在编译器开发体系中有两套框架,一个叫"lex && yacc", 另一个名气更大叫llvm,这两都是开发编译器的框架,我们只要设置好配置文件,那么他们就会生成相应的编译器代码,通常是c或者c++代码,然后对代码进行编译就能获得可执行的编译器运行文件,我们主要模仿lex && yacc的实现。
在centos上可以使用如下命令进行安装:
install flex-devel bison-devel
完成后我们就可以使用flex来生成词法解析代码,首先我们创建一个lex.l文件,输入内容如下:
%option noyywrap
%{
int FCON = 1;
int ICON = 2;
%}
D [0-9]
%%
({D}*\.{D}|{D}\.{D}*) {printf("%s is a float number", yytext); return FCON;}
%%
这个文件其实跟我们在当前GoLex项目中使用的input.lex没有多少区别。然后在同一目录下使用命令:
flex lex.l
执行后在本地目录下会创建lex.yy.c代码文件,我们可以打开它看看,可以发现里面定义了很多函数和变量,其中两个比较重要的是yylex()函数和yytext变量,前者启动输入字符串并执行识别的流程,后者指向当前读入的字符串。接下来我们对lex.yy.c进行编译:
gcc lex.yy.c -o golex
执行后本地目录会多出golex可执行文件,使用./golex将其运行起来,然后程序会等待我们输入,当你输入浮点数字符串,例如1.23后运行结果如下:

我们当前项目的目的就是实现flex对应的功能,根据输入的.l文件,生成lex.yy.cc文件。有了这些上下文后,我们接下来看看DFA跳转表的压缩算法。从前面几节我们看到,跳转表每一行很多元素是重复的,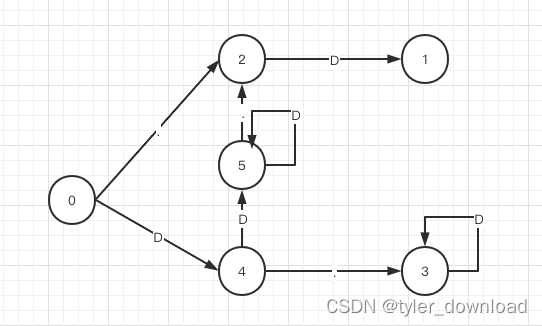
从上图看到对于节点3,它除了了接收0到9对应的10个字符外,其他字符都不接收,由于在ASCII中前128个对应可输入字符,因此在跳转表中,对应节点3这行有118个元素是不必要的,因此这些元素可以压缩掉。我们先采用一种叫pair compress的方法,它首先用一个数字表示当前行的有效跳转数,例如对于节点3,这个值就是10,因为它只接收0到9这10个字符,然后跟着两个数值组成的一对数据,第一个数值对应输入字符,第二个字符对应要跳转的节点,于是对应节点3那行就可以进行如下压缩:
[10, ‘0’,3, ‘1’,3,…‘9’,3]
我们可以看到上面数据存储了21个元素,相比于原来一行128个元素,在内存上就节省了很多,压缩后如果跳转表进入了节点3,针对输入的字符它就可以进行相应查找,首先读取第一个字符,然后依次遍历后面由两个元素组成的数值对进行匹配,例如当在节点3,输入字符是9时,我们读取第一个字符10,然后准备遍历接下来的10个字符对,第一个字符对为‘0’,3,由于’0’不能匹配字符’9’,于是读入第二个字符对’1’,3,依次类推,读到最后一个字符对时匹配成功。如果遍历完所有字符对都找不到匹配,那说明当前节点不接收给定字符.
