台大李宏毅21年机器学习课程 self-attention和transformer
文章目录
- Seq2seq
- 实现原理
- Encoder
- Decoder
- Autoregressive自回归解码器
- Non-Autoregressive非自回归解码器
- Corss-attention
- 总结
- Training
- trick
- Copy Mechanism
- Guided Attention
- Beam Search
- 强化学习(Reinforcement Learning, RL)
- Scheduled Sampling
Seq2seq
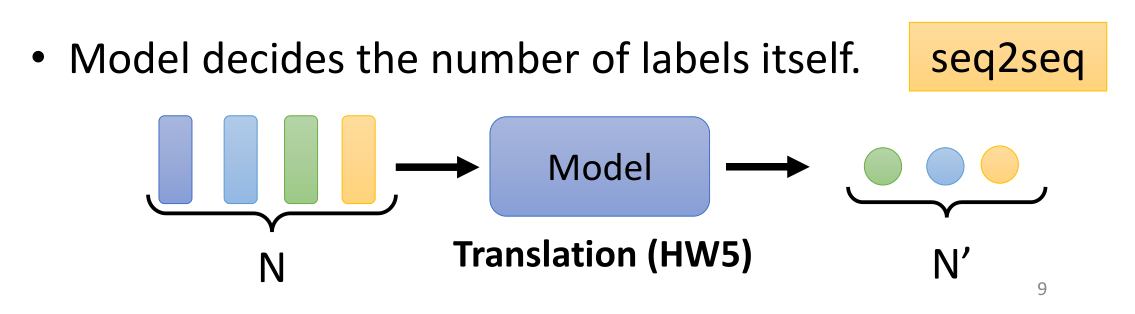
seq2seq输入输出模式,也就是给定一个sequence,让机器自己决定输出的sequence应该有多少个label。
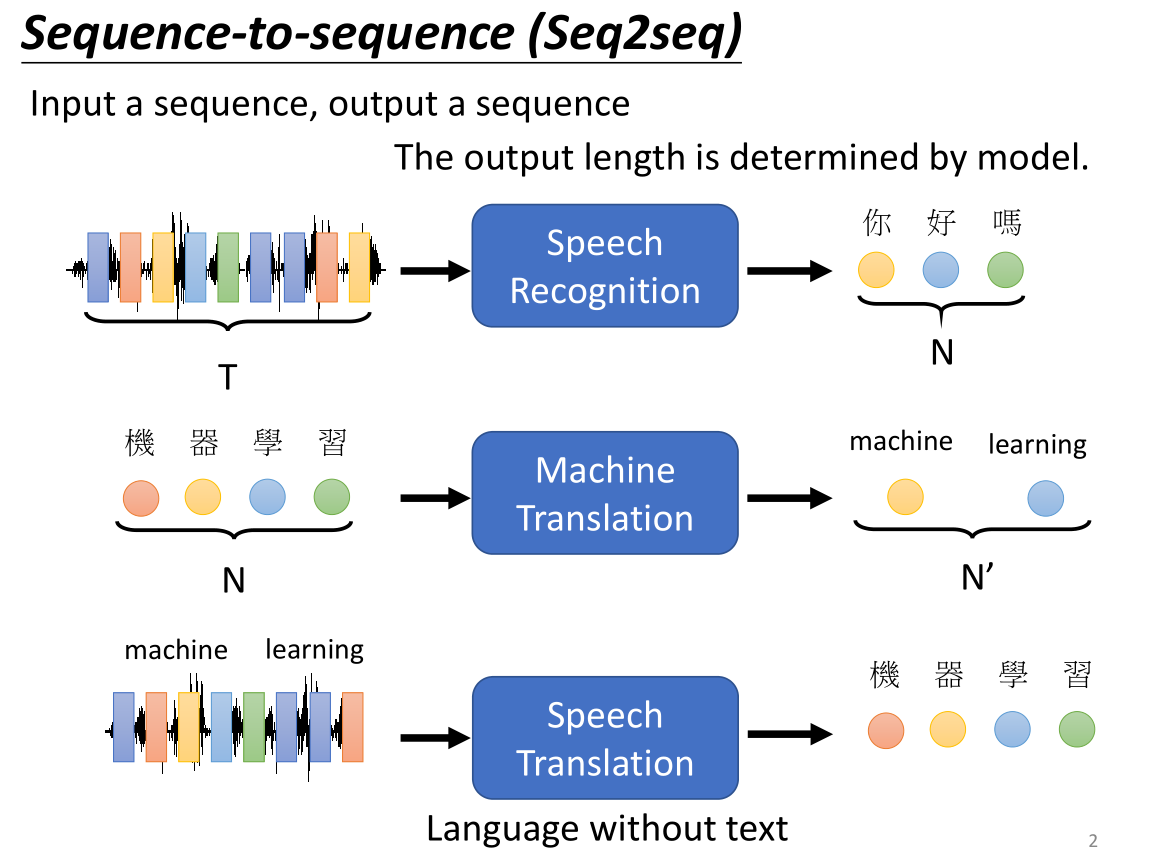
seq2seq的输出长度是不确定的,虽然往往和输入长度是相关的,但是这种相关性并不确定,因此我们更倾向于让机器自己来决定输出的sequence的长度,例如语音识别,机器翻译,甚至更复杂的语音翻译也就是语音转译语音(之所以不用语音识别+机器翻译,有些语言是没有文字的,但是可以翻译成语音)…这样的应用例如对方言的翻译:
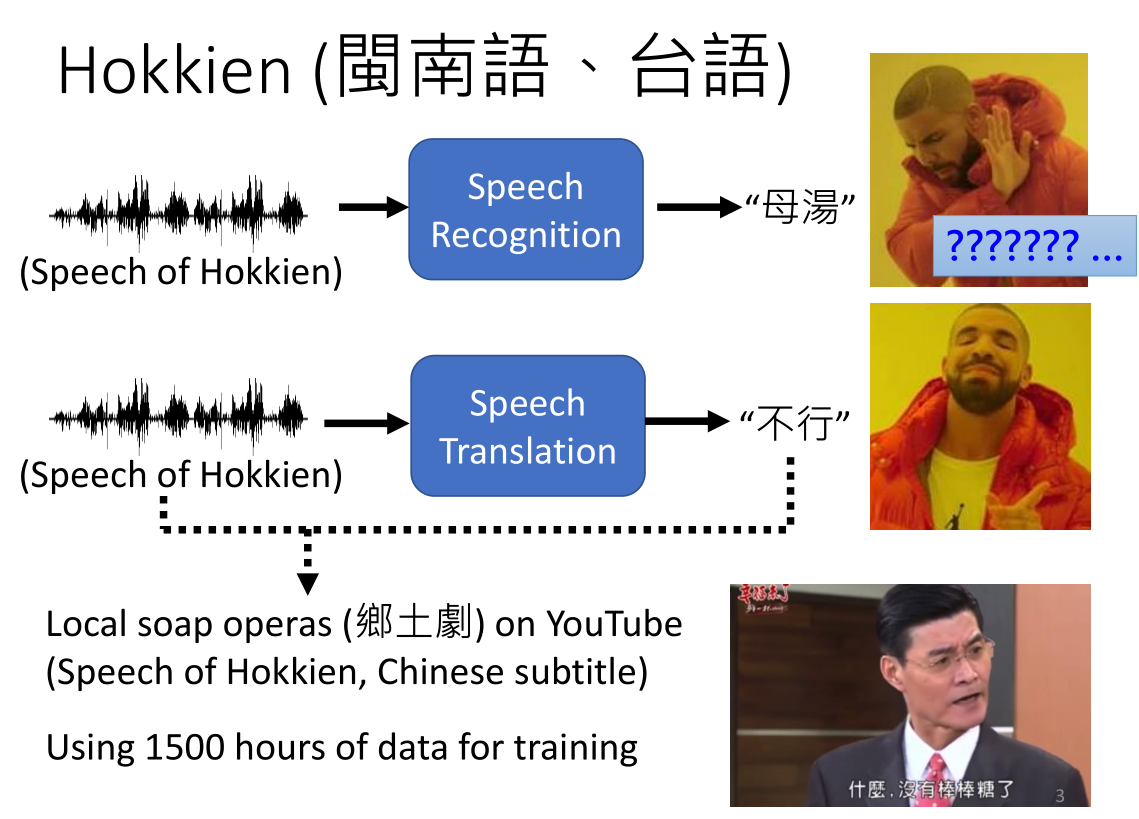
在闽南语中,不行的发音是母汤,我们可以给出对应语音的数据集(例如电视剧的语音和字幕)然后给transformer强行训练,被我们称为强制执行或者强制学习,李老师给出的说法叫“硬train”。听起来问题很大,例如电视剧的背景音和噪声,或者转录的噪声干扰等等…但是竟然真的可以!!这也太离谱了?
以下是讲课时给出的speech2text一些输出结果(幸好会一点闽南语):
(闽南语——中文)
伊身体别康?——你的身体撑不住
袂体别事,伊系安怎别请尬?——没事你为什么要请假
别生诺?——机器翻译:要生了吗,正确答案:不会腻吗
瓦有(wu)尕胸长(giong)拜托——机器翻译:我有帮厂长拜托,虽然直译没错但实际这是倒装句,答案:我拜托厂长了
此外text2speech的效果也非常不错。
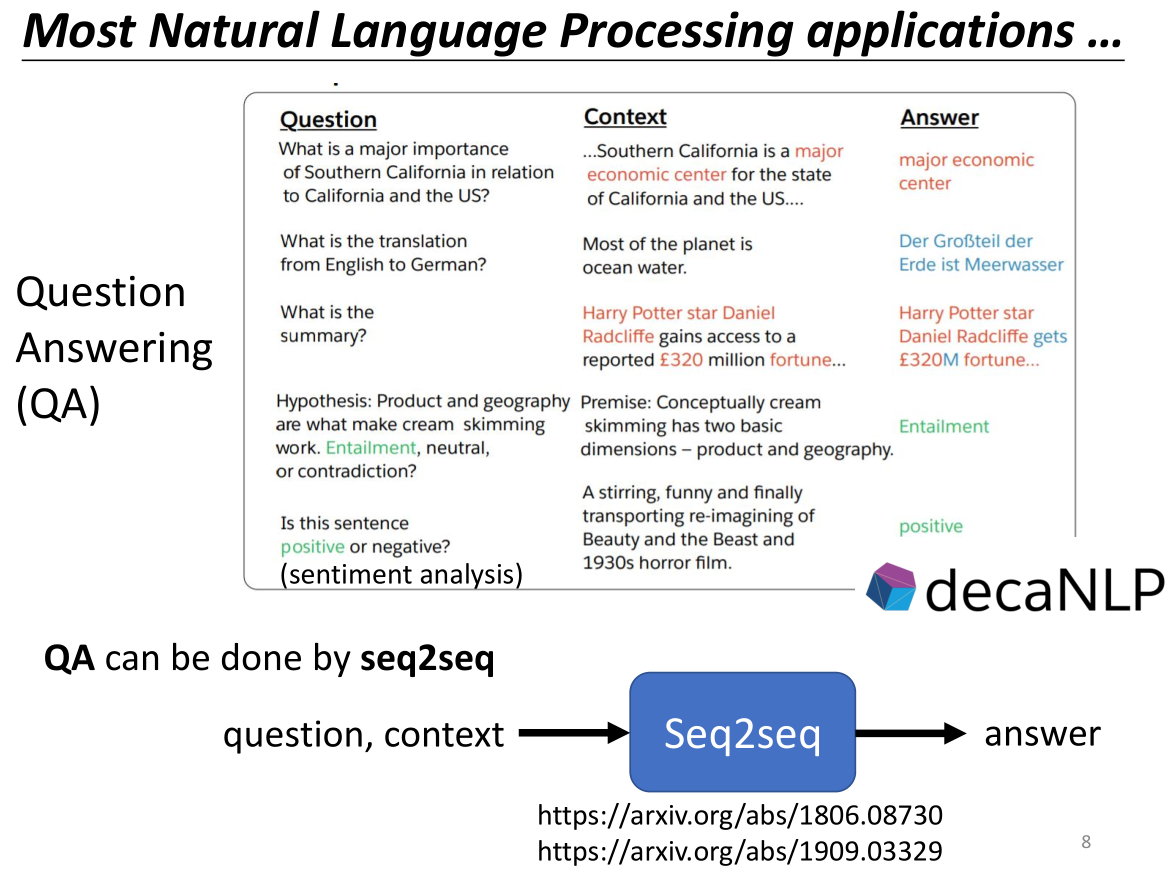
另一个应用seq2seq的重要领域就是NLP领域,例如最近大火的chatGPT之类的chatBot,本质上是一个QA(Question Answering),我们的输入通常是一个问题+内容context的形式(内容是可附加的,输入的核心是一个问题),seq2seq会给出一个answer,本质上它是一个QA。
seq2seq之所以能做到如此多的事情,其中的一个重要原因就是硬train,或者说我们强制地用seq2seq的方式进行学习,使得许多看起来不能用seq2seq的问题都能用它来解决。
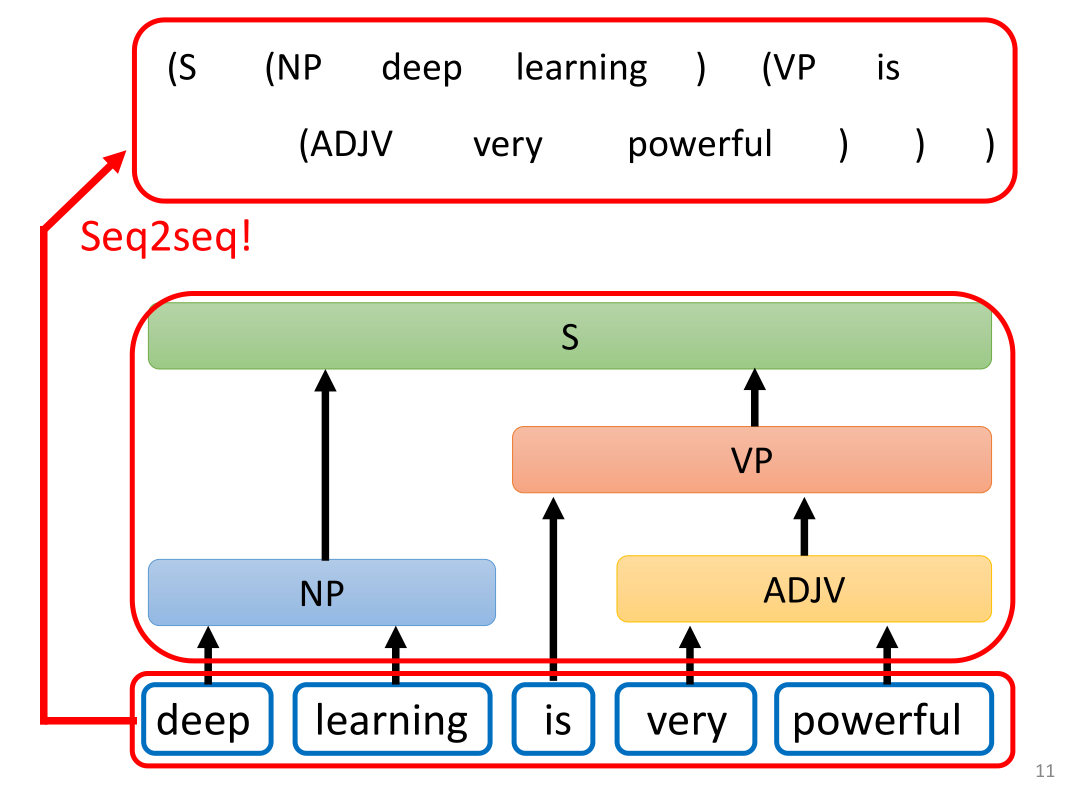
