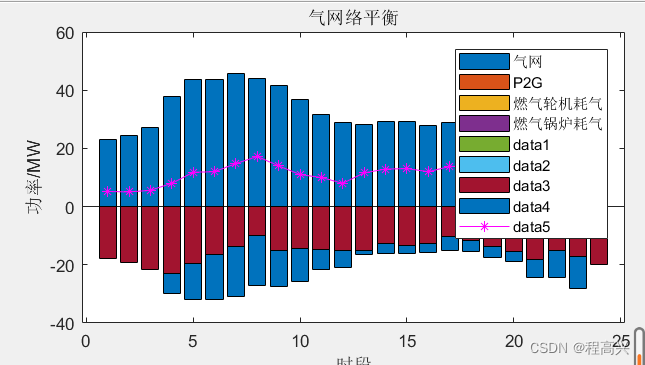
【论文精读】COLING 2020 -带有对偶关系图注意力网络的事件检测模型
【论文原文】:Event Detection with Dual Relational Graph Attention Networks
【作者信息】:Jiaxin Mi and Po Hu and Peng Li
论文:https://aclanthology.org/2022.coling-1.172.pdf
代码:https://github.com/Macvh/DualGAT (未上传)
博主关键词:事件检测
推荐论文:无

摘要
事件检测旨在从文本片段中识别特定事件类型的实例,是信息提取中的基本任务。大多数现有方法利用语法知识和一系列语法关系来增强事件检测。然而,这些基于语法的方法的副作用是,它们可能混淆不同的语法关系,并倾向于引入冗余或噪声信息,这可能导致性能下降。为此,我们提出了一个简单而有效的模型DualGAT (Dual Relational Graph Attention Networks,对偶关系图注意力网络),该模型利用句法和语义关系的互补特性来缓解这一问题。具体地说,我们首先构造一个对偶关系图,它将语法和语义关系聚集到图中的关键节点上,这样就可以从多个透视图(即语法和语义视图)全面捕获事件相关的信息。然后采用增强关系图注意网络对图进行编码,并通过引入上下文信息优化其注意权重,进一步提高事件检测的性能。在标准ACE2005基准数据集上进行的大量实验表明,我们的方法显著优于最先进的方法,并验证了DualGAT优于现有基于语法的方法。
1、简介
如下图1所示,事件检测的目的是识别句子中的事件触发词thrust,并将其分类为Transport事件。事件检测具有大量的下游应用,是信息抽取的核心任务之一。

先前的事件抽取任务可以分为传统的基于特征的方法和深度学习方法,由于深度神经网络强大的特征抽取能力,深度神经网络方法已经超过了传统的基于特征的方法。近年来,大多数深度学习方法都更加注重在事件检测中利用句法关系。这些方法采用图神经网络(GNNs),如图卷积网络(GCNs)和图注意力网络(GATs)对依赖树进行编码,以学习单词的有效表示。由于依赖树为ED传递了丰富的语言信息,基于语法的方法通常能获得更好的性能(Xie et al, 2021)。
然而,现有的基于句法的方法仍有两个缺点需要解决。首先,依赖树不能总是简洁地捕获与触发词相关的显著信息,这可能包含靠近根节点的噪声依赖关系,并误导事件检测(Lai et al, 2020;Liu et al, 2021)。如图1所示,基于语法的事件检测方法错误地将红色标记的依赖项标识为Attack事件的触发词相关提示。由于troops和触发词候选striking与根节点distance有直接关系,基于GNN的方法容易更加关注它们,从而预测错误的触发词(Liu et al, 2021)。值得注意的是,在这种情况下,标记的蓝色依赖项与真正的触发词thrust密切相关,应该更加强调地加以利用。其次,完全依靠语法依赖树不足以完成事件检测。现有依赖项解析器的解析结果可能包含不正确的或弱相关的信息,由于可能的错误传播,这将不可避免地影响基于语法的事件检测方法的性能。此外,句法依赖树不能提供事件检测所需的所有语言知识。
针对上述问题,我们提出了一种新的DualGAT模型,该模型充分利用句法和语义信息来提高事件检测性能。受基于方面级依赖解析(Wang et al, 2020a)的启发,我们构造了一个包含句法和语义关系的对偶关系图,以捕获与触发词相关的信息。根据经验,句子中只有一小部分依赖关系是任务意识的(Zhang et al,2018;He et al, 2018)。因此,为了减少噪声关系的影响,我们剪枝与触发词候选没有直接连接的原始语法依赖项,并重建了句子中剩余单词与触发词候选之间的其他连接。除了句法信息外,我们还引入语义关系信息,使其根植于句子的谓语中。其次,采用增强关系图注意力网络对图进行编码,从句法和语义角度学习根节点的表示。特别地,我们引入了上下文信息来调整注意力权重,以减轻由于引入依赖解析器而可能丢失的信息。在标准ACE2005基准数据集上的实验结果表明,DualGAT在很大程度上优于最先进的方法。
本文最主要的贡献如下所示:
- 我们构造了一个对偶关系图,将句法和语义关系收敛到图中的关键节点,可以从不同角度捕获重要的事件信息,减少句法解析器造成的信息丢失或噪声。
- 采用增强关系图注意网络对图进行编码,并通过引入上下文信息优化其注意权重。
- 实验结果进一步验证了DualGAT相对于现有方法的优越性。DualGA T通过最先进的基于语法的方法实现了F1分数的5%改进。
2、相关工作
近年来,事件检测受到了广泛的关注。传统的事件检测方法使用手工制作的语言特征进行事件检测,例如词汇特征、句法特征或实体特征(Hong et al, 2011; Ahn, 2006)。然而,设计这些特性非常耗时,而且不容易适应其他任务或新的领域。
随着神经网络的快速发展,一系列的神经事件检测方法被提出。许多研究人员将新的学习策略应用于事件检测,例如利用弱监督学习策略来生成更多的标记数据,以提高事件检测的性能(Zeng et al, 2018; Yang et al, 2018)。Wang等人(2019)采用对抗性训练机制来获得多样化和准确的训练数据。Lu等人(2019)提出了一种基于知识蒸馏的方法,以在稀疏标记的触发词上获得更好的性能。最近提出的一些方法引入了额外的知识,通过开放领域触发词知识(Tong et al, 2020)、实体知识(Liu et al, 2019)和语法依赖关系(Yan et al, 2019)来改进事件检测。
依赖关系的有效性已在许多自然语言处理(NLP)任务中得到验证,如情感分析(Wang et al, 2020a)和关系提取(He et al, 2018)。由于句法和结构信息丰富,句法依赖关系在事件检测中也发挥着重要作用(Liu et al, 2018b)。例如,Yan等人(2019)利用句子中的多阶句法关系来获得更好的触发词表示。Lv等人(2021)集成语法和文档信息,以便更好地检测事件。Cui等人(2020)提出了一个模型来进一步探索依赖关系的类型信息,以获取任务感知知识。由于现有的基于图的模型引入了许多不确定触发词的表示,Lai等人(2020)提出通过门控机制过滤噪声信息。由于gnn和句法依赖树的有效结合,这些基于句法的事件检测方法总体性能优于普通的深度学习方法。
虽然这些作品使用了相似的句法信息,但很少有从新的角度对原始图进行重塑,以便于获取与事件相关的显著信息。原始依赖树包含丰富的结构和语言知识,但它可能不准确,并且包含与事件无关的信息。此外,据我们所知,还没有基于语法的方法显式地使用语义信息来补充用于事件检测的语法信息。为此,我们提出了DualGAT,它同时考虑了语法和语义关系以及上下文信息来进行事件检测。
3、方法
3.1 方法总览
DualGAT的整体架构如图2所示,由三个主要组成部分组成:(1)关系图构造器(§3.2),通过依赖关系解析和语义角色标记来构造对偶关系图;(2)增强关系图注意网络(Augmented Relational Graph Attention Networks,§3.3),在注意权重的适应中引入额外的上下文信息,并对对偶关系图进行编码,从句法和语义角度获得根节点的表示;(3)事件检测器(§3.4),利用Biaffine模块在句法和语义表示之间交换相关特征,并执行事件检测。

3.2 关系图构建
3.2.1 对偶关系图
现有的方法受到噪声依赖关系的干扰,并倾向于学习无关的触发词表示(Lai et al, 2020)。由于候选触发词是事件检测任务的重点,这些与触发词无关的噪声信息不可避免地会影响性能。此外,现有依赖解析器的解析结果可能包含不正确的或弱相关的信息,这限制了事件检测的性能。
许多工作已经证明,只有一小部分句法关系是任务感知的(Zhang et al, 2018;He et al, 2018),识别触发词是事件检测任务的核心。因此,我们认为,更多地关注与触发词候选直接关联的句法关系可以减少错误句法关系的影响。此外,语义和句法知识的互补性在相关的NLP任务中得到了利用和验证,如关系提取(Bovi et al, 2015)和实体提取(Chan and Roth, 2011)。我们相信语义关系可以弥补句法关系的不足,减少对依赖解析器的依赖。
为此,我们构建了一个对偶关系图结构,它将句法关系合并到触发词候选中,并且聚合谓词动词的语义关系,以提高图的鲁棒性。算法1描述了对偶关系图的构造过程。我们首先利用依赖解析器获得给定句子的原始语法关系。然后,我们保留直接连接到触发词候选对象的语法关系,并修剪剩余的关系。为了提高图的鲁棒性,我们进一步将修剪后的关系替换为具有触发词候选的按距离分类的虚拟关系。具体来说,虚拟关系的类型定义为 v i r : d vir: d vir:d,其中 d d d表示单词与触发词候选之间的距离。最后,我们进行语义角色标注,在其他词和谓语动词之间附加语义关系,并执行与上述相同的过程。

