🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
编码器-解码器框架
注意力机制
NLP 中的迁移学习
Hugging Face Transformers: Bridging the Gap
Transformer应用之旅
文本分类
命名实体识别
问答
总结
翻译
文本生成
拥抱脸生态系统
The Hugging Face Hub
拥抱面部标记器
拥抱人脸数据集
拥抱脸加速
Transformers的主要挑战
结论
2017 年,谷歌的研究人员发表了一篇论文,提出了一种用于序列建模的新型神经网络架构。1 被称为Transformer,这种架构在机器翻译任务上的表现优于循环神经网络 (RNN),无论是在翻译质量还是培训成本方面。
同时,一种称为 ULMFiT 的有效迁移学习方法表明,在非常大且多样化的语料库上训练长短期记忆 (LSTM) 网络可以产生最先进的文本分类器,而标记数据很少。2
这些进步是当今最著名的两个变压器的催化剂:生成式预训练变压器 (GPT) 3和变压器的双向编码器表示 (BERT)。4通过将 Transformer 架构与无监督学习相结合,这些模型消除了从头开始训练特定任务架构的需要,并大大打破了 NLP 中的几乎所有基准。自 GPT 和 BERT 发布以来,出现了一个变压器模型动物园;图 1-1显示了最突出的条目的时间线 。
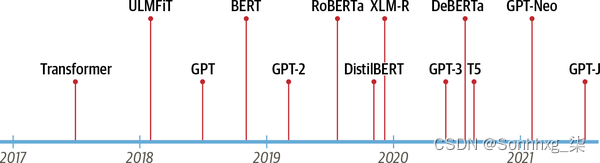
图 1-1。 transformers时间线
但我们正在超越自己。要了解变压器的新颖之处,我们首先需要解释一下:
-
编码器-解码器框架
-
注意力机制
-
迁移学习
在本章中,我们将介绍 Transformer 普遍存在的核心概念,了解他们擅长的一些任务,并以 Hugging Face 工具和库生态系统作为结束。
让我们从探索编码器-解码器框架和变压器兴起之前的架构开始。
编码器-解码器框架
在 Transformer 之前,循环架构(如 LSTM)是 NLP 中的最新技术。这些架构在网络连接中包含一个反馈循环,允许信息从一个步骤传播到另一个步骤,使其非常适合对文本等顺序数据进行建模。如图 1-2左侧所示,RNN 接收一些输入(可能是单词或字符),将其输入到网络中,并输出一个称为隐藏状态的向量。同时,模型通过反馈回路将一些信息反馈给自己,然后可以在下一步中使用。如果我们如图 1-2右侧所示“展开”循环,则可以更清楚地看到这一点 :RNN 在每一步将有关其状态的信息传递给序列中的下一个操作。这允许 RNN 跟踪来自先前步骤的信息,并将其用于其输出预测。
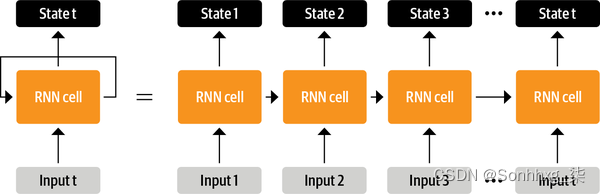
图 1-2。及时展开 RNN
这些架构曾(并将继续)广泛用于 NLP 任务、语音处理和时间序列。您可以在 Andrej Karpathy 的博客文章“循环神经网络的不合理有效性”中找到对它们能力的精彩阐述 。