上图是一个用seq2seq实现语法剖析的句子,model根据input构建了一个语法树,看起来这个output的树状结构并不是seq,但是我们可以使用深度优先遍历将其父节点与子节点组成一个set,强制地转化为seq。这样就成为一个seq2seq的结构了,据李老师透露,这个模型的一作甚至连adam都没用,只用SGD来train一遍就成功了。从这点可以看出seq2seq具有很强的能力,很多问题例如多标签分类问题,物体识别问题等等都可以用seq2seq硬做,让机器自己来决定。seq2seq就像一把万能钥匙,当你不知道如何从原理上解决这些问题,不妨用seq2seq硬train来解决,就像人们常说的“机器会自己找到出路”。
实现原理
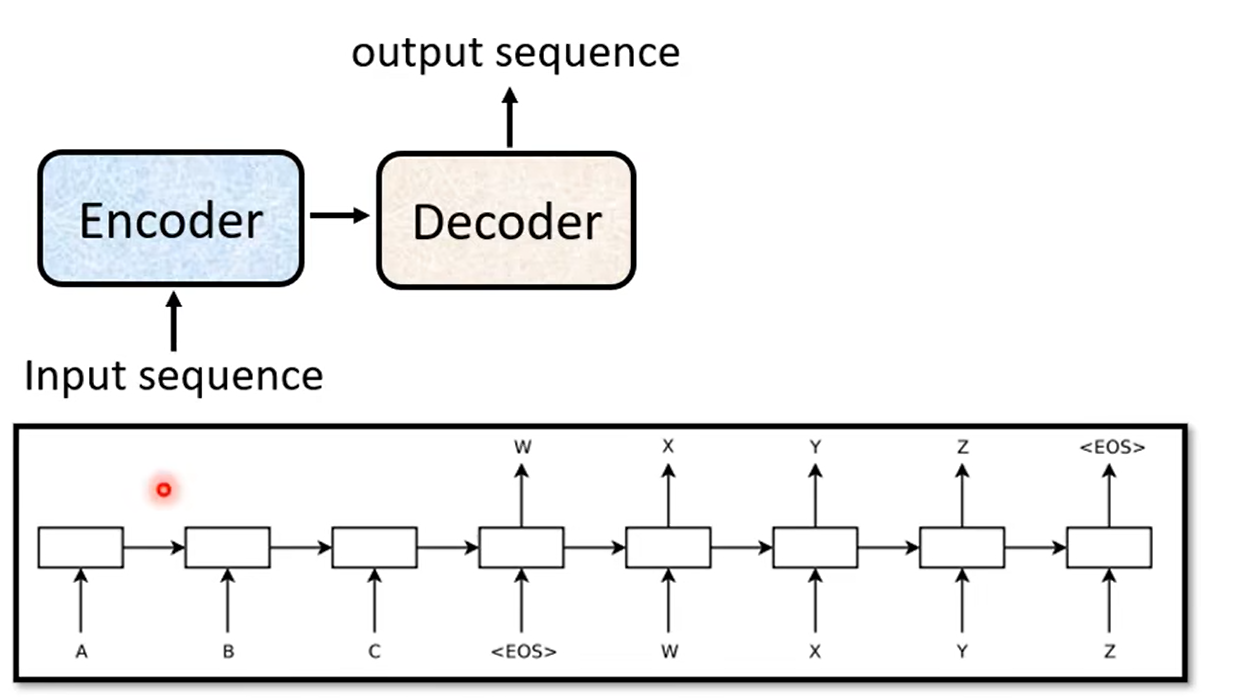
seq2seq的一个基本原理就是将input seq输入给encoder,然后再通过decoder输出output seq,早期的seq2seq如上图所示,还是一种比较简单的结构,就像上节讲过的RNN结构,<EOS>代表end of seq,可以看出就是简单的对RNN输入seq,然后处理后输出一个seq,如果是从左往右完整遍历这个过程,确实做到了对整个输入和输出“联系了上下文”。
Encoder
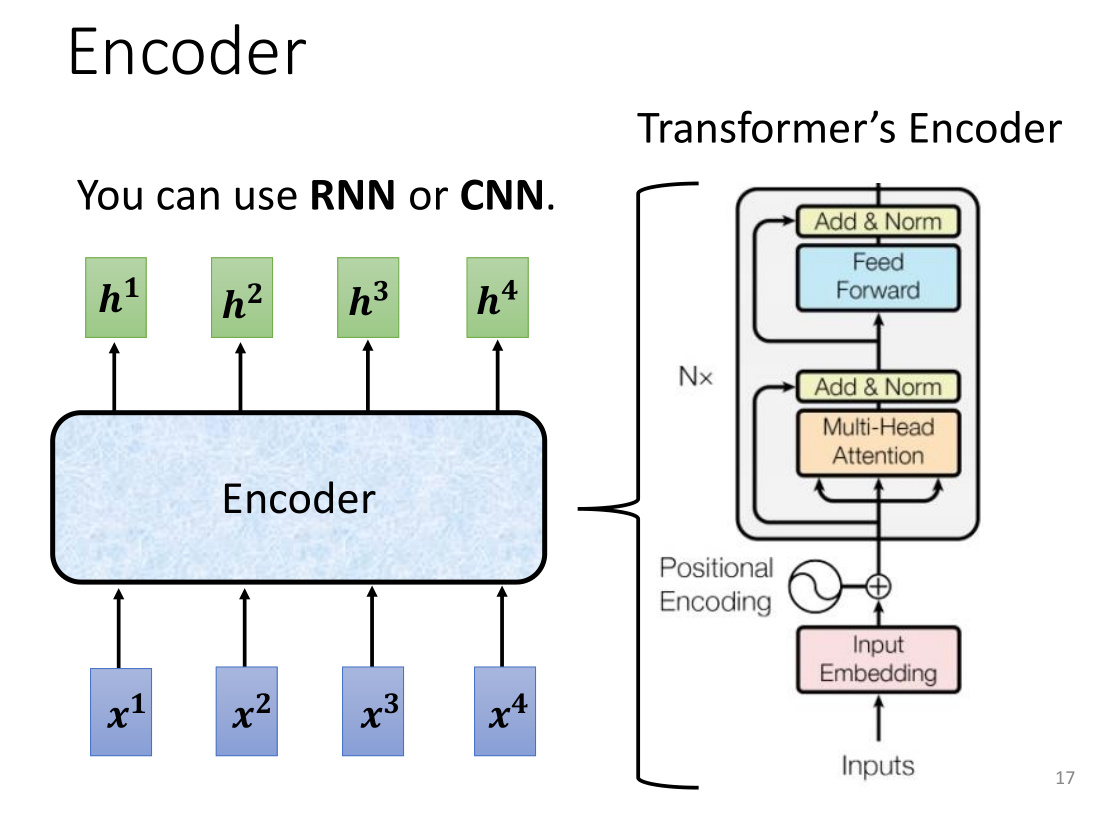
首先我们来讲encoder的内部结构,本质上就是给出input的一排向量输出为另一排向量,这个地方用我们之前讲过的self-attention,RNN,CNN都能实现这一功能。我们介绍的重点还是transformer的encoder。
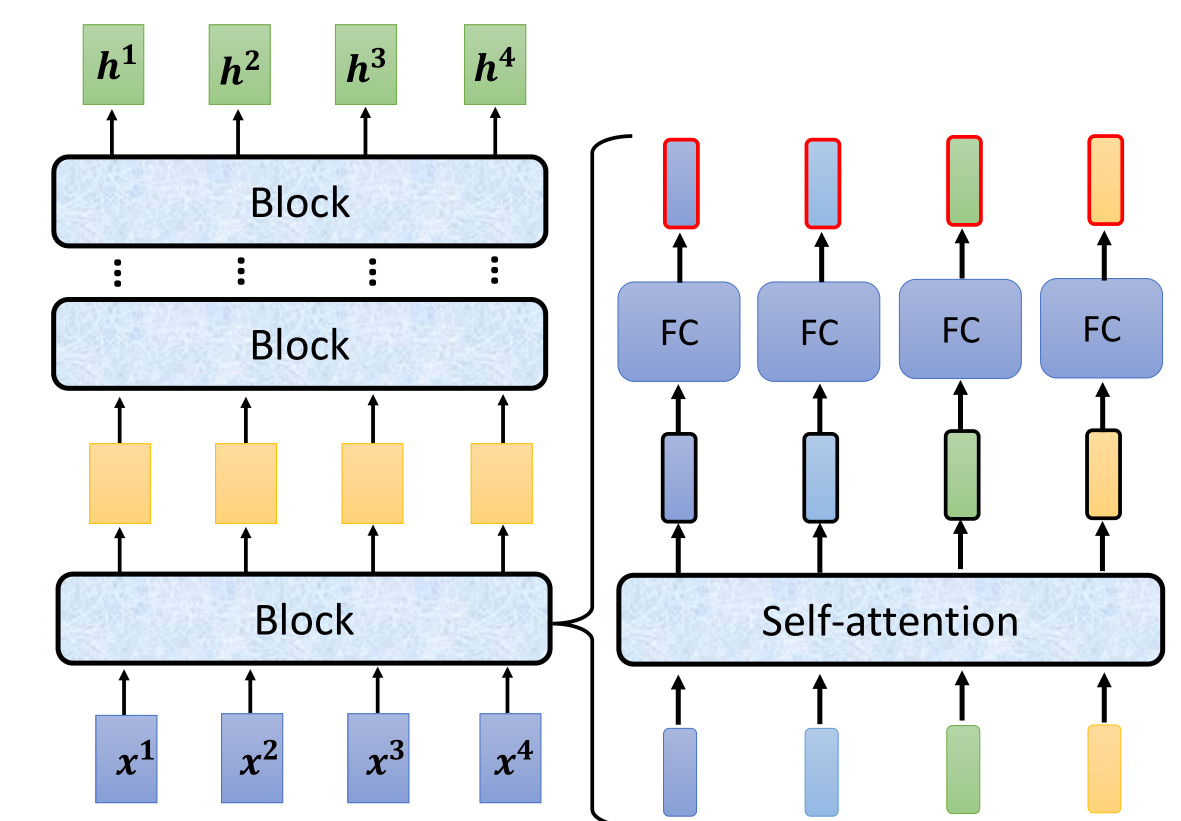
这个encoder拆解开来,里面有很多的block,每一个block的功能就是接受一排输入向量,再输出一排向量,其中每一个block我们并不能称为NN的一层,因为每个bolck里面还有好几个layer,首先,输入到这个block的一排向量会进入到self-attention层来进行labeling,再将输出的vector输入到FC层得到最终的block的输出结果。
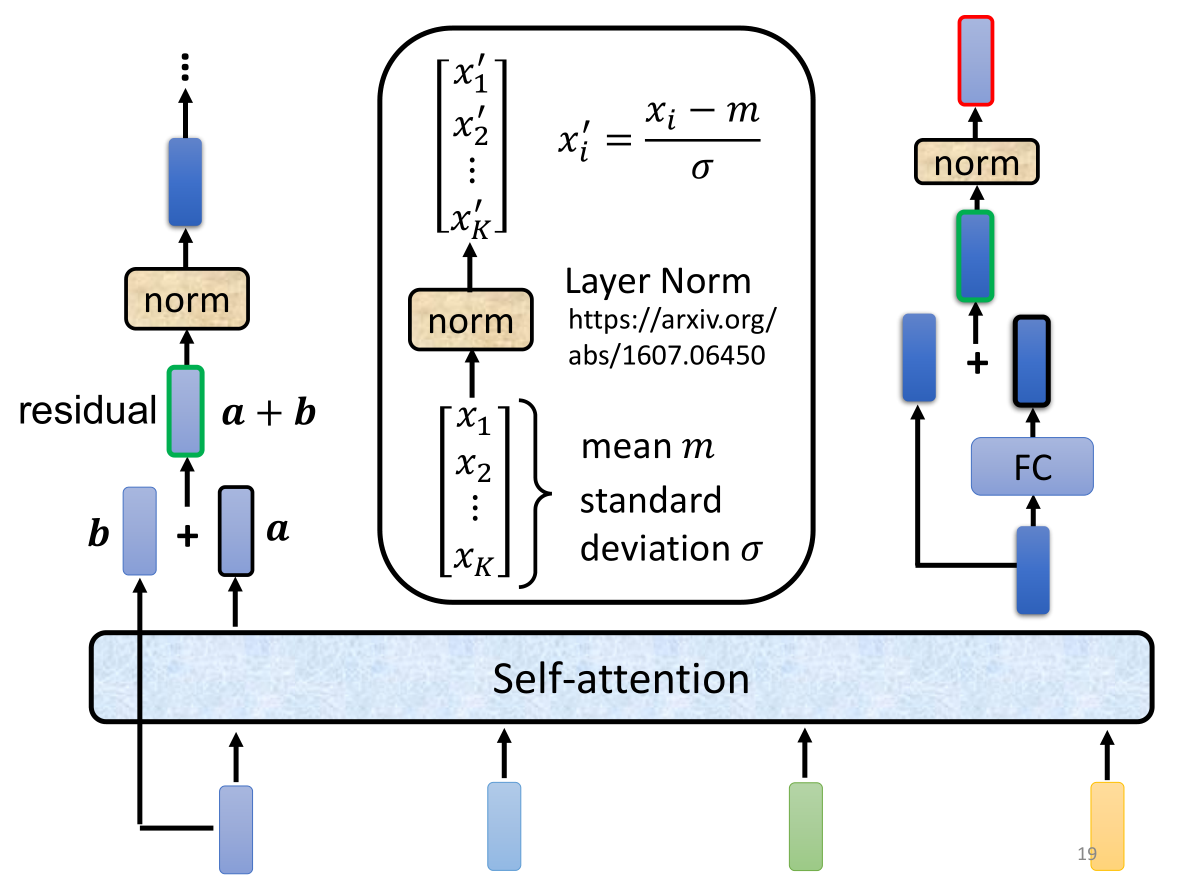
实际上在transformer里面block更加复杂,对于self-attention得到的对应输出向量我们标记为a,原向量标记为b,然后我们进行一个称为residual connect残差连接的操作—— a + b a+b a+b(解释一下残差连接的作用,我们假设 b = F ( a ) b=F(a) b=F(a),残差连接后就是 a + b = a + F ( a ) a+b=a+F(a) a+b=a+F(a)。