目录:导读
引言
1.白盒测试原理
2.自动化测试用例编写
3.UnitTest测试框架
3.1UnitTest组件(测试固件)
3.1.2测试套件
3.1.3测试运行
3.1.4测试断言
3.1.5测试结果
3.2unittest测试固件的详解
3.2.1测试固件每次均执行
3.2.2测试固件只执行一次
3.2.3。测试用例执行的顺序详解
3.3编写测试用例注意的事项
3.4测试套件详解
3.4.1按测试类来执行
3.4.2按测试模块执行
3.4.3按具体的测试用例来执行
3.4.4自定义测试套件
3.4.5分离测试套件
3.5 测试报告
3.6加载所有的测试模块
3.7生成HTML测试报告

引言
Python是一种优秀的编程语言,可以适用于不同方面的开发需求。在软件测试领域,Python也有着非常出色的表现,特别是其自带的UnitTest测试框架。诸如单元测试、集成测试和功能测试等各种类型的测试都可以通过这个框架进行实现。
本文将为您介绍Python中的UnitTest测试框架,并且展示如何使用它来构建一个完整的测试流程。
文章不仅会详细讲解测试框架的基本概念及其应用场景,还会介绍如何编写高效的测试脚本、如何使用第三方工具来扩展测试框架的功能、以及如何对测试结果进行分析和报告。
凭借本文,您将能够全面掌握Python中UnitTest测试框架的全栈应用,从而更好地完成自动化测试任务并提高软件质量。
1.白盒测试原理
简单的来说就是一个白色的盒子,可以直接看见内部的代码来进行测试
2.自动化测试用例编写
不管基于什么测试的框架,自动化测试用例的编写都要遵循一下规则
测试方法
1、初始化
2、执行
3、验证
4、清理
在转到被测系统当中
3.UnitTest测试框架
3.1UnitTest组件(测试固件)
UnitTest是属于Python语言的单元测试框架,它的核心组件具体合一总结为如下:
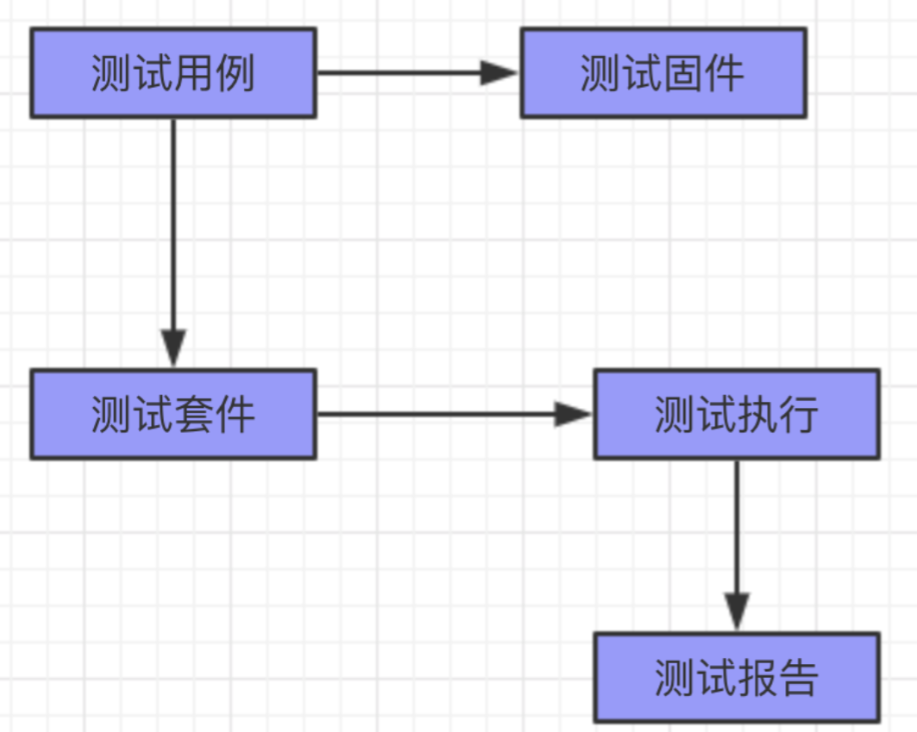
测试类继承unittest模块中的TestCase类后,依据继承的这个类来设置一个信的测试用例类和测试方法,案例代码:
1 from selenium import webdriver
2 import unittest
3
4 class Init(unittest.TestCase):
5 def setUp(self) -> None:
6 self.driver=webdriver.Chrome()
7 self.driver.maximize_window()
8 self.driver.get('https://mail.sina.com.cn/')
9 self.driver.implicitly_wait(30)
10
11 def tearDown(self) -> None:
12 self.driver.quit()该代码为测试固件
3.1.2测试套件
测试套件顾名思义就是相关测试用例的合计。在unittest中主要通过testSuite类提供对测试套件的支持,代码如下
1 from page.login import Login
2 from utils.operationJson import readJson
3 from page.init import Init
4 class LoginTest(Init,Login):
5
6 def test_sina_login_username(self):
7 '''登录验证:验证账户为空的错误提示信息'''
8 self.userName(value='')
9 self.clickLogin()
10 self.assertEqual(self.getUsernameDiv(),readJson()['emailNull'])
11
12 def test_sina_login_emailError(self):
13 '''登录验证:邮箱格式不正确的错误提示'''
14 self.userName(value='asdiwdsi')
15 self.clickLogin()
16 self.assertEqual(self.emailError01(),readJson()['emailError01'])3.1.3测试运行
管理和运行测试用例的对象
3.1.4测试断言
对所测试的对象依据返回的实际结果与期望结果进行断言校验
3.1.5测试结果
测试结果类管理着测试结果的输出, 测试结果呈现给最终的用户来反馈本次测试执行的结果信息。
3.2unittest测试固件的详解
在unittest中的测试固件依据方法可以分为两种方式执行,一种是测试固件只执行一次,另外一种是测试固件每次都执行,下面依据具体的案例来讲解二者。
3.2.1测试固件每次均执行
1 from selenium import webdriver
2 import unittest
3
4 class Init01(unittest.TestCase):
5 def setUp(self) -> None:
6 self.driver=webdriver.Chrome()
7 self.driver.maximize_window()