通常,编码器和解码器组件可以是可以对序列进行建模的任何类型的神经网络架构。图 1-3中的一对 RNN 对此进行了说明,其中英文句子“Transformers are great!” 被编码为隐藏状态向量,然后被解码以产生德语翻译“Transformer sind Grossartig!” 输入字通过编码器顺序输入,输出字从上到下一次生成一个。
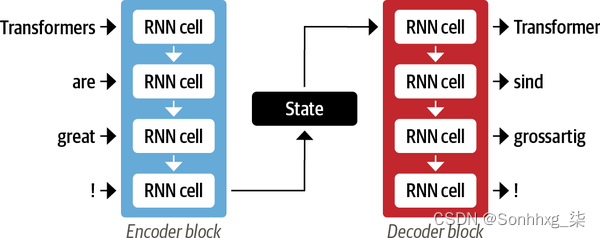
图 1-3。具有一对 RNN 的编码器-解码器架构(通常,循环层比这里显示的要多得多)
尽管其简单性很优雅,但这种架构的一个缺点是编码器的最终隐藏状态会产生信息瓶颈:它必须表示整个输入序列的含义,因为这是解码器在生成输出时可以访问的所有内容。这对于长序列尤其具有挑战性,因为在将所有内容压缩为单个固定表示的过程中,序列开头的信息可能会丢失。
幸运的是,通过允许解码器访问编码器的所有隐藏状态,有办法摆脱这个瓶颈。对此的一般机制称为 注意力6,它是许多现代神经网络架构中的关键组件。了解如何为 RNN 开发注意力将使我们能够很好地理解 Transformer 架构的主要构建块之一。让我们更深入地了解一下。
注意力机制
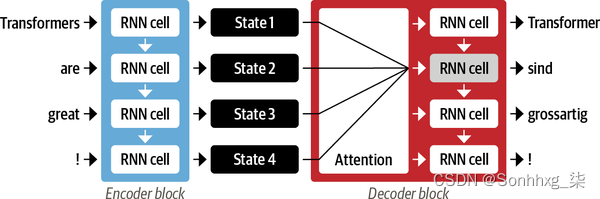
图 1-4。具有用于一对 RNN 的注意力机制的编码器-解码器架构
通过关注每个时间步最相关的输入标记,这些基于注意力的模型能够学习生成的翻译中的单词和源句中的单词之间的非平凡对齐。例如,图 1-5可视化了英语到法语翻译模型的注意力权重,其中每个像素表示一个权重。该图显示了解码器如何正确对齐单词“zone”和“Area”,这两种语言的顺序不同。

图 1-5。RNN 编码器-解码器对齐英语单词和生成的法语翻译(由 Dzmitry Bahdanau 提供)
尽管注意力能够产生更好的翻译,但在编码器和解码器中使用循环模型仍然存在一个主要缺点:计算本质上是顺序的,不能跨输入序列并行化。
Transformer 引入了一种新的建模范式:完全不用递归,而是完全依赖一种称为self-attention的特殊形式的注意力。我们将在第 3 章中更详细地介绍 self-attention ,但基本思想是让 attention 作用于 神经网络同一层中的所有状态。如图 1-6所示 ,编码器和解码器都有自己的自注意力机制,其输出被馈送到前馈神经网络 (FF NN)。这种架构可以比循环模型更快地训练,并为最近 NLP 的许多突破铺平了道路。
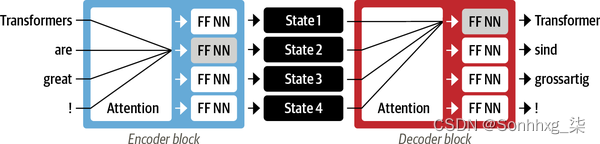
图 1-6。原始 Transformer 的编码器-解码器架构
在最初的 Transformer 论文中,翻译模型是在各种语言的大量句子对上从头开始训练的。然而,在 NLP 的许多实际应用中,我们无法访问大量标记的文本数据来训练我们的模型。让变压器革命开始的最后一件事情是:迁移学习。
NLP 中的迁移学习