这里我们需要注意的是,如果有效跳转数比较多的话,我们就不能使用该压缩算法,因为压缩算法使用(输入字符,跳转状态节点)两个数值对应的数值对来表示跳转信息,如果原来压缩表中有效跳转数多的话,那么执行该压缩算法就有可能增加跳转表的数据而非减少。
我们看看代码实现,在nfa_to_dfa.go中增加如下内容:
func (n *NfaDfaConverter) pairs(name string, threshold int, numbers int) int {
/*
生成压缩后的跳转表,并将其作为C代码进行输出。其中name对应压缩后数组在输出成代码时对应的
数组变量名,threshold用于决定给定行是否需要压缩,如果一行中有效跳转的数量超过了threshold,
那么就不用压缩,numbers决定数值对中,第一个元素使用字符表示还是ascii数值表示,如果members = 0,
那么对应输入字符'0',跳转对则为'0', 3, 如果members=1,那么跳转对为48,3,因为'0'对应ascii的值为48
*/
nrows := n.nstates
numCells := 0 //数值对计数
//开始输出第一部分
for i := 0; i < nrows; i++ {
ncols := len(n.dtrans[i])
ntransation := 0 //统计有效跳转数
for j := 0; j < ncols; j++ {
if n.dtrans[i][j] != F {
ntransation += 1
}
}
if ntransation > 0 {
//如果存在有效跳转则准备压缩,先输入压缩后数据对应的数组变量名
fmt.Fprintf(n.fp, "%s %s %s%d[] = { ", SCLASS, TYPE, name, i)
numCells += 1
if ntransation > threshold {
//如果有效跳转数超过了阈值就不要压缩,要不然数据没有减少反而会增加
fmt.Fprintf(n.fp, "0, \n ")
} else {
//先输入跳转数值对的数量
fmt.Fprintf(n.fp, "%d, ", ntransation)
if threshold > 5 {
//如果阈值大于5,那么我们先输入换行,这么做是希望打印出来的内容看起来比较工整
fmt.Fprintf(n.fp, "\n ")
}
}
nprinted := NCOLS
ncommas := ntransation
for j := 0; j < ncols; j++ {
if ntransation > threshold {
//有效跳转数超过了阈值,那么直接输出原来的行,因为此时压缩有可能会让数据量增大
numCells += 1
nprinted -= 1
fmt.Fprintf(n.fp, "%d", n.dtrans[i][j])
if j < ncols-1 {
fmt.Fprintf(n.fp, ", ")
}
} else {
//使用pair压缩算法来压缩行
if n.dtrans[i][j] != F {
if numbers > 0 {
fmt.Fprintf(n.fp, "%d,%d", j, n.dtrans[i][j])
} else {
fmt.Fprintf(n.fp, "'%s',%d", string(j), n.dtrans[i][j])
}
nprinted -= 2
ncommas -= 1
if ncommas > 0 {
fmt.Fprintf(n.fp, ", ")
}
}
}
if nprinted <= 0 {
//输出换行
fmt.Fprintf(n.fp, "\n ")
nprinted = NCOLS
}
}
fmt.Fprintf(n.fp, "};\n")
}
}
//结束输出第一部分
//开始输出第二部分
fmt.Fprintf(n.fp, "\n%s %s *%s[ %d ] = \n{\n ", SCLASS, TYPE, name, nrows)
nprinted := 10
i := 0
for i := 0; i < nrows - 1; i++ {
ntransations := 0
ncols := len(n.dtrans[i])
for j := 0; j < ncols; j++ {
if n.dtrans[i][j] != F {
ntransations += 1
}
}
//只输出包含有效跳转的节点对应的行,例如节点1就没有任何跳转,因此就不输出它对应的行
if ntransations > 0 {
fmt.Fprintf(n.fp, "%s%d, ", name, i)
} else {
fmt.Fprintf(n.fp, "NULL ,")
}
nprinted -= 1
if nprinted <= 0 {
fmt.Fprintf(n.fp, "\n ")
nprinted = 10
}
}
fmt.Fprintf(n.fp, "%s%d\n};\n\n", name, nrows)