因为增加了一项,那么该层网络对x求偏导的时候,多了一个常数项,所以在反向传播过程中,梯度连乘,也不会造成梯度消失。),随后我们将这个结果normalization标准化,不过不是用常见的batch normalization,而是使用一个叫Layer Norm的方法,好处在于不用考虑batch,我们通过对同一个样本的不同dim计算输入向量的均值 m m m和标准差 σ \sigma σ(而batch是计算不同样本的同一个dim,一个输入特征 x i x_i xi就是一个dimension,简单理解的话batch就是对所有输入向量按行计算而Layer是对每个向量按列计算),然后得到标准化后的输出 x ′ x' x′,然后我们将 x ′ x' x′作为FC的输入再来一次residual connect,再Layer Norm一下,才能得到最终的单层block结果output。
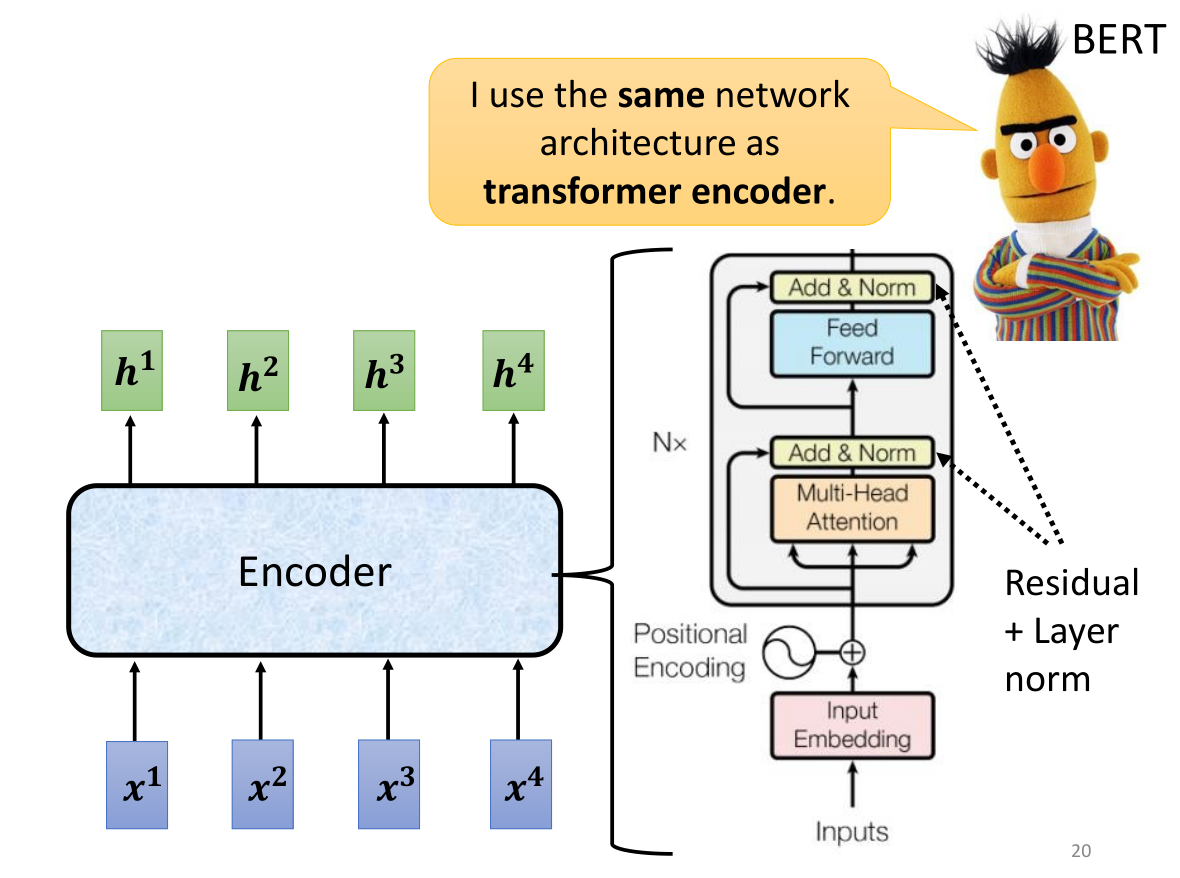
那么上图是一个transformer encoder的具体结构,首先我们给出inputs的seq,将其embedding后与位置信息positional encoding进行相加得到
b
b
b,为了获得不同性质的相关性光用self-attention肯定是不够的,所以需要多头注意力机制,然后将其送入一个multi-head attention得到
a
a
a,与未处理的输入
b
b
b进行residual + Layer norm,然后再送入Feed forward(在transformer里我们常用的是FC——Fully Connect network),再来一次Residual + Layer norm。这就是一个完整的block的输出,一个Encoder一般存在N个block,所以要经历N次整个block的计算才能从input
x
x
x得到output
h
h
h。顺带一提,BERT和transformer encoder使用的是相同的网络结构。
Decoder
一般而言,我们使用的Decoder有两种,分别是Autoregressive自回归解码器和Non-autoregressive非自回归解码器。我们分别来介绍一下它们:
Autoregressive自回归解码器
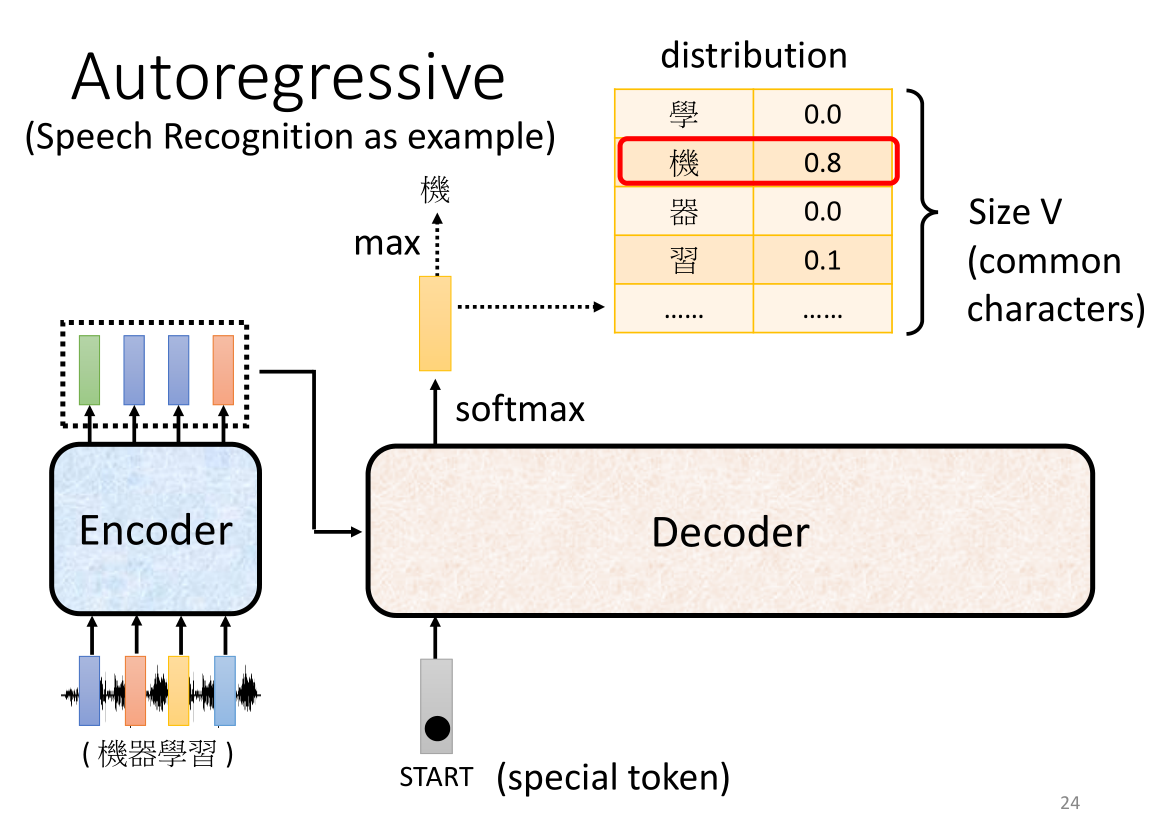
让我们以语音识别为例,我们先不详解Decoder的内部结构,先看看它的实现过程,对于encoder的输出将作为decoder的输入,下方这个长得像多米诺骨牌的图标代表着开始(START,BEGIN,BOS——begin of seq都是它),它是一个特别的token,是我们额外加入到输入来作为开始的标识符,当Decoder识别到这个BOS(机器学习里的token我们可以用上节课讲到的one -hot coding vector来无重复地表示),decoder会给出一个向量,这个向量的size V相当于所有可能的输出结果的长度,在语音识别里它的长度就相当于所有常用的汉字【这个输出的结果代表了识别的所有可能结果,当然我们可以自定义,例如用于英文的话,可以是单个英文字母(总数小),也可以是一个英文单词(总数大),也可以是subword,也就是一些词缀词根(总数适中)】,我们通过对Decoder的输出进行softmax得到这个向量,就相当于将数值转化为了概率分布,因此我们最终会选择概率最大的那个作为输出。
