目录
一、GC的作用
申请变量的时机&销毁变量的时机
内存泄漏
垃圾回收的劣势
二、GC的工作过程
回收垃圾的过程
第一阶段:找垃圾/判定垃圾
方案1:基于引用计数(非Java语言)
引用计数方式的缺陷
方案2:可达性分析(基于Java语言)
GCRoots是哪些变量(3类)
第二阶段:回收垃圾(释放内存)
策略1:标记-清除策略
策略1存在问题分析:(内存碎片)
策略2:复制算法
复制算法存在问题分析:
策略3:标记——整理
分代回收
三、垃圾收集器有哪些
第一类:Serial收集器&Serial Old收集器(串行收集)
第二类:ParNew收集器&Parallel Old收集器&Parallel Scavenge收集器(并发收集)
第三类:CMS收集器
步骤1:找到GCRoots(会引发STW)
步骤2:并发标记
步骤3:重新标记(会引发STW)
步骤4:回收内存
第四类:G1收集器
一、GC的作用
GC:全称是Garbage Clean(垃圾回收)。我们平时写代码的时候,经常会申请内存。例如:
创建变量、new对象、加载类...
但是,由于内存空间是有限的,因此就需要"有借有还"。
如下代码,就是申请了两个变量:一个a,另外一个是object
int a=3;
Object obj=new Object()申请变量的时机&销毁变量的时机
申请一个变量(申请内存的时机)是确定的。就是new或者int a=...这种。但是,这个变量什么时候不需要使用了,那这个时期就不确定了。
例如:内存释放得偏早:如果还想要使用obj对象,但是如果这一个对象被回收了,那这样就显得不合理了。
又或者:内存的释放比较偏迟,对象一直占着"坑位"。
对于内存什么时候被释放这个问题, 不同的语言有不同的处理方式。
对于C语言:程序没有提供垃圾回收机制。因此当内存需要释放的时候,必须由程序员手动进行释放(调用free函数),因此,就会引入一个臭名昭著的问题,那就是"内存泄漏"。
内存泄漏
如果申请的内存越来越多,那么就意味着可用的内存越来越少,最终无内存可用了。这种现象就叫做"内存泄漏"。
虽然垃圾回收可以让开发的程序员专注于设计业务上面的代码,无需关心内存泄露的问题,但是仍然有一定的劣势。
垃圾回收的劣势
1、引入了额外的开销(消耗资源更多了)
2、可能会影响程序的流畅运行:垃圾回收经常会出现:STW(stop the work)问题。
二、GC的工作过程
回收的是什么样的对象
在上一篇文章当中,我们提到了:JVM的内存区域划分主要分为4个部分:
程序计数器、栈、堆、方法区。
对于栈区,只要方法返回之后,就会自动从栈上面消失了,不需要GC。
对于堆区,就很需要GC了,因为堆区当中存放的大量都是new出来的对象。
我们来画一张图,描述一下根据内存使用与否的图:

因此,需要回收的对象,都是一些没有使用,但是同时也占用着内存的对象。
回收垃圾的过程
垃圾回收的过程,分为两大阶段:
第一阶段:找垃圾/判定垃圾
方案1:基于引用计数(非Java语言)
针对每一个对象,都引入一小块的内存,保存这一个对象有多少个引用指向它。
例如:(此时有两个引用都指向new Test()对象)
//t1引用指向new Test()对象
Test t1=new Test();
//t2引用指向new Test()对象
Test t2=t1;那么,此时在new Test()当中,就会有一个引用计数器,显示指向这个对象的引用个数为2。
那么,当引用计数为0的时候,也就意味着此时没有引用指向这个对象了,需要GC对于这一个对象进行回收操作。
什么时候引用计数为0呢?下面举一个例子:
private static void func2() {
//让t1指向new Test1()对象
Test1 t1=new Test1();
//让t2指向new Test1()对象
Test1 t2=t1;
} 在一个方法当中,两个引用(t1,t2)同时指向了new Test1()对象。 当调用func2()方法的时候,t1和t2引用会保存在func2()方法的栈帧上面。两个引用同时指向了堆上面的new Test1()对象。 
当func2()调用结束之后,会从栈帧上面消失,那么t1和t2引用也会随之消失。
那么,也就意味着:new Test2()这一个对象没有引用指向它了,认为它是一个"垃圾",也就会被回收。
引用计数方式的缺陷
缺点1:空间利用率比较低
每一个new的对象都必须要搭配一个计数器来记录几个引用。引用计数器的大小为4个字节,但是如果一个对象除了引用计数器以外的部分本身也就只有4个字节大小,那么就意味着比较浪费空间。

缺点2:会有循环引用的问题
下面,来举一个例子说明一下什么是循环引用问题:
首先:创建一个Test类,在内部有一个属性,就是Test t=null;
然后:在测试类当中,创建这一个类的实例对象:
class Test {
Test t = null;
}
/**
* @author 25043
*/
public class Test2 {
public static void main(String[] args) {
Test t1 = new Test();
Test t2 = new Test();
}
}到这一步的时候,来画一个引用——对象的指向图:
 然后,接下来:执行下面的代码:
然后,接下来:执行下面的代码:
public static void main(String[] args) {
//对象1
Test t1 = new Test();
//对象2
Test t2 = new Test();
t1.t = t2;
t2.t = t1;
}到了这一步,再画一下引用指向的图:(把t2引用指向的对象赋给了对象1的t属性、把t1引用指向的对象赋给了对象2的t属性)
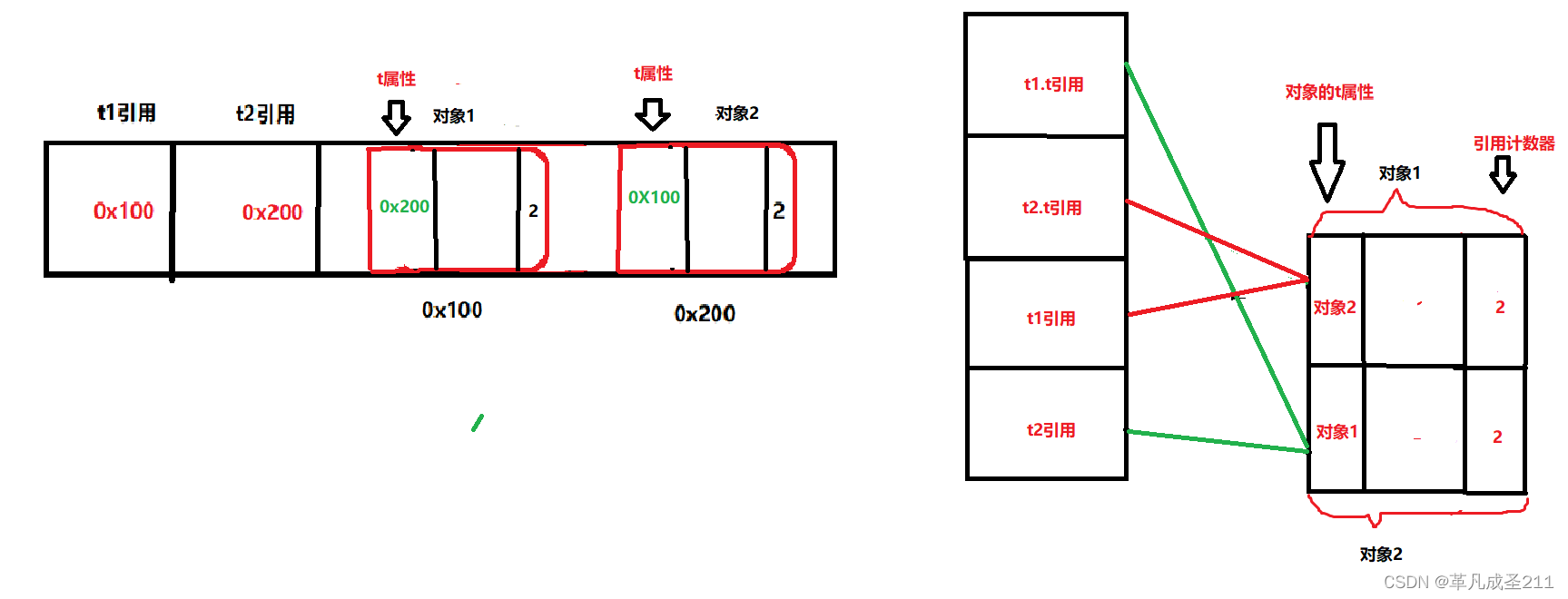
