文章目录
- ①. LRU算法概述
- ②. 查看默认内存
- ③. 如何删除数据
- ④. 缓存淘汰策略
①. LRU算法概述
-
①. LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的数据给予淘汰 (leetcode-cn.com/problems/lru-cache)
-
②. LRU算法题来源
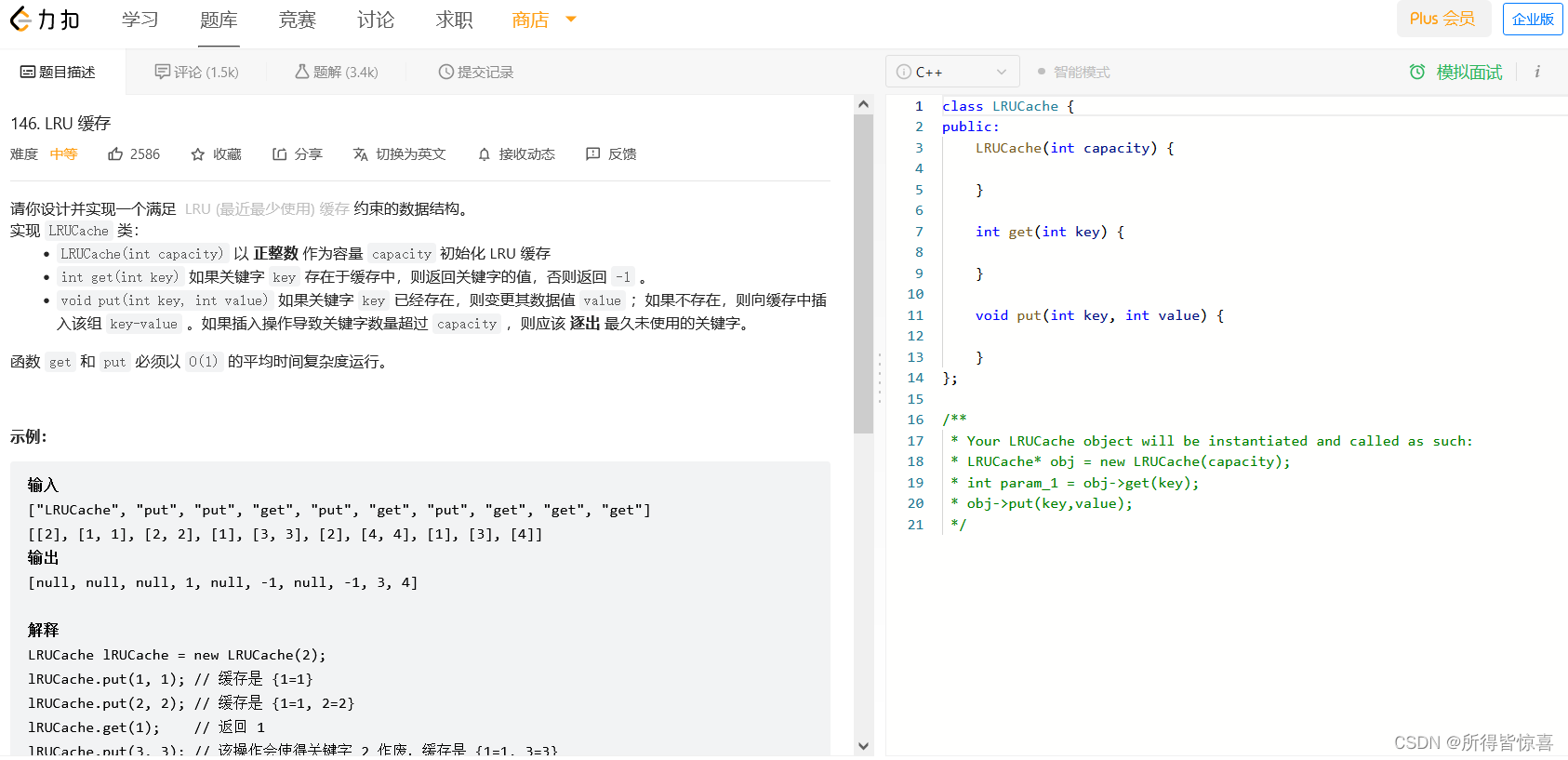
-
③. 设计思想
- 所谓缓存,必须要有读+写两个操作,按照命中率考虑,写操作+读操作时间复杂度都需要为O(1)
- 特征要求:
必须要有顺序之分,一区分最近使用的和很久没有使用的数据排序
写和读操作一次搞定
如果容量坑位满了要删除最不长用的数据,每次信访问还要把心得数据插入到对头
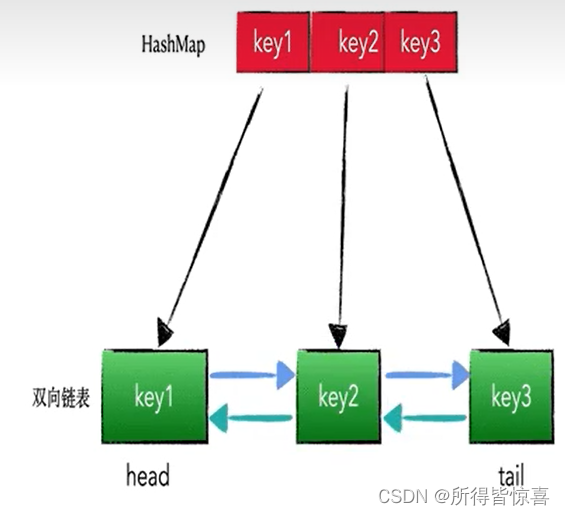
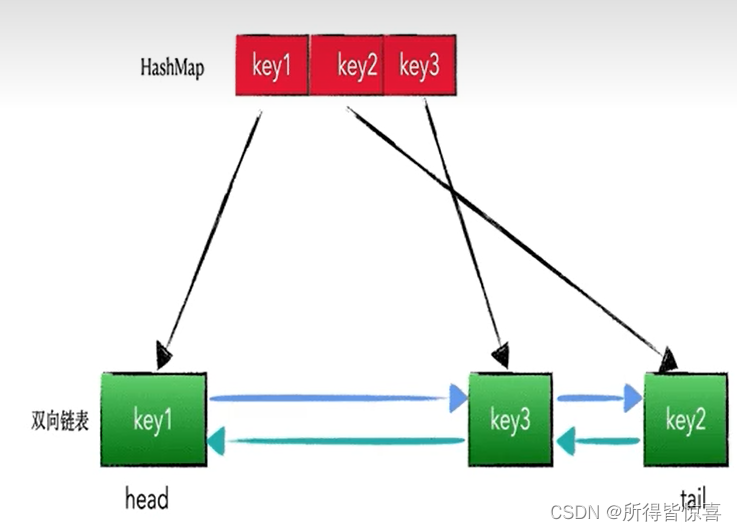
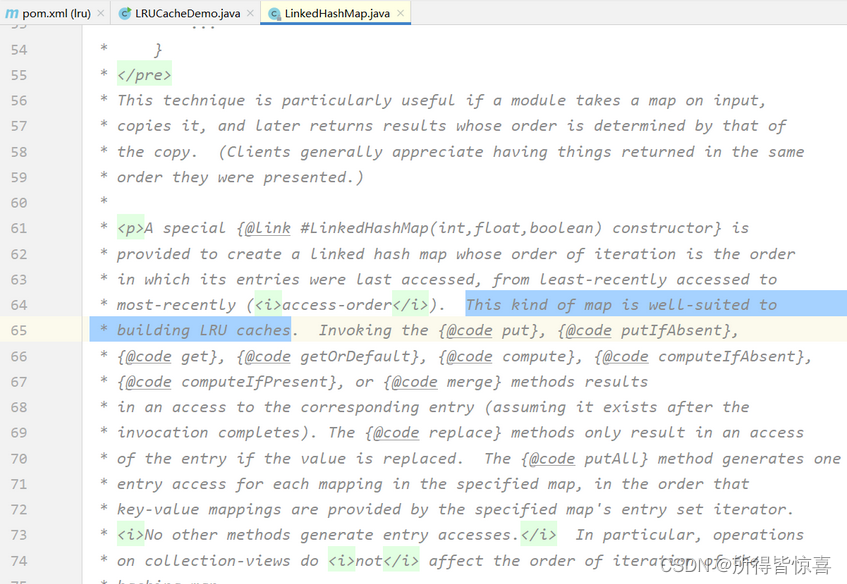
- ④. 使用LinkHashMap实现LRU算法,LinkedHashMap的注释中写明了: LinkedHashMap非常适合用来构建 LRU 缓存
public class LRUCacheDemo <k,V>extends LinkedHashMap<k,V> {
/**
* 缓存坑位
*/
private int capacity;
public LRUCacheDemo(int capacity) {
/**
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
*/
super(capacity,0.75F,true);
this.capacity=capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<k, V> eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LRUCacheDemo lruCacheDemo = new LRUCacheDemo(3);
lruCacheDemo.put(1,"a");
lruCacheDemo.put(2,"b");
lruCacheDemo.put(3,"c");
// [1,2,3]
System.out.println(lruCacheDemo.keySet());
// [2,3,4]
lruCacheDemo.put(4,"d");
System.out.println(lruCacheDemo.keySet());
// [2,4,3]
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
// [2,4,3]
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
// [4,3,5]
lruCacheDemo.put(5,"c");
System.out.println(lruCacheDemo.keySet());
}
}
- ⑤. 完全自己手写
public class LRUSelfCacheDemo {
// map 负责查找,构建一个虚拟的双向链表,它里面装的就是一个个 Node 节点,作为数据载体
// 1.构造一个node节点作为数据载体
class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}
// 2.构建一个虚拟的双向链表,,里面安放的就是我们的Node