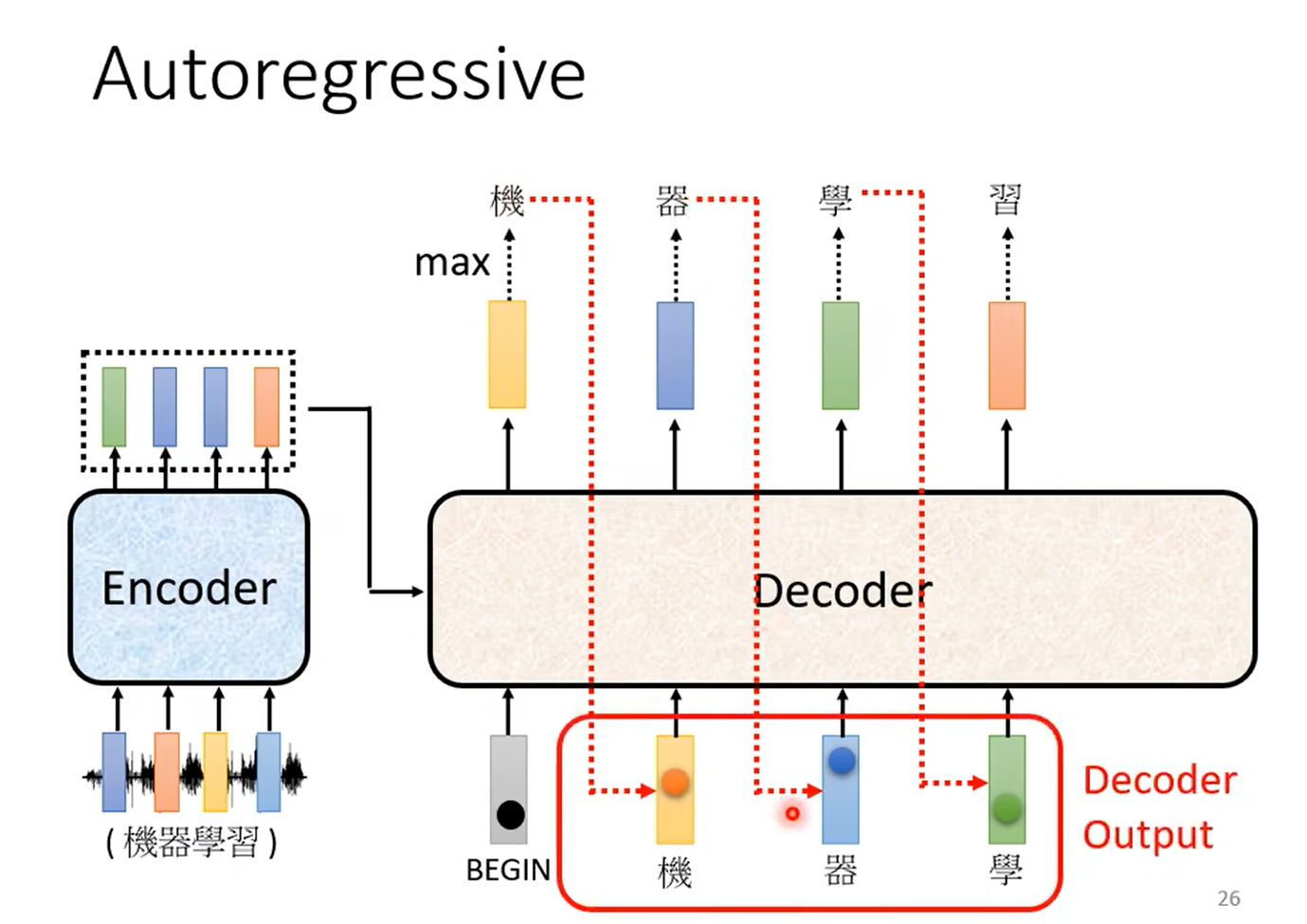
随后我们可以Decoder得到的输出再次作为输入传入Decoder,让Decoder来联系上下文综合判断下一个输出对应的哪个汉字的概率较大,这部分很像RNN的原理,Decoder会将上一次得到的自己的输出作为下一次的输入,然而它有可能会产生一些错误的辨识结果,例如把“器”认成了“气”。那么这样有可能会产生error propagation误差传递的问题,也就是一步错步步错,后面的错误会越来越大。(后面会介绍一种避免这种问题的方法 )
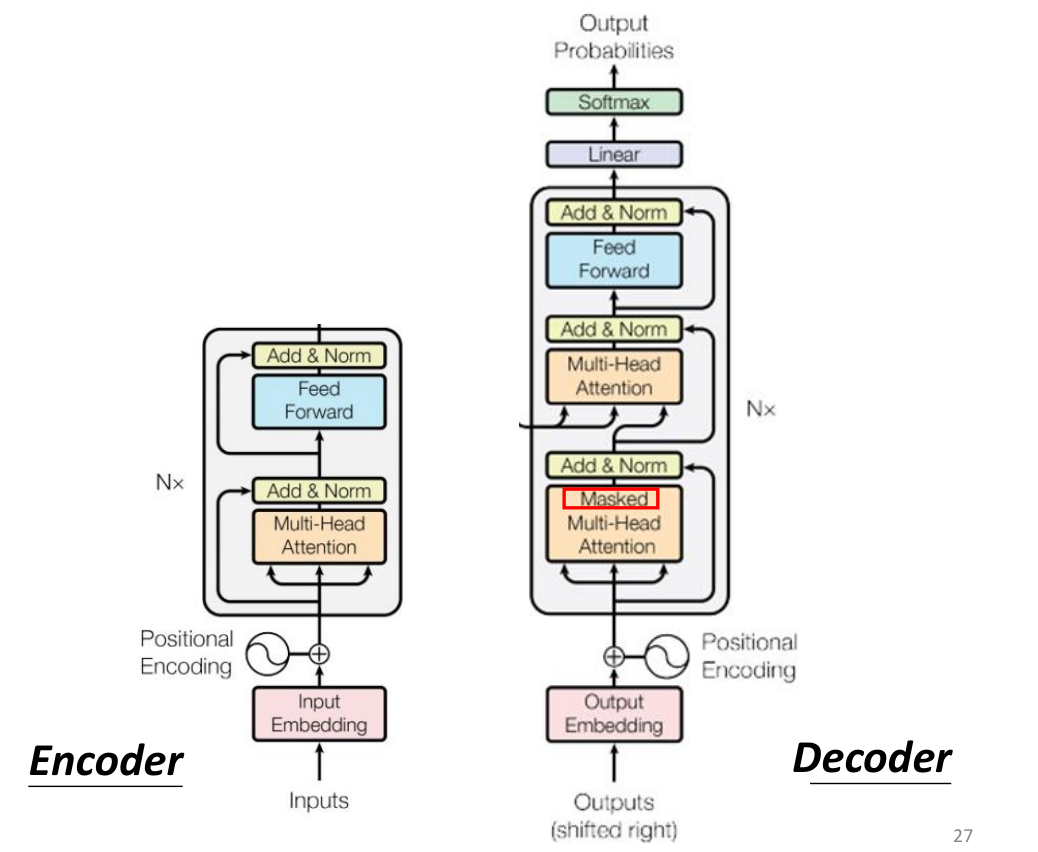
从结构上来看,Decoder和Encoder并无太大差别,Decoder的block中间多了一部分内容,并且第一层的注意力机制使用的是Masked Multi-head Attention,最终的输出结果需要liner线性变换后再softmax转为概率。
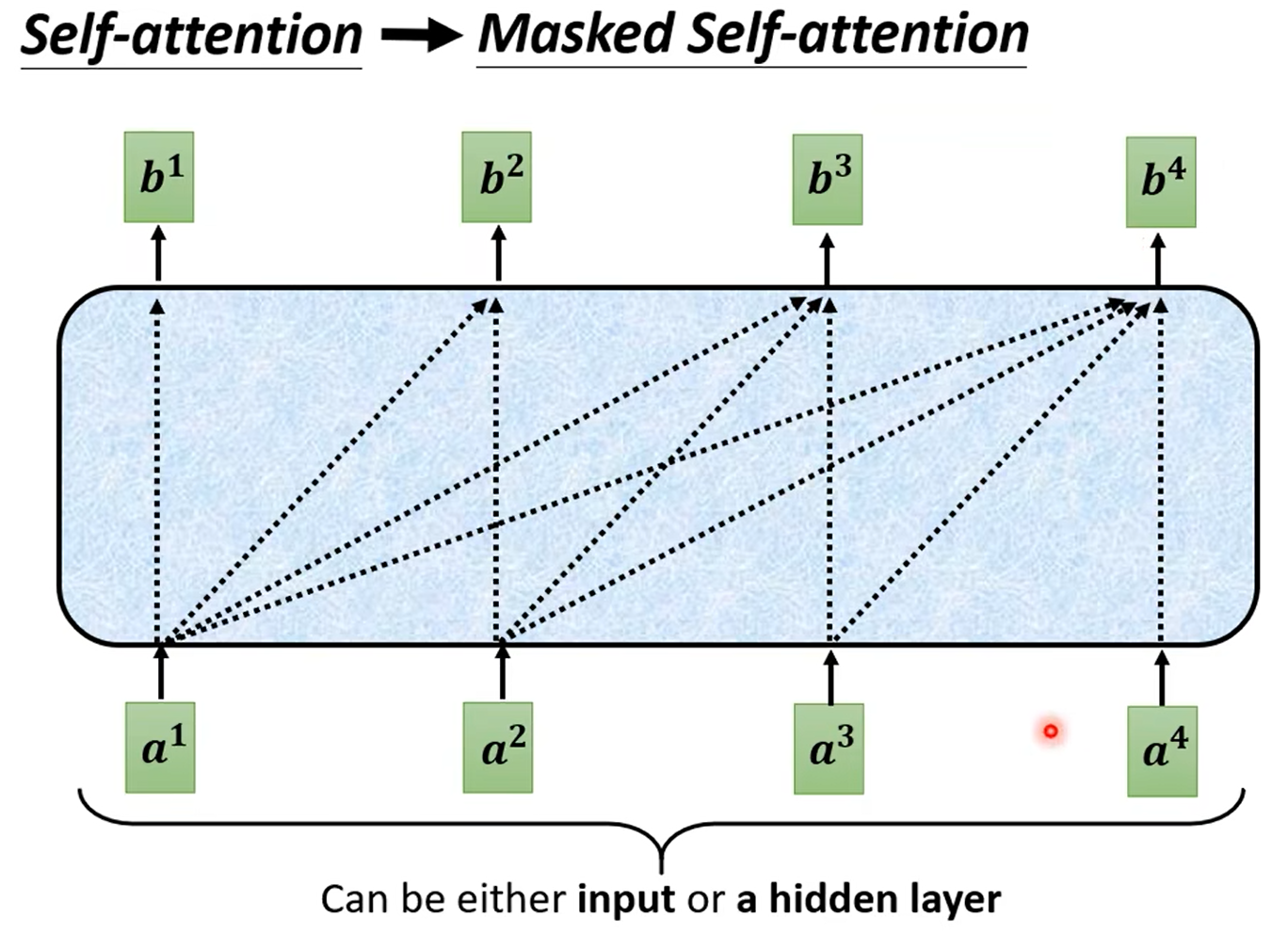
让我们看看什么是Masked self-Attention,之前讲self-Attention的时候我们说每个输入都是考虑了所有input的,例如每个 b b b需要考虑 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4,但是再Masked self-Attention里 b 1 b_1 b1只会考虑到 a 1 a_1 a1; b 2 b_2 b2只会考虑到 a 1 , a 2 a_1,a_2 a1,a2以此类推…整个attention的结构其实和我们之前讲的RNN是一模一样的。并且还隐含了对于input的位置信息的需求。
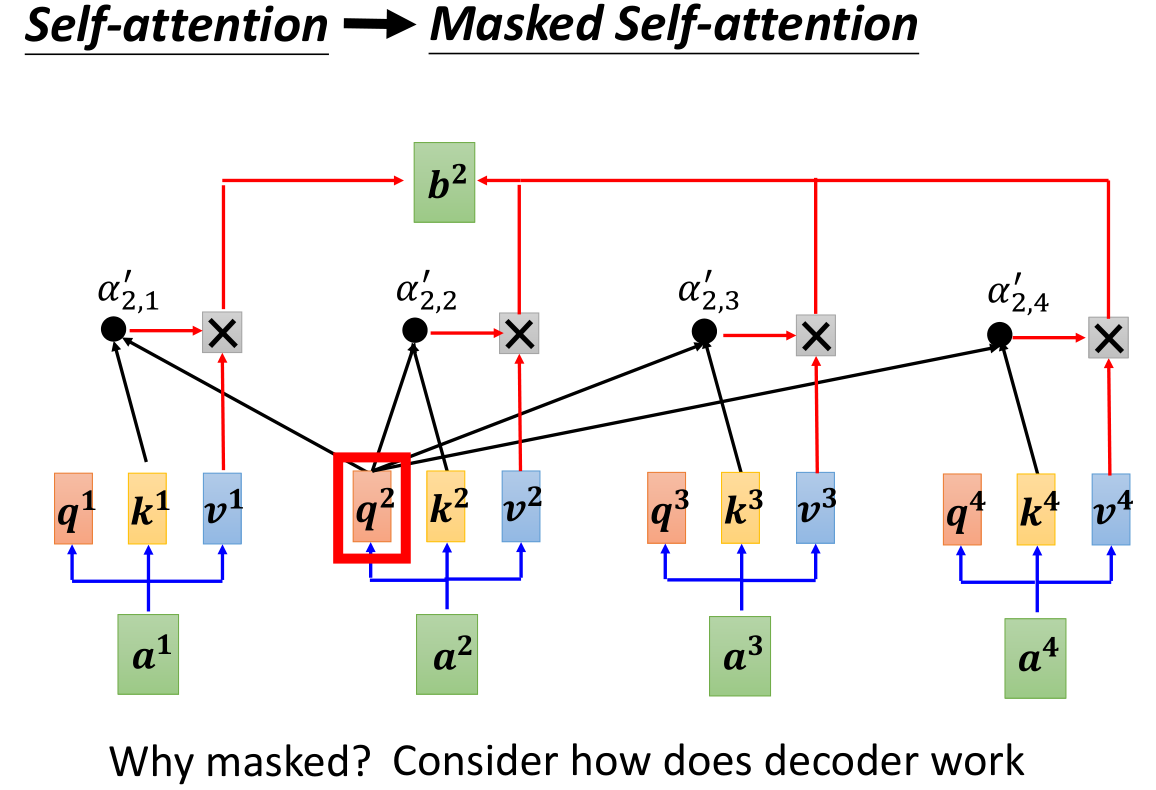
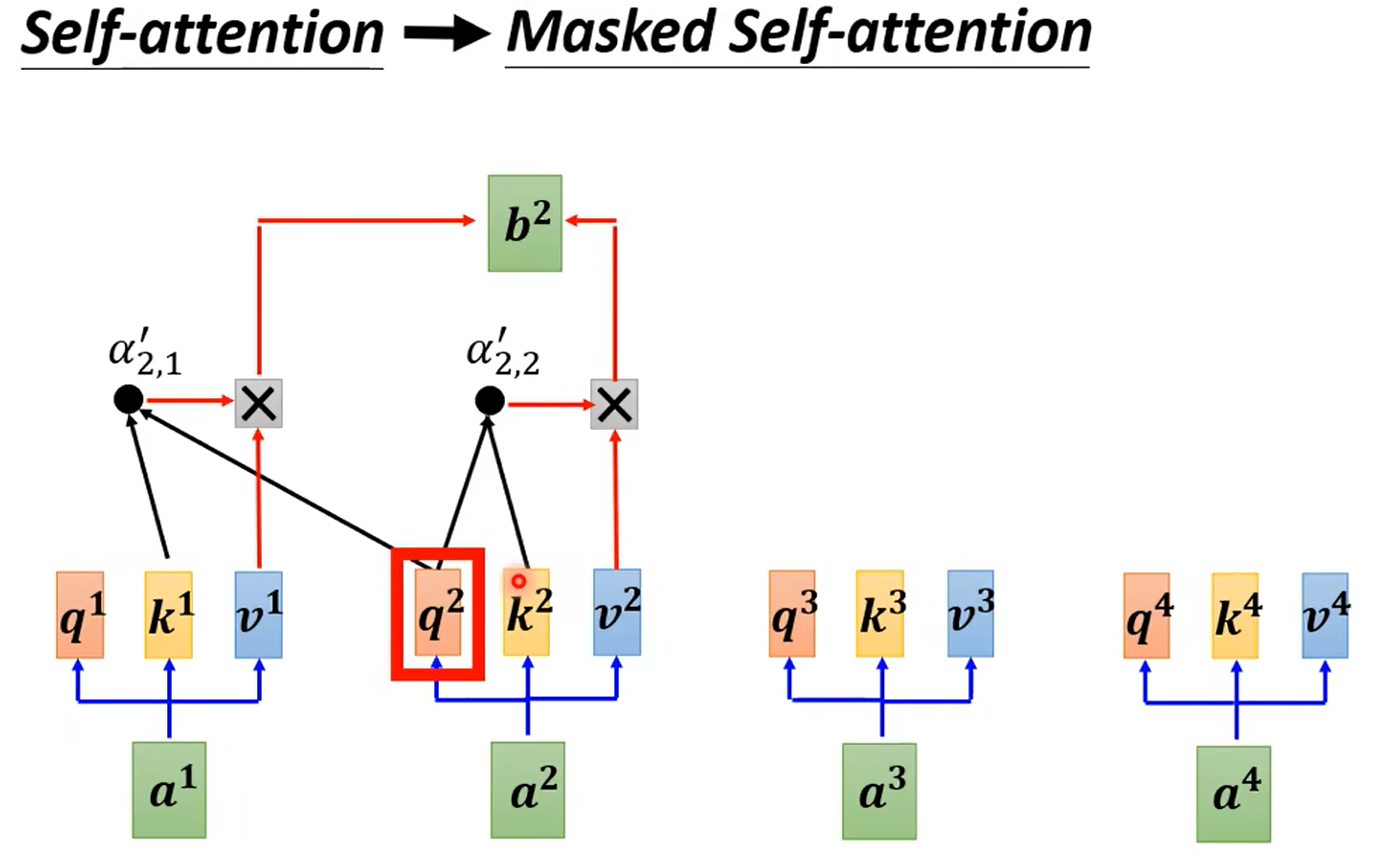
以 b 2 b^2 b2为例,我们来看看计算过程,之前我们在self-attention的时候, b 2 b^2 b2的计算需要 q 2 q^2 q2和其他所有输入向量给出的 k k k进行点积再乘以对应的 v v v,现在,Masked self-attention不需要 a 3 , a 4 a^3,a^4 a3,a4了, q 2 q^2 q2只会和 a 1 , a 2 a^1,a^2 a1,a2的 k , v k,v k,v进行对应的计算,再sum后得到 b 2 b^2 b2。
那么为什么我们需要这个masked?其实原因很简单,因为不同于我们对句子的输入,在encoder的时候,一个句子例如“I saw a saw”,四个单词,机器可以同时进行阅读,这四个单词是同时输入进我们的model里的。但是对于decoder是不一样的,我们刚才在上面的大体结构上讲解decoder的时候,我们说过每一次decoder的上一次output结果需要作为下一次input的输入,因此decoder是一种逐个输出的结构,那么对于未输出的向量自然是看不到的,因此我们会选择masked的这种结构。
