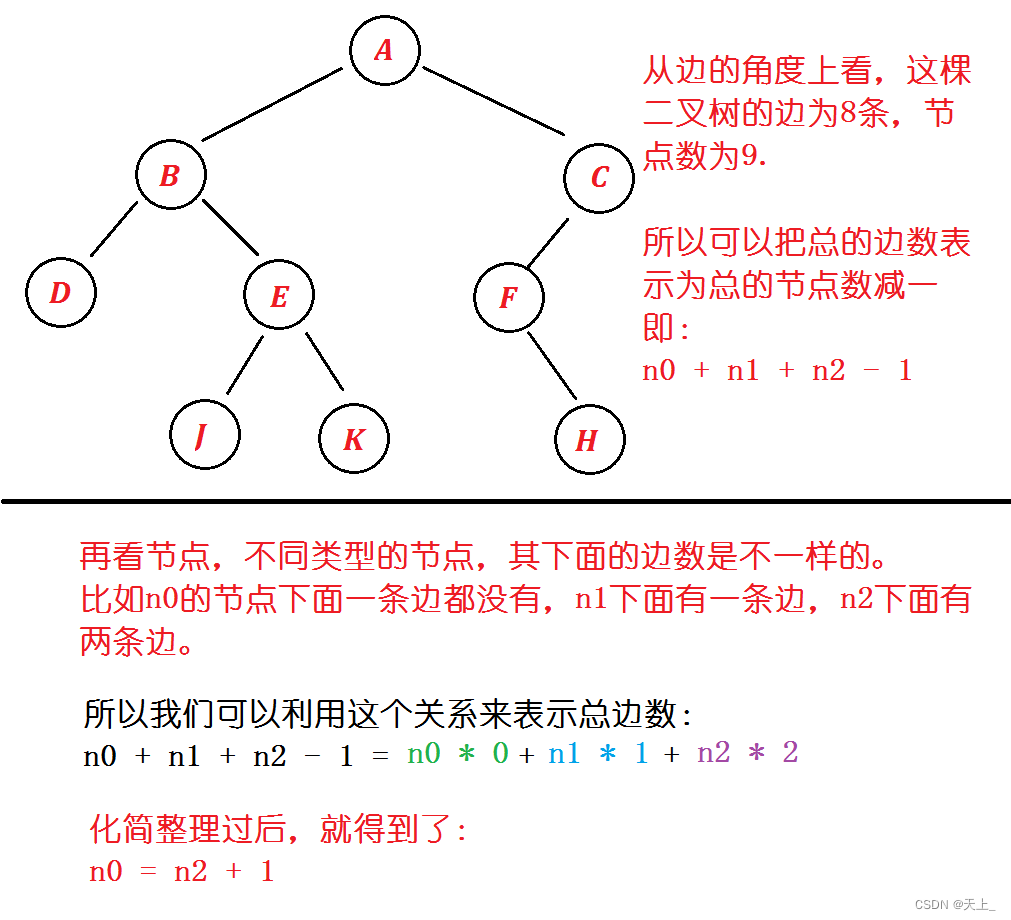
TIPS
- 快速排序本质上是一个分治递归的一个排序。
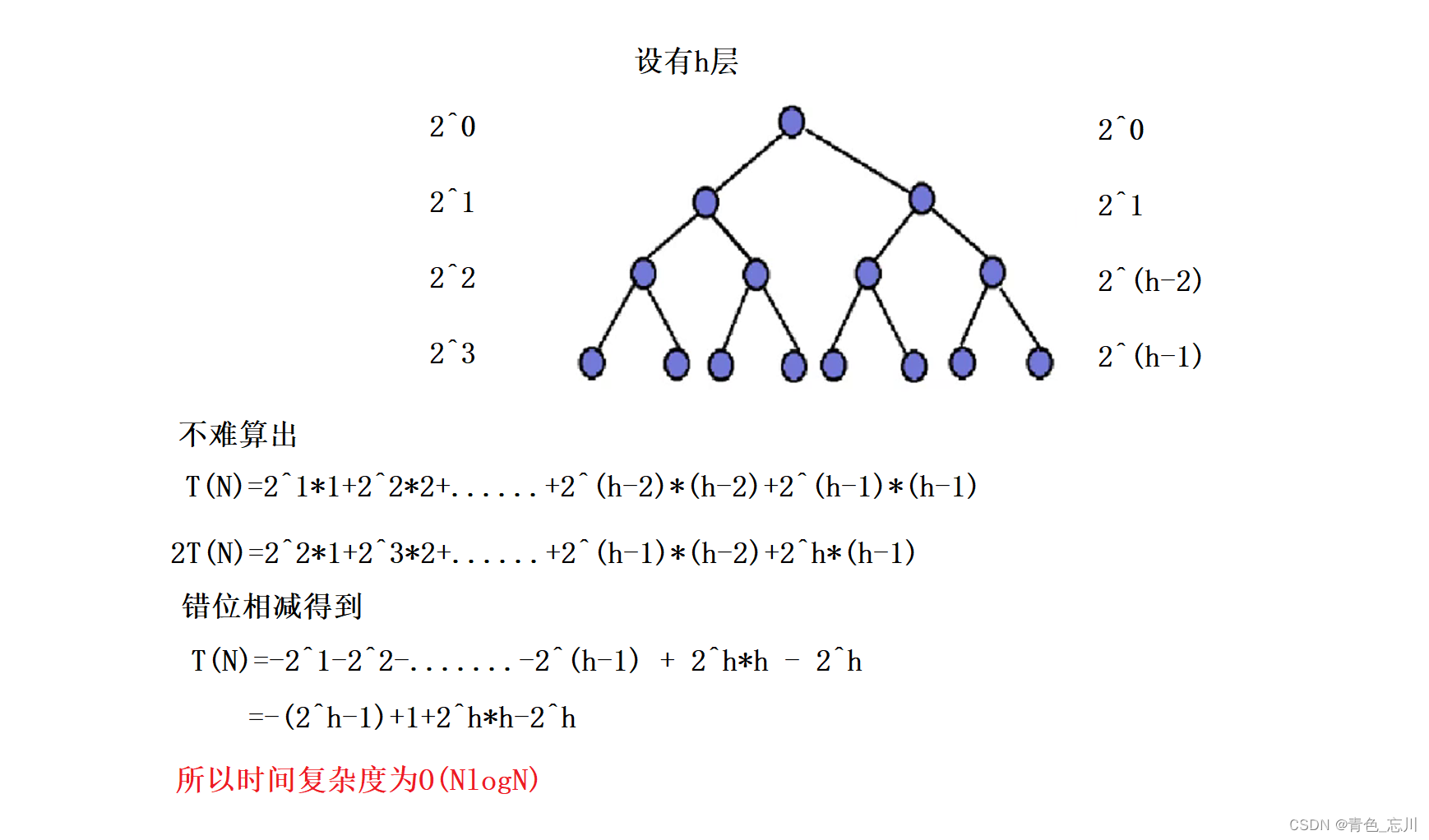
- 快速排序的时间复杂度是NlogN,这是在理想的情况之下,但是它最坏可以到达N^2。决定快速排序的效率是在单趟排序之后这个key最终落在的位置,越落在中间就越接近二分,越接近2分就越接近满二叉树,越接近二叉树它的深度就更加均匀。深度更加均匀的话,不仅可以防止栈溢出,减少递归的层次,效率上也有提高。
- 因此,由此说来,选key是十分关键的。不能一直把数组当中最左边的那个字作为关键值。选key有三数取中与随机数优化版,推荐三数取中。特别是在要排列的那个数组是有序的情况之下,如果用三数取中优化法,那么就可以确保最中间的那个值就是key。
- 有了三数取中选key优化,这个快排它的递归深度相对来说都不会特别深。
- 之前有关于快排代码回顾:
//交换函数
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//Hoare大佬原始版本
void QuickSort1(int* arr, int left , int right)
{
if (left >= right)
{
return;
}
int begin = left;
int end = right;
int keyi = left;
while (left < right)
{
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
Swap(arr + left, arr + right);
}
Swap(arr + left, arr + keyi);
keyi = left;
QuickSort1(arr, begin, keyi - 1);
QuickSort1(arr, keyi + 1, end);
}
//Hoare大佬原始版本+随机数选key优化
void QuickSort2(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
int begin = left;
int end = right;
int randi = left + rand() % (right - left);
Swap(arr + randi, arr + left);
int keyi = left;
while (left < right)
{
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
Swap(arr + left, arr + right);
}
Swap(arr + left, arr + keyi);
keyi = left;
QuickSort2(arr, begin, keyi - 1);
QuickSort2(arr, keyi + 1, end);
}
//Hoare大佬原始版本+三数取中选key优化
int GetMidNumi(int* arr, int left, int right)
{
int mid = (left + right) / 2;
if (arr[mid] < arr[right])
{
if (arr[left] < arr[mid])
{
return mid;
}
else //arr[left]>arr[mid]
{
return arr[left] < arr[right] ? left : right;
}
}
else
{
if (arr[right] > arr[left])
{
return right;
}
else
{
