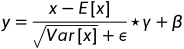Effective dual self-attentional residual networks for epileptic seizure prediction
摘要
癫痫发作预测作为慢性脑疾病中最具挑战性的数据分析任务之一,引起了众多研究者的广泛关注。癫痫发作预测,可以在许多方面大大提高患者的生活质量,如预防意外事故和减少癫痫发作期间可能发生的伤害。这项工作旨在通过探索从多通道脑电图信号中获得的特征的时频相关性,开发一种预测特定患者癫痫发作的通用方法。通过对脑电信号进行短时傅里叶变换(STFT),将原始脑电信号转换为表示时频特征的频谱图。本文首次提出了一种双自注意残差网络(RDANet),该网络将整合局部特征和全局特征的频谱注意模块与挖掘信道映射之间相互依赖关系的信道注意模块相结合,从而获得更好的预测性能。我们提出的方法对来自CHB-MIT公共头皮脑电图数据集的13例患者的敏感性为89.33%,特异性为93.02%,AUC为91.26%,准确性为92.07%。实验结果表明,不同的脑电信号预测段长度是影响脑电信号预测性能的重要因素。我们提出的方法是有竞争力的,并取得了良好的鲁棒性,没有病人特定的工程。
在本文中,我们通过开发基于深度学习的模型,提出了一种患者特异性癫痫发作预测方法,以提高癫痫发作预测的性能。该方法所采用的脑电图信号的时频特性对癫痫发作的预测非常重要。一些研究将卷积神经网络应用于癫痫发作的预测,并证实了卷积神经网络是一种有效的方法脑电图分类[11],[12]。然而,由于脑电图信号的复杂性和多样性,以及卷积神经网络结构简单,许多研究都获得了较低的癫痫预测性能。在本研究中,我们利用残差网络来提高癫痫发作的预测性能,并首次提出了双自我注意残差网络(dual self-attention residual network, RDANet)来预测癫痫发作。该RDANet通过频谱注意模块和信道注意模块,自适应地整合了脑电信号的局部特征和全局特征,增强了多通道脑电信号之间的相关性。此外,我们使用了省略一个交叉验证来评估预测结果,以确保它们是真实情况的代表。总体而言,与现有癫痫发作预测算法相比,数值实验证明了该算法的有效性。
2材料与方法
数据集