如今,计算机视觉领域的常见做法是使用迁移学习在一项任务上训练像 ResNet 这样的卷积神经网络,然后在一项新任务上对其进行调整或微调。这允许网络利用从原始任务中学到的知识。在架构上,这涉及将模型拆分为body和head,其中 head 是特定于任务的网络。在训练期间,身体的权重学习源域的广泛特征,这些权重用于为新任务初始化新模型。7与传统的监督学习相比,这种方法通常会产生高质量的模型,这些模型可以在各种下游任务上更有效地训练,并且标记数据要少得多。两种方法的比较 如图 1-7所示。
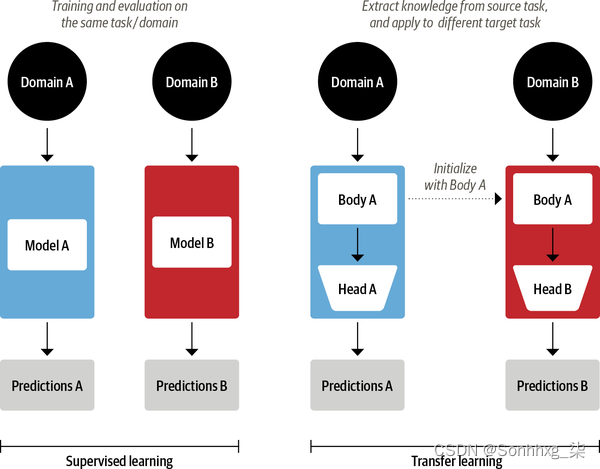
图 1-7。传统监督学习(左)与迁移学习(右)的比较
在计算机视觉中,模型首先在包含数百万张图像的ImageNet等大规模数据集上进行训练。这个过程称为预训练,其主要目的是教模型图像的基本特征,例如边缘或颜色。然后可以在下游任务上对这些预训练模型进行微调,例如使用相对较少的标记示例(通常每类几百个)对花卉种类进行分类。与在相同数量的标记数据上从头开始训练的监督模型相比,微调模型通常可以实现更高的准确度。
尽管迁移学习成为计算机视觉的标准方法,但多年来,对于 NLP 来说,类似的预训练过程是什么并不清楚。因此,NLP 应用程序通常需要大量标记数据来实现高性能。即便如此,该性能也无法与视觉领域的成就相提并论。
在 2017 年和 2018 年,几个研究小组提出了新的方法,最终使迁移学习适用于 NLP。它始于 OpenAI 研究人员的见解,他们通过使用从无监督预训练中提取的特征在情感分类任务上获得了强大的性能。8紧随其后的是 ULMFiT,它引入了一个通用框架,以使预训练的 LSTM 模型适应各种任务。9
最初的训练目标非常简单:根据前面的单词预测下一个单词。此任务称为语言建模。这种方法的优点在于不需要标记数据,并且可以利用来自维基百科等来源的大量可用文本。10
一旦语言模型在大规模语料库上进行了预训练,下一步就是将其适应域内语料库(例如,从维基百科到电影评论的 IMDb 语料库, 如图 1-8 所示)。这个阶段仍然使用语言建模,但现在模型必须预测目标语料库中的下一个单词。
在这一步中,语言模型通过目标任务的分类层进行微调(例如,对图 1-8中的电影评论情绪进行分类)。
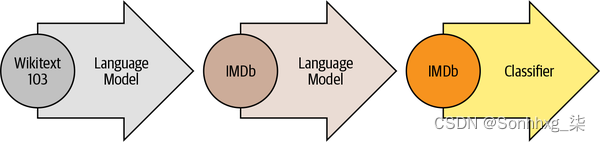
图 1-8。ULMFiT 流程(由 Jeremy Howard 提供)
通过在 NLP 中引入一个可行的预训练和迁移学习框架,ULMFiT 提供了使 Transformer 起飞的缺失部分。2018 年,发布了两个将 self-attention 与迁移学习相结合的 Transformer:
仅使用 Transformer 架构的解码器部分,以及与 ULMFiT 相同的语言建模方法。GPT 在 BookCorpus 11上进行了预训练,其中包括 7,000 本未出版的书籍,这些书籍来自各种类型,包括冒险、奇幻和浪漫。