经过上述处理得到的图就是对偶关系图。它有两个相同级别的子图:语法关系子图,将语法信息收敛到触发词候选;语义关系子图,将语义信息收敛到谓语动词。形式上,我们将对偶关系图定义为 G = ( V , E ) G = (V, E) G=(V,E)与边型映射函数 τ : E → T E τ: E→T_E τ:E→TE相关。 V V V表示句子中的单词节点集合, E E E表示关系边集合。 T E T_E TE表示所有类型的关系,包括句法关系、语义关系和虚拟关系。将单词节点 i i i和单词节点 j j j之间的关系边定义为 e i j e_{ij} eij。
3.2.2 对偶关系图的优势
对偶关系图在事件检测方面具有独特的优势。首先,为每个触发词候选对象定制对偶关系图,减少引入噪声的触发词未知信息;其次,基于谓语动词的语义关系可以提高对偶关系图的鲁棒性。第三,双关系图结构有利于事件检测模型捕获任务感知信息。我们使用三个简单的示例来说明上述优点,如图3所示。

首先,例子(a)和例子(b)是两个自定义的对偶关系图,用于同一句中不同的触发词候选。现有的方法倾向于将striking识别为Attack事件的触发词,因为在原始依赖树中,stricking、enemy和troops之间存在很强的关联。而“striking”的对偶关系图,则剪去了“trigger-不可知论”的关系,清楚地说明了stricking只是distance的形容词修饰语(amod)。此外,thrust的对偶关系图可以帮助ED模型捕捉到它与through和make的联系,而不受原始依赖树中噪声依赖关系的干扰。因此,ED方法倾向于将thrust识别为Transport事件的触发词,而不是striking。
此外,例©可以说明语义关系的重要性。例©中,紫色箭头为原句法关系,橙色箭头为对偶关系图的附加语义关系。基于原有的句法关系,ED方法倾向于将War识别为Attack事件的触发词,因为War和Win之间有很强的联系。即使剔除了触发词无关的句法关系,正确的触发词Former仍然不能得到足够的重视。而语义关系可以使深层语义信息从now流向Former。“ARGM-TMP”关系引入了时间信息,以帮助识别Former作为结束位置事件的触发词。
最后,如例(a)和(b)所示,对偶关系图没有复杂的相互作用。对偶关系图的结构清晰且聚合。它可以减少噪声相互作用的干扰,降低ED模型捕获触发词相关信息的难度。
3.3 增强关系图注意力网络
为了更有效地编码用于事件检测的二元关系图,我们提出了一种增强关系图注意网络(ARGAT),通过引入额外的上下文信息来编码由句子中的单词构建的图。
3.3.3 图注意力网络
图神经网络(Scarselli et al, 2009)已被广泛用于编码事件检测的依赖树,因为它们可以基于信息聚合方案有效地捕获相关信息(Cao et al, 2021)。此外,大量工作表明,图卷积网络(Schlichtkrull et al, 2018)不能有效利用多跳关系信息(Yan et al, 2019)。直观地说,事件检测任务的核心是捕获带有触发词候选词的相关单词。因此,我们应用图注意力网络(Velickovic et al, 2018),它可以更有效地利用单词之间的关系来编码对偶关系图。
形式上,给定一个具有
L
L
L个词节点的对偶关系图
G
G
G,节点
i
i
i的邻域节点集定义为
N
i
N_i
Ni。第
l
l
l层节点i的特征向量记为
h
i
l
(
h
i
l
∈
R
F
)
h^l_i(h^l_i∈\mathbb{R}^F )
hil(hil∈RF),
F
F
F为节点特征的维度。对于
l
+
1
l+1
l+1层的节点
i
i
i,多头图注意网络的计算定义如下:
h
a
t
t
i
l
+
1
=
∥
k
=
1
K
σ
(
∑
j
∈
N
i
α
i
j
l
k
W
k
l
h
j
l
)
h_{att_i}^{l+1}=\parallel_{k=1}^{K} \sigma \left( \sum_{j \in N_i } \alpha_{ij}^{lk}W_k^lh_j^l \right)