波士顿儿童医院收集的CHB-MIT头皮脑电图数据集包含22名儿童受试者连续844小时的头皮脑电图(sEEG)数据,并公开[25]和[26]。采用国际10-20系统的双极蒙太奇技术,以256hz的采样率从22个电极采集脑电图信号。Litt et al.[27]证明复杂的癫痫性放电在癫痫发作前7小时是常见的,而类似癫痫发作的活动在真正发作前2小时左右。与此同时,在癫痫发作前的50分钟内,积累的能量会增加。在本研究中,我们将痫前状态定义为癫痫发作开始前30分钟的脑电图信号,并将发作间期状态定义为癫痫发作结束后4小时至下一次发作开始前4小时之间的时间段。为了进行治疗干预,有必要在发作前留出一个短时间窗口。从临床角度来看,最好是有足够长的干预时间,让有效的治疗干预或预防措施[12]。在本研究中,将干预周期设置为5分钟,并从训练数据中删除。此外,考虑到癫痫发作可能发生得非常接近,我们对预测主要危机感兴趣,它距离下一次危机[29]大约不到30分钟。基于Truong et al.[12],我们只考虑每天发作少于10次的患者,因为对于平均每2小时发作一次的患者来说,执行这项任务并不是很关键。基于上述定义和限制,表I显示我们从该数据集中选择了13例64次癫痫发作和268.6小时间歇期数据的患者。
数据预处理

为了解决数据不平衡的问题,我们在训练阶段使用重叠采样来获得更多的预簇数据。如图3所示。具体来说,我们定义发作前信号的长度为M,发作间信号的长度为N,计算两类数据的长度之比K(公式1),设置采样窗口S为5秒。为了获得相同数量的两类数据,在训练阶段以S × K的移动步长收集癫痫发作前的数据,以S的移动步长收集发作间期的数据。对EEG信号进行分割,分别得到a和b的发作前和发作间期信号片段(见公式2和3)。
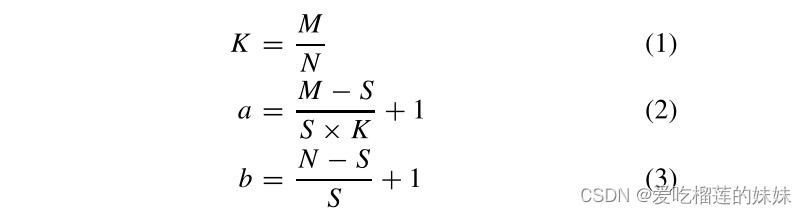
在脑电图数据分析中,时频域特征是非常重要的,通常采用二维图中表示三个参数的谱图进行研究。小波变换和短时傅里叶变换(STFT)是将脑电信号转换为[11]、[12]、[31]的常用方法。我们滑动5秒、15秒和30秒窗口,利用STFT将原始EEG信号转换为以时间和频率为轴的二维矩阵(如图3所示)。CHB-MIT数据集中大部分EEG记录受到60hz电力线噪声的污染,可以通过排除频率范围在57-63 Hz和117-123 Hz的部件来有效地去除。同时,直流分量(0 Hz)也被排除在外。5秒脑电图信号谱图和去噪谱图如图4所示。

c 模型
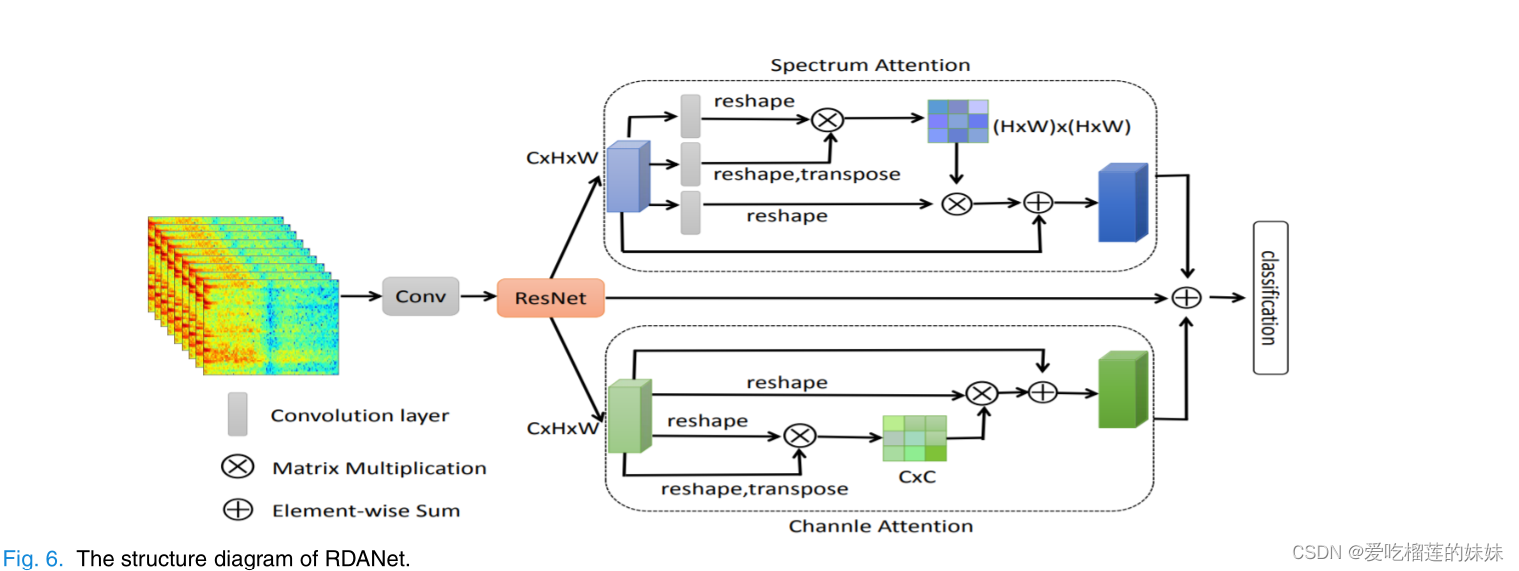