return arr[left] < arr[mid] ? left : mid;
}
}
}
void QuickSort3(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
int begin = left;
int end = right;
int midi = GetMidNumi(arr, left, right);
Swap(arr + midi, arr + left);
int keyi = left;
while (left < right)
{
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
Swap(arr + left, arr + right);
}
Swap(arr + left, arr + keyi);
keyi = left;
QuickSort3(arr, begin, keyi - 1);
QuickSort3(arr, keyi + 1, end);
}
//挖坑法+默认三数取中选key优化
void QuickSort4(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
int begin = left;
int end = right;
int midi = GetMidNumi(arr, left, right);
Swap(arr + midi, arr + left);
int key = arr[left];
int hole = left;
while (left < right)
{
while (left < right && arr[right] >= key)
{
right--;
}
arr[hole] = arr[right];
hole = right;
while (left < right && arr[left] <= key)
{
left++;
}
arr[hole] = arr[left];
hole = left;
}
arr[hole] = key;
QuickSort4(arr, begin, hole - 1);
QuickSort4(arr, hole + 1, end);
}
//前后指针法+默认三数取中选key优化
void QuickSort5(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
int begin = left;
int end = right;
int midi = GetMidNumi(arr, left, right);
Swap(arr + midi, arr + left);
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (arr[cur] < arr[keyi])
{
prev++;
Swap(arr + prev, arr + cur);
}
cur++;
}
Swap(arr + prev, arr + keyi);
keyi = prev;
QuickSort5(arr, begin, keyi - 1);
QuickSort5(arr, keyi + 1, end);
}
快速排序的小区间优化(假设我原先用前后指针法)
- 快速排序实际上还可以继续优化:我们知道快速排序实际上是递归分治这么进行下去的,尤其是当单趟排序完成之后这个key如果一直落在中间的话,那么如果你把每一个递归都给它放出来的话,你会发现它就是一个接近于满二叉树。
- 这时候你想象一下,假设我有1万个数,在第一次递归的时候被分成5000与5000,然后再被分成2500,2500。但随着不断的这么进行递归下去,尤其是在最后面末流,比如说递归的区间范围是五个数,然后把五个数这个区间在递归分治分成两个数与两个数,然后对于两个数的区间也在进行递归分治划分,就会发现有点大题小做,还挺麻烦的。你会发现为了让这五个数有序,我们实际上居然递归了六次。
