总结一下
- dynamodb通常和java等后端sdk结合使用
- 使用的形式可以是api或partiql语法调用
- dynamodb的用法不难,更重要的是维护成本,所需的服务集成,技术选型等
- 和大数据结合场景下有独特优势
之后可能再看看java sdk中DynamoDBMapper的写法,以及对标产品documentdb的比较
创建dynamodb表
创建表
https://docs.aws.amazon.com/cli/latest/reference/dynamodb/create-table.html
- 主键可包含一个属性(分区键)或两个属性(分区键和排序键)。需要提供每个属性的属性名称、数据类型和角色:
HASH(针对分区键) 和RANGE(针对排序键) - 使用预置模式,则必须指定表的初始读取和写入吞吐量设置
/// 预配置表
aws dynamodb create-table \
--table-name Music \
--attribute-definitions \
AttributeName=Artist,AttributeType=S \
AttributeName=SongTitle,AttributeType=S \
--key-schema \
AttributeName=Artist,KeyType=HASH \
AttributeName=SongTitle,KeyType=RANGE \
--provisioned-throughput \
ReadCapacityUnits=5,WriteCapacityUnits=5 \
--table-class STANDARD
# --table-class STANDARD_INFREQUENT_ACCESS
// 按需表
aws dynamodb create-table \
--table-name Music \
--attribute-definitions \
AttributeName=Artist,AttributeType=S \
AttributeName=SongTitle,AttributeType=S \
--key-schema \
AttributeName=Artist,KeyType=HASH \
AttributeName=SongTitle,KeyType=RANGE \
--billing-mode=PAY_PER_REQUEST
控制台创建默认表的配置如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hGso1Yks-1678515745623)(assets/image-20230311111037435.png)]](https://img-blog.csdnimg.cn/6f6499e69bad4b50b0979a0f93865dc1.png)
查看表
- 对按需表调用
DescribeTable时,读取容量单位和写入容量单位设置为 0
aws dynamodb describe-table --table-name Music
此时的最佳实践是开启Point-in-time recovery(dynamodb的自动备份),避免意外的写入和删除
-
可以按需恢复到最近35天(无法修改,禁用在开启需要从0开始计算天数)中的任意时间点。
-
备份方式为增量备份
-
开启时间点恢复不影响api的性能
-
支持跨region还原表
-
删除开启时间点还原的表,会自动创建一个备份快照(保留 35 天)
aws dynamodb update-continuous-backups \
--table-name Music \
--point-in-time-recovery-specification \
PointInTimeRecoveryEnabled=true
写入item
插入item有两种视图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iiqkYI07-1678515745625)(assets/image-20230311112037750.png)]](https://img-blog.csdnimg.cn/405e217a2c77469a8d6c3e29374f63b3.png)
dynamodb api插入item
https://docs.aws.amazon.com/cli/latest/reference/dynamodb/put-item.html#examples
cat > item.json << EOF
{
"Artist": {"S": "No One You Know"},
"SongTitle": {"S": "Howdy"},
"AlbumTitle": {"S": "Somewhat Famous"},
"Awards": {"N": "0"}
}
EOF
aws dynamodb put-item \
--table-name MusicCollection \
--item file://item.json \
--return-consumed-capacity TOTAL \
--return-item-collection-metrics SIZE
// output
{
"ConsumedCapacity": {
"TableName": "Music",
"CapacityUnits": 1.0
}
}
PartiQL插入item
aws dynamodb execute-statement --statement "INSERT INTO Music \
VALUE {'Artist':'Oh My Hony','SongTitle':'Call Me Today', 'AlbumTitle':'Somewhat Famous', 'Awards':'1'}"
读取item
dynamodb api读取item
https://docs.aws.amazon.com/cli/latest/reference/dynamodb/get-item.html
--consistent-read|--no-consistent-read(boolean)Determines the read consistency model: If set to
true, then the operation uses strongly consistent reads; otherwise, the operation uses eventually consistent reads.
