正则表达式的基本使用
前言: 在我们开发过程中,有很多地方需要用到正则表达式。如验证用户登录信息、手机号、邮箱地址等等。那你都会正则表达式的哪几个方法呢?
首先,我们要知道什么是正则表达式。
正则表达式的定义:
- 正则表达式
RegExp (regular expression)是ECMAScript内置对象,是一个用于对字符串实现逻辑匹配运算的对象
正则表达式的作用:
- 按照某种规则来匹配字符串,而正则表达式就是制定这个规则
如何使用正则表达式
- (1) 创建正则表达式对象
- (2) 开始匹配
使用test()方法
由于正则表达式非常的晦涩难懂,使用图形可以更好的方便理解,正所谓一图胜千言!
正则表达式图形化网站:https://regexper.com/
下面就让我们步入正题,开始学习正则。
1、元字符与原义文本字符
一个正则表达式主要由两部分组成:
-
原义文本字符 : 就是字符本身的含义,千万别想多
/abc/ // 含义,就是检查字符串中有没有abc。 别想多了 // 不是说有a或者有b或者有c,也不是说有a 和 b 和 c console.log(/abc/.test('a123'));//false console.log(/abc/.test('ab123c'));//false console.log(/abc/.test('abc123'));//true -
元字符 : 改变了字符串本身的含义 (相当于 js 的关键字)
. \ | [] {} () + ? * $ ^
2、字符类
有时候我们并不想只匹配一个字符,而是想要匹配符合某一类特征的字符,这时就可以使用字符类
1、简单字符类:[]
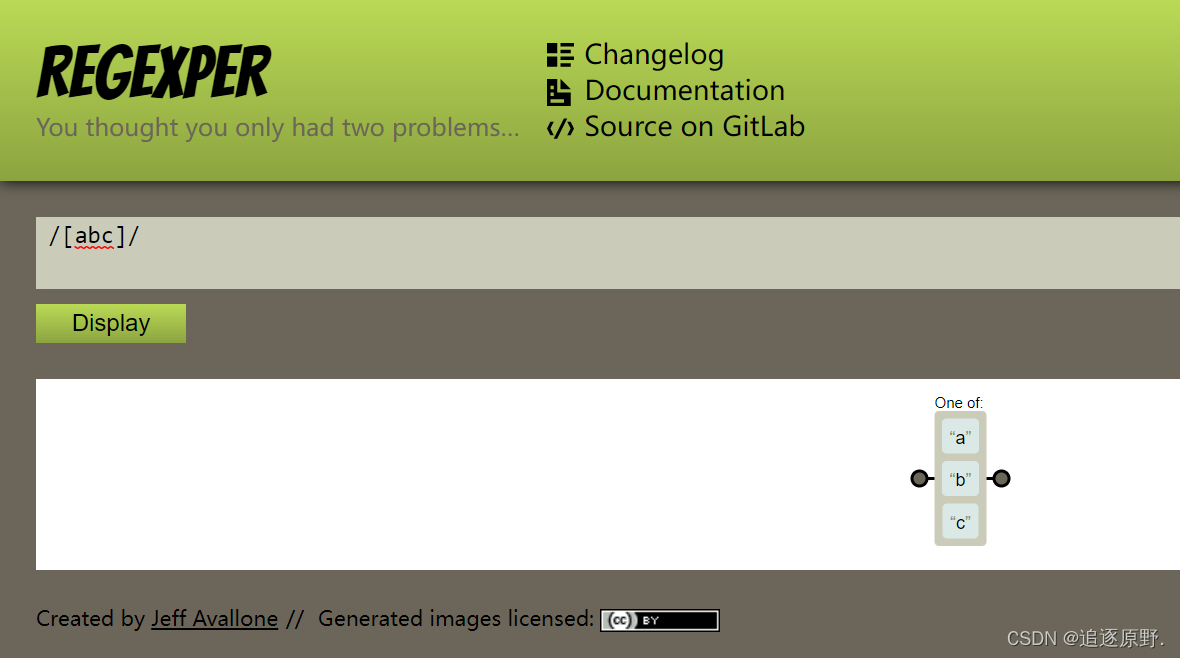
/[abc]/
// 把字符a或b或c归为一类,可以匹配这类的字符
// 含义是,匹配字符串中只要有 a或者b或者c任何一个即可
console.log ( /[abc]/.test ( "eeeeefffff" ) );//false
console.log ( /[abc]/.test ( "eaeeffffff" ) );//true
console.log ( /[abc]/.test ( "ebeeeffffff" ) );//true
2、反向类(负向类):^