该模型由残差网络(ResNet)[32]和双自注意机制[33]组成。以图6上部的频谱注意模块为例,我们将频谱图作为网络的输入,通过ResNet提取潜在的时频特征。然后,通过以下三个步骤将特征输入到频谱注意模块中,生成新的全局光谱特征。第一步是生成一个频谱注意矩阵来描述任何频谱图之间的空间关系。其次,我们对注意矩阵和原始特征进行矩阵乘法。第三,我们通过在最后一步的结果矩阵和原始特征之间执行元素和来执行最终的全局光谱特征。信道注意模块的过程与频谱注意模块的过程相似。最后,我们将两个模块的特征合并,并将其添加到原始特征中,以更好地捕获EEG信号的特征。
1)残差网络:CNN[34]已广泛应用于计算机视觉、自然语言处理等领域。根据科学研究,为了获得表达能力,更好地拟合潜在映射关系,加深网络层数或拓宽网络结构是有效的。随着神经网络层数的加深,会出现梯度消失的问题,随机梯度下降的优化变得更加困难。最近,He et al.[35]提出了一种ResNet来解决训练非常深的卷积网络时的上述问题,该卷积网络由几个残差块组成。如图5所示,残差块通过快捷连接向网络添加了一个身份映射,既不增加额外的参数,也不增加计算量,在一定程度上解决了模型退化问题。每个残差块由两个3 × 3卷积层、批归一化和ReLu组成。此外,它有两条路径相加,即残差路径F(x)和身份映射x。在本研究中,我们使用了4个残差块,它们相互连接。

2)双重自我注意机制:
注意机制起源于人类的视觉知觉。人类在感知物体时,通常先扫描整体图像,然后将注意力集中在特定的部分,以获得更详细的信息,同时抑制其他无用的信息。随着注意机制研究的深入,谷歌机器翻译研究团队[36]提出的自注意机制因其能够学习到某一位置与其他位置之间的关系并捕捉语境依赖关系而受到广泛关注。Liu等[37]使用自注意生成对抗网络完成图像补全任务。Bello等[38]应用自注意机制提高图像分类精度。在癫痫发作预测研究中,我们首先提出了一种双重自我注意机制来捕捉脑电信号的全局信息。接下来,我们将详细说明这些过程。
a)频谱注意模块:

如图6所示,给定一个局部特征X∈RC×H×W,我们首先将其馈入卷积层,分别生成两个新的特征图Y和Z,其中Y和Z的维数都为RC×H×W。然后我们将它们重塑为RC×N,其中N = H×W。然后对Y和Z的转置进行矩阵相乘,通过softmax层[33]得到维数为的权值矩阵S:
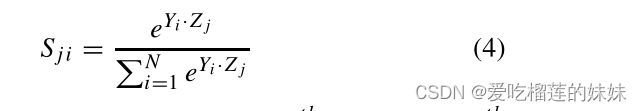
S代表了第i个位置对第j个位置的影响,两个位置的特征表示越相似,它们之间的相关性就越大。同时,将X馈送给卷积层,并将其重塑为RC×N,将生成一个新的特征T∈RC×H×W表示。然后我们执行T和S的矩阵乘法,然后将结果重塑为RC×H×W。最后,我们将其乘以一个缩放参数α,并与X进行逐元素求和运算,得到最终结果E∈RC×H×W[33](如公式5所示),