到这一步的时候:
对象1有两个引用指向(t1、t2.t);
对象2有两个引用指向(t2、t1.t)。
接下来:令:t1=null,t2=null。
public static void main(String[] args) {
//对象1
Test t1 = new Test();
//对象2
Test t2 = new Test();
t1.t = t2;
t2.t = t1;
t1 = null;
t2 = null;
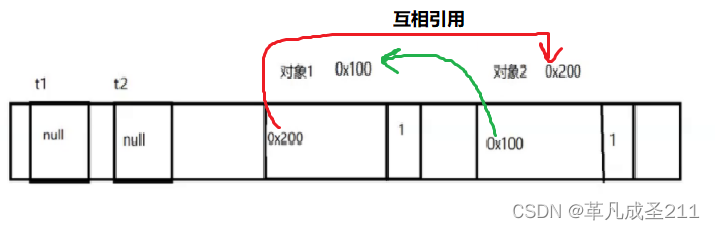
}那么此时可以认为:
t1的指向为null,并且t2的指向为null。
那么对应的指向对象1的引用减少了一个,只剩下(t2.t)
同时,指向对象2的引用也减少了一个,只剩下(t1.t)
两个对象的引用计数器各自减少为1。
由于引用计数不为0,也就是两个对象互相引用。那么,这两个对象无法被回收。但是,外部的引用又无法访问这两个对象。因此,这两个对象就永远无法被回收,也永远无法被使用。这样,也就出现了内存泄漏。
由于上述的两个缺点,因此引入了方案2(基于Java语言的解决方案:基于可达性分析)
方案2:可达性分析(基于Java语言)
通过一个额外的线程,定期地针对整个内存空间的对象进行扫描。
有一些起始的位置(称为GCroots),然后类似于深度优先搜索的方式,把可以访问到的对象都标记一遍。那么,带有标记的对象就是"可达的"。没有被标记的对象,那就是"垃圾"。这样就很好地解决了对象不可达的问题。(避免了两个对象相互引用、但是没有外部引用指向的问题) 
尽管可达性分析方法可以有效解决引用循环的问题,但是如果一个程序当中的对象特别多,那么也一定会造成比较大的性能损耗,因为整个搜索的过程也是比较消耗时间的。
GCRoots是哪些变量(3类)
第一类:栈上的局部变量;
第二类:常量池当中的引用指向的变量;
第三类:方法区当中的静态成员指向的对象。
第二阶段:回收垃圾(释放内存)
回收垃圾主要分为三种策略:
策略1:标记-清除策略;
策略2:复制算法;
策略3:标记-整理策略
下面,将分别介绍这三种策略:
策略1:标记-清除策略
标记,就是可达性分析的过程。例如在一次搜索当中,发现了以下几个部分是"垃圾"。清除,就是直接释放内存。
策略1存在问题分析:(内存碎片)
此时如果直接释放,虽然内存的确还给了操作系统了,但是内存还是离散的,也就不是连续的,这样带来的问题就是"内存碎片",影响程序的运行效率。
策略2:复制算法
为了解决内存碎片,引入的复制算法。如下图:把内存一分为二:
然后,把正常的对象(没有被标记为垃圾的对象)的拷贝到令一半。
 最后,把左侧的空前全部释放掉。此时,内存碎片问题就迎刃而解了。
最后,把左侧的空前全部释放掉。此时,内存碎片问题就迎刃而解了。

复制算法存在问题分析:
复制算法有效解决了上述的内存碎片问题,但是,仍然有以下的两个问题没有解决:
问题1:内存空间利用率低,只能利用一半的空间。
问题2:开销大。如果垃圾比较少,那么这种搬运得不偿失。
策略3:标记——整理
这个过程,就是把正常的对象(没有被标记为垃圾的)往前搬运。最后,释放掉最后面的内存。
下图当中,灰色部分的为垃圾。
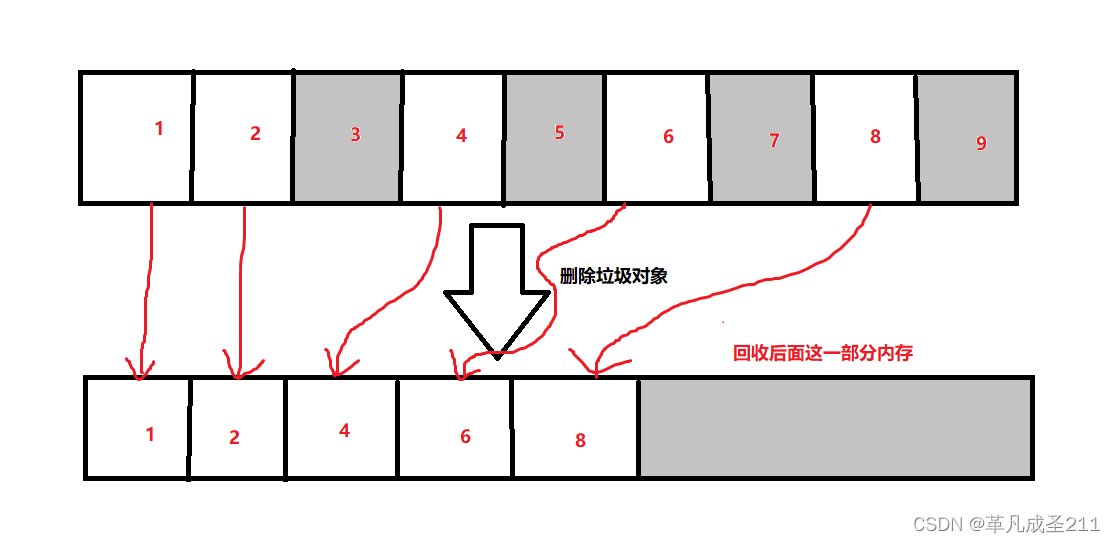
但是,这个拷贝也是有开销的。
上述的3种方案,虽然可以解决问题,但是都有缺陷。因此,实际上JVM当中,会结合多种方案一起来实现,并不是采用单一的策略。这种方式,就是"分代回收"。
分代回收
分代回收,其实就是针对对象进行"分类",根据对象的"年龄"进行回收。
对象的年龄:每熬过GC的一轮扫描没有被回收,那么对象的年龄就+1岁。这个年龄存储在"对象头"当中。
大致是这样的一个过程:
存储对象的内存区域大致就被分为了两部分:新生代和老年代
在新生代当中,分为了两部分:伊甸区和幸存区。一共有2个幸存区
步骤1:对于刚刚产生的对象,都会被存放在"伊甸区"。
步骤2:如果熬过一轮GC,那么就会被拷贝到"幸存区",(应用了复制算法)。但是大部分对象都熬不过一轮的GC。
步骤3:在后续的几轮GC当中,幸存区的对象就在两个幸存区当中来回拷贝。此处也是采用了"复制算法",来淘汰掉一些对象。
步骤4:经过了多轮的GC后,如果一个对象还是没有被淘汰,那么就会被放入"老年代"。此时就认为这个对象存活的可能性就比较大了。对于老年代的对象来说,GC扫描的次数就远远低于新生代了。同时,老年代当中采用的就是"标记——整理"的方式来回收。

但是,有一种特殊的情况,就是当一个对象特别"大",也就是占用内存比较多的时候,无需经过多轮GC的扫描,就可以直接进入"老年代"了,因为回收这一类的对象比较消耗性能。
三、垃圾收集器有哪些
第一类:Serial收集器&Serial Old收集器(串行收集)
这两个垃圾收集器是串行收集的。那么也就意味着,在垃圾的扫描和释放的时候,其他的业务线程都需要停止工作。这种方式扫描得慢、释放得慢、也产生了严重的STW。
第二类:ParNew收集器&Parallel Old收集器&Parallel Scavenge收集器(并发收集)
这三个收集器、引入了多线程的方式来进行回收,也就是"并发收集"。并不影响业务线程执行业务代码。
第三类:CMS收集器
执行步骤:
步骤1:找到GCRoots(会引发STW)
找到GCRoots,但是会引起短暂的STW。
步骤2:并发标记
和业务线程一起执行。
步骤3:重新标记(会引发STW)
步骤4:回收内存
这个步骤,也是和业务线程一起执行的。

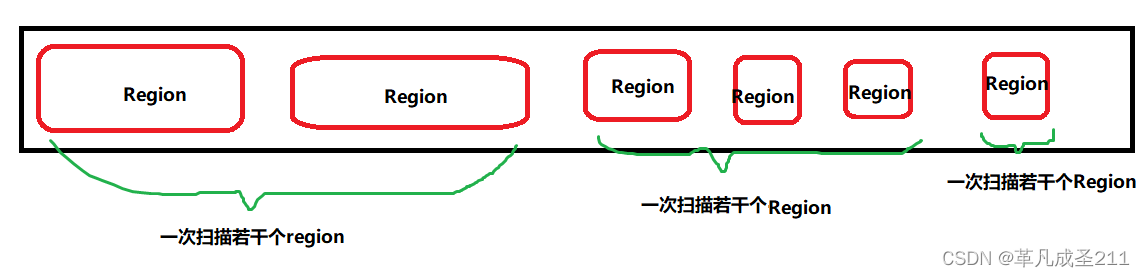
第四类:G1收集器
把整个内存,分成了很多个小的区域(Region)
给这些Region进行了不同的标记。有一些region存放新生的对象,有一些存放老年代的对象。
然后一次扫若干个Region(但不是全部扫完)