8 self.driver.get('https://mail.sina.com.cn/register/regmail.php')
9 self.driver.implicitly_wait(30)
10
11 def tearDown(self) -> None:
12 self.driver.quit()3.2.2测试固件只执行一次
使用的是类方法,这样测试固件只会执行一次的
1 import unittest
2 from selenium import webdriver
3
4 class ApiTest(unittest.TestCase):
5 @classmethod
6 def setUpClass(cls):
7 cls.driver=webdriver.Chrome()
8 cls.driver.maximize_window()
9 cls.driver.get('http://www.baidu.com')
10 cls.driver.implicitly_wait(30)
11
12 @classmethod
13 def tearDownClass(cls):
14 cls.driver.quit()
15
16 def test_baidu_title(self):
17 self.assertEqual(self.driver.title,'百度一下,你就知道')
18
19 def test_baidu_url(self):
20 self.assertEqual(self.driver.current_url,'https://www.baidu.com/')3.2.3。测试用例执行的顺序详解
在unittest中,测试点的执行顺序是依据ascill码来执行的,也就是说根据ASCLL码的加载顺序,数字与字母的顺序
优先数字 然后大写字母 、小写字母 切记数字的大笑之不能包含test,值的是test后面的测试点的数字大小,
1 import unittest
2 class WebUI(unittest.TestCase):
3 def test_001(self):
4 pass
5
6 def test_002(self):
7 pass由上述代码可见 代码的执行顺序为 001 002 当然测试点不单纯是数字的,也会有字符串相关的,在Python中,字符串与数字转换为:
chr():数字转为字母
ord():字母转为数字
同时也会有字符串与数字的比较
3.3编写测试用例注意的事项
1、在一个测试类里面,每一个测试方法都是以test开头的,test不能是中间或者尾部,必须是开头
2、每一个测试用例方法都应该有注释信息,这样在测试报告就会显示具体的测试点的检查点
3、在自动化测试中,每个测试用例都必须得有断言,五断言的自动化测试用例都是无效的
4、最好一个测试用例方法对应一个业务测试点,不要多个业务检查点写一个测试用例
5、如果设计到业务逻辑的处理,最好把业务逻辑的处理方法在断言面前,这样做的目的是不要因为业务逻辑 行错误导致断言也是失败
6、测试用例名称最好是规范,有约束
7、是否先写自动化测试的测试代码,在使用自动化测试方式写,本人觉得没必要,毕竟能够做自动化测试的都具备了功能测试的基本水平,所以没必要把一个业务的检查点写多次,浪费时间和人力成本
3.4测试套件详解
UnitTest的测试框架中提供了很多丰富的测试套件,所谓测试套件其实我们可以把它理解成为测试用例的集合,或者可以说理解为一个容器,这个容器里面有很多测试用例、
各个不同测试套件的应用和实战
3.4.1按测试类来执行
按测试类执行,可以理解成为在测试套件中,我们按测试类的方式来执行,那么也就不需要在乎一个测试类里面有多少测试用例,我们是以测试类为单位来进行执行,测试类里面有多少的测试用例,我们都会进行执行
1 import unittest
2 from selenium import webdriver
3 from test.init import Init
4
5 class Baidu(Init):
6
7 def test_baidu_shouye_title(self):
8 '''验证百度首页的title信息'''
9 assert self.driver.title=='百度一下,你就知道'
10
11 def test_baidu_shouye_url(self):
12 '''验证百度的首页URL地址'''
13 assert self.driver.current_url=='https://www.baidu.com/'3.4.2按测试模块执行
思维按测试模块来执行,就是以模块为单位来进行执行,那么其实在一个模块里面可以编写很多的类,下面通过详细的代码演示这部分,具体案例代码如下:
1 import unittest
2 from selenium import webdriver
3 from test.init import Init
4
5 class Baidu(Init):
6 def test_baidu_shouye_title(self):
7 '''验证百度首页的title信息'''
8 assert self.driver.title=='百度一下,你就知道'
9
