会选取新的leader;其他高可用的案例有:
- 数据库:主从复制,主节点宕机,etcd选举新的节点
- redis:去中心化,每个master节点都有两个副本节点,master节点宕机了,另外两个副本节点会选举一个成为新的master节点
工作中遇到的问题
- 有时发现一些日志没有写磁盘,是因为这个日志处于不活跃的segment,然后被清理了吗?kafaka日志清除策略
- 主推消息乱序是因为一个主题建立了多个分区吗?