aws dynamodb get-item \
--consistent-read \
--table-name Music \
--key '{ "Artist": {"S": "Acme Band"}, "SongTitle": {"S": "Happy Day"}}'
PartiQL读取item
aws dynamodb execute-statement --statement "SELECT * FROM Music \
WHERE Artist='Acme Band' AND SongTitle='Happy Day'"
更新item
dynamodb api更新item,逻辑上先查询再修改
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/dynamodb/update-item.html
aws dynamodb update-item \
--table-name Music \
--key '{ "Artist": {"S": "Acme Band"}, "SongTitle": {"S": "Happy Day"}}' \
--update-expression "SET AlbumTitle = :newval" \
--expression-attribute-values '{":newval":{"S":"Updated Album Title1"}}' \
--return-values ALL_NEW
PartiQL更新item
aws dynamodb execute-statement --statement "UPDATE Music \
SET AlbumTitle='Updated Album Title' \
WHERE Artist='Acme Band' AND SongTitle='Happy Day' \
RETURNING ALL NEW *"
查询item
dynamodb api查询item
aws dynamodb query \
--table-name Music \
--key-condition-expression "Artist = :name" \
--expression-attribute-values '{":name":{"S":"Acme Band"}}'
这里必须指定key表达式,否则会报错
An error occurred (ValidationException) when calling the Query operation: ExpressionAttributeValues can only be specified when using expressions: FilterExpression and KeyConditionExpression are null
PartiQL查询item
aws dynamodb execute-statement --statement "SELECT * FROM Music \
WHERE Artist='Acme Band'"
更新dynamodb表
支持的操作有
- 修改表的预置吞吐量设置
- 更改表的读/写容量模式。
- 在表上操作全局二级索引
- 在表上启用或禁用 DynamoDB Streams
修改读写模式
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/switching.capacitymode.html
| 类型 | 位置 | 模式转换 |
|---|---|---|
| 按需模式 => 预置模式 | ||
| 读写模式 | 控制台 | 根据表和全局二级索引在过去 30 分钟内占用的读写容量估计初始预配置容量值 |
| 读写模式 | CLI 或 SDK | 用户通过cw查看历史使用情况(ConsumedWriteCapacityUnits 和 ConsumedReadCapacityUnits 指标)以确定新的吞吐量设置 |
| 按需模式 <= 预置模式 | ||
| 读写模式 | 任意 | 无需指定预期应用程序执行的读取和写入吞吐量 |
| 预置模式 => 按需模式 | ||
| 自动扩缩 | CLI 或 SDK | 可能会保留自动扩缩设置 |
| 自动扩缩 | 控制台 | 会删除自动扩缩设置 |
| 按需模式 <= 预置模式 | ||
| 自动扩缩 | CLI 或 SDK | 保留先前的 Auto Scaling 设置 |
| 自动扩缩 | 控制台 | 建议设置,目标利用率:70%,最小预置容量:5 个单位,最大预置容量:区域最大值 |
-
从按需模式更新为预置模式
- 控制台修改,根据表和全局二级索引在过去 30 分钟内占用的读写容量估计初始预配置容量值
- CLI 或 SDK,用户通过cw查看历史使用情况(
ConsumedWriteCapacityUnits和ConsumedReadCapacityUnits指标)以确定新的吞吐量设置
-
从预置模式更新为按需模式
- 无需指定预期应用程序执行的读取和写入吞吐量
关于自动扩缩
-
从预置模式更新为按需模式
-
控制台会删除自动扩缩设置
-
cli则可能会保留自动扩缩设置
-
-
从按需模式更新为预置模式
- 控制台建议设置,目标利用率:70%,最小预置容量:5 个单位,最大预置容量:区域最大值
- cli保留先前的 Auto Scaling 设置
创建全局二级索引
创建全局二级索引是更新表操作的一种
dynamodb api创建索引
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/dynamodb/update-table.html#examples
If you are adding a new global secondary index to the table,
AttributeDefinitionsmust include the key element(s) of the new index.