10 def test_baidu_shouye_url(self):
11 '''验证百度的首页URL地址'''
12 assert self.driver.current_url=='https://www.baidu.com/'
13
14
15 class BaiDuSo(Init):
16 def test_baidu_so_value(self):
17 '''百度搜索关键字的验证'''
18 so=self.driver.find_element_by_id('kw')
19 so.send_keys('Selenium4')
20 assert so.get_attribute('value')=='Selenium4'3.4.3按具体的测试用例来执行
当然如果是仅仅执行某一个测试用例,执行的方式一种是鼠标放到具体的测试用例,然后右键执行就可以了,另外一种方式是我们可以把需要执行的测试用例添加到测试套件中,然后来单独的进行执行,这种方式其实我个人是不建议的,但是还是通过具体的代码来演示:
1 import unittest
2 from selenium import webdriver
3 from test.init import Init
4
5 class Baidu(Init):
6
7 def test_baidu_shouye_title(self):
8 '''验证百度首页的title信息'''
9 assert self.driver.title=='百度一下,你就知道'
10
11 def test_baidu_shouye_url(self):
12 '''验证百度的首页URL地址'''
13 assert self.driver.current_url=='https://www.baidu.com/'3.4.4自定义测试套件
针对测试套件的方式是很多的,那么我们就可以把加载所有测试用例的方法单独分离出来了,当然其实是可以的,这样我们只需要关注更多的测试用例的执行,下面具体演示测试套件的分离部分
1 import unittest
2 from selenium import webdriver
3 from test.init import Init
4
5
6 class Baidu(Init):
7
8 def test_baidu_shouye_title(self):
9 '''验证百度首页的title信息'''
10 assert self.driver.title=='百度一下,你就知道'
11
12 def test_baidu_shouye_url(self):
13 '''验证百度的首页URL地址'''
14 assert self.driver.current_url=='https://www.baidu.com/'
15
16 def suite(self):
17 '''自定义测试套件'''
18 return unittest.TestLoader().loadTestsFromModule('test_customer.py')3.4.5分离测试套件
在一个完整的自动化测试用例中,比如在UI的自动化测试用力中,我们的测试用例是按照业务模块来进行划分的,那么以为我们着想需要编写很多的模块,但是就存在重复的代码,比如我们针对百度的产品进行测试,不管是测试什么模块,测试固件这部分的代码每个测试模块都是一样的,这样就导致很多重复的代码,重复必然就带来测试效率低下的问题,举一个简单的问题,比如需要修改测试的地址,就需要修改很多的测试模块,但是如果把测试套件分离出来,我们就需要该一个地方就可以了,这样我们的测试效率就提升了一点,毕竟效率的提升是需要做很多的,不可能一点就进行大幅度的提升。分离测试套件的思想其实很简单,就是运用了继承的思想来解决这个问题,我们将分离的测试固件放到init.py里面
1 import unittest
2 from selenium import webdriver
3
4
5 class Init(unittest.TestCase):
6 def setUp(self) -> None:
7 self.driver=webdriver.Chrome()
8 self.driver.maximize_window()
9 self.driver.implicitly_wait(30)
10 self.driver.get('http://www.baidu.com')
11
12 def tearDown(self) -> None:
13 self.driver.quit()这样其他测试模块就需要引入这个模块中的init类就可以了,然后在继承这个类,具体代码如下:
1 import unittest
2 from selenium import webdriver
3 from test.init import Init
4
5 class Baidu(Init):
6
7 def test_baidu_shouye_title(self):
8 '''验证百度首页的title信息'''
9 assert self.driver.title=='百度一下,你就知道'
10