其中α初始化为0,逐渐分配更多的权重[39]。最终的特征E是频谱的加权特征与原始特征的和,具有全面的上下文视角,并可选地基于频谱注意图收集全局信息。
b)通道注意模块:
不同的通道特征代表不同的EEG信号语义。信道注意机制用于挖掘信道映射之间的相互依赖关系,使不同的语义表示之间相互关联。首先,我们将X重塑为RC×N,然后在X与X的转置之间应用矩阵乘法。最后,我们应用softmax层得到通道注意图P∈RC×C[33](如式6所示),其中Pji度量第i个通道对第j个通道的影响。

接下来,我们对P和X执行矩阵乘法,然后将结果重塑为RC×H×W。我们将结果乘以缩放参数β,并对X执行元素和运算,以获得最终输出E∈RC×H×W[33](如公式7所示),

其中β初始化为0。为了充分利用信道和频谱上下文信息,我们对这两个注意模块进行了逐元素和的整合。与原始特征融合后,通过平均池化得到最终的特征图。
3)训练:
为了得到与真实条件相似的结果于不同的情况,我们采用一种留一交叉验证的方法对每个病人[40]。也就是说,如果一个病人有n次癫痫发作和T小时的间歇录音,整个间歇录音被分为n个部分,每个部分大约有t /n小时数,与任何预诊记录随机分组。此循环进行n次,每次保留一个preictal -interictal对用于测试,而其余n - 1对用于训练阶段。一般情况下,有些研究通常随机抽取80%的数据作为训练集,剩余的20%作为验证集监测过拟合[13]。但是,该方法适用于时间上独立的数据,如图像分类。EEG数据是有时间依赖性的,所以我们应该选择与训练期不同时间段的样本来监测模型是否已经开始过拟合。在本研究中,我们从训练集中的产前和间歇期录音中选择25%的后期样本作为监测的验证集,其余75%的样本作为训练集[12]。虽然训练阶段的迭代次数增加了训练的准确性,但仍然存在过拟合的问题,我们使用了早期停止来解决这个问题。具体来说,当检测到验证集上的损失已经开始增加时,我们立即停止训练,并将网络参数存储在最低验证损失处。

RDANet网络参数如表二所示。模型输入为1×22×9×114, 22为脑电信号通道数,9×114为谱图维数。每个卷积层后面都有一个批归一化、一个dropout和一个ReLu激活函数。我们首先将上述特征图输入卷积层,然后进行重构,得到一个64 × 7 × 28的矩阵。随后,我们使用4个ResBlock层来提取EEG信号的深层特征。一个融合全局特征的双自注意层随后是一个具有sigmoid激活函数的全连接层。我们采用交叉熵损失函数作为代价函数。批大小为32。