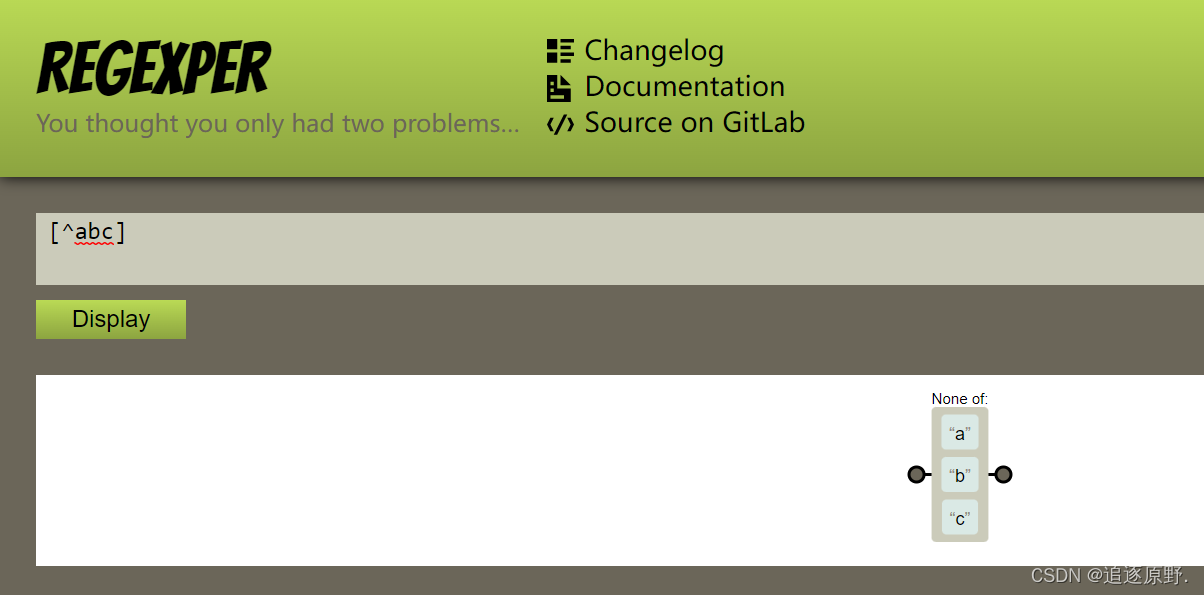
// 反向类意思是不属于某类的内容
/[^abc]/
// 含意是,不是字符a或b或c的内容
// 只要有任何一个字符不是a或者b或者c,就满足条件
console.log ( /[^abc]/.test ( "1abacbc" ) );//true
console.log ( /[^abc]/.test ( "aaabbbcccc" ) );//false
console.log ( /[^abc]/.test ( "aaabbbcccce" ) );//true
3、范围类: -
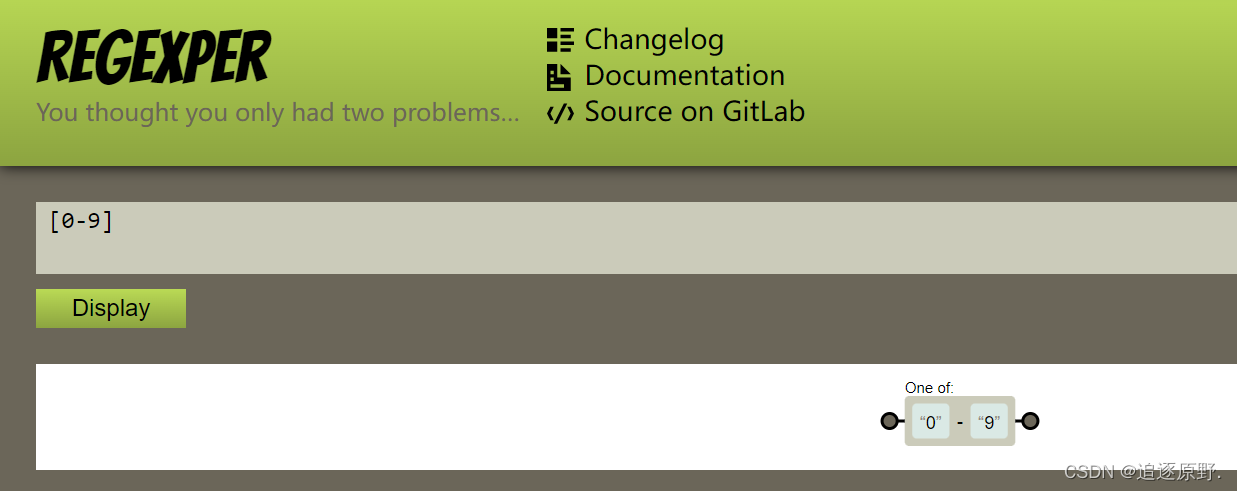
在实际开发中,如果我们需要匹配所有的数字, 可以写[0123456789] : 含义是,有任何数字的内容。如果这样写,表达式就很冗余,假如我要匹配字母,那就要写 [abcdefg…xyz],非常麻烦。
那么如何解决呢?可以使用范围类 -。
[0-9] : 含义是, 0-9之间的任意字符
[a-z]: 含义是,a-z之间的任意字符
[A-Z]:含义是,A-Z之间的任意字符
console.log ( /[0-9]/.test ( "1acasdas" ) );//true 只要有数字就满足
console.log ( /[0-9]/.test ( "acasdas" ) );//false
注意:
- 范围类是一个闭区间, [a-z],这个范围包含字符a和z本身
- 在[]内部是可以连写的, [0-9a-zA-Z] : 含义是,包含数字0-9,或者a-z,或者A-Z任意字符
- 右边一定要大于左边,例如 [5-8],这是合法的,表示5-8之间的数字,不能写[8-5],程序会报错(正则语法错误)
4、预定义类
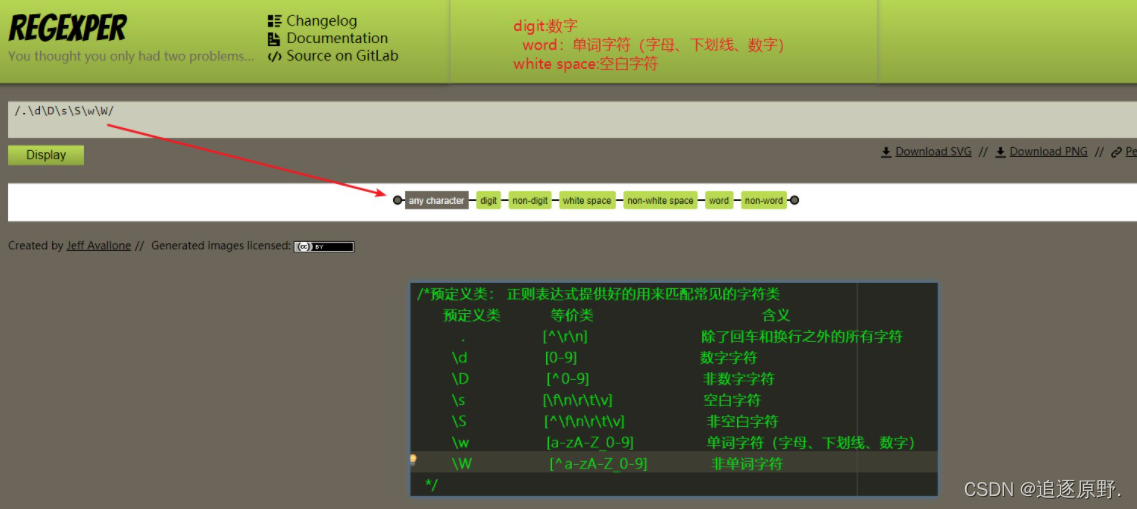
.:除了回车和换行之外的所有字符
console.log ( /./.test ( "\r\n" ) );//false
console.log ( /./.test ( "" ) );//false 空字符
console.log ( /./.test ( " " ) );//true 空格字符
\d数字字符(只要有数字即可)
console.log ( /\d/.test ( "123abc" ) );//true