hattil+1=∥k=1Kσ
j∈Ni∑αijlkWklhjl
α i j l k = exp ( f 1 ( a T [ W k l h i l ∥ W k l h j l ] ) ) ∑ t ∈ N i exp ( f 1 ( a T [ W k l h i l ∥ W k l h t l ] ) ) \alpha_{ij}^{lk}=\frac{\exp (f_1(a^T [W_k^l h_i^l \parallel W_k^l h_j^l]))}{\sum_{t \in N_i} \exp (f_1(a^T [W_k^l h_i^l \parallel W_k^l h_t^l]))} αijlk=∑t∈Niexp(f1(aT[Wklhil∥Wklhtl]))exp(f1(aT[Wklhil∥Wklhjl]))
其中 h a t t i l + 1 h_{att_i}^{l+1} hattil+1为第 l + 1 l+1 l+1层节点 i i i的注意力头, W k l W^l_k Wkl为变换矩阵,f 1 ( ⋅ ) 1(·) 1(⋅)为LeakyReLU的函数, a a a为权重向量, K K K为head数, ∥ k = 1 K \parallel_{k=1}^{K} ∥k=1K表示 h 1 h_1 h1到 h K h_K hK的向量拼接。
3.3.2 AR-GAT
关系图注意力网络(Wang et al, 2020a)扩展了原始图注意力网络,增加了额外的头部,以利用边缘的类型信息。然而,关系图注意力网络与对偶关系图的编码并不完全兼容。一方面,最初生成的原始句法和语义关系可能是错误的。另一方面,在对偶关系图的构造过程中,重塑和修剪可能进一步导致源于解析器的错误传播。因此,关系头不足以准确控制来自邻近节点的信息流。
为了克服上述问题,我们建议从单词节点引入额外的上下文信息,以更准确地控制信息流。因子分解机制的效果已经在许多任务中得到了证明(Guo et al, 2017)。受到因子分解机制的启发,我们应用了一个内积单元用于组合上下文信息和类型信息。
形式上,初始关系嵌入矩阵定义为
W
t
∈
R
N
t
×
F
W_t∈\mathbb{R}^{N_t×F}
Wt∈RNt×F,
N
t
N_t
Nt为关系类型的个数。对于
l
+
1
l+1
l+1层的节点
i
i
i,多头增强关系图注意力网络的计算定义如下:
h
r
e
l
i
l
+
1
=
∥
m
=
1
M
σ
(
∑
j
∈
N
i
β
i
j
l
m
W
m
l
h
j
l
)
{h}_{r e l_{i}}^{l+1}=\|_{m=1}^{M} \sigma\left(\sum_{j \in {N}_{i}} \beta_{i j}^{l m} {W}_{m}^{l} {h}_{j}^{l}\right) \\
hrelil+1=∥m=1Mσ
j∈Ni∑βijlmWmlhjl
R i j m = ( W m 1 f 2 ( τ ( e i j ) , W t ) + b m 1 ) ⊙ σ ( W m 2 ( h i ∥ h j ) + b m 2 ) R_{i j}^{m}=\left({W}_{m 1} f_{2}\left(\tau\left(e_{i j}\right), {W}_{t}\right)+b_{m 1}\right) \odot \sigma\left({W}_{m 2}\left({h}_{i} \| {h}_{j}\right)+b_{m 2}\right) \\ Rijm=(Wm1f2(τ(eij),Wt)+bm1)⊙σ(Wm2(hi∥hj)+bm2)
g i j l m = σ ( ( r e l u ( R i j m W m 3 + b m 3 ) W m 4 + b m 4 ) ) g_{ij}^{lm}=\sigma (\left( relu \left(R_{i j}^{m} {W}_{m 3}+b_{m 3}\right) {W}_{m 4}+b_{m 4}\right)) gijlm=σ((relu(RijmWm3+bm3)Wm4+bm4))
β i j l m = exp ( g i j l m ) ∑ j ∈ N i exp ( g i j l m ) \beta_{ij}^{lm}=\frac{\exp (g_{ij}^{lm})}{\sum_{j \in N_i} \exp (g_{ij}^{lm})} βijlm=∑j∈Niexp(gijlm)exp(gijlm)