辍学率设置为0.5,学习率设置为0.0005。我们的新模型是用Keras 2.2.2的tensorflow 1.4.0后端完成的。
III. RESULTS
在这项研究中,我们使用四个参数来评估所提出的模型的性能:敏感性、特异性、准确性和AUC,AUC是一个常用的指标,通过计算接受者操作特征曲线(ROC)下的面积来评估分类任务的性能。
以预测5s段为目的,CNN、ResNet和RDANet模型在CHB-MIT数据集的13个案例上的评估结果分别显示在表III、IV和V。实验执行了两次,报告了带有标准差的平均结果。总的来说,数值实验表明,模型的性能因病人而异。如表三所示,Pt2、Pt9和Pt14的结果低于其他病人。这是合理的,因为Pt 2只包括3次发作,而且可用于训练的发作前记录很少,这使得简单的CNN模型难以提取发作前数据的特征。Pt 9有46.7小时的发作间期记录,但只有4次发作,这导致了极不平衡的数据和糟糕的分类性能。同样,Pt14只有少量的间歇期记录,这使得CNN模型难以达到高分类性能。

表四显示了ResNet模型对同一数据集中13名患者的评估结果。与表三相比,Pt9和Pt14的预测结果有明显改善。Pt2的敏感性稍有下降,但特异性同时提高,导致AUC和准确率相应提高。看来ResNet模型通过快速连接和更深的网络结构可以缓解数据不平衡的问题是合理的。与CNN模型相比,也可以证明ResNet模型对其他患者的预测性能明显提高,除了Pt2。

表五显示了RDANet模型对CHB-MIT数据集中13个病人的评估结果。与CNN和ResNet模型相比,RDANet模型在许多患者身上的评价结果都有所提高,除了Pt9和Pt14。例如,Pt1、Pt13、Pt20和Pt23的灵敏度和AUC都接近100%。这表明,双自注意模块可以增强脑电数据的特征表示,从而提高预测性能。

然而,pt9的期前和期间数据显示出非常大的差距。虽然重新取样解决了数据不平衡的问题,但很容易对以前的样本进行过度拟合,导致特异性高于敏感性。pt14只有少量的间歇期记录,这使得RDANet模型难以达到高分类性能。
AUC是评价分类任务的综合参数,因此我们比较了三种模型测试不同患者的发作预测性能的ROC。在CHB-MIT数据集的13个病人的数据上评估CNN、ResNet和RDANet模型得到的ROC曲线见图7。可以看出,对于Pt1和Pt23,三个模型的ROC曲线几乎重叠,AUC值也几乎相同。