MultiHead-Attention和Masked-Attention的机制和原理
这篇文章解释了为什么decoder要选择这样的输入输出模式:
假设一下如果不使用masked,而直接使用self-attention结构,那么假如我们输入“机”,那么decoder理所当然的可以识别出”机“,编码为 [ 0.13 , 0.73... ] [0.13,0.73...] [0.13,0.73...],那么假如我们输入“机器”,而decoder在辨认第一个汉字的时候,提前注意到了后面的器,那么“机”的编码可能会变成 [ 0.95 , 0.81... ] [0.95,0.81...] [0.95,0.81...],总而言之由于上下文的干扰导致了我们的两个输出结果产生了不同,但是问题是它们的输入实际上可以说是同一个输入,而对于同一个输入却无法得到同一个值,这样就可能会让网络有问题。所以我们为了不让“机”字的编码产生变化,所以我们要使用mask,掩盖住“机”字后面的字,也就是即使他能attention后面的字,也不让他attention。
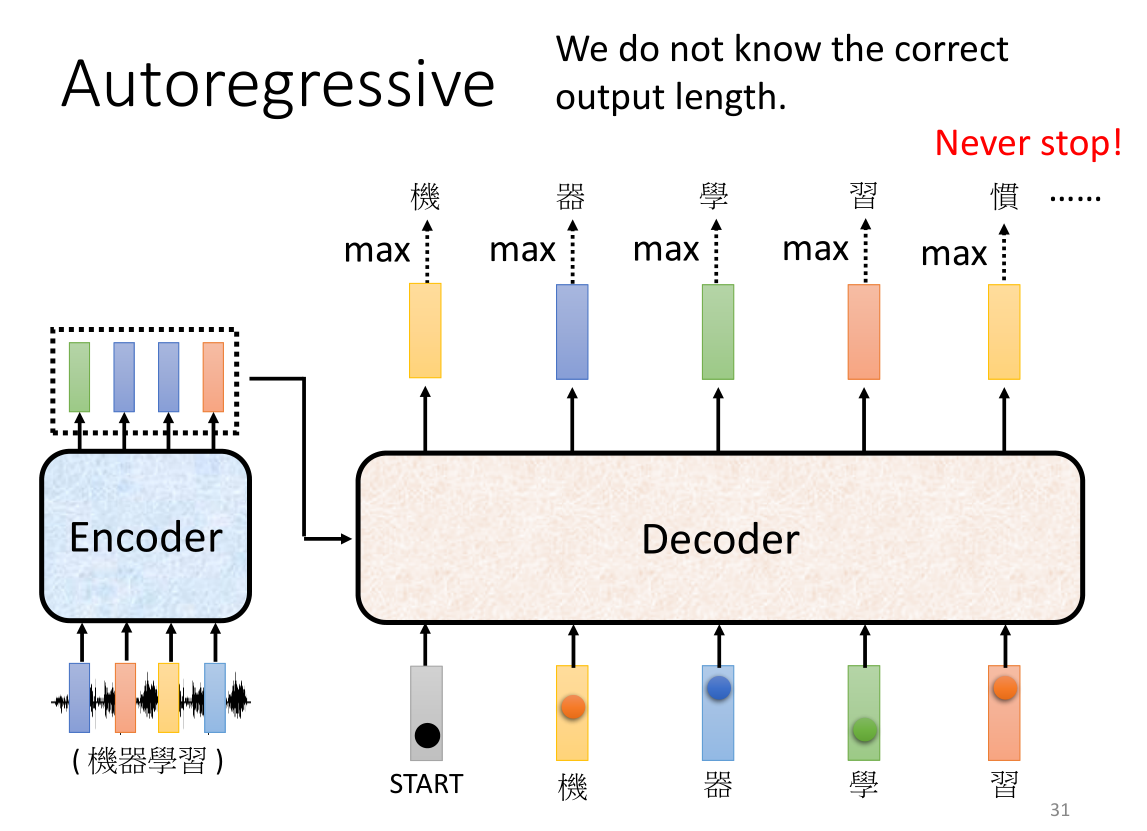
此外我们说过,seq2seq最后的输出长度是不确定的,因此decoder只能通过机器自己的判断来决定输出的seq的长度。而正是由于这种模式,因此如果不加以干涉或制止的话,Decoder接下来就会无限地根据之前的输入来给出新的输出,就像一个文字接龙一样——例如:迅雷不及掩耳盗铃儿响叮当仁不让我们荡起双桨…
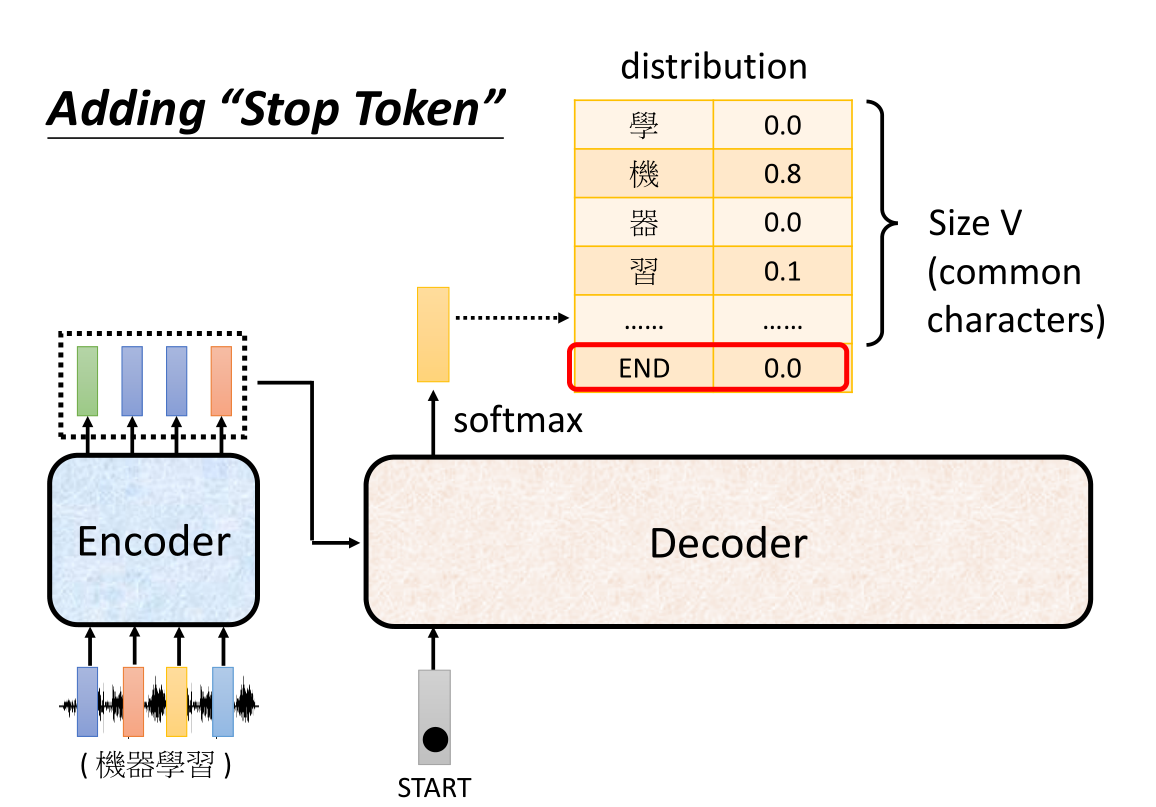
为了避免文字接龙,我们的解决方法其实很简单:之前我们在开始的时候会给出一个讯号——就是BOS这个特殊的开始token,那么同样的我们可以也给出一个特殊的停止token——EOS来代表结束(当然两个token可以用同一个符号来表示)。当然由于输出结果是一个概率分布,所以我们就需要在这个概率分布中加入我们的结束token。
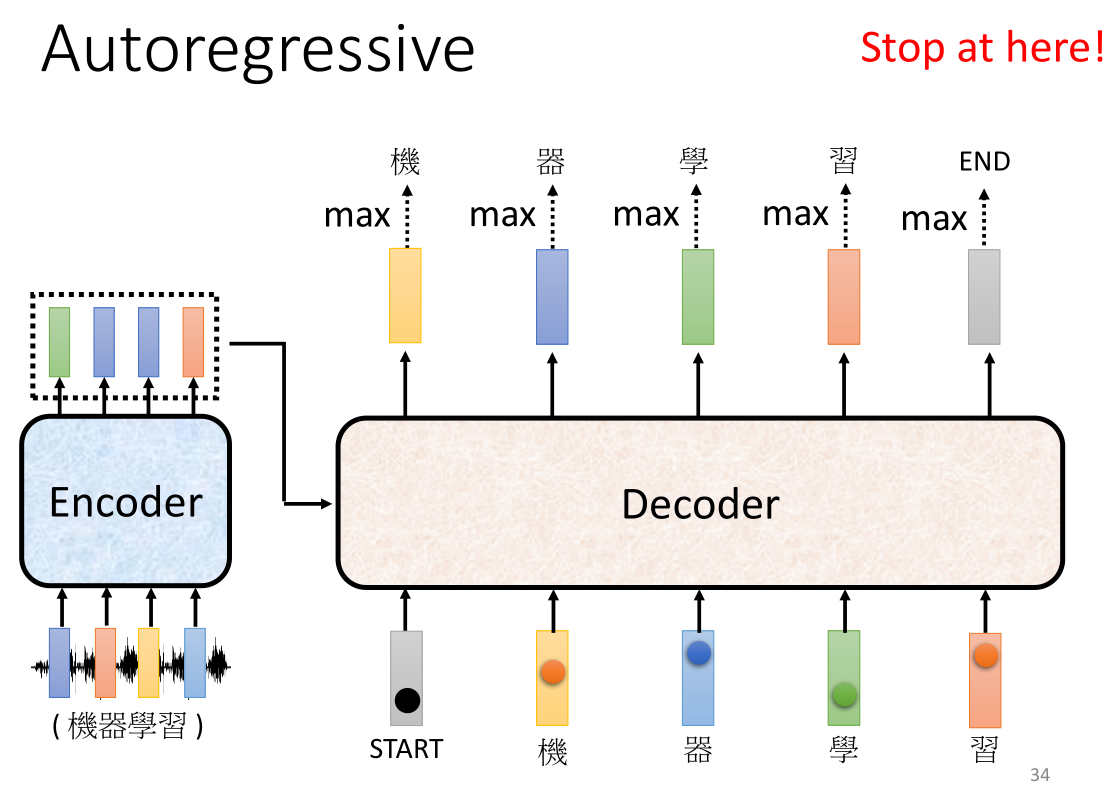
最后我们的Decoder应该在合适的时候输出这个特殊的向量结果,然后程序结束。
Non-Autoregressive非自回归解码器
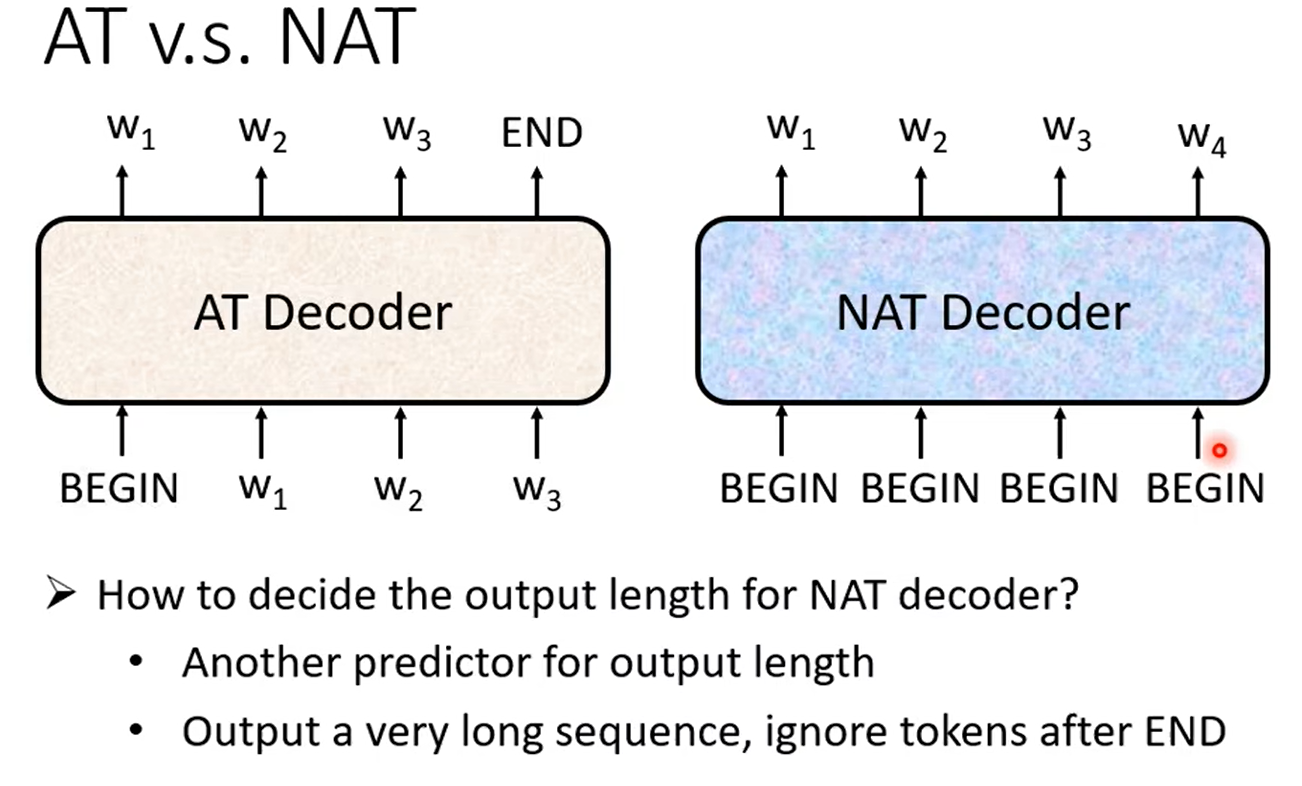
我们刚才讲的是AT Decoder,而现在讲的NAT Decoder的原理是我们的输入给出一排的BEGIN的token,然后对应的token产生了相同数量的一排output,这样就结束了,一步并行计算就能完成句子的生成。
但是有个问题,我们说seq2seq的最后输出长度我们是不知道的,既然如此,我们如何能确定要给出多少个Begin的token?
