1 概述
1.1 redis介绍
Redis 是互联网技术领域使用最为广泛的存储中间件,它是「Remote Dictionary Service」的首字母缩写,也就是「远程字典服务」。Redis 以其超高的性能、完美的文档、 简洁易懂的源码和丰富的客户端库支持在开源中间件领域广受好评。国内外很多大型互联网 公司都在使用 Redis,比如 Twitter、YouPorn、暴雪娱乐、Github、StackOverflow、腾讯、 阿里、京东、华为、新浪微博等等,很多中小型公司也都有应用。
Redis 是一个开源的 key-value 存储系统。和 Memcached 类似,它支持存储的 value 类型相对更多,包括 string (字符串)、list (链表)、set (集合)、zset (sorted set –有序集合) 和 hash(哈希类型)。这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
在此基础上,Redis 支持各种不同方式的排序。与 memcached 一样,为了保证效率,数据都是缓存在内存中。区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。并且在此基础上实现了 master-slave (主从) 同步。
1.2 redis应用场景
为什么使用?
- 解决应用服务器的CPU和内存压力
- 减少IO的读操作,减轻IO的压力
- 关系型数据库的扩展性不强,难以改变表结构
1.2.1 应用:缓存
Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,使用Redis用在缓存的场合非常多。合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。
1.2.2 应用:计数器
诸如统计点击数等应用。由于单线程,可以避免并发问题,保证不会出错,而且100%毫秒级性能;
命令:INCRBY
1.2.3 应用:队列
redis设计用来做缓存的,但是由于它自身的某种特性使得它可以用来做消息队列,它有几个阻塞式的API可以使用,正是这些阻塞式的API让其有能力做消息队列;另外,做消息队列的其他特性例如FIFO(先入先出)也很容易实现,只需要一个list对象从头取数据,从尾部塞数据即可;redis能做消息队列还得益于其list对象blpop brpop接口以及Pub/Sub(发布/订阅)的某些接口,它们都是阻塞版的,所以可以用来做消息队列。
如果对于数据一致性要求高的话还是用RocketMQ等专业系统。
1.2.4 应用:分布式锁与单线程机制
Redis单线程的特性,用来做高性能的分布式锁,秒杀场景等
1.2.5 应用:自动过期能力
Redis针对数据都可以设置过期时间,这个特点也是大家应用比较多的,过期的数据清理无需使用方去关注,所以开发效率也比较高,当然,性能也比较高。最常见的就是:短信验证码、具有时间性的商品展示等。无需像数据库还要去查时间进行对比。
1.2.6 应用:位操作(大数据处理)
用于数据量上亿的场景下,例如几亿用户系统的签到,去重登录次数统计,某用户是否在线状态等等。
想想一下腾讯10亿用户,要几个毫秒内查询到某个用户是否在线,你能怎么做?这里要用到位操作——使用setbit、getbit、bitcount命令。
redis内构建一个足够长的数组,每个数组元素只能是0和1两个值,然后这个数组的下标index用来表示我们上面例子里面的用户id(必须是数字哈),那么很显然,这个几亿长的大数组就能通过下标和元素值(0和1)来构建一个记忆系统,上面我说的几个场景也就能够实现
1.2.7 应用:排行榜
谁得分高谁排名往上。命令:ZADD(有续集,sorted set)
1.2.8 应用:用数据库来算附近的人
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现 摩拜单车「附近的 Mobike」、美团和饿了么「附近的餐馆」这样的功能了。
业界比较通用的地理位置距离排序算法是 GeoHash 算法,Redis 也使用 GeoHash 算 法。
2 redis安装
1、https://redis.io/download/ 下载对应版本的redis,解压缩tar -zxvf redis-6.2.7.tar.gz
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4gSrA1bu-1681570135804)(assets/image-20221208160304260.png)]
2、检查环境
检查gcc环境 gcc -v,如果命令无效,安装gcc环境:sudo apt install gcc
检查make环境,如果无效:sudo apt install make
lizheng@lz-x:~/redis-6.2.7$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:hsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-10ubuntu2' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 9.3.0 (Ubuntu 9.3.0-10ubuntu2)
3、make & make install
cd /redis-6.2.7
make
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JQeVbvPq-1681570135805)(assets/image-20221208161310148.png)]
make install

4、启动:redis-server

3 数据类型
3.1 字符串(String)
String 是 Redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
String 类型是二进制安全的。意味着 Redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。
String 类型是 Redis 最基本的数据类型,一个 Redis 中字符串 value 最多可以是 512M

Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图中所示,内部为当前字 符串实际分配的空间 capacity 一般要高于实际字符串长度 len。
当字符串长度小于 1M 时, 扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是 字符串最大长度为 512M。
# 键值对
127.0.0.1:6379> set name zhangsan
OK
127.0.0.1:6379> get name
"zhangsan"
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
# 批量操作
127.0.0.1:6379> mset id 1 name zhangsan age 12
OK
127.0.0.1:6379> mget id name age
1) "1"
2) "zhangsan"
3) "12"
# 过期和 set 命令扩展
127.0.0.1:6379> expire name 5 #过期5秒
(integer) 1
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> setex name 5 lisi #过期5秒
OK
127.0.0.1:6379> get name
"lisi"
127.0.0.1:6379> get name
(nil)
# 计数
127.0.0.1:6379> set age 10
OK
127.0.0.1:6379> incr age
(integer) 11
127.0.0.1:6379> incrby age 2
(integer) 13
127.0.0.1:6379> get age
"13"
127.0.0.1:6379>
3.2 列表(List)
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)
实际上 Redis 底层存储的还不是一个简单的 linkedlist,而是称之为 快速链表 quicklist 的一个结构。

首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是 压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的 时候才会改成 quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且 会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的 指针 prev 和 next 。将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
右边进左边出:队列
127.0.0.1:6379> rpush books java golang python js
(integer) 4
127.0.0.1:6379> llen books
(integer) 4
127.0.0.1:6379> lpop books
"java"
127.0.0.1:6379> lpop books
"golang"
127.0.0.1:6379> lpop books
"python"
127.0.0.1:6379> lpop books
"js"
127.0.0.1:6379> lpop books
(nil)
127.0.0.1:6379> llen books
(integer) 0
127.0.0.1:6379>
右边进右边出:栈
127.0.0.1:6379> rpush books java golang python js
(integer) 4
127.0.0.1:6379> rpop books
"js"
127.0.0.1:6379> rpop books
"python"
127.0.0.1:6379> rpop books 3
1) "golang"
2) "java"
127.0.0.1:6379> llen books
(integer) 0
127.0.0.1:6379>
Lindex 慢操作
Lindex 命令用于通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
127.0.0.1:6379> rpush books java golang python js
(integer) 4
127.0.0.1:6379> lindex books -1
"js"
127.0.0.1:6379> lindex books -2
"python"
127.0.0.1:6379> lindex books 2
"python"
127.0.0.1:6379> lindex books 0
"java"
127.0.0.1:6379> lindex books 100
(nil)
127.0.0.1:6379>
3.3 哈希字典(hash)
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。

127.0.0.1:6379> hset hkey name "zhangsan" age 12 doub 11.22
(integer) 3
127.0.0.1:6379> hmget hkey
(error) ERR wrong number of arguments for 'hmget' command
127.0.0.1:6379> hmget hkey name age doub
1) "zhangsan"
2) "12"
3) "11.22"
127.0.0.1:6379> hgetall hkey
1) "name"
2) "zhangsan"
3) "age"
4) "12"
5) "doub"
6) "11.22"
同字符串一样,hash 结构中的单个子 key 也可以进行计数,它对应的指令是 hincrby, 和 incr 使用基本一样。
3.4 集合(set)
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的 内部实现相当于一个特殊的hash字典,字典中所有的 value 都是一个值 NULL。
当需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。
127.0.0.1:6379> sadd setkey java
(integer) 1
127.0.0.1:6379> sadd setkey java
(integer) 0
127.0.0.1:6379> sadd setkey redis
(integer) 1
127.0.0.1:6379> sadd setkey python go
(integer) 2
127.0.0.1:6379> smembers setkey
1) "redis"
2) "java"
3) "go"
4) "python"
127.0.0.1:6379> sismember setkey java
(integer) 1
127.0.0.1:6379> sismember setkey java1
(integer) 0
3.5 有序集合(zset)
类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫着跳跃列表的数据结构。
zset 可以用来存 粉丝列表,value 值是粉丝的用户 ID,score 是关注时间。我们可以对粉丝列表按关注时间 进行排序。 zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们 可以对成绩按分数进行排序就可以得到他的名次
127.0.0.1:6379> zadd books 9.0 java
(integer) 1
127.0.0.1:6379> zadd books 7.0 go
(integer) 1
127.0.0.1:6379> zadd books 8.8 js
127.0.0.1:6379> zrange books 1 -1 #排序输出
1) "go"
2) "js"
3) "java"
4) "mysql"
127.0.0.1:6379> zrevrange books 0 -1 #逆排序输出
1) "mysql"
2) "java"
3) "js"
4) "go"
127.0.0.1:6379> zrangebyscore books 8 9 #根据分值筛选
1) "js"
2) "java"
跳跃列表
zset 内部的排序功能是通过「跳跃列表」数据结构来实现的,它的结构非常特殊,也比较复杂。 因为 zset 要支持随机的插入和删除,所以它不好使用数组来表示。我们先看一个普通的 链表结构