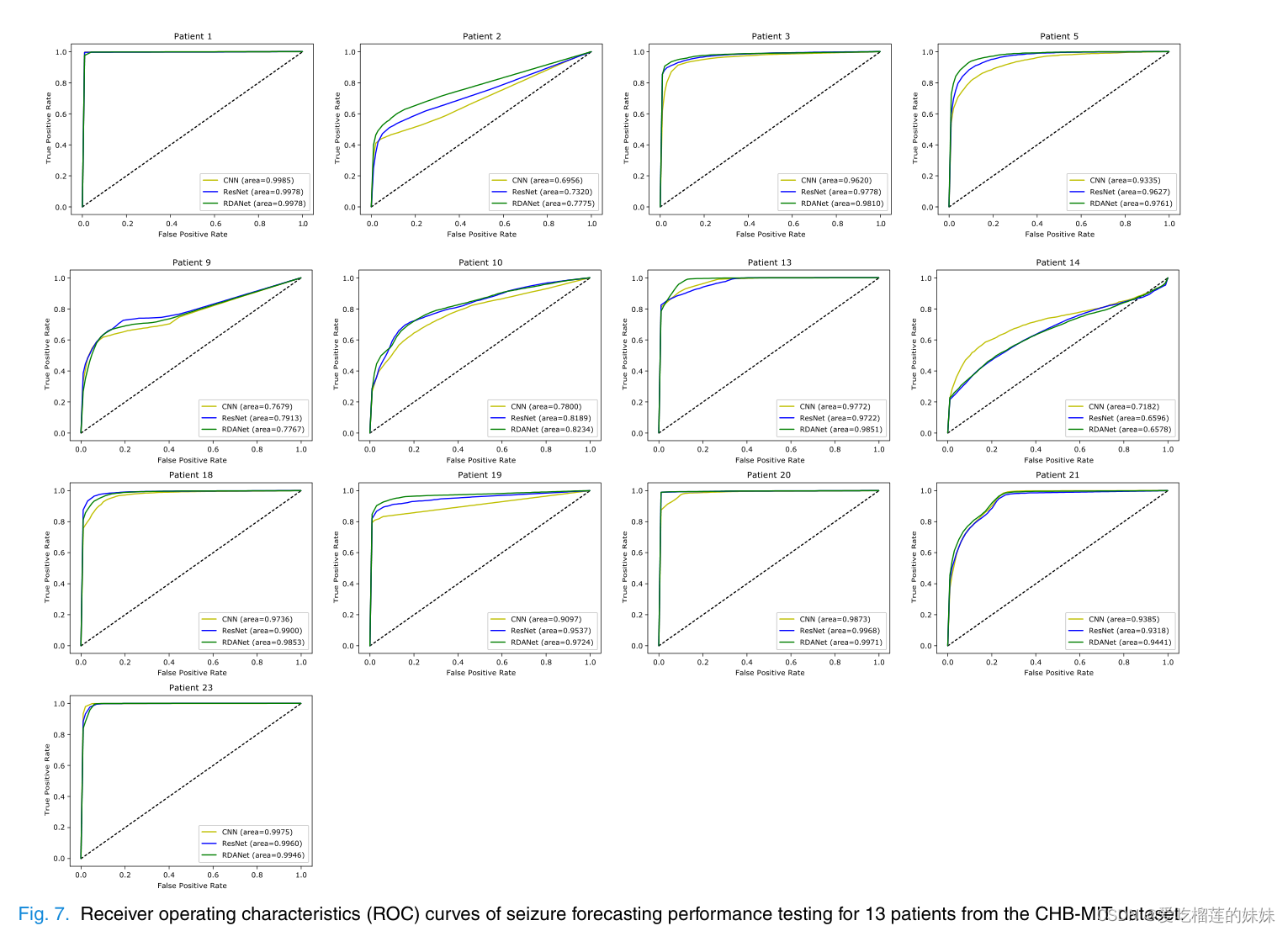
对于Pt1和Pt23,使用简单的CNN模型可以获得更好的结果,AUC接近100%。这表明,当原始模型具有良好的分类性能时,我们提出的模型并没有表现出很大的改进,因为改进的余地很小。从Pt9和Pt18的ROC曲线来看,可以得出ResNet模型的AUC值大于RDANet模型的AUC值,说明ResNet对这两个病人的分类性能比RDANet好。
根据Pt 14的ROC曲线,CNN模型的AUC值明显高于其他两个模型。原因是14号病人只有5个小时的发作间期记录,如果使用ResNet和RDANet模型预测癫痫发作,很容易造成过度拟合,降低性能。总的来说,虽然使用RDANet模型在一些患者身上取得的AUC值稍低,但我们提出的模型提高了整体预测性能。从这些数字可以清楚地看到,真阳性的比例高于假阳性的比例。很明显,对于大多数病人来说,RDANet模型的发作预测性能表现最好。这是因为我们提出的RDANet通过双重自我注意机制捕捉全局特征,并挖掘不同通道的脑电信号的相关性,促进了发作前时期和发作间期的分类性能。
为了检验我们的模型,CNN、ResNet和RDANet模型的整体癫痫发作预测性能可以用上述结果的加权平均值来表示(见图8)

。一般来说,RDANet模型的性能评价要高于CNN和ResNet模型。CNN模型由一个四层卷积神经网络和两个全连接层组成,用于对EEG信号进行分类。ResNet模型是一个只有四层ResBlock和一个平均池层的网络。与CNN模型相比,ResNet模型的预测结果要好于CNN。这是因为ResNet模型从建立更深的网络和快速连接方面具有更强的表达能力。通过比较ResNet和RDANet模型的实验结果,可以看出在引入双自注意模块[28]后,RDANet模型的灵敏度增加了0.17%,特异性增加了0.09%,AUC值增加了0.68%,准确率增加了0.37%。总的来说,RDANet模型在预测癫痫发作方面比其他两个模型有更多优势。
很少有研究考察EEG信号段长度对预测癫痫发作的影响。因此,我们探讨了脑电信号预测段的适当长度以达到最佳的预测性能。在这项研究中,我们对所有模型进行了重复训练,不同的发作预测长度为15秒和30秒。

图9是CNN、ResNet和RDANet模型在5秒、15秒和30秒的EEG信号预测段上的评估对比图。实验结果表明,虽然一些模型的灵敏度提高了,但特异性却相应降低了。通过比较AUC和准确率等综合指标,可以看出,当预测长度增加时,三个模型的预测性能普遍下降。