其中
h
r
e
l
i
l
+
1
h^{l+1}_{rel_i}
hrelil+1表示节点
i
i
i在第
l
+
1
l+1
l+1层的增强关系注意头,
M
M
M为头数,
f
2
(
τ
(
e
i
j
)
,
W
t
)
f_2(τ(e_{ij}),W_t)
f2(τ(eij),Wt)为根据关系嵌入矩阵
W
t
W_t
Wt将边
e
i
j
e_{ij}
eij映射到相应的关系嵌入的映射函数,计算节点i的最终表示形式为:
o
i
l
+
1
=
h
a
t
t
i
l
+
1
∥
h
r
e
l
i
l
+
1
o_i^{l+1}=h_{att_i}^{l+1} \parallel h_{rel_i}^{l+1}
oil+1=hattil+1∥hrelil+1
h i l + 1 = r e l u ( W l + 1 o i l + 1 + b l + 1 ) h_i^{l+1}=relu \left(W_{l+1}o_i^{l+1} + b_{l+1} \right) hil+1=relu(Wl+1oil+1+bl+1)
3.4 事件检测
我们使用BERT (Devlin et al, 2019)来获得图节点的词嵌入,将词 x i x_i xi的嵌入定义为 h i 0 h^0_i hi0。我们分别使用 h t 0 h^0_t ht0和 h v 0 h^0_v hv0表示触发词候选节点和谓词谓词节点的初始嵌入。然后应用AR-GAT分别对对偶关系图的两个子图进行编码,得到它们的根表示 h t l h^l_t htl和 h v l h^l_v hvl。 h t l h^l_t htl和 h v l h^l_v hvl分别聚合句法和语义信息。
为了在这两种类型的信息之间有效地交换相关特征,我们采用了相互Biaffine转换(Li et al, 2021b)。交互过程为:
h
t
l
′
=
softmax
(
h
t
l
W
1
(
h
v
l
)
T
)
h
v
l
h_t^{l'}=\text{softmax}(h_t^lW_1(h_v^l)^T)h_v^l
htl′=softmax(htlW1(hvl)T)hvl
h v l ′ = softmax ( h v l W 2 ( h t l ) T ) h t l h_v^{l'}=\text{softmax}(h_v^lW_2(h_t^l)^T)h_t^l hvl′=softmax(hvlW2(htl)T)htl
W 1 , W 2 W_1,W_2 W1,W2是可训练参数。
最终,我们连接
h
t
l
′
,
h
v
l
′
h_t^{l'},h_v^{l'}
htl′,hvl′的表示:
x
=
h
t
l
′
∥
h
v
l
′
x= h_t^{l'}\parallel h_v^{l'}
x=htl′∥hvl′
最终的表示
x
x
x将送入全连接层,经过softmax函数进行分类:
p
(
t
)
=
softmax
(
W
p
x
+
b
p
)
p(t)=\text{softmax}(W_p x+ b_p)
p(t)=softmax(Wpx+bp)
4、实验
数据集:ACE2005。
评估指标:precision,recall,f1.
baseline:
- 基于句法的模型:GCN-ED,SA-GRCN,EE-GCN,GatedGCN。
- 基于外部知识的方法:PLMEE,DNR,SS-JDN。
实验结果

消融实验

5、总结
在本文中,我们提出了一个简单而有效的模型DualGAT (Dual Relational Graph Attention Networks,双关系图注意网络),以解决基于语法的事件检测任务方法的缺点。为了便于从句子的不同角度准确捕捉关键信息,我们设计了一个对偶关系图,它将句法和语义关系聚集到图中的关键节点上。为了有效地编码二元关系图,我们提出了增强关系图注意网络,引入上下文信息来计算更健壮的注意力权重。实验结果表明,该方法具有较好的性能。
我们打算在未来进一步探讨我们工作的几个方面。首先,我们将改进语义信息引入的方式。其次,我们将开发一种更有效的方法来融合句法和语义信息。第三,我们将探讨增强关系图注意力网络在其他任务中的作用。
【论文速递 | 精选】

最近工作