爬虫说明
我们知道,互联网时代,大量的数据信息会以网页作为载体而存在,有些公开而免费的数据比较适合采集,并经过有效处理之后,可用于数据分析、机器学习、科学决策等方面,而从网页中采集数据的利器,当属爬虫了。爬虫的定义也很好理解:指按照一定的规则自动地从网页上抓取数据的代码或脚本,它能模拟浏览器对存储指定网页的服务器发起请求,从而获得网页的源代码,再从源代码中提取需要的数据。
利用爬虫技术获取数据,具有持续性、稳定性、效率高等优势。接下来,将梳理有关爬虫的入门知识点,并把实践中遇到的问题也记录下。
入门爬虫的话,建议选择 requests + BeautifulSoup 模块。requests 模块是一个简单而优雅的 HTTP 库,用于处理请求和响应的,通常得到响应的数据大多数都是 HTML 文档形式,可使用 BeautifulSoup 模块解析 HTML 文档并提取其中想要的数据。
首先,通过 pip 命令下载依赖:
pip install requests
pip install beautifulsoup41、请求头检查(User-Agent)
通常情况下,网站都会开启反爬虫机制的,其中最简单且最常见的一种策略是检查 User-Agent,网站会检查是否存在请求头信息。如果不存在的话,说明不是通过浏览器访问的,会被当做爬虫程序被拒绝请求。解决的方法也很简单,就是在代码里加入 User-Agent 呗,然而不同的浏览器的User-Agent是不同的,如果我们每次都去找浏览器的 User-Agent 并手动加入代码中,这显然很费劲!
推荐一个用于随机生成请求头的库 fake-useragent,名字看上去很霸气,也超级好用!编写一段测试代码,测试不同浏览器的 User-Agent 内容,如下:
from fake_useragent import UserAgent
ua = UserAgent()
print(f"firefox: {ua.firefox}")
print(f"chrome: {ua.chrome}")
print(f"google: {ua.google}")
print(f"IE: {ua['Internet Explorer']}")记得去年使用的时候,可以直接拿来用,而最近使用却老是报错,报错信息如下:
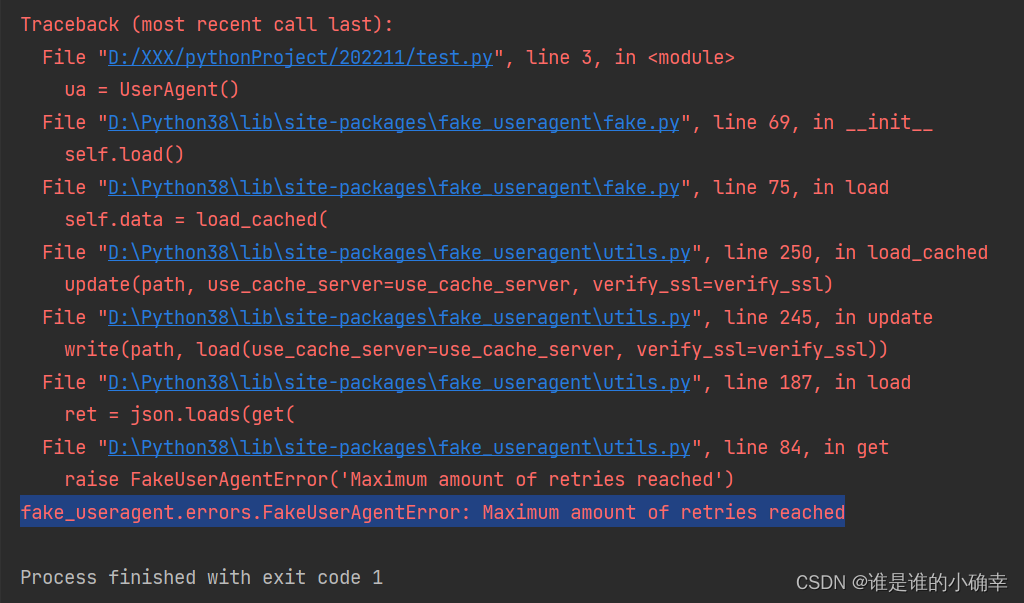
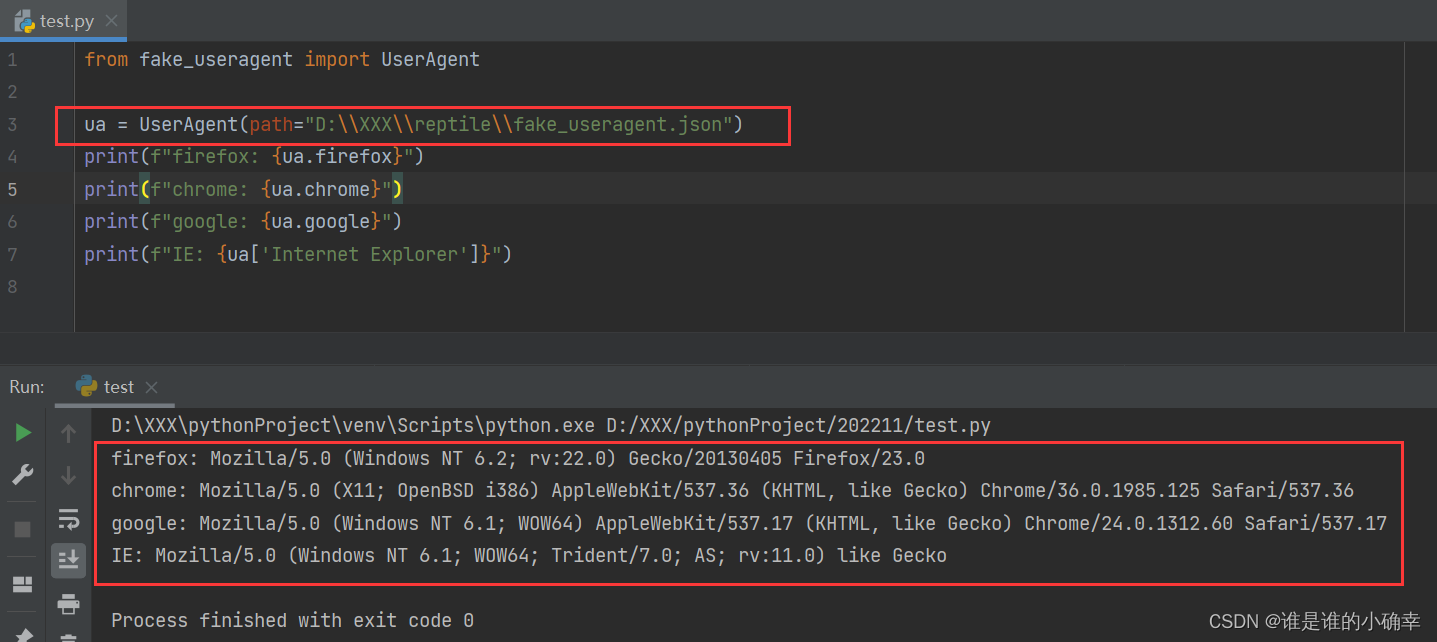
废了半天的劲,终于解决了,在ua对象的参数 path 里加入一个 JSON 文件,通过这个 JSON 文件匹配不同浏览器的 User-Agent,该文件可以去这里下载,重新测试,完美解决:
2、请求目标 URL(requests API)
在正式开启爬虫之前,我们需要了解熟悉下 requests 模块相关的 API。
这里,以新安人才网的 Java 开发工程师招聘的网页作为目标 URL 为例,进行热身练习。当以 get 方式请求网页数据后,如果响应的状态返回200或 reason 返回 OK,就能判断获取网页数据成功,从而进一步可拿到响应内容或整个 HTML 文档,为后续的网页解析做好准备,如下:
import requests
url = 'https://search.goodjobs.cn/index.php'
# 以get方式发送请求,暂时不加入请求头
response = requests.get(url)
print(response.reason) # 请求成功的话,返回OK
print(response.status_code) # 请求成功的话,返回200
print(response.headers.items()) # 获取请求头信息
print(response.cookies) # 获取cookies信息
print(response.encoding) # 获取编码方式
print(response.content) # 响应内容
