目录
一、网络请求流程
1.HTTP
2.URL
3.网络传输模型
4.长链接/短链接
二、爬虫基础
1.基础概念
2.发送请求
3.请求模式
5.retrying
一、网络请求流程
1.HTTP
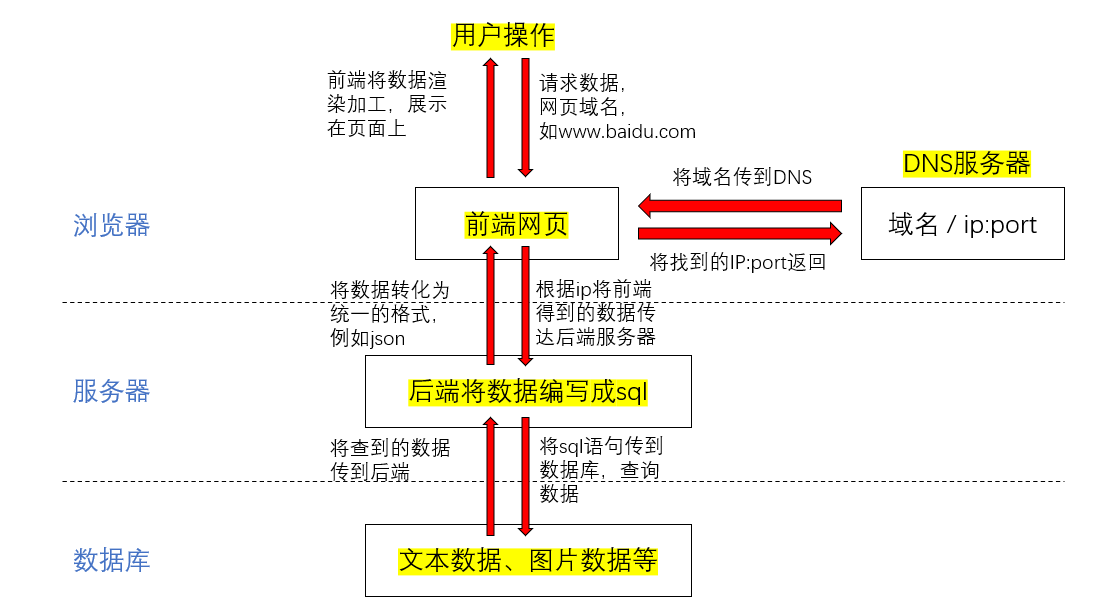
- 用户输入网址,例如 www.baidu.com
- 浏览器先向DNS请求,找到网址域名对应的ip地址和端口号并传到前端
- 浏览器请求访问这个ip地址对应的服务器,然后将域名里带有的参数一起传入后端
- 后端将接收到的参数拼写成sql语句,通过sql语言向数据库查询数据
- 数据库将结果返回给后端
- 后端将得到的数据整理成统一的格式返回给前端
- 前端拿到数据之后,通过前端代码进行渲染加工,展示在页面上提供给用户
2.URL
URL示例:
https://www.bilibili.com/video/BV1dK4y1A7aM/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=18bd1edf91a238e3df510f2409d7b427
URL的四部分:
- 协议:https://
- 域名:www.baidu.com/
- 资源路径:video/BV1dK4y1A7aM/?