我们需要这个链表按照 score 值进行排序。这意味着当有新元素需要插入时,要定位到特定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表地址不连续效率低,于是引入了跳跃列表
跳跃列表是一种数据结构。它允许快速查询一个有序连续元素的数据链表,而其快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集。

我们把一些节点从有序表中提取出来,缓存一级索引,就组成了下面这样的结构:

同样地,一级索引也可以往上再提取一层,组成二级索引,如下:

如果我们再查找17这个元素呢?只需要经过6、15、17这几个元素就可以找到17了。
这基本上就是跳表的核心思想了,其实这也是一个“空间换时间”的算法,通过向上提取索引增加了查找的效率。
跳跃列表采取一个随机策略来决定新元素可以兼职到第几层。 首先 0 层肯定是 100% 了,1 层只有 50% 的概率,2 层只有 25% 的概率,3 层只有 12.5% 的概率,以此类推,绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
3.6 位图(Bitmaps)
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。由于bit是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。位图(bitmap)同样属于 string 数据类型。Redis 中一个字符串类型的值最多能存储 512 MB 的内容,每个字符串由多个字节组成,每个字节又由 8 个 Bit 位组成。位图结构正是使用“位”来实现存储的,它通过将比特位设置为 0 或 1来达到数据存取的目的,这大大增加了 value 存储数量,它存储上限为2^32 。
比如记录用户一年内签到的次数,签了是 1,没签是 0。如果使用 key-value 来存储,那么每个用户都要记录 365 次,当用户成百上亿时,需要的存储空间将非常巨大。Redis 提供位图结构,可以很好的解决。
位图本质上就是一个普通的字节串,也就是 bytes 数组。您可以使用getbit/setbit命令来处理这个位数组,位图的结构如下所示:

127.0.0.1:6379> setbit bitkey 0 1
(integer) 0
127.0.0.1:6379> setbit bitkey 1 0
(integer) 0
127.0.0.1:6379> setbit bitkey 2 1
(integer) 0
127.0.0.1:6379> setbit bitkey 3 1
(integer) 0
127.0.0.1:6379> setbit bitkey 4 1
(integer) 0
127.0.0.1:6379> setbit bitkey 5 0
(integer) 0
127.0.0.1:6379> getbit bitkey 4
(integer) 1
127.0.0.1:6379> get bitkey
"\xb8"
127.0.0.1:6379> bitcount bitkey
(integer) 4
3.7 基数统计(HyperLogLog)
基数统计(Cardinality Counting) 通常是用来统计一个集合中不重复的元素个数。
思考这样的一个场景: 如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站上每个网页的 UV(独立访客,每个用户每天只记录一次),然后让你来开发这个统计模块,你会如何实现?
解决基数问题有很多种方案:
-
数据存储在 MySQL 表中,使用 distinct count 计算不重复个数。
-
使用 Redis 提供的 hash、set、bitmaps 等数据结构来处理。
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。能否能够降低一定的精度来平衡存储空间?Redis 推出了 HyperLogLog
-
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
-
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
-
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {
1,3,5,7, 5, 7,8},那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数 (不重复元素) 为5。 基数估计就是在误差可接受的范围内,快速计算基数。HyperLogLog 是大数据基数统计中的常见方法,无论是 Redis,Spark 还是 Flink 都提供了这个功能,其目的就是在一定的
误差范围内,用最小的空间复杂度来估算一个数据流的基数。HyperLogLog 算法简要思路是通过一个 hash 函数把数据流
Ⅾ映射到{0,1}∞,也就是说用二进制来表示数据流中的元素。每一个数据流中的元素x都对应这一个0,1序列在介绍HyperLogLog之前考虑一个场景:在一个抛硬币的场景下,假设硬币的正面对应着
1硬币的反面对应着0,依次置出0,0,0,1的概率是多少?通过计算可以得到1/2^4 = 1/16,那就相当于平均置16次,才会获得0,0,0,1这个序列,反之如果出现0,0,0,1这个序列说明起码置了16次硬币。对于大批量随机0,1序列,可以根据
第一出现1的位置,来估算这批0,1序列的个数,例如:
- 出现序列
1 X X X X意味着不可重复元素估计 2^1 = 2 个- 出现序列
0 1 X X X意味着不可重复元素估计 2^2 = 4 个- 出现序列
0 0 1 X X意味着不可重复元素估计 2^3 = 8 个- 出现序列
0 0 0 1 X意味着不可重复元素估计 2^4 = 16 个
127.0.0.1:6379> pfadd hllkey redis java
(integer) 1
127.0.0.1:6379> pfadd hllkey redis
(integer) 0
127.0.0.1:6379> pfadd hllkey redis
(integer) 0
127.0.0.1:6379> pfadd hllkey go
(integer) 1
127.0.0.1:6379> pfadd hllkey go
(integer) 0
127.0.0.1:6379> pfadd hllkey js
(integer) 1
127.0.0.1:6379> pfcount hllkey
(integer) 4
3.8 位置(Geospatial)
Redis 3.2 中增加了对 GEO 类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的 2 维坐标,在地图上就是经纬度。redis 基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度 Hash 等常见操作。
127.0.0.1:6379> geoadd geokey 13.361389 38.115556 Palermo 15.087269 37.502669 Catania
(integer) 2
127.0.0.1:6379> geodist geokey Palermo Catania
"166274.1516"
127.0.0.1:6379> georadius geokey 15 37 100m
(error) ERR wrong number of arguments for 'georadius' command
127.0.0.1:6379> georadius geokey 15 37 100 m
(empty array)
127.0.0.1:6379> georadius geokey 15 37 100 km
1) "Catania"
127.0.0.1:6379> georadius geokey 15 37 200 km
1) "Palermo"
2) "Catania"
3.9 容器型数据结构的通用规则
list/set/hash/zset 这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
1、create if not exists 如果容器不存在,那就创建一个,再进行操作。比如 rpush 操作刚开始是没有列表的, Redis 就会自动创建一个,然后再 rpush 进去新元素。
2、drop if no elements 如果容器里元素没有了,那么立即删除元素,释放内存。这意味着 lpop 操作到最后一 个元素,列表就消失了。
4 redis 的发布订阅
4.1 什么是发布订阅
Redis 发布/订阅是一种消息传递模式,其中发送者(在Redis术语中称为发布者)发送消息,而接收者(订阅者)接收消息。传递消息的通道称为channel。
在Redis中,客户端可以订阅任意数量的频道,下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

4.2 测试
订阅一个channel
127.0.0.1:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1
向channel1发布消息
127.0.0.1:6379> publish channel1 hello
(integer) 1
4.3 发布订阅缺点
PubSub 的生产者传递过来一个消息,Redis 会直接找到相应的消费者传递过去。如果一个消费者都没有,那么消息直接丢弃。如果开始有三个消费者,一个消费者突然挂掉了,生产者会继续发送消息,另外两个消费者可以持续收到消息。但是挂掉的消费者重新连上的时候,这断连期间生产者发送的消息,对于这个消费者来说就是彻底丢失了。
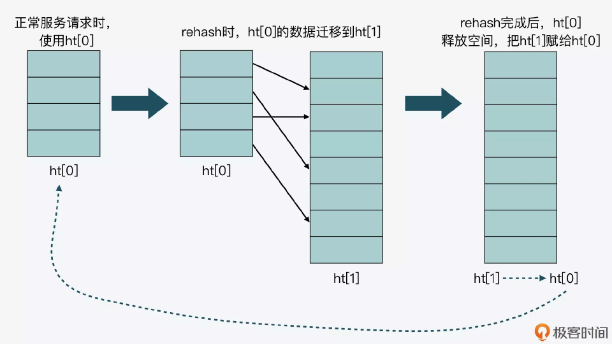
正是因为 PubSub 有这些缺点,它几乎找不到合适的应用场景,Redis5.0 新增了 Stream 数据结构,这个功能给 Redis 带来了持久化消息队列。
5 Redis Stream
5.1 Stream概述
Redis Stream 是 Redis 5.0 版本新增加的数据结构。主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。且无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:

上图解析:
Consumer Group:消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。last_delivered_id:游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。pending_ids:消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
5.2 Stream 消息太多怎么办
要是消息积累太多,Stream 的链表岂不是很长,内容会不会爆掉? xdel 指令又不会删除消息,它只是给消息做了个标志位。 Redis 自然考虑到了这一点,所以它提供了一个定长 Stream 功能。在 xadd 的指令提供 一个定长长度 maxlen,就可以将老的消息干掉,确保最多不超过指定长度。
5.3 Stream 的高可用
Stream 的高可用是建立主从复制基础上的,它和其它数据结构的复制机制没有区别,也就是说在 Sentinel 和 Cluster 集群环境下 Stream 是可以支持高可用的。不过鉴于 Redis 的指令复制是异步的,在 failover 发生时,Redis 可能会丢失极小部分数据,这点 Redis 的其 它数据结构也是一样的。
6 事务(Transcation)
6.1 redis事务概述
Redis 事务不是严格意义上的事务,只是用于帮助用户在一个步骤中执行多个命令。单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
Redis 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。也可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
Redis 事务的主要作用就是串联多个命令防止别的命令插队
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
6.2 事务的使用
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
MULTI、EXEC、DISCARD、WATCH 这四个指令构成了 redis 事务处理的基础。
- MULTI 用来组装一个事务;
- EXEC 用来执行一个事务;
- DISCARD 用来取消一个事务;
- WATCH 本身的作用是监视 key 是否被改动过,而且支持同时监视多个 key,只要还没真正触发事务,WATCH 都会尽职尽责的监视,一旦发现某个 key 被修改了,在执行 EXEC 时就会返回 nil,表示事务无法触发。