//结束输出第二部分
return numCells
}
func (n *NfaDfaConverter) pnext(name string) {
/*
这里输出一段c语言代码,它们的作用是根据输入字符,查询上面生成的压缩跳转表后,跳转到下一个状态节点
*/
toptext := []string{"unsigned int c ;", "int cur_state;", "{",
"/*给定当前状态和输入字符,返回跳转后的下一个状态节点*/",
}
boptext := []string{
" int i;",
"",
" if ( p ) ",
" {",
" if ((i = *p++) == 0)",
" return p[ c ];",
"",
" for(; --i >= 0; p += 2)",
" if( c == p[0] )",
" return p[1];",
" }",
" return unsigned char (-1);",
"}",
}
fmt.Fprintf(n.fp, "\n/*------------------------------------*/\n")
fmt.Fprintf(n.fp, "%s %s yynext(cur_state, c)\n", SCLASS, TYPE)
for _, str := range toptext {
fmt.Fprintf(n.fp, "%s\n", str)
}
fmt.Fprintf(n.fp, " %s *p = %s[cur_state];\n", TYPE, name)
for _, str := range boptext {
fmt.Fprintf(n.fp, "%s\n", str)
}
}
func (n *NfaDfaConverter) DoPairCompression() {
n.pairs("yy_next", 10, 1)
n.pnext("yy_next")
}
上面代码的逻辑有些繁琐,大家可以通过视频观看我调试演示的过程来加深理解,接下来我们调用上面代码看看输出结果,比对运行结果也能帮助理解代码逻辑,在main.go中添加代码如下:
func main() {
....
nfaConverter.DoPairCompression()
}
代码运行后在本地目录会生成一个lex.yy.c文件,其内容如下:
static unsigned char yy_next0[] = { 0,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, 2, -1, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1};
static unsigned char yy_next2[] = { 10,
48,1, 49,1, 50,1, 51,1, 52,1,
53,1, 54,1, 55,1, 56,1, 57,1
};
static unsigned char yy_next3[] = { 10,
48,3, 49,3, 50,3, 51,3, 52,3,
53,3, 54,3, 55,3, 56,3, 57,3
};
static unsigned char yy_next4[] = { 0,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, 3, -1, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1};
static unsigned char yy_next5[] = { 0,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, 2, -1, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1};
static unsigned char *yy_next[ 6 ] =
{
yy_next0, NULL ,yy_next2, yy_next3, yy_next4, yy_next5
/*------------------------------------*/
static unsigned char yynext(cur_state, c)
unsigned int c ;
int cur_state;
{
/*给定当前状态和输入字符,返回跳转后的下一个状态节点*/
unsigned char *p = yy_next[cur_state];
int i;
if ( p )
{
if ((i = *p++) == 0)
return p[ c ];
for(; --i >= 0; p += 2)
if( c == p[0] )
return p[1];
}
return unsigned char (-1);
}
在上面输出中,顶部yy_next0到yy_next5这部分由前面代码中注释"第一部分“代码所生成
//开始输出第一部分
...