IV . 讨论
根据脑电图信号的时间和空间分辨率,人们开发了大量的统计技术来分析脑电图信号[41]。许多信号转换技术已被用于解释大脑信号和检测异常情况,如傅里叶变换、短时傅里叶变换和基于小波的变换[31], [42]。连续小波变换[11], [43]和经验小波变换[18]已被应用于癫痫发作的预测领域。基于傅里叶-贝塞尔级数扩展(FBSE)[44]-[46]的经验小波变换(EWT)[47](FBSE-EWT)可以有效地解决非平稳信号的问题,并被引入分析EEG信号,它使用由FBSE设计的经验小波进行信号[48], [49]。因此,我们在RDANet中比较了四种信号转换方法。
我们首先使用CWT、EWT和FBSE-EWT分别转换EEG信号(见图10),

然后用RDANet网络自动提取特征并进行分类。该模型的输入是1×22×9×1280,其中22代表EEG信号通道的数量和9×1280代表转换后的尺寸。为了提高计算效率,加快训练速度,我们对上述输入结果进行随机降样,得到1×22×9×160的新输入。实验结果如表六所示。
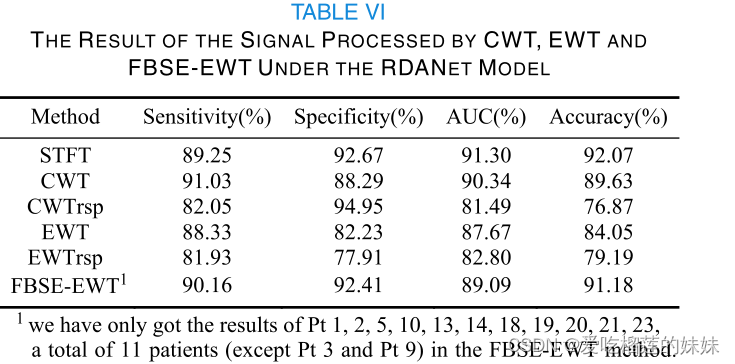
与STFT+RDANet相比,CWT+RDANet模型的灵敏度达到了91.03%,但其他三项指标相对较低,尤其是特异性。我们可以看到,STFT和CWT分别在发作间期和发作前期信号上表现良好。EWT+RDANetmodel的四项评价结果都很好。可能是时频域的信号特征更有利于区分脑电信号的不同状态。CWTrsp+RDANet和EWTrsp+RDANet表示下采样后的模型,其预测结果很差。原因可能是脑电信号中的一些重要信号由于下采样而丢失。
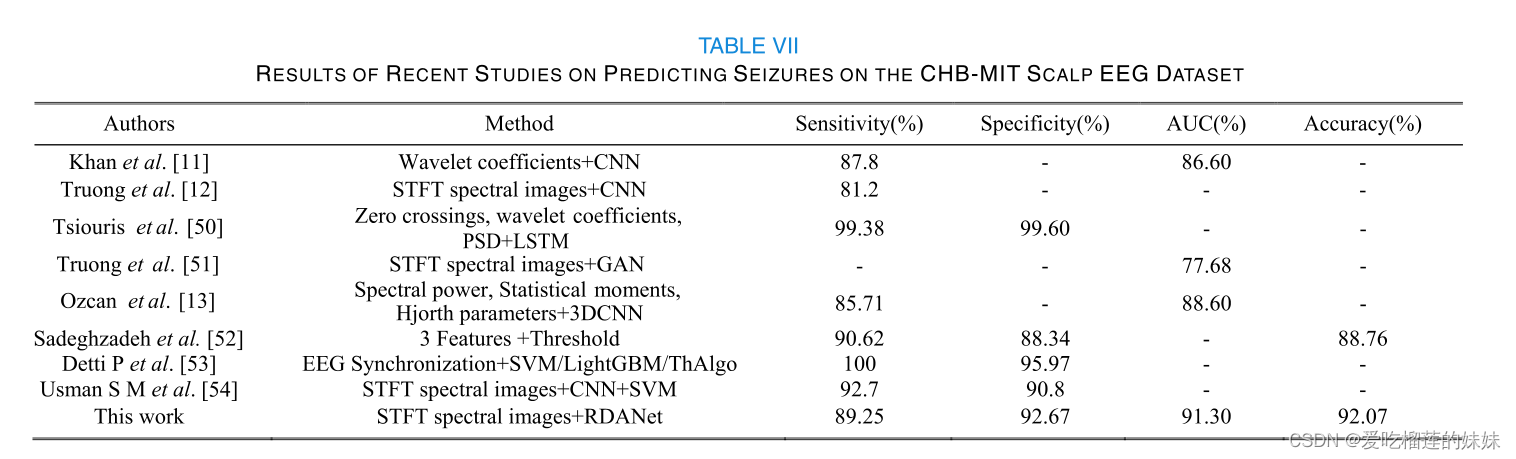
表七提供了我们的方法和其他方法的发作预测性能的比较。所有的方法都是在CHB-MIT头皮EEG数据集上评估的,这是一个由长期记录组成的公共数据集。很难决定哪种方法更好,因为每种方法都是根据不同的病人和不同的时间定义,用有限的数据进行测试。因此,所提出的方法的通用性,而不需要针对病人的特征工程,是一个重要的影响癫痫发作预测性能的指标。在一个类似的方法中,Khan等人[11]提出了一种使用原始EEG信号的小波变换作为卷积神经网络的输入的方法,并在15名患者身上评估了他们的方法。Truong等人[12]提出了一种结合短时傅里叶变换和卷积神经网络的方法,并在同一数据集的13名病人身上测试了他们的方法。很明显,我们提出的方法优于他们的方法。