使用 Transformer 架构的编码器部分,以及一种称为掩码语言建模的特殊语言建模形式。掩码语言建模的目的是预测文本中随机掩码的单词。例如,给定一个句子,如“我看了看我的 [MASK],发现[MASK]已经晚了”。该模型需要预测由 表示的掩码词的最可能候选者 [MASK]。BERT 在 BookCorpus 和英语 维基百科上进行了预训练。
GPT 和 BERT 在各种 NLP 基准测试中树立了最先进的技术水平,并开启了变形金刚时代。
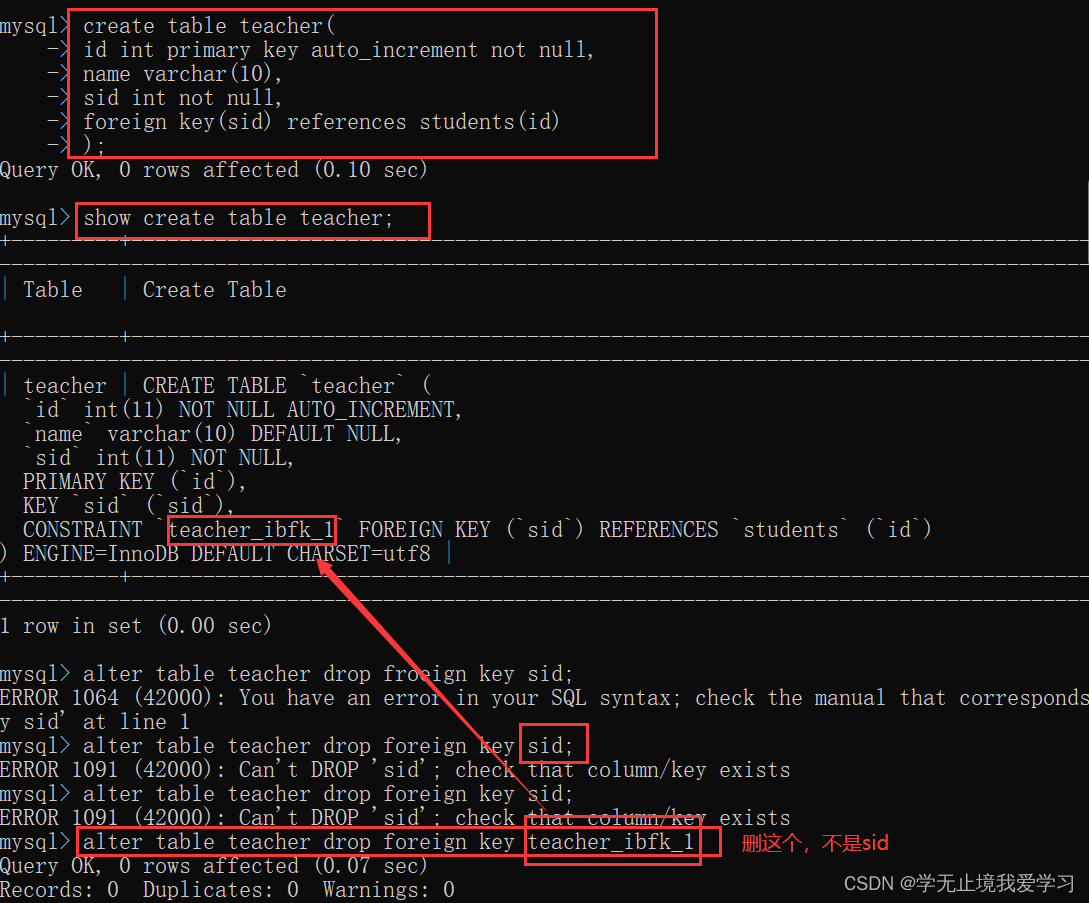
然而,随着不同的研究实验室在不兼容的框架(PyTorch 或 TensorFlow)中发布他们的模型,NLP 从业者将这些模型移植到他们自己的应用程序中并不总是那么容易。随着![]() Transformers的发布,一个跨越 50 多个架构的统一 API 逐步构建。这个库促进了对变压器研究的爆炸式增长,并迅速渗透到 NLP 从业者身上,使得将这些模型轻松集成到当今许多现实生活中的应用程序中变得很容易。我们来看一下!
Transformers的发布,一个跨越 50 多个架构的统一 API 逐步构建。这个库促进了对变压器研究的爆炸式增长,并迅速渗透到 NLP 从业者身上,使得将这些模型轻松集成到当今许多现实生活中的应用程序中变得很容易。我们来看一下!
Hugging Face Transformers: Bridging the Gap
将新颖的机器学习架构应用于新任务可能是一项复杂的工作,通常涉及以下步骤:
-
在代码中实现模型架构,通常基于 PyTorch 或 TensorFlow。
-
从服务器加载预训练的权重(如果可用)。
-
预处理输入,将它们传递给模型,并应用一些特定于任务的后处理。
-
实现数据加载器并定义损失函数和优化器来训练模型。
这些步骤中的每一个都需要为每个模型和任务定制逻辑。传统上(但并非总是如此!),当研究小组发布新文章时,他们也会发布代码以及模型权重。但是,此代码很少标准化,并且通常需要数天的工程才能适应新的用例。
这就是![]() 变形金刚来拯救 NLP 实践者的地方!它为各种变压器模型以及使这些模型适应新用例的代码和工具提供了标准化接口。该库目前支持三种主要的深度学习框架(PyTorch、TensorFlow 和 JAX),并允许您在它们之间轻松切换。此外,它还提供了特定于任务的头,因此您可以轻松地在文本分类、命名实体识别和问答等下游任务上微调转换器。这将从业者训练和测试少数模型所需的时间从一周缩短到一个下午!
变形金刚来拯救 NLP 实践者的地方!它为各种变压器模型以及使这些模型适应新用例的代码和工具提供了标准化接口。该库目前支持三种主要的深度学习框架(PyTorch、TensorFlow 和 JAX),并允许您在它们之间轻松切换。此外,它还提供了特定于任务的头,因此您可以轻松地在文本分类、命名实体识别和问答等下游任务上微调转换器。这将从业者训练和测试少数模型所需的时间从一周缩短到一个下午!