print(response.text) # 返回整个HTML网页文档当然,我们也可以选择其他的请求方式,比如 POST、PUT、DELTET、HEAD、OPTIONS 等,而最常用的请求方式则是 GET 和 POST 了。需要注意的是,GET 方式还支持传入请求参数 params,请求头 headers 等,如下:
import requests
from fake_useragent import UserAgent
#完整url:https://search.goodjobs.cn/index.php?metro=0&area=0&page=1
url = 'https://search.goodjobs.cn/index.php'
# 请求参数
params = {'metro':0, 'area':0, page=1}
# 请求头
path = 'D:\\XXX\\reptile\\fake_useragent.json'
headers = UserAgent(path).google
#构建请求
res = requests.get(url. params, headers)3、解析网页数据(BeautifulSoup)
requests 模块负责向目标url发送请求,并返回响应数据,接着就是如何处理响应数据了。如果从响应得到的数据是Json格式的话,那最好不过了,直接存入文件或数据库中即可。通常情况下,得到的是 HTML 文档,那就需要考虑如何去解析它了。解析和提取目标网页数据的话,可以使用正则表达式,也可以使用 BeautifulSoup 模块。
这里,以 BeautifulSoup 模块为例说明,相关的 API 可以了解一下:
from bs4 import BeautifulSoup
soup = BeautifulSoup(respone.text, "html.parser") #返回整个HTML文档对象
# HTML文档的遍历
soup.div #获取所有的div
soup.div.p #获取所有的div下的p标签
soup.div.p.name #获取所有的div下的p标签的名称
soup.div.p['id']#获取所有的div下的p标签的id属性
'''
HTML文档的搜索:有两种方法find_all()、find()
find_all():返回所有匹配到的标签
find():返回匹配到的第一个标签
'''
soup.find_all('div') #获取所有的div标签
soup.find_all("p", class_="aaa") #获取class属性为aaa的p标签
soup.find_all(id='203568110') #搜索id='203568110'标签
# get_text():获取文本内容,返回的是 unicode 类型的字符串
soup.find_all('div').get_text()通过 CSS 选择器的定位方式,测试一下:
import requests
from bs4 import BeautifulSoup
# 以get方式发送请求,暂时不加入请求头
response = requests.get(url)
if response.status_code == 200:
# 返回整个HTML文档对象
soup = BeautifulSoup(response.text, "html.parser")
# 获取职位列表(提取招聘公司名称)
jobList = []
jobDivList = soup.find_all('div', class_='border-b clearfix ml16 mr20 h130 sear-job relative jshandle_jobShowDetailParent')
for i in range(0, len(jobDivList)):
company = soup.select("div[class='fr']>a")[i].get_text().strip().split(' ')
jobList.append(company)
print(jobList)爬取到的结果,如下:

可以看到,使用 BeautifulSoup 模块解析和提取 HTML 文档包含的数据,重点在于对网页结构的了解和分析。我在刚开始接触的时候,通过 BeautifulSoup 模块解析 HTML 文档是一个很麻烦的过程,如果不使用 CSS 选择器操作的话,通过 xpath 屡试屡错让人抓狂啊,期间还遇到很多的语法书写错误。
BeautifulSoup 模块提供了 select() 方法获取 CSS 选择器定位到的标签结果,如果想要获取标签内容,继续使用 get_text() 方法,这极大的方便对网页的解析操作,语法学习也不是太难,建议采用 CSS 选择器。
4、CSS 选择器
CSS,即层叠样式表(Cascading Style Sheets)的简称,是一种负责页面美化和布局控制的语言,它有很多类型的选择器,比如id选择器,class选择器,元素选择器等。有时候爬虫需要去解析HTML文档,为提升效率,掌握CSS选择器的用法,对定位到想要的数据很有帮助。
接下来,以下面这段 HTML 标签为例:
<div id='ddd'>
<span id="kkk" class="f618 sp0 m0" name="wxx1">你真棒!!!</span>
<span id="kzz" class="f618 sp0 m0" name="wxx2">你真好棒!!!</span>
</div>在整个HTML文档中要定位到 span 标签的位置的话,可以使用元素选择器:(所有span标签)
span可以使用id选择器:(唯一)
#kkk可以使用 class 选择器:(div标签下的类属性为f618 sp0 m0的所有span标签)
.f618 sp0 m0可以使用相邻选择器:(id 为kkk的 span 标签的下一个相邻span标签)
#kkk+span可以使用子选择器:(div标签下的所有span标签)
div>span可以使用包含选择器:(div标签下的所有span标签)
div span可以使用全局选择器:(div标签下的所有标签)
div *可以使用群选择器:(div标签下的指定span标签)
div #kkk,#kzz可以用属性选择器:(指定属性的span标签)
span[name='wxx1']
span[class='f618 sp0 m0']可以使用伪选择器:(对列表类型更实用~)
-
id为ddd的div标签下的第一个span标签:
div#ddd > span:nth-child(1)
div#ddd > span:frist-child-
id为ddd的div标签下的最后一个span标签:
div#ddd > span:nth-last-child(1)
div#ddd > span:last-child-
取反:例如不选择第一个span标签:
div#ddd > span:not(1)在上面的基础知识点掌握之后,就可以根据自己的需求拼接解析表达式了,如下:
soup = BeautifulSoup(text, "html.parser")
#获取第一个span标签内容,可以写:
soup.select("div > span[name='wxx1']").get_text()
#也可以写:
soup.select("div > span:frist-child").get_text()
#也可以写:
soup.select("div > span:nth-child(1)").get_text()
#也可以写:
soup.select("div #kkk").get_text()最后
基于 Python 的爬虫入门看起来并不难,选择 requests + BeautifulSoup 模块入门基本就够了。而实际中的爬虫技术远没有这么简单了,需要学习和掌握的还有很多知识,比如,解析更复杂的 HTML 文档:从嵌套更为复杂的页面提取出目标数据,从动态网页提取目标数据等;反爬虫机制:有哪些常见反爬类型,又如何绕开网站反爬虫的防御呢;常见的爬虫框架有哪些,都有哪些优点和特色等等。
此外,我们需要清醒的认识到,爬虫技术是把双刃剑,用的好可以提升效率,用途不好牢饭管饱,近些年来触犯底线的新闻事件时有发生,以至于提及到爬虫,总会给人一种不太好的印象啊!!因此,正确认识爬虫技术,正确使用爬虫技术,我们应该拥有这样的认识观~~