//结束输出第一部分
接下来的yy_next[6]这部分有代码中标注的”第二部分“生成,最后yynext对应函数的代码则由pnext函数运行后生成。还有一种压缩方法就是去除跳转表中多余的列或者行,例如:
[1, 1 ,1, 2, 2, 3, 3
1, 1 ,1, 2, 2, 3, 3,
2, 2, 2, 3, 3, 4, 4,
2, 2, 2, 3, 3, 5, 5,
]
可以看到第0,1,2列重复,第3,4列重复,第5,6列重复,于是我们可以只存储第0,3,5列,如果访问到第1,2两列时,我们就到第0列相应位置,同理访问第4列时就到第3列相应位置,访问到第6列时则进入到第5列,于是我们将上面跳转表压缩为:
[1,2,3
1,2,3,
2,3,4,
2,3,5
]
由于原来列的位置发生了变化,第3列在新表中是第1列,第5列在新表中就是第2列,因此我们需要把这个对应关系记录下来,于是:
col_map[0] = 0, col_map[1] = 0, col_map[2]=0, col_map[3] = 2, col_map[4]=2,
col_map[5] = 2, col_map[5] = 2
由此在访问某一列时,我们先在上面映射表进行查询,得到原来列在新表中对应的列后再去新表进行访问。我们看看具体代码实现:
func (n *NfaDfaConverter) colEquiv(i int, j int) bool {
//判断给定两列是否相同
for row := 0; row < n.nstates; row++ {
if n.dtrans[row][i] != n.dtrans[row][j] {
return false
}
}
return true
}
func (n *NfaDfaConverter) rowEquiv(compressed [][]int, i int, j int) bool {
//判断给定两行是否相同
iRow := compressed[i]
jRow := compressed[j]
for k := 0; k < len(iRow); k++ {
if iRow[k] != jRow[k] {
return false
}
}
return true
}
func (n *NfaDfaConverter) colCopy(dest [][]int, srcCol int, destCol int) {
//将原跳转表srcCol对应的列拷贝到dest数组中destCol对应的列
rows := n.nstates
for i := 0; i < rows; i++ {
dest[i][destCol] = n.dtrans[i][srcCol]
}
}
func (n *NfaDfaConverter) rowCopy(src [][]int, srcRow int, destRow int) {
//将压缩表对应的行拷贝到跳转表
n.dtrans[destRow] = src[srcRow]
}
func (n *NfaDfaConverter) reduce() {
//压缩跳转表中冗余的列,save用于存储没有与前面列重复的列的下标
save := make([]int, 0)
current := -1 //指向没有与前面列重复的列
colReduce := 0 //当前不重复的列要存储到该变量指定的位置
colNum := len(n.dtrans[0])
for true {
i := current + 1
for ; i < colNum; i++ {
_, ok := n.colMap[i]
if !ok {
//当前列不还没有被标志为重复
break
}
}
if i >= colNum {
//已经没有不重复的列了
break
}
save = append(save, i)
current = i
n.colMap[i] = colReduce
for j := i + 1; j < colNum; j++ {
//如果当前j指向的列与current指向的列重复,那么则压缩它
_, ok := n.colMap[j]
if !ok && n.colEquiv(current, j) {
//当前列对应到压缩后跳转表对应的colReduce列
n.colMap[j] = colReduce
}
}
colReduce += 1
}
compressed := make([][]int, n.nstates)
for k := 0; k < n.nstates; k++ {
compressed[k] = make([]int, colReduce)
}
//把save中存储的那些不重复的列拷贝到compressed数组
for k := 0; k < colReduce; k++ {
srcCol := save[k]
destCol := k
n.colCopy(compressed, srcCol, destCol)
}
//使用跟列压缩相同的方法来压缩行
save = make([]int, 0)
current = -1 //指向没有与前面列重复的行
rowReduce := 0 //当前不重复的行要存储到该变量指定的位置
for true {
i := current + 1
for ; i < n.nstates; i++ {
_, ok := n.rowMap[i]
if !ok {
break
}
}
if i >= n.nstates {
//已经没有不重复的行
break
}
save = append(save, i)
current = i
n.rowMap[i] = rowReduce
for j := i + 1; j < n.nstates; j++ {
_, ok := n.rowMap[j]
if !ok && n.rowEquiv(compressed, current, j) {
n.rowMap[j] = rowReduce
}
}
rowReduce += 1
}