您将在下一节中亲自看到这一点,我们将在其中展示只需几行代码,![]() Transformers 就可以用于处理您可能在野外遇到的一些最常见的 NLP 应用程序。
Transformers 就可以用于处理您可能在野外遇到的一些最常见的 NLP 应用程序。
Transformer应用之旅
每个 NLP 任务都以一段文本开头,例如以下关于某个在线订单的虚构客户反馈:
text = """Dear Amazon, last week I ordered an Optimus Prime action figure
from your online store in Germany. Unfortunately, when I opened the package,
I discovered to my horror that I had been sent an action figure of Megatron
instead! As a lifelong enemy of the Decepticons, I hope you can understand my
dilemma. To resolve the issue, I demand an exchange of Megatron for the
Optimus Prime figure I ordered. Enclosed are copies of my records concerning
this purchase. I expect to hear from you soon. Sincerely, Bumblebee."""根据您的应用程序,您正在使用的文本可能是法律合同、产品描述或其他内容。在客户反馈的情况下,您可能想知道反馈是正面的还是负面的。这项任务称为 情感分析,是我们将在 第 2 章探讨的更广泛的文本分类主题的一部分。现在,让我们看看如何使用![]() Transformers 从我们的一段文本中提取情绪。
Transformers 从我们的一段文本中提取情绪。
文本分类
正如我们将在后面的章节中看到的, ![]() Transformers 有一个分层的 API,允许您在不同的抽象级别与库进行交互。在本章中,我们将从管道开始,它抽象出将原始文本转换为来自微调模型的一组预测所需的所有步骤。
Transformers 有一个分层的 API,允许您在不同的抽象级别与库进行交互。在本章中,我们将从管道开始,它抽象出将原始文本转换为来自微调模型的一组预测所需的所有步骤。
在Transformers 中,我们通过调用函数并提供我们感兴趣的任务的名称来![]() 实例化管道:
实例化管道:pipeline()
from transformers import pipeline
classifier = pipeline("text-classification")第一次运行此代码时,您会看到一些进度条出现,因为管道会自动从Hugging Face Hub下载模型权重。第二次实例化管道时,库会注意到您已经下载了权重,并将使用缓存的版本。默认情况下,text-classification管道使用专为情感分析而设计的模型,但它也支持多类和多标签分类。
现在我们有了管道,让我们生成一些预测!每个管道都将一个文本字符串(或一个字符串列表)作为输入,并返回一个预测列表。每个预测都是一个 Python 字典,因此我们可以使用 Pandas 将它们很好地显示为 DataFrame:
import pandas as pd
outputs = classifier(text)
pd.DataFrame(outputs)| label | score | |
|---|---|---|
| 0 | NEGATIVE | 0.901546 |
在这种情况下,模型非常确信文本具有负面情绪,考虑到我们正在处理来自愤怒客户的投诉,这是有道理的!请注意,对于情绪分析任务,管道仅返回一个POSITIVE或NEGATIVE标签,因为另一个可以通过计算推断1-score。
现在让我们看看另一个常见的任务,识别文本中的命名实体。
命名实体识别
预测客户反馈的情绪是很好的第一步,但您通常想知道反馈是否与特定项目或服务有关。在 NLP 中,产品、地点和人等现实世界的对象称为命名实体,从文本中提取它们称为 命名实体识别(NER)。我们可以通过加载相应的管道并将我们的客户评论反馈给它来应用 NER:
ner_tagger = pipeline("ner", aggregation_strategy="simple")
outputs = ner_tagger(text)
pd.DataFrame(outputs)| entity_group | score | word | start | end | |
|---|---|---|---|---|---|
| 0 | ORG | 0.879010 | Amazon | 5 | 11 |
| 1 | MISC | 0.990859 | Optimus Prime | 36 | 49 |
| 2 | LOC | 0.999755 | Germany | 90 | 97 |
| 3 | MISC | 0.556569 | Mega | 208 | 212 |
| 4 | PER | 0.590256 | ##tron | 212 | 216 |
| 5 | ORG | 0.669692 | Decept | 253 | 259 |
| 6 | MISC | 0.498350 | ##icons | 259 | 264 |
| 7 | MISC | 0.775361 | Megatron | 350 | 358 |
| 8 | MISC | 0.987854 | Optimus Prime | 367 | 380 |
| 9 | PER | 0.812096 | Bumblebee | 502 | 511 |
您可以看到管道检测到所有实体,并且还为每个实体分配了一个类别,例如ORG(组织)、LOC(位置)或 PER(人员)。在这里,我们使用aggregation_strategy 参数根据模型的预测对单词进行分组。例如,实体“擎天柱”由两个词组成,但被分配了一个类别:(MISC 杂项)。分数告诉我们模型对其识别的实体的信心程度。我们可以看到,它对“霸天虎”和第一次出现的“威震天”最没有信心,这两者都未能归类为一个实体。
提取文本中的所有命名实体很好,但有时我们想提出更有针对性的问题。这是我们可以使用 问答的地方。
问答
在问答中,我们为模型提供了一段称为context的文本,以及一个我们想要提取其答案的问题。然后模型返回与答案对应的文本范围。让我们看看当我们询问有关客户反馈的特定问题时会得到什么:
reader = pipeline("question-answering")
question = "What does the customer want?"
outputs = reader(question=question, context=text)
pd.DataFrame([outputs])| score | start | end | answer | |
|---|---|---|---|---|
| 0 | 0.631291 | 335 | 358 | an exchange of Megatron |
通过这种方法,您可以从客户的反馈中快速读取和提取相关信息。但是,如果您收到一大堆冗长的投诉而您没有时间阅读它们怎么办?让我们看看总结模型是否有帮助!
