安装
因为clickHouse很消耗cpu资源,所以需要修改:用户可打开的文件数量和最大进程数:
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
//第一列代表用户用户组,*代表所有,正常应该是“用户名@用户组”
//第二列soft代表软限制(正常生效状态),hard代表硬限制(最大)
//第三列 nofile代表文件数量,nproc代表进程数
另外还需要在limits.d/20-nproc.conf 中修改配置,防止覆盖上述的配置
vim /etc/security/limits.d/20-nproc.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
使用ulimit -a,可以查看配置是否生效
安装相应的依赖
yum install -y libtool
yum install -y *unixODBC*
Centos取消SELINUX(linux的一种安全机制,非常强大,但是也非常麻烦),是内核级别的东西,必须重启,也可以设置为临时生效,等下次服务器维护重启,配置自然也生效了
vim /etc/selinux/config
SELINUX=disabled
准备好安装包,官网:https://clickhouse.com/docs/en/install
21.7.3.14 链接:https://pan.baidu.com/s/1pCU41L4K2rUbQIZe6V8TjQ?pwd=qycr
提取码:qycr
全部安装
rpm -ivh *.rpm
默认用户是:default
密码:123456
确认是否都安装成功
rpm -qa |grep clickhouse
rpm安装文件的位置
配置文件默认位置
cd /etc/clickhouse-server/
默认lib文件
cd /var/lib/clickhouse/
默认bin文件
cd /usr/bin
默认log文件:
cd /var/log/clickhouse-server
数据文件:
cd /var/lib/clickhouse/
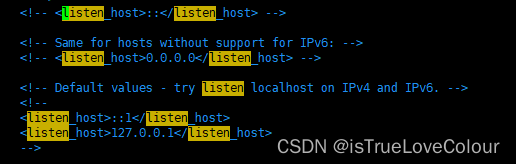
clickHouse默认只有本机可以访问,把下图第一行注释去掉,就代表不做限制
启动:下面两种启动方式都可以
systemctl status clickhouse-server.service
clickhouse status
重启
clickhouse restart
clickhouse-client --password
clickhouse默认就是开机自启的
单机版可以不用启动zk,但是集群是需要zk来调度的
副本
为了保证高可用,就需要做集群
在clickhouse集群中,没有主从一说,所有的节点都是主,相互之间互为副本,某一个节点的数据发生变化,就会提交写日志给zookeeper,其他节点就会从zookeeper监听到数据发生了变化,然后从数据发生变化的节点同步数据
接入zookeeper
可以在/etc/clickhouse-server/config.xml 中直接修改配置
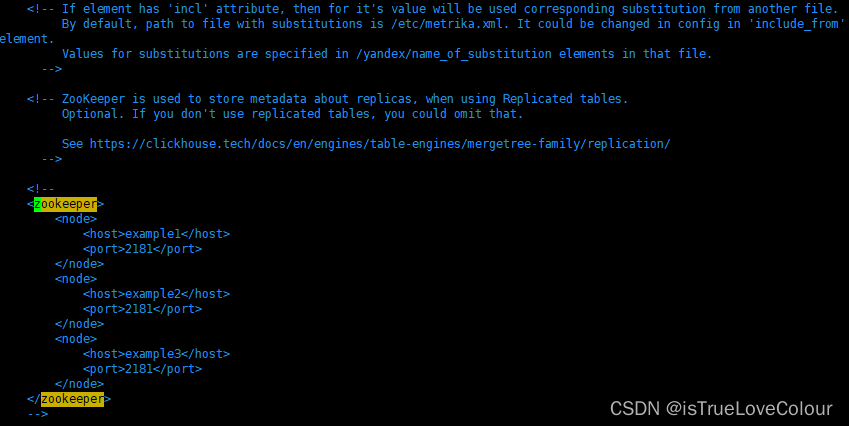
根据自己的zookeeper更改为:
vim /etc/clickhouse-server/config.xml
<zookeeper>
<node>
<host>192.168.158.158</host>
<port>2181</port>
</node>
<node>
<host>192.168.158.159</host>
<port>2181</port>
</node>
<node>
<host>192.168.158.160</host>
<port>2181</port>
</node>
</zookeeper>
给不同的clickhouse节点分别配置本机ip
vim /etc/clickhouse-server/config.xml
<interserver_http_host>192.168.158.155</interserver_http_host>
<interserver_http_host>192.168.158.156</interserver_http_host>
<interserver_http_host>192.168.158.157</interserver_http_host>
副本间的同步默认是9009端口,需要开放端口
<interserver_http_port>9009</interserver_http_port>
firewall-cmd --zone=public --add-port=9009/tcp --permanent
firewall-cmd --reload
副本只针对合并树家族
CREATE TABLE test (
name String,
age UInt8 TTL ctime+interval 10 SECOND,
ctime Date
) ENGINE = ReplicatedMergeTree('/clickhouse/table/01/test','test-01')
ORDER BY (name,ctime);
CREATE TABLE test (
name String,
age UInt8 TTL ctime+interval 10 SECOND,
ctime Date
) ENGINE = ReplicatedMergeTree('/clickhouse/table/01/test','test-02')
ORDER BY (name,ctime);
-- 两张表路径需要一样,名字必须不一样
-- ReplicatedMergeTree(路径,名称)