cat > gsi-updates.json << EOF
[
{
"Create": {
"IndexName": "AlbumTitle-index",
"KeySchema": [
{
"AttributeName": "AlbumTitle",
"KeyType": "HASH"
}
],
"ProvisionedThroughput": {
"ReadCapacityUnits": 10,
"WriteCapacityUnits": 5
},
"Projection": {
"ProjectionType": "ALL"
}
}
}
]
EOF
aws dynamodb update-table \
--table-name Music \
--attribute-definitions AttributeName=AlbumTitle,AttributeType=S \
--global-secondary-index-updates file://gsi-updates.json
控制台查看
aws dynamodb describe-table --table-name Music | grep IndexStatus
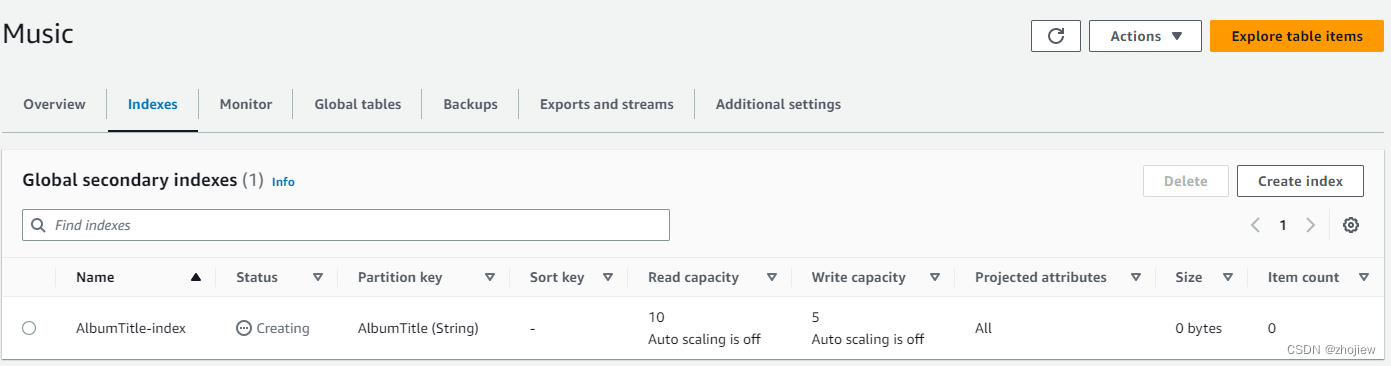
查询全局二级索引
dynamodb api查询GSI
aws dynamodb query \
--table-name Music \
--index-name AlbumTitle-index \
--key-condition-expression "AlbumTitle = :name" \
--expression-attribute-values '{":name":{"S":"Somewhat Famous"}}'
PartiQL查询GSI
aws dynamodb execute-statement --statement "SELECT * FROM ‘Music’.‘AlbumTitle-index’ \
WHERE AlbumTitle='Somewhat Famous'"
删除表
aws dynamodb delete-table --table-name Music
查看吞吐量配额
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/ServiceQuotas.html#default-limits-throughput
- 预置吞吐量配额是表容量加上其所有全局二级索引容量的总和
$ aws dynamodb describe-limits
{
"AccountMaxReadCapacityUnits": 80000,
"AccountMaxWriteCapacityUnits": 80000,
"TableMaxReadCapacityUnits": 40000,
"TableMaxWriteCapacityUnits": 40000
}
相关问题
节流问题
https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/ProvisionedThroughput.html#ProvisionedThroughput.Troubleshooting
-
DynamoDB 仅向 CloudWatch 报告分钟级指标,然后将这些指标计算为一分钟的总和并取平均值。但是 DynamoDB 本身会应用每秒的速率限制。可能由于微突增产生限流
-
当 2 个数据点在 1 分钟内超过所配置的目标利用率值时,可以触发自动扩缩,如果峰值间隔超过 1 分钟,则可能无法触发自动扩缩。在触发自动扩缩之后,都会调用
UpdateTable API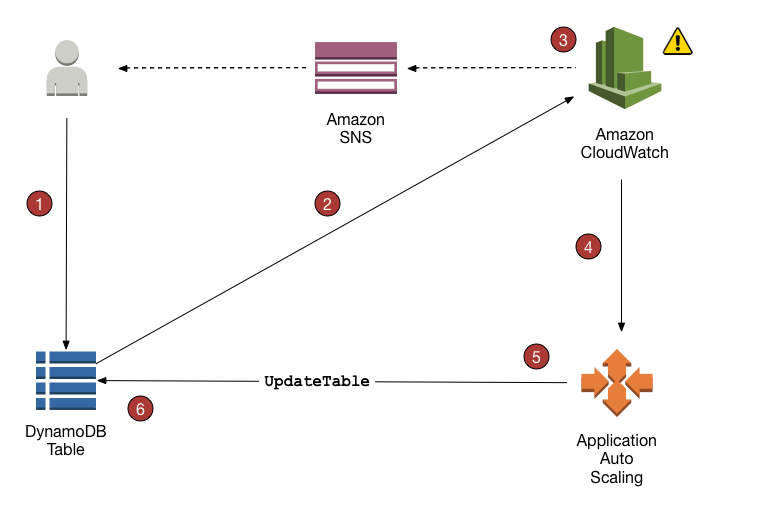
-
对于按需表,如果吞吐量在 30 分钟内超出先前峰值的两倍,则可能发生节流
-
生成的“热分区”超过了每分区每秒 3000 RCU 或 1000 WCU 的限制,这可能会导致节流

![Yocto系列讲解[技巧篇]90 - toolchain交叉编译器SDK中安装的软件](https://img-blog.csdnimg.cn/f64e1f114d7045eaa57a680daec4395b.png)