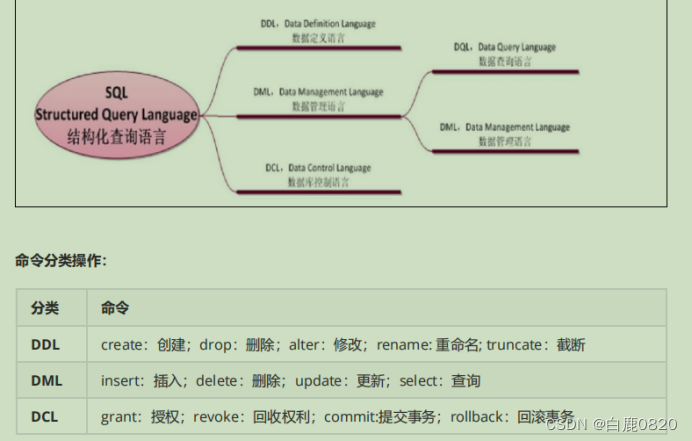
常见的聚合函数:
avg(),求平均值; sum() 求和;
count(),计算和; min()求最小值;
max()求最大值
聚合函数的应用场景:
COUNT:用于统计指定列的行数,可以用于统计表中的记录数或者去重后的记录
数。
SUM:用于计算指定列的总和,可以用于计算某个时间段内的销售总额等。
AVG:用于计算指定列的平均值,可以用于计算某个时间段内的平均销售额等。
MAX:用于返回指定列的最大值,可以用于查找最高分数或者最大年龄等。
MIN:用于返回指定列的最小值,可以用于查找最低分数或者最小年龄等。
三范式的各个范式的目的是:
第一范式:每个字段的数据不能再被拆分
第二范式:通过拆表的方式减少数据冗余
第三范式:通过分析实体的关系来形成主表与从表
三范式的优缺点:
优点:三大范式既减少数据冗余,也避免了一些更新数据时的异常。
· 满足范式的表通常较小,可以更好的放入内存,执行操作更快;
缺点:按照范式设计出来的表在数据冗余的问题虽然得到解决,但是会生成许多
表,导致了表数量的复杂性,其二,查询· 数据的时候,多表查询的时间远远高
于单表查询的时间。
项目的sql语句:
已知tb_note为所有的笔记 用noteId来区分,tb_note_type中含有id对应的type
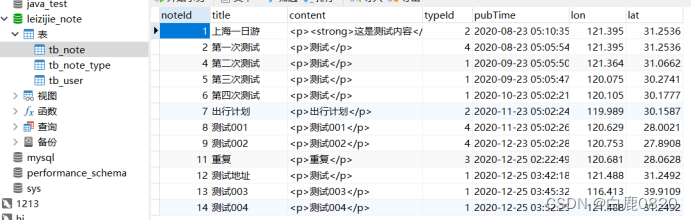
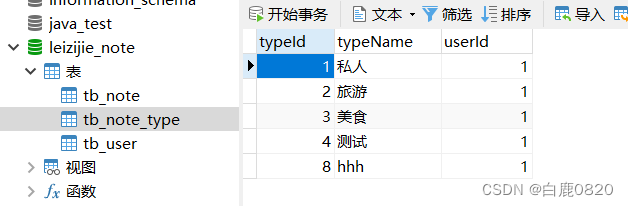
需求1:根据noteId查找出云记的笔记各方面信息 包括type
Select noteId,title,content,pubTime,typeName,n.typeId from tb_note n inner join tb_note_type t on n.typeId =t.typeId where noteId=?;需求2:
通过userId查询云记列表中的某些值:
Select lon,lat from tb_note n inner join tb_note_type t on n.typeId=t.typeId where userId=?;需求3;
删除某指定noteId对应的行
Delete from tb_note where noteId=?;需求4:
按照次数排序降序 找出相同年月的云记
DATA_FORMAT ( pubTime , ’%y年%m月’)=================》日期格式化
将 count(1) 重命名为 notecount
格式化后的列 重命名为 groupname
根据时间来分组
根据count来排序
Select count(1)Notecount, DATA_FORMAT(pubTime, '%y年%m月') groupName
from tb_note n inner join tb_note_type t on n.typeId =t.typeId where userId =?
group by DATA_FORMAT(pubtime,'%y年%m%日')
order by DATA_FORMAT(publicTime,'%y年%m月') desc;