为了揭示所提出的模型在与真实情况相似的条件下的发作预测性能,可以使用留一交叉验证法进行训练。Detti等人[53]提出了一种基于寻找EEG中同步模式的方法,使他们能够实时区分发作前和发作间状态,并比较了三种分类器。SVM、梯度提升决策树算法和基于阈值的ThAlgo方法。这些方法使用五倍交叉验证对CHB-MIT头皮EEG数据集进行了评估。由于他们没有使用留一交叉验证,他们使用ThAlgo算法正确预测了所有的癫痫发作,而LightGBM的预测率为98%,SVM的预测率为86.7%。Tsiouris等人[50]提出了一种将脑电信号的小波变换系数和功率谱密度与LSTM相结合来预测癫痫发作的方法,并获得了99.84%的高灵敏度和0.02/h的假阳性率。他们的方法也没有使用留一交叉验证。
Truong等人[51]使用生成对抗网络(GAN)来预测癫痫发作,获得了77.68%的AUC。由于他们的方法采用了半监督训练,训练数据量不足,导致监督训练的预测性能出现差距。Ozcan等人[13]提出了一个多帧3DCNN模型来预测癫痫发作。在使用相同数量的病人和相同的发作期的条件下,我们提出的RDANet获得了88.63%的敏感性,FPR为0.122/h,AUC值为89.91%,准确率为89.78%。我们的方法的灵敏度和AUC都高于Ozcan的方法。Hoda等人[52]提出了一种实时低计算量的癫痫发作预测方法。他们提取了早期发病信号的第三级特征,并将第三级信息与预定义的阈值水平进行比较,以确定提取的特征是否与癫痫有关。除灵敏度外,其他两项指标相对较低。
Usman等人[54]提出了一个简单的发作预测系统,使用卷积神经网络自动提取特征并进行SVM分类。他们的方法在CHB-MIT数据集上进行了评估,结果是平均灵敏度和特异性分别为92.7%和90.8%。
然而,他们没有描述数据是如何划分的,使用了什么验证方法,以及实验的细节并不十分清楚。
V. 结论
在这项工作中,我们提出了一个用于预测癫痫发作的双自注意残余网络(RDANet),它可以通过自注意机制将全局特征整合为局部特征。具体来说,频谱注意模块和通道注意模块分别捕捉到全局对频谱的依赖性和对通道的相互依赖性,从而提高了表达局部特征的能力。总的来说,我们提出的方法与其他最新的方法相比是有竞争力的,而且由于没有针对病人的工程,所以是可以推广的。然而,CHB-MIT数据集主要由儿科病人组成,我们的方法将在不同的临床条件下对更多不同年龄组的病人进行综合测试,以确认整体性能。