class DoubleLinkedList<K, V> {
Node<K, V> head;
Node<K, V> tail;
public DoubleLinkedList() {
head = new Node<>();
tail = new Node<>();
head.next = tail;
tail.prev = head;
}
// 3.添加到头
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
// 4.删除节点
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
// 5.获得最后一个节点
public Node getLast() {
return tail.prev;
}
}
private int cacheSize;
Map<Integer, Node<Integer, Integer>> map;
DoubleLinkedList<Integer, Integer> doubleLinkedList;
public LRUSelfCacheDemo(int cacheSize) {
this.cacheSize = cacheSize;//坑位
map = new HashMap<>();//查找
doubleLinkedList = new DoubleLinkedList<>();
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
return node.value;
}
public void put(int key, int value) {
if (map.containsKey(key)) { //update
Node<Integer, Integer> node = map.get(key);
node.value = value;
map.put(key, node);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
} else {
if (map.size() == cacheSize) //坑位满了
{
Node<Integer, Integer> lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);
doubleLinkedList.removeNode(lastNode);
}
//新增一个
Node<Integer, Integer> newNode = new Node<>(key, value);
map.put(key, newNode);
doubleLinkedList.addHead(newNode);
}
}
public static void main(String[] args) {
LRUSelfCacheDemo lruCacheDemo = new LRUSelfCacheDemo(3);
lruCacheDemo.put(1, 1);
lruCacheDemo.put(2, 2);
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(4, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(5, 1);
System.out.println(lruCacheDemo.map.keySet());
}
}
②. 查看默认内存
-
①. 查看Redis最大占用内存:打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型,注意转换