一个方法是给出一个classifier分类器,让分类器接收Encoder的output结果来判断应该给出多少个begin的token。
另一种方法直接给出一堆begin的token,例如我们已知句子的长度一定不会超过300个字,那么我们就直接给出300个begin的token,那么肯定有个对应的输出会输出END的结果,只需找到这个END的位置,然后包含其左边所有的输出就是我们所需的正确输出,而右边的输出我们就直接丢了不管。
NAT的一个好处就是并行,AT这种结构需要一个一个地输出,因此是串行的。因此NAT的结构会比AT要快;NAT的另一个优点就是可控的输出长度,例如我们用classifier来决定NAT的长度,我们就可以对classifier进行数乘来手动控制NAT的长度(例如语音识别,如果classifier/2就能使得语速加倍)
不过目前AT的效果还是要比NAT要好的,目前研究的热门也是如何让NAT变得和AT一样好。尤其是multi-modality多模态领域AT的效果更加显著。
Corss-attention
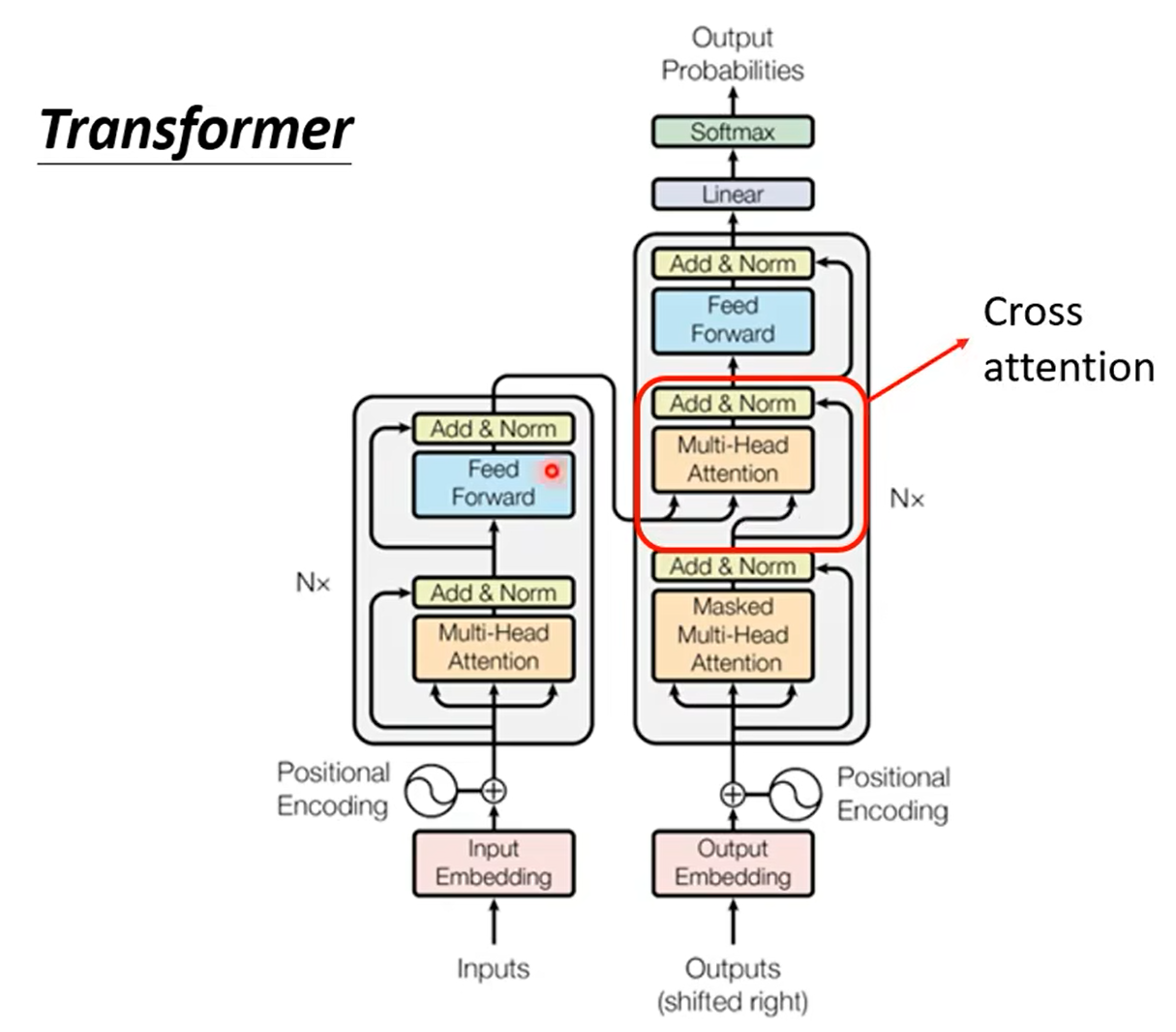
那么讲完了masked multi-head attention,我们再讲解一下中间多出来的这个部分,我们称之为——Cross attention交叉注意力机制,其中两个输入来自于input,另一个来自于output的上一层
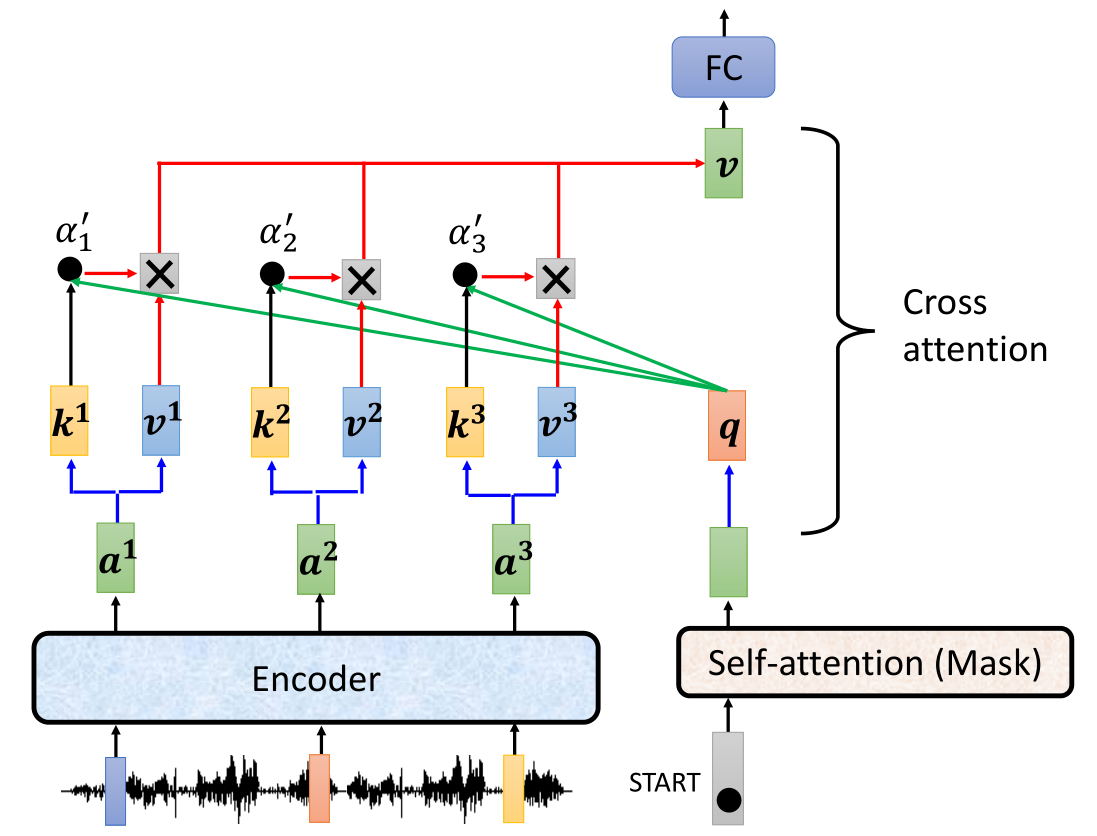
这个Cross attention层使用mask层得到的向量所计算出来的 q q q,然后用Encoder计算出的向量来得到 k , v k,v k,v,并进行了attention的分数计算 α ′ \alpha ' α′,当然我们也可以对 α ′ \alpha' α′进行softmax转化为概率。所以对应的输入一个来自于mask层,另外两个来自于Encoder。最后得到的 v v v是用于作为下一层的Feed Forward Network(FFN,这里是FC network)的输入。
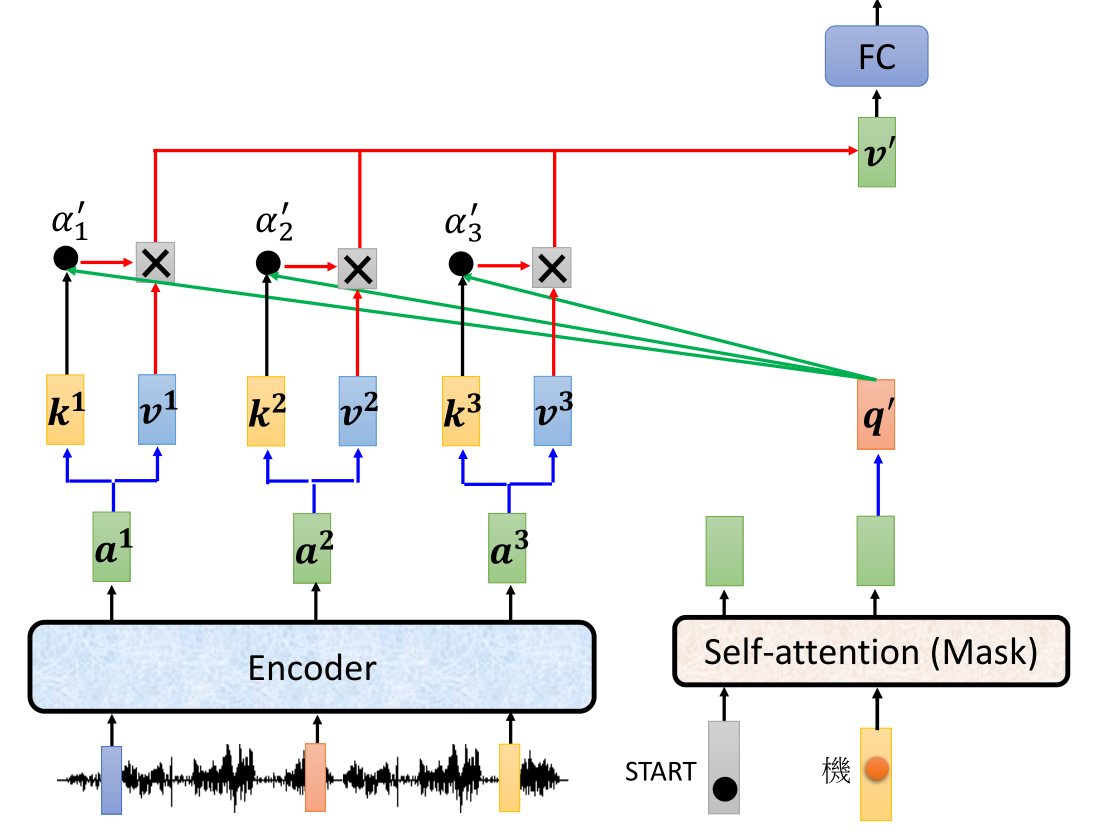
对于mask层的其他输出向量,也需要进行cross attention的计算。
总结
让我们来总结一下transformer的整个结构。
首先transformer用于解决seq2seq的问题,seq2seq可以让机器自行决定输出的seq的长度,因此会表现出一些特殊的性质,尤其是当我们对seq2seq的model进行硬train的时候,机器竟然也能做到较好的效果。
transformer的整个结构就是 i n p u t → E n c o d e r → D e c o d e r → o u t p u t → D e c o d e r . . . . . . → e n d input \to Encoder \to Decoder \to output \to Decoder...... \to end input→Encoder→Decoder→output→Decoder......→end。让我们解析一下完整的结构:
首先对于输入inputs,我们需要先embedding为对应大小的向量,并加入Positional信息然后送入到Encoder;Encoder由N个block组成,每个block内都有许多的layer,首先input的向量会经过一个Multi-head attention来计算不同性质的相关性,并通过residual connect避免梯度消失,然后使用layer Norm来进行标准化。接下来将这个output输入到FFN中(transformer中使用的是FC),然后再次使用residual + Layer Norm。重复上述的block 共N次得到最终Encoder的输出结果。