总结
文本摘要的目标是将长文本作为输入,并生成包含所有相关事实的简短版本。这是一项比以前的任务复杂得多的任务,因为它需要模型生成连贯的文本。以现在应该熟悉的模式,我们可以实例化一个汇总管道,如下所示:
summarizer = pipeline("summarization")
outputs = summarizer(text, max_length=45, clean_up_tokenization_spaces=True)
print(outputs[0]['summary_text'])Bumblebee ordered an Optimus Prime action figure from your online store in Germany. Unfortunately, when I opened the package, I discovered to my horror that I had been sent an action figure of Megatron instead.
这个总结还不错!虽然复制了部分原文,但该模型能够抓住问题的本质,并正确识别出“大黄蜂”(出现在最后)是投诉的作者。max_length在此示例中,您还 可以看到我们将一些关键字参数传递clean_up_tokenization_spaces给管道;这些允许我们在运行时调整输出。
但是,当您收到使用您不懂的语言的反馈时会发生什么?您可以使用谷歌翻译,也可以使用自己的转换器为您翻译!
翻译
与摘要一样,翻译是一项输出由生成的文本组成的任务。让我们使用翻译管道将英文文本翻译成德文:
translator = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de")
outputs = translator(text, clean_up_tokenization_spaces=True, min_length=100)
print(outputs[0]['translation_text'])Sehr geehrter Amazon, letzte Woche habe ich eine Optimus Prime Action Figur aus Ihrem Online-Shop in Deutschland bestellt. Leider, als ich das Paket öffnete, entdeckte ich zu meinem Entsetzen, dass ich stattdessen eine Action Figur von Megatron geschickt worden war! Als lebenslanger Feind der Decepticons, Ich hoffe, Sie können mein Dilemma verstehen. Um das Problem zu lösen, Ich fordere einen Austausch von Megatron für die Optimus Prime Figur habe ich bestellt. Anbei sind Kopien meiner Aufzeichnungen über diesen Kauf. Ich erwarte, bald von Ihnen zu hören. Aufrichtig, Bumblebee.
同样,该模型产生了一个非常好的翻译,正确地使用了德语的正式代词,如“Ihrem”和“Sie”。在这里,我们还展示了如何覆盖管道中的默认模型以选择最适合您的应用程序的模型 - 您可以在 Hugging Face Hub 上找到数千种语言对的模型。在我们退后一步看看整个 Hugging Face 生态系统之前,让我们来看看最后一个应用程序。
文本生成
假设您希望能够通过访问自动完成功能来更快地回复客户反馈。使用文本生成模型,您可以执行以下操作:
generator = pipeline("text-generation")
response = "Dear Bumblebee, I am sorry to hear that your order was mixed up."
prompt = text + "\n\nCustomer service response:\n" + response
outputs = generator(prompt, max_length=200)