建表成功,给其中一张表插入数据,另一张会自动同步
分片集群
副本可以提高数据的可用性,降低了数据丢失的风险,但是服务器需要容纳全量的数据,如果数据量很大或者想要横向扩展,就需要分片了
Distributed分布式表,表引擎本身不存储数据,类似于中间件,通过分布式逻辑来写入、分发和路由来操作多台节点不同分片的分布式数据,是表级别的
内部同步
internal_replication(内部同步)
- 如果内部同步为true,客户端发出命令,向分布式表写入,分布式表通知分片写入,然后由分片自己向自己的副本同步
- 如果内部同步为false,客户端发出命令,向分布式表写入,分布式表通知分片和副本写入,这种情况有可能出现副本间的数据一致性的问题
客户端发出读请求,优先选择errors_count(错误数)小的副本,如果错误数相同,还有:随机、顺序或者host名称近似等方式
分片,下面是资源不够用的情况,只有3个节点,没有副本
vim /etc/clickhouse-server/config.xml
<colony_test> <!-- 集群名称-->
<!--第一个分片-->
<shard>
<!--# 内部同步-->
<internal_replication>true</internal_replication>
<!--一个副本-->
<replica>
</replica>
<!--一个副本-->
<replica>
</replica>
</shard>
<!--第二个分片-->
<shard>
</shard>
</colony_test>
在 <remote_servers>中编辑
#默认的通信端口
<tcp_port>9000</tcp_port>
<colony_test> <!-- 集群名称-->
<!--一个分片-->
<shard>
<!--# 内部同步-->
<internal_replication>true</internal_replication>
<!--一个副本-->
<replica>
<host>192.168.158.155</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<shard>
<!--# 内部同步-->
<internal_replication>true</internal_replication>
<!--一个副本-->
<replica>
<host>192.168.158.156</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<shard>
<!--# 内部同步-->
<internal_replication>true</internal_replication>
<!--一个副本-->
<replica>
<host>192.168.158.157</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
</colony_test>
<!--宏定义,各节点自定义的配置 -->
<macros>
<shard>01</shard>
<replica>clickhouse-1-3</replica>
</macros>
<macros>
<shard>02</shard>
<replica>clickhouse-2-3</replica>
</macros>
<macros>
<shard>03</shard>
<replica>clickhouse-3-1</replica>
</macros>
firewall-cmd --zone=public --add-port=9000/tcp --permanent
firewall-cmd --reload
建表语句
create table 表名 on cluster 集群名 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine
-- 这里的两个变量对应配置文件中的变量
=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
-- on cluster 会在指定的集群建立本地表
create table st_order_mt on cluster colony_test (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine
=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
先有本地表,再建立分布式表
create table st_order_mt_all2 on cluster colony_test
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(colony_test,default, st_order_mt,hiveHash(sku_id));
-- 参数含义:
-- Distributed(集群名称,库名,本地表名,分片键)
-- 分片键必须是整型数字,所以用 hiveHash(取hash值) 函数转换,也可以 rand()
然后向分布式表插入数据
insert into st_order_mt_all2 values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');
可以看到数据会根据分片的键,插入到了不同的本地表中
![[LeetCode周赛复盘] 第 92 场双周赛20221015](https://img-blog.csdnimg.cn/fe90b8cf343c48c7a75815560d3be358.png)