- 参数:spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=18bd1edf91a238e3df510f2409d7b427
通常情况资源路径与参数部分用 '?' 进行分隔,不容参数之间用 ‘&’ 进行分隔
在输入网址的时候协议和域名部分是必须要有的,协议不输入浏览器会默认使用https://
域名包括了ip地址和端口号port
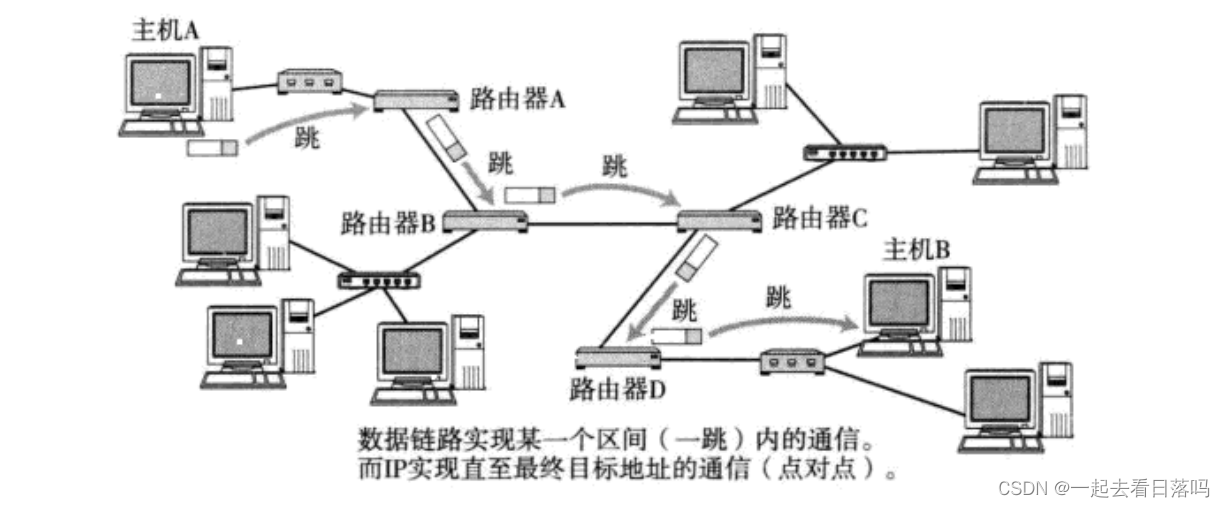
3.网络传输模型
HTTP协议(HyperText Transfer Prorocol)超文本传输协议,是浏览器和web服务器传输数据格式的协议,基于TCP协议,是一个应用层协议


在保证应用层、传输层、网络层、链路层一致后:
- 数据先从客户端从应用层一级一级向链路层传递
- 通过以太网络和IP,将数据进行传输
- 通过令牌环(加密算法),验证数据,保证数据真实可靠
- 再由链路层将数据传递到应用层,表示数据可进行下一步操作
4.长链接/短链接
HTTP/1.0中,服务器默认使用短链接。浏览器和服务器没进行一次HTTP操作,就建立一次链接,但任务结束就中断链接。
HTTP/1.1起,浏览器默认使用长链接。客户端的浏览器访问某个HTML或其他类型的web页中包含有其他的web资源,如js文件、图像文件、CSS文件等,当浏览器每遇到一个这样的资源,就会建立一个HTTP会话。
Connection:keep-alive
keep-alive是客户端和服务端的一个约定,即长链接,表示服务端在返回response后不关闭TCP连接,接收完响应之后的客户端也不关闭TCP连接,发送下一个HTTP请求时会重用该连接
- 短链接对于服务器来说实现比较简单,存在的链接都是有效的连接,不需要额外的控制手段
- 短链接建立成功后,一次请求和响应完成以后连接就会断开,每次发送请求需要重新建立连接。往往可能很短的时间内创立大量连接,造成服务器响应速度过慢
- 短链接不会占用服务端过多的资源,但是增加了用户的等待时间,减慢了访问速度
- 长链接可以省去较多的TCP建立和关闭操作,提高效率
- 长链接建立成功后,可以发送多次请求和响应,等双方不进行通信的时候,服务端做好断开链接的操作
- 长链接增加了服务端的资源开销,可能造成服务端负载过高,最终导致服务不可用
二、爬虫基础
1.基础概念

什么是爬虫?爬虫即为模拟用户网络请求,向目标网站获取数据。理论上只要是浏览器上展示的数据,爬虫皆能获取。
爬虫流程:
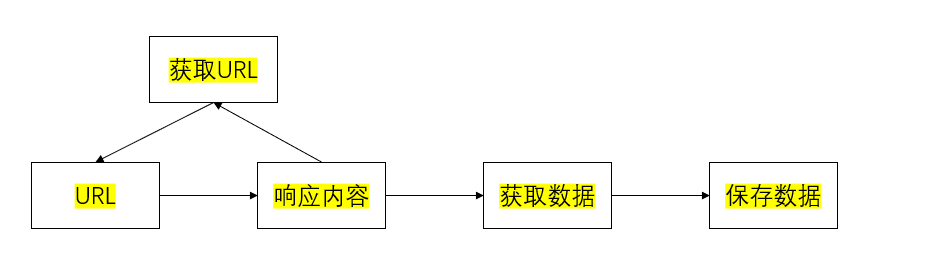
- 向url发送请求,获取响应
- 对响应进行提取
- 如果有需要提取url,则继续发送请求获取响应
- 提取数据,将数据保存
HTTP和HTTPS:
- HTTP:超文本传输协议,默认端口号80
- HTTPS:HTTP + SSL(安全套接字),带有安全套接字的超文本传输协议,默认端口号443
HTTP常见请求头:
- Host:主机和端口号
- Connection:链接类型
- Upgrade-Insecure-Requests:升级HTTPS请求
- User-Agent:浏览器名称
- Accept:传输文件类型
- Referer:页面跳转处
- Accept-Encoding:文件编码/解码格式
- Cookie:参数
User-Agent和Cookie是最重要的参数,这两个参数表明了请求的由来,是最好的伪装成人为请求的参数。
响应状态码(status code):
- 200:成功
- 302:临时转移至新的url
- 307:临时转移至新的url
- 404:找不到该页面
- 403:资源不可用
- 500:服务器内部错误
- 503:服务器不可用,通常是被反爬
2.发送请求