print(outputs[0]['generated_text'])Dear Amazon, last week I ordered an Optimus Prime action figure from your online store in Germany. Unfortunately, when I opened the package, I discovered to my horror that I had been sent an action figure of Megatron instead! As a lifelong enemy of the Decepticons, I hope you can understand my dilemma. To resolve the issue, I demand an exchange of Megatron for the Optimus Prime figure I ordered. Enclosed are copies of my records concerning this purchase. I expect to hear from you soon. Sincerely, Bumblebee. Customer service response: Dear Bumblebee, I am sorry to hear that your order was mixed up. The order was completely mislabeled, which is very common in our online store, but I can appreciate it because it was my understanding from this site and our customer service of the previous day that your order was not made correct in our mind and that we are in a process of resolving this matter. We can assure you that your order
好吧,也许我们不想用这个补全来让 Bumblebee 平静下来,但你明白了。
现在您已经看到了一些很酷的 Transformer 模型应用程序,您可能想知道训练在哪里进行。我们在本章中使用的所有模型都是公开可用的,并且已经针对手头的任务进行了微调。但是,一般来说,您会希望根据自己的数据微调模型,在接下来的章节中,您将学习如何做到这一点。
但训练模型只是任何 NLP 项目的一小部分——能够有效地处理数据、与同事共享结果以及使您的工作具有可重复性也是关键组成部分。幸运的是, ![]() Transformers 被一个庞大的有用工具生态系统所包围,这些工具支持大部分现代机器学习工作流程。让我们来看看。
Transformers 被一个庞大的有用工具生态系统所包围,这些工具支持大部分现代机器学习工作流程。让我们来看看。
拥抱脸生态系统
从![]() Transformers 开始的东西迅速发展成为一个由许多库和工具组成的完整生态系统,以加速您的 NLP 和机器学习项目。Hugging Face 生态系统主要由库族和 Hub 两部分组成,如图 1-9所示。库提供代码,而 Hub 提供预训练的模型权重、数据集、评估指标的脚本等。在本节中,我们将简要介绍各种组件。我们将跳过变形金刚,因为我们已经讨论过它,我们将在本书的整个过程中看到更多它。
Transformers 开始的东西迅速发展成为一个由许多库和工具组成的完整生态系统,以加速您的 NLP 和机器学习项目。Hugging Face 生态系统主要由库族和 Hub 两部分组成,如图 1-9所示。库提供代码,而 Hub 提供预训练的模型权重、数据集、评估指标的脚本等。在本节中,我们将简要介绍各种组件。我们将跳过变形金刚,因为我们已经讨论过它,我们将在本书的整个过程中看到更多它。
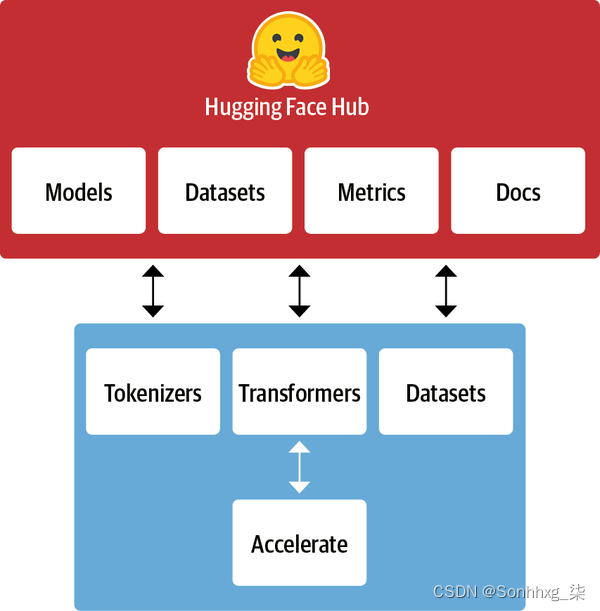
图 1-9。Hugging Face 生态系统概述
The Hugging Face Hub
如前所述,迁移学习是推动 Transformer 成功的关键因素之一,因为它可以将预训练模型重用于新任务。因此,能够快速加载预训练模型并对其进行实验至关重要。
Hugging Face Hub 拥有超过 20,000 个免费提供的模型。如图 1-10所示,有用于任务、框架、数据集等的过滤器,旨在帮助您浏览 Hub 并快速找到有前途的候选人。正如我们在管道中看到的那样,在您的代码中加载一个有前途的模型实际上只需一行代码。这使得对各种模型的试验变得简单,并允许您专注于项目的特定领域部分。
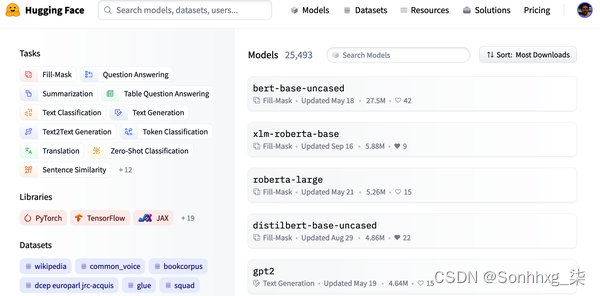
图 1-10。Hugging Face Hub 的模型页面,左侧显示过滤器,右侧显示模型列表
除了模型权重,Hub 还托管用于计算指标的数据集和脚本,让您可以重现已发布的结果或为您的应用程序利用其他数据。
Hub 还提供模型和数据集 卡片来记录模型和数据集的内容,并帮助您就它们是否适合您做出明智的决定。Hub 最酷的功能之一是您可以通过各种特定于任务的交互式小部件直接试用任何模型, 如图 1-11所示。