n.dtrans = make([][]int, rowReduce)
for k := 0; k < len(save); k++ {
srcRow := save[k]
n.rowCopy(compressed, srcRow, k)
}
}
func (n *NfaDfaConverter) reduceTesting() {
n.dtrans = [][]int{
{1, 1, 1, 2, 2, 3, 3},
{1, 1, 1, 2, 2, 3, 3},
{2, 2, 2, 3, 3, 4, 4},
{2, 2, 2, 3, 3, 5, 5},
}
n.nstates = 4
/*
经过列压缩后应该为
[1, 2, 3
1, 2, 3,
2, 3, 4,
2, 3, 5,]
再经过行压缩后应该为
[1,2,3
2,3,4
2,3,5]
*/
}
func (n *NfaDfaConverter) Squash() {
//执行冗余行和列的压缩
//用于测试,若不然要讲其注释掉
//n.reduceTesting()
n.reduce()
//打印压缩后的跳转表用于测试
n.PrintCompressedDTran()
}
func (n *NfaDfaConverter) PrintCompressedDTran() {
fmt.Printf("\n-------Compressed DTran Table------------\n")
for i := 0; i < n.nstates; i++ {
for j := 0; j < MAX_CHARS; j++ {
mapRow := n.rowMap[i]
mapCol := n.colMap[j]
if n.dtrans[mapRow][mapCol] != F {
fmt.Printf("from state %d jump to state %d with input: %s\n", i, n.dtrans[mapRow][mapCol], string(j))
}
}
}
}
在上面代码实现中reduce函数实现跳转表的压缩逻辑,在代码中为了测试,我专门准备了前面例子中的跳转表,当在main函数中调用Squash函数后,表压缩的结果跟前面我们分析的一样,由此能保证算法实现的正确性。如果注释掉reduceTesting函数,压缩会直接作用在DFA跳转表上,然后我们通过调用PrintCompressedDTran将压缩后的跳转表打印出来。这里需要注意的是,当我们访问跳转表中特定的行和列时,我们需要对其进行映射,因为原来的行和列跟压缩后的跳转表并不一一对应,最终上面代码执行后,打印出的跳转表跟我们前面章节描述的一样,因此可以确认实现逻辑的正确性。
接下来我们像前面一样把压缩后的跳转表转换为c语言代码输入到lex.yy.c文件中,因此我们增加如下代码:
func (n *NfaDfaConverter) Squash() {
//执行冗余行和列的压缩
//用于测试,若不然要讲其注释掉
//n.reduceTesting()
n.reduce()
//打印压缩后的跳转表用于测试
//n.PrintCompressedDTran()
n.printColMap()
n.printRowMap()
}
func (n *NfaDfaConverter) DoSquash() {
n.Squash()
fmt.Fprintf(n.fp, "%s %s %s[%d][%d]=\n", SCLASS, TYPE, DTRAN_NAME, len(n.dtrans), len(n.dtrans[0]))
n.printArray(n.dtrans)
n.cnext("Yy_nxt")
}
func (n *NfaDfaConverter) printArray(array [][]int) {
nrows := len(array)
ncols := len(array[0])
fmt.Fprintf(n.fp, "{\n")
col := 0
for i := 0; i < nrows; i++ {
fmt.Fprintf(n.fp, "/* %d */ {", i)
for col = 0; col < ncols; col++ {
fmt.Fprintf(n.fp, "%d", array[i][col])
if col < ncols-1 {
fmt.Fprintf(n.fp, ", ")
}
if col%NCOLS == NCOLS-1 && col != ncols-1 {
fmt.Fprintf(n.fp, "\n ")
}
}
if col > NCLOS {
fmt.Fprintf(n.fp, "\n ")
}
fmt.Fprintf(n.fp, "}")
if i < nrows-1 {
fmt.Fprintf(n.fp, ",\n")
} else {
fmt.Fprintf(n.fp, " \n")
}
}
fmt.Fprintf(n.fp, "};\n")
}
func (n *NfaDfaConverter) printComment(commnets []string) {
//打印c语言中的注释
fmt.Fprintf(n.fp, "\n/*--------------------------------------\n")
for _, str := range commnets {
fmt.Fprintf(n.fp, "* %s\n", str)
}
fmt.Fprintf(n.fp, "*/\n\n")
}
func (n *NfaDfaConverter) printMap(compressMap map[int]int) {
//需要将map转换为int类型数组
count := len(compressMap)
mapArray := make([]int, count)
for key, value := range compressMap {
mapArray[key] = value
}