requests请求:老版本的Python都是使用urllib发送请求,requests是对urllib的进一步封装
文本请求
import requests
url = "https://www.baidu.com"
# 向目标url发送get请求
response = requests.get(url)
# 响应内容
print(response.text) # str类型
print(response.content) # bytes类型
print(response.status_code) # 状态码
print(response.request.headers) # 请求头
print(response.headers) # 响应头
print(response.cookies) # 响应的cookie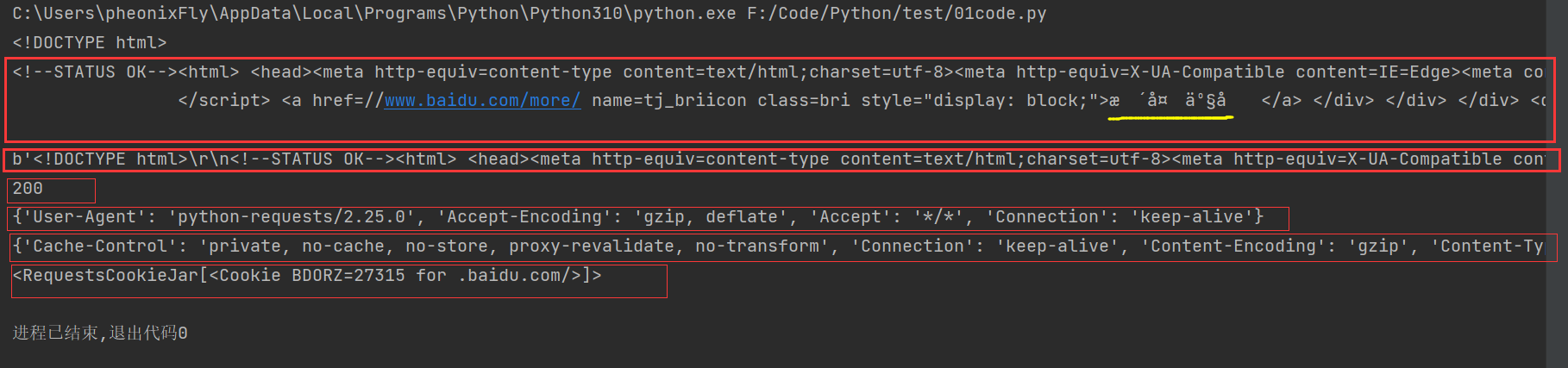
import requests
url = "https://www.baidu.com"
# 向目标url发送get请求
response = requests.get(url)
# 响应内容
print(response.text) # str类型,中文字符为乱码
print(response.content) # bytes类型
print(response.content.decode()) # 正常显示中文字符
print(response.content.decode('utf-8')) # 正常显示中文字符
print(response.content.decode('gbk')) # 报错
图片请求
import requests
url = "https://hips.hearstapps.com/hmg-prod.s3.amazonaws.com/images/d-1592982809.jpg"
response = requests.get(url)
# 打印图片的字节型内容
print(response.content)
with open("image.jpg", "wb") as f:
# 写入response.content bytes二进制类型
f.write(response.content)
请求头与参数
请求头与参数会默认设置,但是如果我们要自定义请求头headers和params,我们要以字典的结构创建请求头和参数变量,并传入get或post请求函数
3.请求模式
get请求:直接向网页发起的请求,可以不带任何参数
post请求:当我们确定了需要什么数据时,再发起请求时需要带上参数
代理
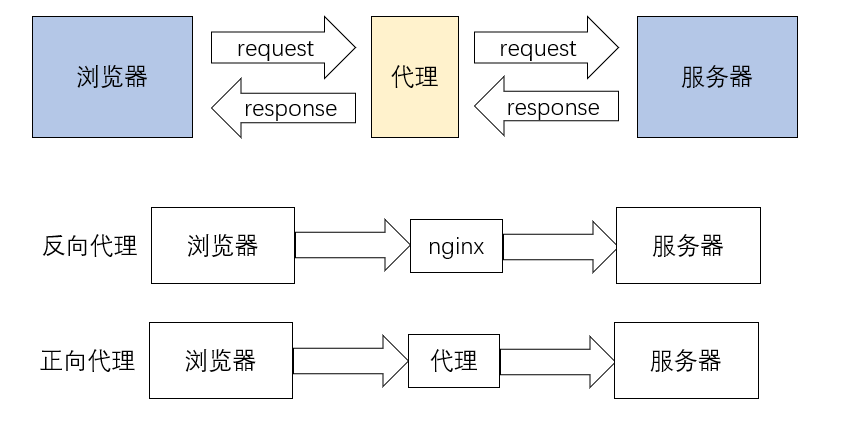
反向代理:浏览器不知道服务器的真实地址,如nginx
正向代理:浏览器知道服务器的真实地址,如VPN
代理的使用本质上都是隐藏自己的ip地址。登录信息的不足,特定ip的被禁止,同一ip短时间内多次访问,这些都会被服务器定义为恶意ip并禁止访问。所以我们使用代理来替换真实的ip及访问信息。
import requests
import random as rd
import time
for i in range(1, 100):
# 生成随机代理
proxie_str = f"https://{rd.randint(1, 100)}.{rd.randint(1, 100)}.{rd.randint(1, 100)}." \
f"{rd.randint(1, 100)}:{rd.randint(3000, 9000)}"
print(proxie_str)
# 设置代理
proxie = {
"https": proxie_str
}
url = "http://www.baidu.com"
response = requests.get(url, proxies=proxie)
print(response.content.decode())