- 在每一次分治递归的时候,你这个QuickSort的使命是让left与right这个区间里面的数有序,你用什么方法有序的话都可以,你可以把它继续切分成子问题,然后这么进行下去,让这个区间有序;可以通过直接的方法让他去有序。
- 因此也就是说当这个需要排序的区间缩小到一定程度的时候,就可以不再考虑用递归的方式继续分成子问题,然后使得这个区间有序。而是用别的排序方法。
- 插入排序是最好的,如果用希尔排序的话,希尔排序针对插入排序的优势主要体现在当数据量很大的时候,这时候我的gap取得很大,就可以让那些大的数尽快的跳到后面。但现在本身的逻辑前提就是说这个区间已经小到一定程度,怎么杀鸡焉用牛刀,根本用不着希尔排序。然后选择排序与冒泡排序的话虽然他们的时间复杂度都与直接插入排序一样N^2,但是之前就有过比较,这两种排序是无法与直接插入排序最终抗衡的。因为对于直接插入排序而言,只要在这个数据段当中,有几部分小段小段是有序的,对于他的优势就非常大。对于堆排也麻烦还要建堆。库函数也是这么优化的。
- 然后以理想化的方式来看待,就以一颗满二叉树来看待,如果说把最后一层的递归给他全部消灭掉的话,能够使得总的函数调用次数减少掉一半。
- 比如说当整个待排序的数组里面的元素个数(right - left + 1)小于等于十个的时候,这时候就不进行继续递归分治的玩法,还是采用直接插入排序。想一想这样的话就能够减少掉往下面的三层递归(以理想化的满二叉树为例),那么算下来可以减少50%+25%+12.5%即87.5%的递归(以理想化的满二叉树为例),效果贼棒
- 然后进行直接插入排序的时候,那个函数传参又是一个很坑的地方。insertSort的第一个参数应该为arr+left
//前后指针法(默认三数取中选key优化)+小区间优化
void InsertSort(int* arr, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
if (right - left + 1 <= 10)
{
InsertSort(arr + left, right - left + 1);
return;
}
int begin = left;
int end = right;
int midi = GetMidNumi(arr, left, right);
Swap(arr + midi, arr + left);
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (arr[cur] < arr[keyi])
{
prev++;
Swap(arr + prev, arr + cur);
}
cur++;
}
Swap(arr + prev, arr + keyi);
keyi = prev;
QuickSort(arr, begin, keyi - 1);
QuickSort(arr, keyi + 1, end);
}
快速排序的非递归实现
递归改成非递归有两种方式:1. 直接改成循环。2. 使用栈辅助改循环

- 快排在实际应用当中绝对会有问题,只要是递归,就会有问题。
- 递归的真正问题在于:当深度太深的时候,递归是撑不住的。有时候程序本身是没有任何错误与问题的。实际上递归写着好着呢,但是程序就是跑不出来。这时候其实就是一个栈溢出的问题。
- 因为递归是有消耗的,这个消耗就是建立函数栈帧。当栈的空间不够你继续去建立函数栈帧,完了栈溢出了。