11 def test_baidu_shouye_url(self):
12 '''验证百度的首页URL地址'''
13 assert self.driver.current_url=='https://www.baidu.com/'其实过程中我们使用了很简单的思维,但是解决了一个很核心的问题
3.5 测试报告
下面详细的说明下测试报告的生成以及加载所有模块的过程,我们在tests的模块下编写了很多的测试用例,但是实际的生产环境中总不能按照测试模块来执行,我们都是加载所有的测试模块来执行并且最终生成基于HTML的测试报告,测试报告会用到第三方的库HTMLTestRunner
3.6加载所有的测试模块
下面我们编写具体的函数来加载所有的测试模块,路径处理部分我们使用os的模块来进行处理,针对路径处理的这部分特别的再说下,不能使用硬编码,使用硬编码只会带来维护的成本性,而且也涉及到不同的操作系统针对路径是有不同的,比如MAC和Linux下是没有C盘的,但是Windows操作系统,这部分需要特别的注意下,下面的函数主要体验的是加载所有测试模块的代码,具体如下:
1 import os
2 import HTMLTestRunner
3 import unittest
4
5
6 def base_dir():
7 return os.path.join(os.path.dirname(__file__),'test')
8
9
10 def getSuite():
11 tests=unittest.defaultTestLoader.discover(
12 start_dir=base_dir(),
13 pattern='test_*.py',
14 top_level_dir=None
15 )
16 return tests从如上的输出结果来看,已经到模块级别了,下面我们出一个需求,总共有多少测试用例,请统计出来,其实我们可以针对模块进行再次进行循环到类别,然后到测试用例的级别,然后把所有的测试用例加到一个列表里面,获取列表的长度就是测试用例的总数,下面是到类级别的代码和输出结果:
1 if __name__ == '__main__':
2 for item in getSuite():
3 for i in item:
4 print(i) 1 import os
2 import HTMLTestRunner
3 import unittest
4
5
6 def base_dir():
7 return os.path.join(os.path.dirname(__file__),'test')
8
9
10 def getSuite():
11 tests=unittest.defaultTestLoader.discover(
12 start_dir=base_dir(),
13 pattern='test_*.py',
14 top_level_dir=None
15 )
16 return tests
17
18
19
20 if __name__ == '__main__':
21 for item in getSuite():
22 for i in item:
23 for j in i:
24 print(j)3.7生成HTML测试报告
下面具体展示测试报告的生成,把测试报告储存到report的文件夹里面,思考每次生成的测试报名名称一致,我们可以以当前时间作为区分,那么整体实现的代码如下:
1 import os
2 import HTMLTestRunner
3 import unittest
4 import time
5
6
7 def base_dir():
8 return os.path.join(os.path.dirname(__file__),'test')
9
10
11 def getSuite():
12 tests=unittest.defaultTestLoader.discover(
13 start_dir=base_dir(),
14 pattern='test_*.py',
15 top_level_dir=None
16 )
17 return tests
18
19
20
21 def getNowTime():
22 return time.strftime('%y-%m-%d %h_%m_%s',time.localtime(time.time()))
23
24 def run():
25 filename=os.path.join(os.path.dirname(__file__),'report',getNowTime()+'report.html')
26 fp=open(filename,'wb')
27 runner=HTMLTestRunner.HTMLTestRunner(
28 stream=fp,
29 title='',
30 description=''
31 )
32 runner.run(getSuite())在report的文件夹下,生成的测试报告打开后显示如下:

结语
这篇贴子到这里就结束了,最后,希望看这篇帖子的朋友能够有所收获。欢迎留言,或是关注我的专栏和我交流。
有兴趣就点击下方小卡片去和大神交流交流吧!!