console.log ( /\d/.test ( "abc" ) );//false
\D非数字字符(只要没有数字即可)
console.log ( /\D/.test ( "123abc" ) );//true
console.log ( /\D/.test ( "123" ) );//false
\s空白字符(只要有空白字符即可)
console.log ( /\s/.test ( "\nabc" ) );//true
console.log ( /\s/.test ( "abc" ) );//false
\S非空白字符(只要有非空白字符即可)
console.log ( /\S/.test ( "\nabc" ) );//true
console.log ( /\S/.test ( "abc" ) );//true
console.log ( /\S/.test ( "" ) );//false
console.log ( /\S/.test ( "\t\n" ) );//false
\w单词字符(只要有字母、数字、下划线即可)
console.log ( /\w/.test ( "abc123_中国" ) );//true
console.log ( /\w/.test ( "中国" ) );//false
\W非单词字符(只要有除字母、数字、下划线之外的任意字符即可)
console.log ( /\W/.test ( "abc123_中国" ) );//true
console.log ( /\W/.test ( "中国" ) );//true
console.log ( /\W/.test ( "abc123_" ) );//false
记忆技巧:
字母是小写,表示是肯定的规则。
字母是大写,表示是否定的规则。
5、边界
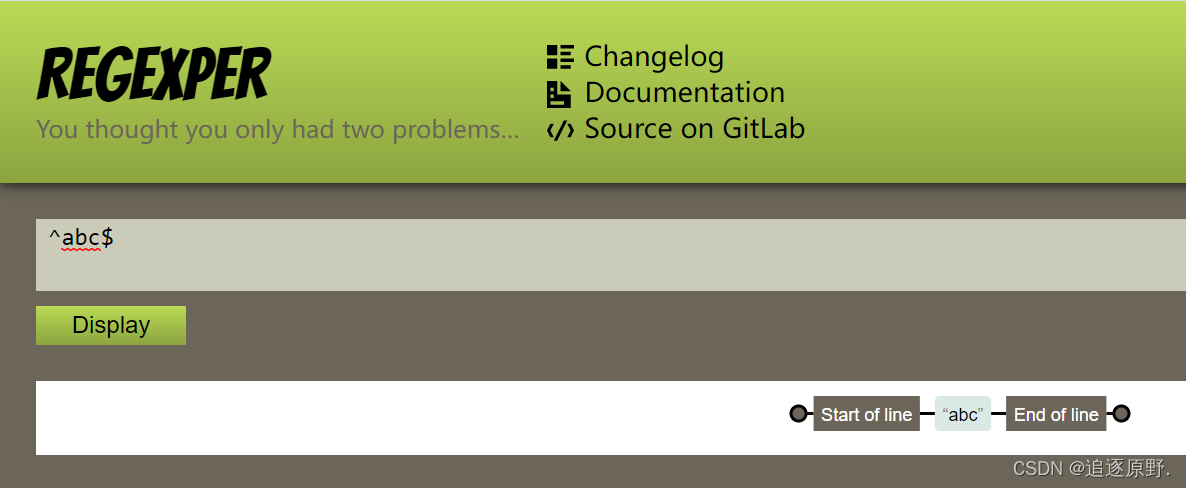
严格匹配: ^字符串$
例如: ^abc$ : 含义是,字符串必须以a开头,中间必须是b,结尾必须是c
满足该条件的只有一个字符串: abc
正则表达式还提供了几个常用的边界匹配字符:
^ 以xxxx开头
$ 以xxxx结束
\b 单词边界
\B 非单词边界
1、 ^ 以xxxx开头
这里容易记混的知识点:
[^] : 负向类,有取反的意思。 例如[^abc] : 不包含abc的任意字符
/^/:边界,以xxxx开头。 例如/^\d/ : 以数字开头的任意字符
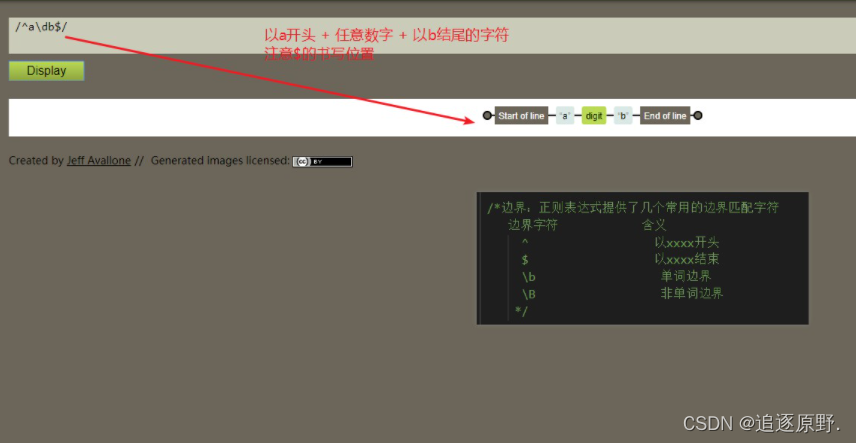
/^abc/ : 以a开头,后面是bc的字符
(不是以abc开头,虽然最终结果一样,但是含义不同)
console.log ( /^abc/.test ( "a" ) );//false
console.log ( /^abc/.test ( "abc" ) );//true
console.log ( /^abc/.test ( "abc123" ) );//true
/^\d/ : 以任意数字开头的任意字符
console.log ( /^\d/.test ( "1abc" ) );//true
console.log ( /^\d/.test ( "a1bc" ) );//false
2、 $ 以xxxx结束
/b$/ : 结尾是b的任意字符
console.log ( /b$/.test ( "b" ) );//true
console.log ( /b$/.test ( "abc" ) );//false
console.log ( /b$/.test ( "acb" ) );//true
/^ab$/ : 以a开头 + 以b结尾的字符 (言外之意:只能是ab)
console.log ( /^ab$/.test ( "ab" ) );//true
console.log ( /^ab$/.test ( "acb" ) );//false
3、 \b 单词边界(晦涩难懂,用的不多)
单词: 由\w(字母数组下划线)组成的一串字符
边界:指的是某一个位置,而不是字符
// 将单词is替换成XX
console.log ( "this is a girl".replace ( /\bis/, "XX" ) )// this XX a girl
// 将非单词is替换成XX
console.log ( "this is a girl".replace ( /\Bis/, "XX" ) )// thXX is a girl
6、量词
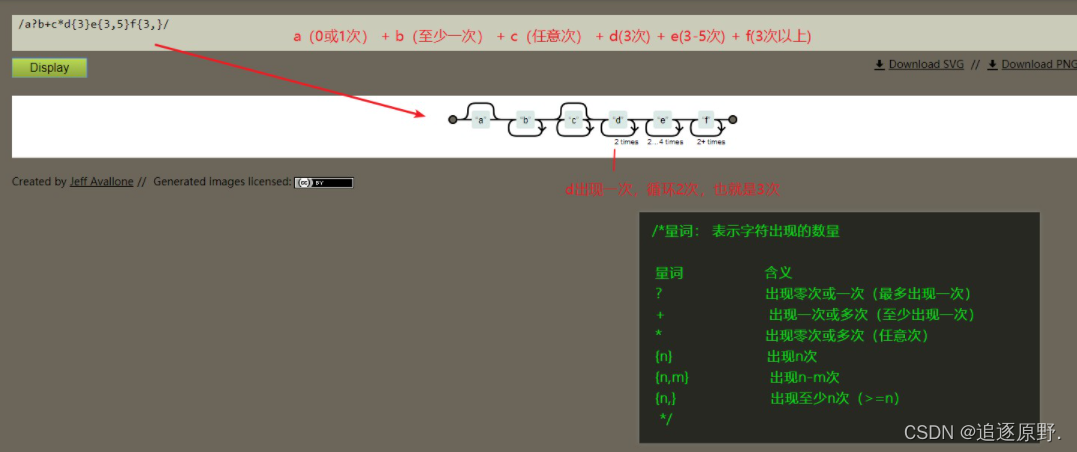
量词: 表示字符出现的数量
量词 含义
? 出现零次或一次(最多出现一次)