time.sleep(0.5)4.cookie
cookie是爬虫访问网站时的个人信息,也是请求头中的重要组成部分。
cookie中的信息包括但不限于设备信息、历史记录、访问密钥。
使用requests处理cookie的三种方法:
1. 将cookie字符串以键值对格式放入headers请求头字典中
header = {
'Cookie': 'OUTFOX_SEARCH_USER_ID_NCOO=2067300732.9291213;\
OUTFOX_SEARCH_USER_ID="93319303@10.169.0.81"; _ga=GA1.2.831611348.1638177688;\
P_INFO=joldemox@163.com|1647320299|0|youdao_jianwai|00&99|shh&1647226292&mailmas\
ter_ios#shh&null#10#0#0|&0|mailmaster_ios|joldemox@163.com; fanyi-ad-id=305838;\
fanyi-ad-closed=1; ___rl__test__cookies=1653295115820'
}2. 把cookie字典传给请求方法的cookie参数接收
cookies = {"cookie的key":"cookie的value"}
requests.get(url,headers=header,cookies=cookie)3. 使用requests提供的session模板
header = {
'Cookie': 'OUTFOX_SEARCH_USER_ID_NCOO=2067300732.9291213;\
OUTFOX_SEARCH_USER_ID="93319303@10.169.0.81"; _ga=GA1.2.831611348.1638177688;\
P_INFO=joldemox@163.com|1647320299|0|youdao_jianwai|00&99|shh&1647226292&mailmas\
ter_ios#shh&null#10#0#0|&0|mailmaster_ios|joldemox@163.com; fanyi-ad-id=305838;\
fanyi-ad-closed=1; ___rl__test__cookies=1653295115820'
}
session = requests.session()
response = session.get(url, headers, verify=False)
# 这个写法针对长链接和第三方跳转,保证cookie可以在请求中不被清空5.retrying
重复发送请求模块
import requests
from retrying import retry
@retry(stop_max_attempt_number=4)
def get_info(url):
# 超时会报错并重试
# 等待超时时间设为4秒
response = requests.get(url, timeout=4)
# 状态码不是200也会报错重试
assert response.status_code == 200
return response
def parse_info(url):
try:
response = get_info(url)
except:
print(Exception)
response = None
return response
if __name__ == "__main__":
res = parse_info("https://www.baidu.com")
print(res.content.decode())
这里的retry是以装饰器的形式,监视get_info,如果重试次数达到4次且仍然无法正常获取数据,则会停止并报错。