接下来这个输出将作为Decoder的input,首先对这个output进行embedding,再加上位置信息positional encoding,接着送入到Decoder作为input,首先需要经过masked multi-head attention,masked类似于RNN只会考虑之前时刻输入的向量,相同的,计算attention以及residual + Layer Norm。随后这个output向量经过参数矩阵计算后将被作为 q q q,而对应的去和encoder里给出的multi-head self attention层中 a a a计算出的 k i , v i k^i,v^i ki,vi进行attention的计算,得到注意力得分 α ′ \alpha ' α′(也可以对其进行softmax等操作进行加权计算)并sum得到 v v v 并residual + Layer Norm,随后送入到FFN(FC)并再次residual + Layer Norm。整个block重复M次,直到最后的output我们还需要进行线性变换Liner之后再使用softmax转化为一个概率分布,来得到max的概率对应的输出结果,然后这个Decoder的output将作为下一次Decoder的input重复上面的计算流程,直到得到的输出为EOS代表了整个过程的结束。
Training
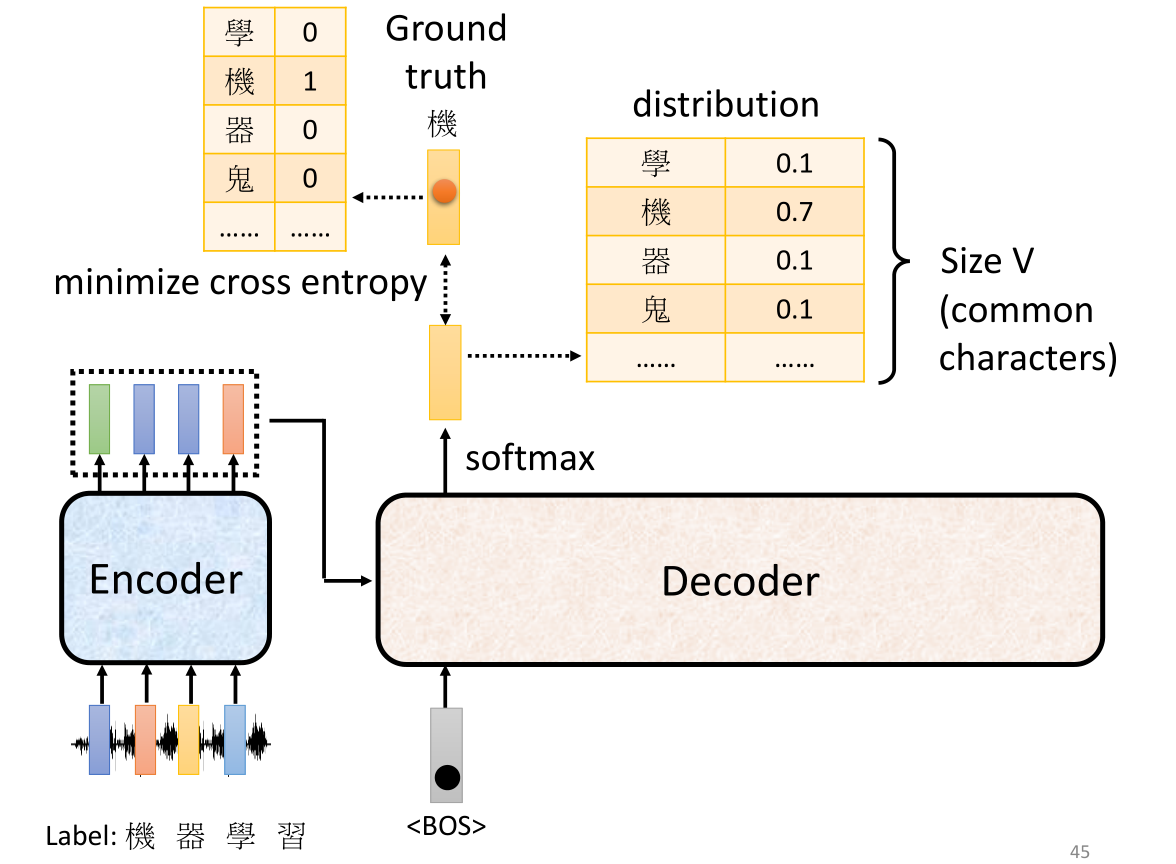
此处以“机”的识别为例,Decoder的输出结果是一个概率分布,而最终我们得到的结果向量应该是一个只有“机”是1,其他都是0的概率分布。对于Decoder的概率分布而言,最好的识别效果肯定是“机”的概率接近于1,而其他字符的概率接近于0,也就是整个Decoder给出的概率分布要接近最后输出结果的这个概率分布。因此两个概率分布越接近,代表了训练效果越好。所以我们希望两个概率分布接近的话,从数学上来说就是最小化交叉熵=最大似然对数。
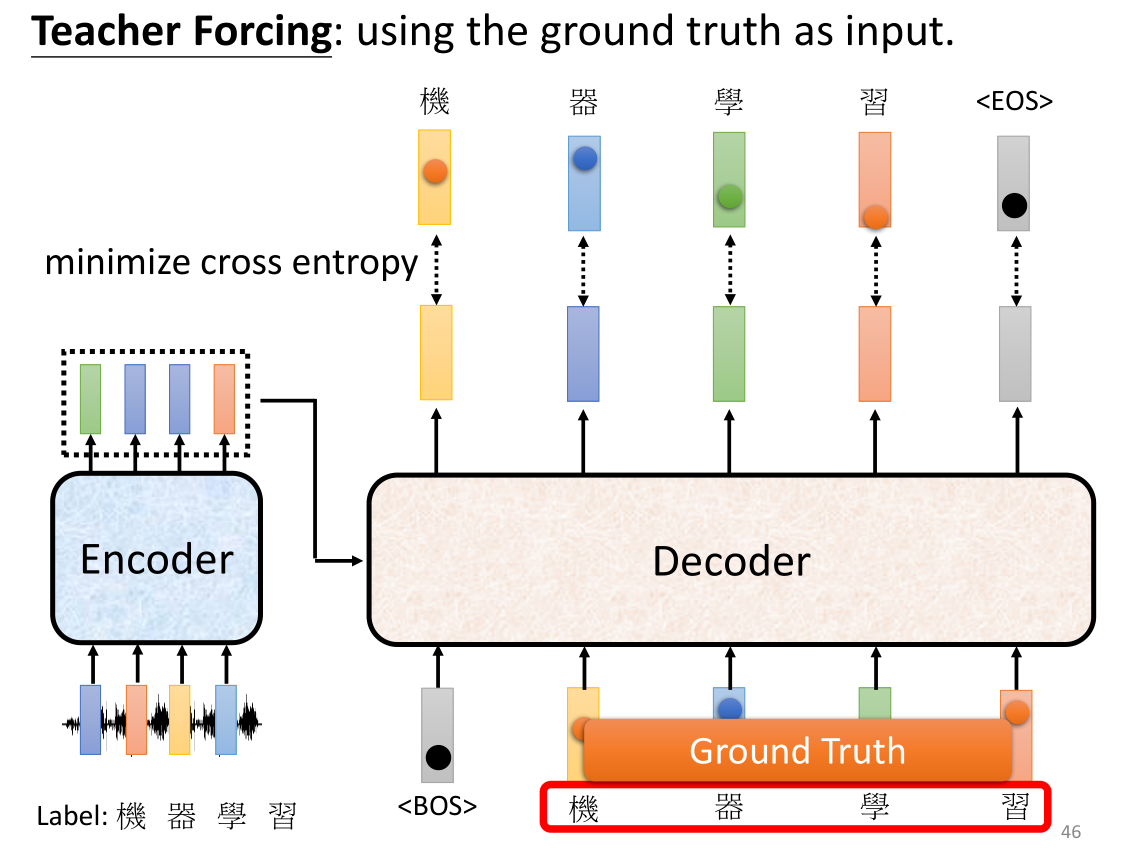
因此训练过程就是,我们可以给出Decoder最终的正确答案+EOS,让机器在训练过程中调整参数使得所有的输出的交叉熵之和最小,除此之外,由于Decoder输出是上一次的输出,为了保证训练我们也可以将正确结果直接输入给Decoder,这种方法被我们称为Teacher Forcing。但是这个方法还是有一个问题,例如在使用的时候我们是不可能提前给出正确答案的,就像平时都是抄作业,一到考试就没有答案给你抄了,所以到考试的时候就难以考到高分。
解决方法是:Scheduled Sampling
trick
最后要讲的属于拓展内容,就是一些优化网络的技巧
Copy Mechanism
不知道大家有没有和chatGPT,new bing这些chat bot聊过天,例如你说“你好我叫王大锤”,一般机器会回应“你好王大锤,很高兴认识你”,那么“王大锤”这个名字一般不属于我们上述说的Decoder的输出的这个范畴,毕竟世界上有这么多人名,几乎任意的词汇都能组成人名,因此不会专门去预测人名。因此这里机器使用了一个Copy Mechanism复制装置的技巧,简单来说就是复制给出的Question里的一些信息,这个技巧也需要我们进行训练。
Guided Attention
由于机器是一个black box,我们没法看到中间的hidden layer是什么,因此直接硬train似乎能解决大部分问题。以课件给出的这个Text2Speech为例,例如让机器读出“发财发财发财发财”,它竟然不仅能读出来还能抑扬顿挫,三次两次发财都是差不多的,但是如果只读一次“发财”结果只发出了“发”的音,问题就在于训练数据上较长的句子样例很多,但是较短的句子训练样本却相对很少,以至于出现这样能读长句却不能读短词的问题。