+ 出现一次或多次(至少出现一次)
* 出现零次或多次(任意次)
{n} 出现n次
{n,m} 出现n-m次
{n,} 出现至少n次(>=n)
需求:匹配一个连续出现10次数字的字符
正则表达式: /\d\d\d\d\d\d\d\d\d\d/
弊端:表达式冗余 解决方案:使用量词
console.log ( /\d{10}/.test ( "1234567abc" ) );//false
console.log ( /\d{10}/.test ( "1234567890abc" ) );//true
7、分组
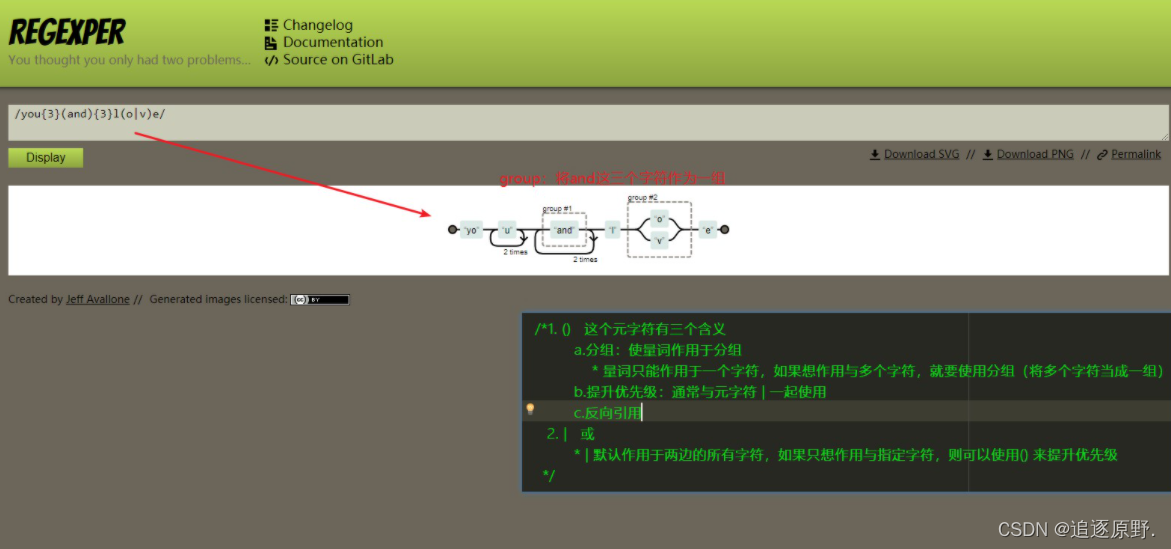
1、()
这个元字符有三个含义
- 分组:使量词作用于分组
- 量词只能作用于一个字符,如果想作用与多个字符,就要使用分组(将多个字符当成一组)
- 提升优先级:通常与元字符 | 一起使用
- 反向引用
// 需求: 匹配连续出现三次love的字符串 - lovelovelove
// 1.错误写法: /love{3}/ , 含义: lov + e{3}
console.log ( /love{3}/.test ( "lovelovelove" ) );//false
console.log ( /love{3}/.test ( "loveee" ) );//true
console.log ( /love{3}/.test ( "loveeeabc" ) );//true
//2.正确做法:使用分组 /(love){3}/
console.log ( /(love){3}/.test ( "lovelovelove" ) );//true
console.log ( /(love){3}/.test ( "loveee" ) );//false
2、|
// 1.错误写法: /lo|ive/ ,含义: lo 或者 ive
console.log ( "I love you".replace ( /lo|ive/, "X" ) );// I Xve you
console.log ( "I live you".replace ( /lo|ive/, "X" ) );// I lX you
//2.正确写法: /l(o|i)ve/, 含义:匹配love 或者 live