127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set name sz
QUEUED
127.0.0.1:6379(TX)> set age 10
QUEUED
127.0.0.1:6379(TX)> set address = 1
QUEUED
127.0.0.1:6379(TX)> set sex 0
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) OK
3) (error) ERR syntax error # 不影响下面执行
4) OK
127.0.0.1:6379> get sex
"0"
watch
127.0.0.1:6379> watch good_num
OK
127.0.0.1:6379> set good_num 0
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set good_num 0
QUEUED
127.0.0.1:6379(TX)> exec #不会被执行
(nil)
7 Lua脚本
7.1 简介
Redis的单个命令都是原子性的,有时候我们希望能够组合多个Redis命令,并让这个组合也能够原子性的执行,甚至可以重复使用,在软件热更新中也有一席之地。Redis开发者意识到这种场景还是很普遍的,就在2.6版本中引入了一个特性来解决这个问题,这就是Redis执行Lua脚本。允许开发者使用Lua语言编写脚本传到Redis中执行。
Lua广泛作为其它语言的嵌入脚本,尤其是C/C++,语法简单,小巧,源码一共才200多K,这可能也是Redis官方选择它的原因。
使用脚本的好处如下:
- 减少网络开销。可以将多个请求通过脚本的形式一次发送,减少网络时延。
- 原子操作。Redis会将整个脚本作为一个整体执行,中间不会被其他请求插入。因此在脚本运行过程中无需担心会出现竞态条件,无需使用事务。
- 复用。客户端发送的脚本会永久存在redis中,这样其他客户端可以复用这一脚本,而不需要使用代码完成相同的逻辑。
7.2 Redis中Lua的常用命令
7.2.1 EVAL命令
Redis中使用EVAL命令来直接执行指定的Lua脚本。
EVAL luascript numkeys key [key ...] arg [arg ...]
EVAL命令的关键字。luascriptLua 脚本。numkeys指定的Lua脚本需要处理键的数量,其实就是key数组的长度,必传。key传递给Lua脚本零到多个键,空格隔开,在Lua 脚本中通过KEYS[INDEX]来获取对应的值,其中1 <= INDEX <= numkeys。arg是传递给脚本的零到多个附加参数,空格隔开,在Lua脚本中通过ARGV[INDEX]来获取对应的值,其中1 <= INDEX <= numkeys。
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> EVAL "return redis.call('GET',KEYS[1])" 1 hello
"world"
127.0.0.1:6379> EVAL "return redis.call('GET','hello')"
(error) ERR wrong number of arguments for 'eval' command
127.0.0.1:6379> EVAL "return redis.call('GET','hello')" 0
"world"
7.2.2 call函数和pcall函数
在上面的例子中我们通过redis.call()来执行了一个GET命令,其实我们也可以替换为redis.pcall()。它们唯一的区别就在于处理错误的方式,前者执行命令错误时会向调用者直接返回一个错误;而后者则会将错误包装为一个Lua table表格:
7.3 Lua和Redis数据类型转换
当Lua脚本使用call()或pcall()调用Redis命令时,Redis返回值将转换为Lua数据类型。同样,在调用Redis命令和Lua脚本返回值时,Lua数据类型将转换为Redis协议类型,以便脚本可以控制EVAL返回给客户端的内容。
数据类型之间的转换原则是,如果将Redis类型转换为Lua类型,然后将结果转换回Redis类型,则结果与初始值相同。
换句话说,Lua和Redis类型之间存在一对一的转换。下表显示了所有转换规则:
Redis to Lua 转换对应表
Redis integer reply -> Lua number
Redis bulk reply -> Lua string
Redis multi bulk reply -> Lua table (may have other Redis data types nested)
Redis status reply -> Lua table with a single ok field containing the status
Redis error reply -> Lua table with a single err field containing the error
Redis Nil bulk reply and Nil multi bulk reply -> Lua false boolean type
Lua to Redis 转换对应表
Lua number -> Redis integer reply (the number is converted into an integer)
Lua string -> Redis bulk reply
Lua table (array) -> Redis multi bulk reply (truncated to the first nil inside the Lua array if any)
Lua table with a single ok field -> Redis status reply
Lua table with a single err field -> Redis error reply
Lua boolean false -> Redis Nil bulk reply.
Lua boolean true -> Redis integer reply with value of 1
127.0.0.1:6379> eval "return 3.14" 0
(integer) 3 # 丢失精度
127.0.0.1:6379> eval "return tostring(3.14)" 0
"3.14"
7.4 脚本原子性
Redis使用相同的Lua解释器来运行所有命令。另外,Redis保证以原子方式执行脚本:执行脚本时不会执行其他脚本或Redis命令。与 MULTI/EXEC 事务的概念相似。从所有其他客户端的角度来看,脚本要不已经执行完成,要不根本不执行。
然而运行一个缓慢的脚本就是一个很愚蠢的主意。创建快速执行的脚本并不难,因为脚本开销非常低。但是,如果您要使用了执行缓慢的脚本,由于其的原子性,其他客户端的命令都是得不到执行的,这并不是我们想要的结果,大家要切记。
7.5 脚本管理
7.5.1 SCRIPT LOAD
加载脚本到缓存以达到重复使用,避免多次加载浪费带宽,每一个脚本都会通过SHA校验返回唯一字符串标识。需要配合EVALSHA命令来执行缓存后的脚本。
127.0.0.1:6379> SCRIPT LOAD "return 'hello'"
"1b936e3fe509bcbc9cd0664897bbe8fd0cac101b"
127.0.0.1:6379> EVALSHA 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b 0
"hello"
7.5.2 SCRIPT FLUSH
既然有缓存就有清除缓存,但是遗憾的是并没有根据SHA来删除脚本缓存,而是清除所有的脚本缓存,所以在生产中一般不会再生产过程中使用该命令。
127.0.0.1:6379> script flush
OK
127.0.0.1:6379> script exists 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b
1) (integer) 0
7.5.3 SCRIPT EXISTS
以SHA标识为参数检查一个或者多个缓存是否存在。
127.0.0.1:6379> script exists 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b
1) (integer) 0
7.5.4 SCRIPT KILL
终止正在执行的脚本。但是为了数据的完整性此命令并不能保证一定能终止成功。如果当一个脚本执行了一部分写的逻辑而需要被终止时,该命令是不凑效的。需要执行SHUTDOWN nosave在不对数据执行持久化的情况下终止服务器来完成终止脚本。
127.0.0.1:6379> SCRIPT LOAD “return ‘hello’”
“1b936e3fe509bcbc9cd0664897bbe8fd0cac101b”
127.0.0.1:6379> EVALSHA 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b 0
“hello”
### 7.5.2 SCRIPT FLUSH
既然有缓存就有`清除缓存`,但是遗憾的是并没有根据SHA来删除脚本缓存,而是`清除所有`的脚本缓存,所以在生产中一般不会再生产过程中使用该命令。
```bash
127.0.0.1:6379> script flush
OK
127.0.0.1:6379> script exists 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b
1) (integer) 0
7.5.3 SCRIPT EXISTS
以SHA标识为参数检查一个或者多个缓存是否存在。
127.0.0.1:6379> script exists 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b
1) (integer) 0
7.5.4 SCRIPT KILL
终止正在执行的脚本。但是为了数据的完整性此命令并不能保证一定能终止成功。如果当一个脚本执行了一部分写的逻辑而需要被终止时,该命令是不凑效的。需要执行SHUTDOWN nosave在不对数据执行持久化的情况下终止服务器来完成终止脚本。