- 递归真正的问题有两个:效率慢一些(有是有,但现阶段影响不大),深度太深会栈溢出。但是release环境下可能会有一定的优化,包括函数栈帧可能变小了等等,release优化非常明显。但是在debug环境下早就撑不住了,但在debug下面不能跑也是个问题啊,我不能调试了啊。
- 然后对于快速排序的递归方法进行看待的话,你会发现在一次又一次的递归当中,首先指向数组首元素的那个指针肯定是雷打不动的,当然,数组里面的元素都在不断的发生变化。递归的话主要是那个待处理数组区域的左右区间在不断的发生变化。这一点非常关键。数组的话就这么一个就这么放在内存里面,然后数组里面的那些数字都在不断的发生交换与变化,再进行这么的一个排序。然后递归递归,你仔细去看一看这个递归函数里面记录的到底真正是什么?你会发现就是左右区间。
- 然后我现在自己手搓一个栈进行辅助(我不用递归了)。因为我分析出来我已经知道这个递归函数他真正实际上是在记录左右区间,那我就用我自己的一个栈用来记录左右区间。
- 当然,就单趟排序而言,与递归函数的单趟排序没有任何的区别。只不过就是说在单趟排序之后,把接下来需要继续处理的数组区间的左右边界(肯定是有左边和右边两组)给他压到栈里面去。
- 子区间入栈。根据栈这个数据结构的特性,先进后出,后进先出。然后等会儿要进行下一轮的单趟排序的时候,那我该怎么知道我需要处理哪个数组区域的数据呢?这时候就把栈顶的元素出栈便能够获取到一对左右区间。每次的过程就是:从栈里面取一段区间,单趟排序,将单趟排序后分割的子区间入栈,如果说子区间只有一个值或者不存在就不入栈
- 栈的意义就是把区间存起来。
- 以前的话单趟排序完成之后就对两个子区间进行分治递归,但现在已经说了分治递归的话,有个潜在的问题就在于可能会发生栈溢出的情况。因此现在当把单趟排序完成之后,就把两个新的子区间给他入栈。然后对于两个新的子区间在入栈之前先进行判断一下,就是说判断这个区间到底值不值得入栈,如果区间不存在或者只有一个值,这段区间我才不要继续对你单趟排序
- 虽然说整个过程并不是递归,但是会发现他好像也与递归差不多,因为递归本质上不也在这么干嘛。只是现在不用递归去玩,只是把数据存到栈这个数据结构里面。
- 以后但凡就是说递归要改成非递归的话。你就去看一下这个递归函数它的参数到底是什么?参数条件变化的是什么?那么这样的话,栈里面基本上存的就是什么(如果用栈辅助的话)
#include "Stack.h"
void QuickSortNonR(int* arr, int left, int right)
{
ST stack;
STInit(&stack);
STPush(&stack, right);
STPush(&stack, left);
while (!STEmpty(&stack))
{
int begin = STTop(&stack);
STPop(&stack);
int end = STTop(&stack);
STPop(&stack);
if (begin >= end)
{
continue;
}
int midi = GetMidNumi(arr, begin, end);
Swap(arr + midi, arr + begin);
int keyi = begin;
int prev = begin;
int cur = prev + 1;
while (cur <= end)
{
if (arr[cur] < arr[keyi])
{
prev++;
Swap(arr + prev, arr + cur);
}
cur++;
}
Swap(arr + keyi, arr + prev);
keyi = prev;
STPush(&stack, end);
STPush(&stack, keyi + 1);
STPush(&stack, keyi - 1);
STPush(&stack, begin);
}
STDestroy(&stack);
}