console.log ( "I love you".replace ( /l(o|i)ve/, "X" ) );// I X you
console.log ( "I live you".replace ( /l(o|i)ve/, "X" ) );// I X you
8、修饰符
修饰符:影响整个正则规则的特殊符号
书写位置: /pattern/modifiers(修饰符)
i (intensity):大小写不敏感(不区分大小写)
g (global) : 全局匹配
m(multiple) : 检测换行符,使用较少,主要影响字符串的开始^与结束$边界
1、i
i:不区分大小写
let str = 'ABCabcdefgaaaAAA';
console.log ( str.replace ( /a/, "X" ) );//ABCXbcdefgaaaAAA //默认区分大小写
console.log ( str.replace ( /a/i, "X" ) );//XBCabcdefgaaaAAA
2、g
g : 全局匹配
let str = 'ABCabcdefgaaaAAA';
console.log ( str.replace ( /a/, "X" ) );//ABCXbcdefgaaaAAA //默认匹配第一个就停止
console.log ( str.replace ( /a/g, "X" ) );//ABCXbcdefgXXXAAA //默认匹配第一个就停止
//修饰符可以同时使用多个
console.log ( str.replace ( /a/ig, "X" ) );//XBCXbcdefgXXXXXX
3、 m
m: 检测换行符 主要针对边界^与$
//需求:将下列字符串中每一行开头的字符变成0
let str = "aascdascd\nwebdfbdfbdfbfd\ngcsdfcwdfwfwe";
console.log ( str );//虽然在控制台看到三行字符串,实际上代码中每一行只是一个换行符\n
console.log ( str.replace ( /^\w/g, "0" ) );//错误 只能替换第一个字符
/*注意不要漏掉了全局匹配g*/
console.log ( str.replace ( /^\w/gm, "0" ) );//正确 能替换每一行第一个字符,m能检测换行符把\n后i面字符作为单独一行