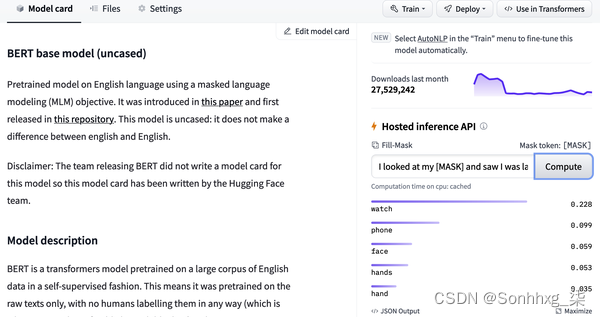
图 1-11。来自 Hugging Face Hub 的示例模型卡:推理小部件,允许您与模型交互,显示在右侧
让我们继续我们的![]() Tokenizers 之旅。
Tokenizers 之旅。
拥抱面部标记器
我们在本章中看到的每个管道示例背后都有一个标记化步骤,该步骤将原始文本拆分为称为标记的较小片段。我们将在 第 2 章详细了解它是如何工作的,但现在理解标记可能是单词、单词的一部分或只是像标点符号这样的字符就足够了。Transformer 模型在这些标记的数字表示上进行了训练,因此正确执行此步骤对于整个 NLP 项目非常重要!![]()
Tokenizers提供了许多标记化策略,并且由于其 Rust 后端,它在标记文本方面非常快。12它还负责所有预处理和后处理步骤,例如规范化输入和将模型输出转换为所需格式。使用 Tokenizer,我们可以加载一个 tokenizer,就像我们可以使用Transformers。
我们需要一个数据集和指标来训练和评估模型,所以让我们看![]() 一下负责这方面的数据集。
一下负责这方面的数据集。
拥抱人脸数据集
加载、处理和存储数据集可能是一个繁琐的过程,尤其是当数据集太大而无法放入笔记本电脑的 RAM 时。此外,您通常需要实现各种脚本来下载数据并将其转换为标准格式。![]()
然而,如果你不能可靠地衡量性能,那么拥有一个好的数据集和强大的模型是毫无价值的。不幸的是,经典的 NLP 指标带有许多不同的实现,这些实现可能略有不同并导致欺骗性的结果。通过为许多指标提供脚本,![]() 数据集有助于使实验更可重复,结果更值得信赖。
数据集有助于使实验更可重复,结果更值得信赖。
借助![]() Transformers、 Tokenizers 和 Datasets 库,我们拥有训练自己的 Transformer 模型所需的一切!然而,正如我们将在第 10 章中看到的,在某些情况下,我们需要对训练循环进行细粒度控制。这就是生态系统的最后一个库发挥作用的地方:加速。
Transformers、 Tokenizers 和 Datasets 库,我们拥有训练自己的 Transformer 模型所需的一切!然而,正如我们将在第 10 章中看到的,在某些情况下,我们需要对训练循环进行细粒度控制。这就是生态系统的最后一个库发挥作用的地方:加速。
拥抱脸加速
如果您曾经不得不在 PyTorch 中编写自己的训练脚本,那么在尝试将笔记本电脑上运行的代码移植到组织集群上运行的代码时,您可能会感到头疼。 ![]() Accelerate为您的正常训练循环添加了一个抽象层,负责处理训练基础架构所需的所有自定义逻辑。通过在必要时简化基础架构的更改,这确实加速了您的工作流程。
Accelerate为您的正常训练循环添加了一个抽象层,负责处理训练基础架构所需的所有自定义逻辑。通过在必要时简化基础架构的更改,这确实加速了您的工作流程。
这总结了 Hugging Face 开源生态系统的核心组件。但在结束本章之前,让我们来看看在现实世界中尝试部署变压器时遇到的一些常见挑战。
Transformers的主要挑战
在本章中,我们已经了解了可以使用 Transformer 模型处理的范围广泛的 NLP 任务。阅读媒体头条,有时听起来他们的能力是无限的。然而,尽管它们很有用,但变形金刚远非灵丹妙药。以下是与它们相关的一些挑战,我们将在整本书中探讨:
NLP 研究以英语为主。其他语言有几种模型,但很难找到用于稀有或低资源语言的预训练模型。在 第 4 章中,我们将探讨多语言转换器及其执行零样本跨语言迁移的能力。
尽管我们可以使用迁移学习来显着减少模型所需的标记训练数据量,但与人类执行任务所需的量相比,它仍然很多。处理几乎没有标记数据的情况是第 9 章的主题。
Self-attention 在段落长的文本上效果非常好,但是当我们转向像整个文档这样的较长文本时,它变得非常昂贵。第 11 章讨论了减轻这种情况的方法。
与其他深度学习模型一样,Transformer 在很大程度上是不透明的。很难或不可能解开模型做出某个预测的“原因”。当部署这些模型以做出关键决策时,这是一个特别艰巨的挑战。我们将在第2章和 第4章探索一些方法来探测 Transformer 模型的误差。
Transformer 模型主要基于来自互联网的文本数据进行预训练。这会将数据中存在的所有偏差都印入模型中。确保这些既不是种族主义、性别歧视或更糟的是一项具有挑战性的任务。我们将在第 10 章更详细地讨论其中一些问题。
尽管令人生畏,但其中许多挑战是可以克服的。除了提到的特定章节,我们将在接下来的几乎每一章中触及这些主题。
结论
希望现在您很高兴学习如何开始训练这些多功能模型并将其集成到您自己的应用程序中!您在本章中已经看到,只需几行代码,您就可以使用最先进的模型进行分类、命名实体识别、问答、翻译和摘要,但这实际上只是“提示冰山。”