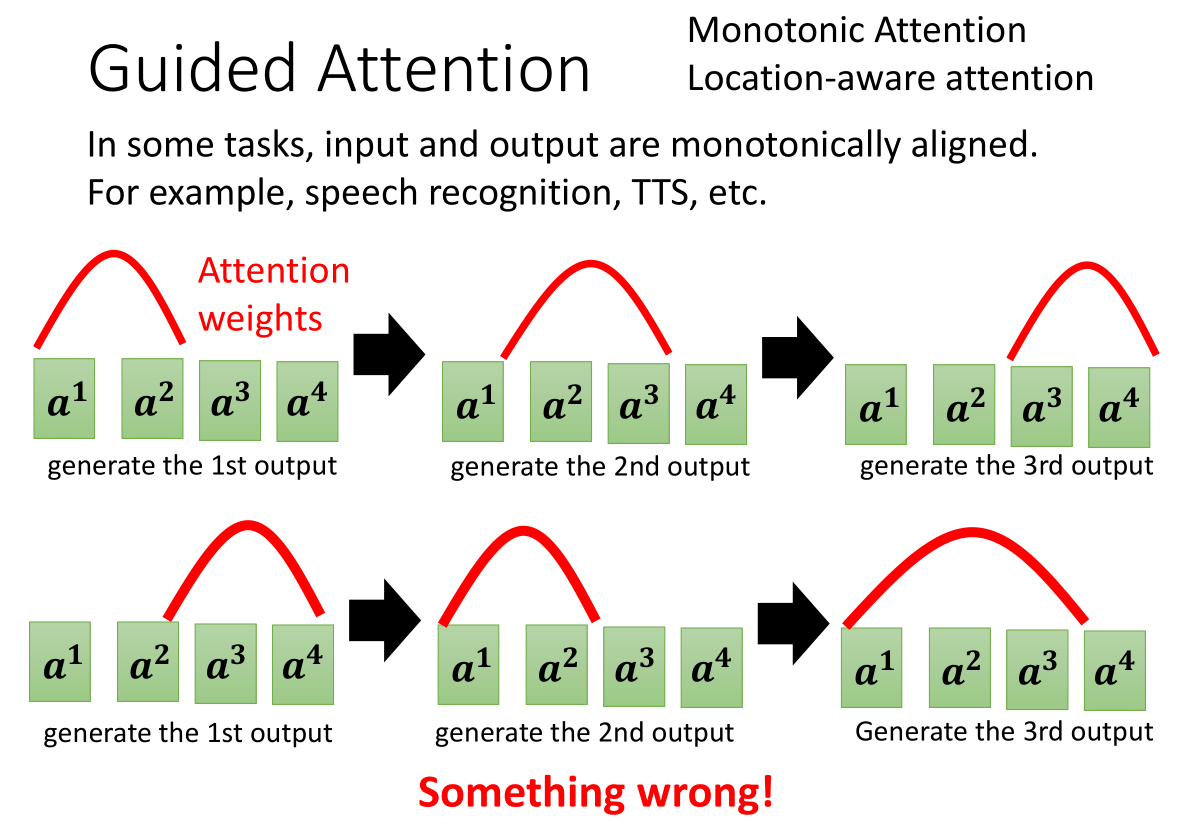
Guided Attention引导注意力在语音辨识和语音识别中是一项很重要的技术,其原理在于引导机器注意到attention的固定方式,例如下面这一行就是一个错误样例,红色曲线代表attention的得分:在生成第一个output结果的时候,机器的注意力却在234(红色曲线经过部分),生成第二个结果了注意力却在12,竟然只瞻前不顾后…因此我们引入Guided Attention,希望结果能像第一列一样,例如第一个输出注意力能看到12,第二个能看到234这样,能够根据上下文综合的考虑。
Beam Search
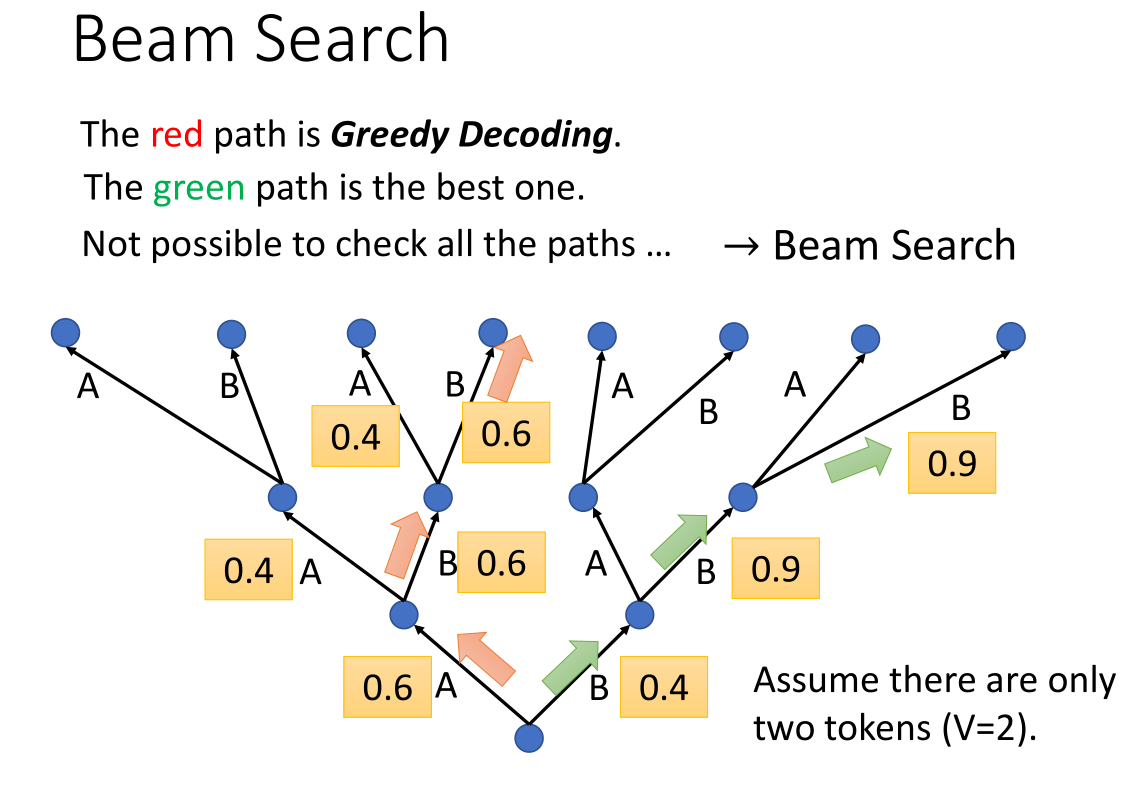
Beam Search集束搜索,我们看看上面的二叉树,其中红色代表了贪心算法的路径,绿色代表了最佳路径。有的时候贪心并不能达到最佳的目的,当然你也可以说“咱们可以先算完整条路径然后再进行贪心选取啊”,但是实际运用的时候面对未知的输出结果是无法做到这一点的。
集束搜索的思想就是确定一个beam size,例如beam size=2,以这个二叉树为例,beam就会同时记住对两条路径同时贪心算法的结果,例如上图中会得到分数第一大和第二大的两条路径。在下一个时刻,又会分布对这两条路径进行一次贪心算法,以此类推。因此beam search保留了不同分支下的最可能输出结果,最后再比较二者哪个更合适。(更细节的就不讲了)
beam search有时有用,有时没啥用,因为虽然它能找出最好的路径,但是有时对Decoder来说,有时例如想要一些确定的结果,那么beam search也许效果更好;但是有时例如我们需要机器发挥一点创造力,创造一个故事或者TTS生成语音什么的,引入随机性的效果反而更好,不找到分数更高的路径反而能得到更好的结果。
强化学习(Reinforcement Learning, RL)
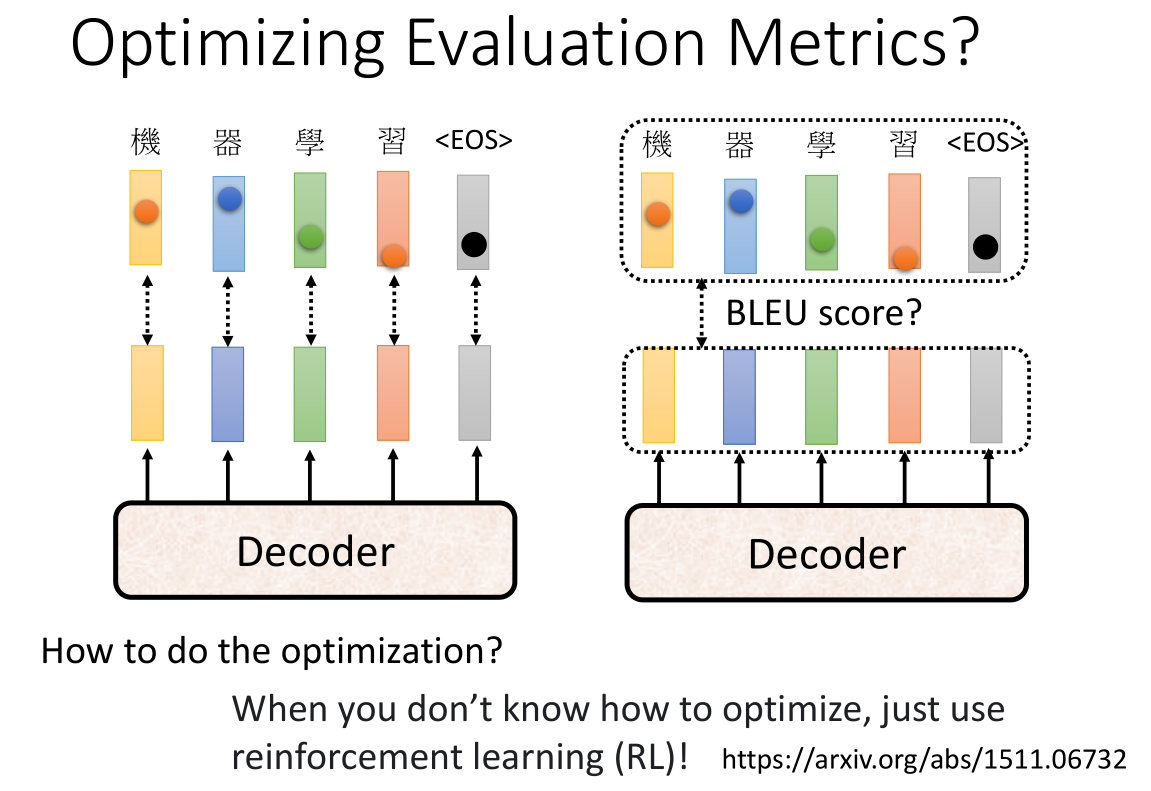
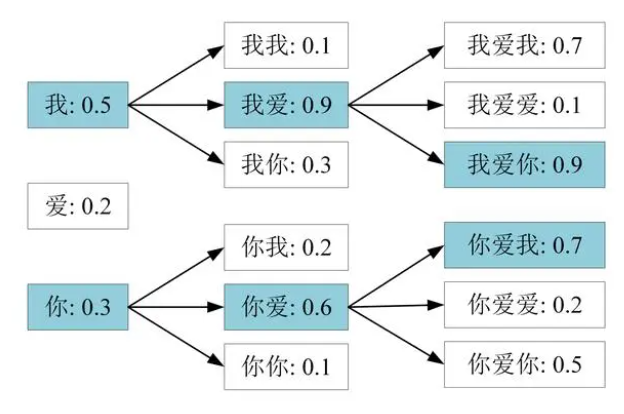
老师还讲到了RL强化学习(为什么不叫强制学习呢),例如上面这个S2T的例子,我们说想要达到最好的训练效果是使用最小化交叉熵,然而最终评判的标准并不是使用交叉熵,而是称为BLEU score的分数来评估模型,也就是说即使最小化交叉熵也不一定能得到最好的BLEU score,所以就有人提出,那我们能不能直接以BLEU score作为训练标准而非最小化交叉熵呢?问题在于BLEU score比较复杂,难以进行参数化。解决方法是——使用RL强化学习,当你不知道如何参数化的时候,直接用强化学习硬train一发也能达到很好的效果。
Scheduled Sampling
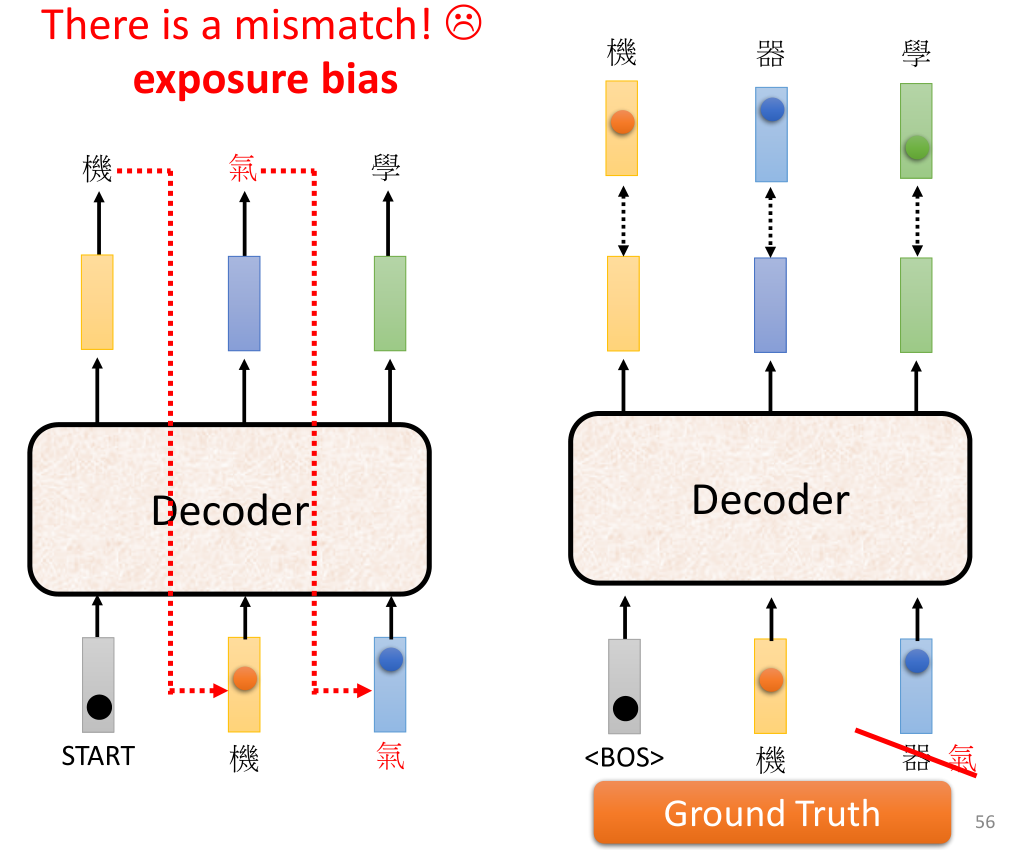
Scheduled sampling(计划采样),这是一种避免Exposure Bias(传递偏差,一步错步步错)的trick,我们说如果对模型Teacher-Forcing只输入正确的样本,那么模型就只会处理正确的输入,那么对于可能的错误输入就无法纠正错误,类似于过拟合导致了缺少泛化性,Scheduled sampling的解决方法是再Teacher-Forcing的时候加入一些错误的输入,让机器看到正确答案的时候同时也要训练纠正错误(例如你某科学得很好,发现了试卷的答案有一个错误)。总体来说,实现思路不是很复杂,不过中间的可控性不高,并且可能需要找到符合数据集的一种更佳方式,可能泛化上不是很好。