length := len(mapArray)
for j := 0; j < length-1; j++ {
fmt.Fprintf(n.fp, "%d,", mapArray[j])
if j%NCOLS == NCOLS-1 {
fmt.Fprintf(n.fp, "\n ")
}
}
fmt.Fprintf(n.fp, "%d\n};\n\n", mapArray[length-1])
}
func (n *NfaDfaConverter) printColMap() {
//打印压缩后的列映射表
text := []string{
"The Yy_cmap[] and Yy_rmap arrays are used as follows:",
"",
" next_state= Yydtran[ Yy_rmap[current_state] ][ Yy_cmap[input_char] ];",
"",
"Character positions in the Yy_cmap array are:",
"",
" ^@ ^A ^B ^C ^D ^E ^F ^G ^H ^I ^J ^K ^L ^M ^N ^O",
" ^P ^Q ^R ^S ^T ^U ^V ^W ^X ^Y ^Z ^[ ^\\ ^] ^^ ^_",
" ! \" # $ % & ' ( ) * + , - . /",
" 0 1 2 3 4 5 6 7 8 9 : ; < = > ?",
" @ A B C D E F G H I J K L M N O",
" P Q R S T U V W X Y Z [ \\ ] ^ _",
" ` a b c d e f g h i j k l m n o",
" p q r s t u v w x y z { | } ~ DEL",
}
n.printComment(text)
fmt.Fprintf(n.fp, "%s %s Yy_cmap[%d]=\n{\n ", SCLASS, TYPE, MAX_CHARS)
n.printMap(n.colMap)
}
func (n *NfaDfaConverter) printRowMap() {
fmt.Fprintf(n.fp, "%s %s Yy_rmap[%d]\n{\n ", SCLASS, TYPE, len(n.dtrans))
n.printMap(n.rowMap)
}
func (n *NfaDfaConverter) cnext(name string) {
text := []string{
"yy_next(state,c) is given the current state number and input",
"character and evaluates to the next state.",
}
n.printComment(text)
fmt.Fprintf(n.fp, "define yy_next(state, c) (%s[Yy_rmap[state]][Yy_cmap[c]])\n", name)
}
最后我们在main函数中调用DoSquash接口,最终生成的lex.yy.c文件内容如下:
/*--------------------------------------
* The Yy_cmap[] and Yy_rmap arrays are used as follows:
*
* next_state= Yydtran[ Yy_rmap[current_state] ][ Yy_cmap[input_char] ];
*
* Character positions in the Yy_cmap array are:
*
* ^@ ^A ^B ^C ^D ^E ^F ^G ^H ^I ^J ^K ^L ^M ^N ^O
* ^P ^Q ^R ^S ^T ^U ^V ^W ^X ^Y ^Z ^[ ^\ ^] ^^ ^_
* ! " # $ % & ' ( ) * + , - . /
* 0 1 2 3 4 5 6 7 8 9 : ; < = > ?
* @ A B C D E F G H I J K L M N O
* P Q R S T U V W X Y Z [ \ ] ^ _
* ` a b c d e f g h i j k l m n o
* p q r s t u v w x y z { | } ~ DEL
*/
static unsigned char Yy_cmap[128]=
{
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,1,0,2,2,
2,2,2,2,2,2,2,2,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0
};
static unsigned char Yy_rmap[6]
{
0,1,2,3,4,5
};
static unsigned char Yy_nxt[6][3]=
{
/* 0 */ {-1, 2, 4},
/* 1 */ {-1, -1, -1},
/* 2 */ {-1, -1, 1},
/* 3 */ {-1, -1, 3},
/* 4 */ {-1, 3, 5},
/* 5 */ {-1, 2, 5}
};
/*--------------------------------------
* yy_next(state,c) is given the current state number and input
* character and evaluates to the next state.
*/
define yy_next(state, c) (Yy_nxt[Yy_rmap[state]][Yy_cmap[c]])
更详细的调试演示请在b站搜索Coding迪斯尼。代码下载:
链接: https://pan.baidu.com/s/17_nmShjvLgoYlFeJvFkzkg 提取码: ft2x