-
②. redis默认内存多少可以用?
如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB -
③. 一般生产上你如何配置?
一般推荐Redis设置内存为最大物理内存的四分之三(和hashMap默认的负载因子0.75一致) -
④. 通过修改文件配置[1]

-
⑤. 通过命令修改[2]

-
⑥. 什么命令查看redis内存使用情况?
info memory
- ⑦. 如果Redis内存使用超出了设置的最大值会怎样?

③. 如何删除数据
- ①. 立即删除
- Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除
- 立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死
- 这会产生大量的性能消耗,同时也会影响数据的读取操作
- 总结:对CPU不友好,用处理器性能换取存储空间 (拿时间换空间)
- ②. 惰性删除
- 数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据,如果未过期,返回数据
- 惰性删除策略的缺点是,它对内存是最不友好的
- 在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏–无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息
- 总结:对memory不友好,用存储空间换取处理器性能(拿空间换时间)
- ③. 定期删除
- 定期删除策略是前两种策略的折中
- 定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响
- 定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成立即删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率

- ④. 总结下对于惰性删除和定期删除时
- 定期删除时,从来没有被抽查到
- 惰性删除时,也从来没有被点中使用过
- 引入redis缓存淘汰策略登场
④. 缓存淘汰策略
- ①. 有哪些(redis6.0.8版本) - 这个是要背下来的各位网友
- noeviction: 不会驱逐任何key,农村满了就报错
- allkeys-lru: 对所有key使用LRU算法进行删除
- volatile-lru: 对所有设置了过期时间的key使用LRU算法进行删除
- allkeys-random: 对所有key随机删除
- volatile-random: 对所有设置了过期时间的key随机删除
- volatile-ttl: 删除马上要过期的key
- allkeys-lfu: 对所有key使用LFU算法进行删除
- volatile-lfu: 对所有设置了过期时间的key使用LFU算法进行删除
- ②. 总结上面8种模式:2 * 4 得8、2个维度(过期键中筛选、所有键中筛选)、4个方面(LRU、LFU、random、ttl)、8个选项
- LRU:最近最少使用(最长时间)淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的页面
- LFU:最不经常使用(最少次)淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的页面
- ③. 工作中使用的是哪种:maxmemory-policy allkey-lru









![Yocto系列讲解[技巧篇]90 - toolchain交叉编译器SDK中安装的软件](https://img-blog.csdnimg.cn/f64e1f114d7045eaa57a680daec4395b.png)